本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon Aurora PostgreSQL 和 Amazon RDS for PostgreSQL 中模擬 Oracle PL/SQL 關聯陣列
Rajkumar Raghuwanshi、Bhanu Ganesh Gudivada 和 Sachin Khanna,Amazon Web Services
Summary
此模式說明如何模擬 Amazon Aurora PostgreSQL
我們提供 PostgreSQL 替代方案,除了在遷移 Oracle 資料庫時使用 aws_oracle_ext函數來處理空的索引位置。此模式使用額外的資料欄來存放索引位置,並維護 Oracle 處理稀疏陣列,同時整合原生 PostgreSQL 功能。
Oracle
在 Oracle 中,集合可以初始化為空白,並使用EXTEND集合方法填入,這會將NULL元素附加到陣列。使用由 編製索引的 PL/SQL 關聯陣列時PLS_INTEGER,EXTEND方法會依序新增NULL元素,但元素也可以在非連續索引位置初始化。任何未明確初始化的索引位置都會保持空白。
這種靈活性允許稀疏陣列結構,其中元素可以填入任意位置。使用FOR LOOP具有 FIRST和 LAST 邊界的 反覆查看集合時,只會處理初始化的元素 (無論 NULL還是具有定義的值),同時略過空位置。
PostgreSQL (Amazon Aurora 和 Amazon RDS)
PostgreSQL 處理空值的方式與NULL值不同。它會將空值儲存為使用一個位元組儲存體的不同實體。當陣列具有空值時,PostgreSQL 會指派循序索引位置,就像非空值一樣。但是,循序索引需要額外處理,因為系統必須逐一查看所有索引位置,包括空的位置。這會使稀疏資料集的傳統陣列建立效率降低。
AWS Schema Conversion Tool
AWS Schema Conversion Tool (AWS SCT) 通常會使用 aws_oracle_ext函數處理 Oracle-to-PostgreSQL 的遷移。在此模式中,我們提出使用原生 PostgreSQL 功能的替代方法,該功能結合了 PostgreSQL 陣列類型和用於存放索引位置的額外資料欄。然後,系統只能使用索引資料欄逐一查看陣列。
先決條件和限制
先決條件
作用中 AWS 帳戶。
具有管理員許可的 AWS Identity and Access Management (IAM) 使用者。
與 Amazon RDS 或 Aurora PostgreSQL 相容的執行個體。
對關聯式資料庫的基本了解。
限制
有些 AWS 服務 完全無法使用 AWS 區域。如需區域可用性,請參閱AWS 服務 依區域
。如需特定端點,請參閱服務端點和配額頁面,然後選擇服務的連結。
產品版本
此模式已使用下列版本進行測試:
Amazon Aurora PostgreSQL 13.3
Amazon RDS for PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
架構
來源技術堆疊
內部部署 Oracle 資料庫
目標技術堆疊
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
目標架構
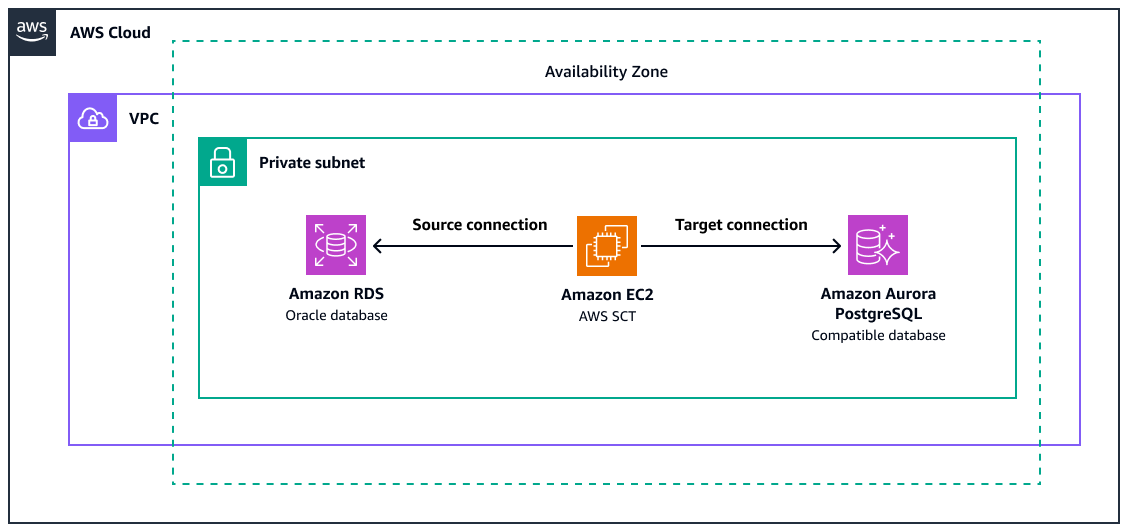
上圖顯示以下項目:
來源 Amazon RDS for Oracle 資料庫執行個體
使用 AWS SCT 將 Oracle 函數轉換為 PostgreSQL 對等項目的 Amazon EC2 執行個體
與 Amazon Aurora PostgreSQL 相容的目標資料庫
工具
AWS 服務
Amazon Aurora 是一種全受管關聯式資料庫引擎,專為雲端而建置,並與 MySQL 和 PostgreSQL 相容。
