本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 pg_transport 在兩個 Amazon RDS 資料庫執行個體之間傳輸 PostgreSQL 資料庫
Raunak Rishabh 和 Jitender Kumar,Amazon Web Services
Summary
此模式說明使用 pg_transport 擴充功能,在兩個 Amazon Relational Database Service (Amazon RDS) for PostgreSQL 資料庫執行個體之間遷移極大型資料庫的步驟。此擴充套件提供實體的傳輸機制來移動每個資料庫。透過以最少的處理方式串流資料庫檔案,它提供了在資料庫執行個體之間以最少的停機時間遷移大型資料庫的極快速方法。此延伸模組使用提取模型,其中目標資料庫執行個體會從來源資料庫執行個體匯入資料庫。
先決條件和限制
先決條件
兩個資料庫執行個體都必須執行相同的 PostgreSQL 主要版本。
資料庫不得存在於目標上。否則,傳輸會失敗。
來源資料庫中不得啟用 pg_transport 以外的擴充功能。
所有來源資料庫物件都必須位於預設 pg_default 資料表空間中。
來源資料庫執行個體的安全群組應允許來自目標資料庫執行個體的流量。
安裝 PostgreSQL 用戶端,例如 psql
或 PgAdmin ,以使用 Amazon RDS PostgreSQL 資料庫執行個體。您可以在本機系統中安裝用戶端,或使用 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體。在此模式中,我們在 EC2 執行個體上使用 psql。
限制
您無法在 Amazon RDS for PostgreSQL 的不同主要版本之間傳輸資料庫。
來源資料庫的存取權限和擁有權不會傳輸至目標資料庫。
您無法在僅供讀取複本或僅供讀取複本的父執行個體上傳輸資料庫。
您無法在計劃使用此方法傳輸的任何資料庫資料表中使用 reg 資料類型。
您最多可以在資料庫執行個體上同時執行總共 32 個傳輸 (包括匯入和匯出)。
您無法重新命名或包含/排除資料表。一切都會依原樣遷移。
注意
在移除擴充功能之前進行備份,因為移除擴充功能也會移除相依物件和一些對資料庫操作至關重要的資料。
當您判斷 pg_transport 的工作者數量和
work_mem值時,請考慮在來源執行個體的其他資料庫上執行的執行個體類別和程序。傳輸開始時,來源資料庫上的所有連線都會結束,且資料庫會進入唯讀模式。
注意
當傳輸在一個資料庫上執行時,不會影響相同伺服器上的其他資料庫。
產品版本
Amazon RDS for PostgreSQL 10.10 及更新版本,以及 Amazon RDS for PostgreSQL 11.5 及更新版本。如需最新版本的資訊,請參閱 Amazon RDS 文件中的在資料庫執行個體之間傳輸 PostgreSQL 資料庫。
架構
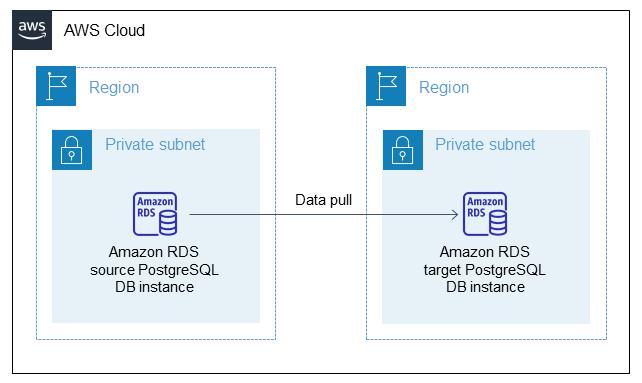
工具
pg_transport 提供實體傳輸機制來移動每個資料庫。透過以最少的處理方式串流資料庫檔案,實體傳輸移動資料的速度遠比傳統傾印和載入程序快得多,而且停機時間也最少。PostgreSQL 可傳輸的資料庫使用提取模式,也就是目的地的資料庫執行個體從來源資料庫執行個體輸入資料庫。當您準備來源和目標環境時,您可以在資料庫執行個體上安裝此延伸模組,如此模式所述。
psql
可讓您連線至 PostgreSQL 資料庫執行個體並使用。若要在您的系統上安裝 psql,請參閱 PostgreSQL 下載 頁面。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立目標系統的參數群組。 | 指定可識別為目標參數群組的群組名稱,例如 | DBA |
修改參數群組的參數。 | 設定下列參數:
如需這些參數的詳細資訊,請參閱 Amazon RDS 文件。 | DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立來源系統的參數群組。 | 指定可識別為來源參數群組的群組名稱,例如 | DBA |
修改參數群組的參數。 | 設定下列參數:
如需這些參數的詳細資訊,請參閱 Amazon RDS 文件。 | DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立新的 Amazon RDS for PostgreSQL 資料庫執行個體以傳輸來源資料庫。 | 根據您的業務需求,決定執行個體類別和 PostgreSQL 版本。 | DBA、系統管理員、資料庫架構師 |
修改目標的安全群組,以允許來自 EC2 執行個體的資料庫執行個體連接埠連線。 | 根據預設,PostgreSQL 執行個體的連接埠為 5432。如果您使用的是另一個連接埠,則必須為 EC2 執行個體開啟該連接埠的連線。 | DBA,系統管理員 |
修改執行個體,並指派新的目標參數群組。 | 例如 | DBA |
重新啟動目標 Amazon RDS 資料庫執行個體。 | 參數 | DBA,系統管理員 |
使用 psql 從 EC2 執行個體連線至資料庫。 | 使用 命令:
| DBA |
建立 pg_transport 擴充功能。 | 以具有
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
修改來源的安全群組,以允許來自 Amazon EC2 執行個體和目標資料庫執行個體的資料庫執行個體連接埠連線 | 根據預設,PostgreSQL 執行個體的連接埠為 5432。如果您使用的是另一個連接埠,則必須為 EC2 執行個體開啟該連接埠的連線。 | DBA,系統管理員 |
修改執行個體並指派新的來源參數群組。 | 例如 | DBA |
重新啟動來源 Amazon RDS 資料庫執行個體。 | 參數 | DBA |
使用 psql 從 EC2 執行個體連線至資料庫。 | 使用 命令:
| DBA |
建立 pg_transport 擴充功能,並從要傳輸的資料庫移除所有其他擴充功能。 | 如果來源資料庫上安裝 pg_transport 以外的任何延伸項目,則傳輸會失敗。此命令必須由具有 | DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
執行試轉。 | 使用
此函數的最後一個參數 (設定為 此函數會顯示您在執行主要傳輸時會看到的任何錯誤。在執行主要傳輸之前解決錯誤。 | DBA |
如果試轉成功,請啟動資料庫傳輸。 | 執行
此函數的最後一個參數 (設定為 | DBA |
執行傳輸後步驟。 | 資料庫傳輸完成後:
| DBA |
相關資源