Amazon Aurora PostgreSQL 相容版本是完全受管的 ACID 相容關聯式資料庫引擎,可協助您設定、操作和擴展 PostgreSQL 部署。
Amazon Elastic Compute Cloud (Amazon EC2) 在 AWS 雲端中提供可擴展的運算容量。您可以視需要啟動任意數量的虛擬伺服器,,並快速進行擴展或縮減。
Amazon Relational Database Service (Amazon RDS) 可協助您在 中設定、操作和擴展關聯式資料庫 AWS 雲端。
Amazon Relational Database Service (Amazon RDS) for Oracle 可協助您在 中設定、操作和擴展 Oracle 關聯式資料庫 AWS 雲端。
適用於 PostgreSQL 的 Amazon Relational Database Service (Amazon RDS) 可協助您在 中設定、操作和擴展 PostgreSQL 關聯式資料庫 AWS 雲端。
AWS Schema Conversion Tool (AWS SCT) 透過自動將來源資料庫結構描述和大部分自訂程式碼轉換為與目標資料庫相容的格式,支援異質資料庫遷移。
其他工具
Oracle SQL Developer
是一種整合的開發環境,可簡化傳統和雲端部署中 Oracle 資料庫的開發和管理。 pgAdmin
是 PostgreSQL 的開放原始碼管理工具。它提供圖形界面,可協助您建立、維護和使用資料庫物件。在此模式中,pgAdmin 會連線至 RDS for PostgreSQL 資料庫執行個體並查詢資料。或者,您可以使用 psql 命令列用戶端。
最佳實務
測試資料集邊界和邊緣案例。
考慮針對out-of-bounds索引條件實作錯誤處理。
最佳化查詢以避免掃描稀疏資料集。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
在 Oracle 中建立來源 PL/SQL 區塊。 | 在 Oracle 中建立使用下列關聯陣列的來源 PL/SQL 區塊:
| DBA |
執行 PL/SQL 區塊。 | 在 Oracle 中執行來源 PL/SQL 區塊。如果關聯陣列的索引值之間存在間隙,則不會在這些間隙中存放任何資料。這可讓 Oracle 迴圈僅逐一查看索引位置。 | DBA |
檢閱輸出。 | 以非連續間隔將五個元素插入陣列 (
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
在 PostgreSQL 中建立目標 PL/pgSQL 區塊。 PostgreSQL | 在 PostgreSQL 中建立使用以下關聯陣列的目標 PL/pgSQL 區塊: PostgreSQL
| DBA |
執行 PL/pgSQL 區塊。 | 在 PostgreSQL 中執行目標 PL/pgSQL 區塊。 PostgreSQL 如果關聯陣列的索引值之間存在間隙,則不會在這些間隙中存放任何資料。這可讓 Oracle 迴圈僅逐一查看索引位置。 | DBA |
檢閱輸出。 | 陣列長度大於 5,因為
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
使用陣列和使用者定義的類型建立目標 PL/pgSQL 區塊。 | 為了最佳化效能並符合 Oracle 的功能,我們可以建立使用者定義的類型,同時存放索引位置及其對應的資料。這種方法透過維持索引和值之間的直接關聯來減少不必要的反覆運算。
| DBA |
執行 PL/pgSQL 區塊。 | 執行目標 PL/pgSQL 區塊。如果關聯陣列的索引值之間存在間隙,則不會在這些間隙中存放任何資料。這可讓 Oracle 迴圈僅逐一查看索引位置。 | DBA |
檢閱輸出。 | 如下列輸出所示,使用者定義的類型只會存放填入的資料元素,這表示陣列長度符合值的數量。因此,
| DBA |
相關資源
AWS 文件
其他文件
