Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenmigration von einer RDS-for-PostgreSQL-DB-Instance zu einem Aurora-PostgreSQL-DB-Cluster unter Verwendung eines Aurora–Lesereplikats
Sie können eine RDS-for-PostgreSQL-DB-Instance als Grundlage für einen neuen Aurora-PostgreSQL-DB-Cluster verwenden, indem Sie eine Aurora-Lesereplikat für den Migrationsprozess verwenden. Die Aurora-Read-Replica-Option ist nur für die Migration innerhalb desselben AND-Kontos verfügbar AWS-Region und nur verfügbar, wenn die Region eine kompatible Version von Aurora PostgreSQL für Ihre RDS for PostgreSQL-DB-Instance anbietet. Kompatibel bedeutet, dass die Aurora-PostgreSQL-Version mit der RDS-for-PostgreSQL-Version identisch ist oder dass es sich um eine höhere Nebenversion in derselben Hauptversionsfamilie handelt.
Um diese Technik beispielsweise zum Migrieren einer RDS-for-PostgreSQL-11.14-DB-Instance verwenden zu können, muss die Region Aurora PostgreSQL Version 11.14 oder eine höhere Nebenversion in der PostgreSQL-Version-11-Familie anbieten.
Themen
Übersicht über das Migrieren von Daten mittels einer Aurora-Read Replica
Migrieren von einer RDS-for-PostgreSQL-DB-Instance zu einem Aurora-PostgreSQL-DB-Cluster ist ein mehrstufiges Verfahren. Zuerst erstellen Sie ein Aurora-Lesereplikat Ihrer Quell-RDS-Instance-for-PostgreSQL-DB-Instance. Dies startet einen Replikationsprozess von Ihrer RDS-for-PostgreSQL-DB-Instance zu einem speziellen DB-Cluster, der als Replikat-Cluster bekannt ist. Der Replikat-Cluster besteht ausschließlich aus einem Aurora-Lesereplikat (einer Reader-Instance).
Anmerkung
Es kann mehrere Stunden pro Terabyte Daten dauern, bis die Migration abgeschlossen ist.
Werbung für ein Aurora PostgreSQL-Replikat
Nachdem Sie einen Aurora PostgreSQL-DB-Cluster erstellt haben, gehen Sie wie folgt vor, um die Aurora Replica zu bewerben:
-
Stoppen Sie den gesamten Datenbank-Schreib-Workload auf der Quell-RDS für PostgreSQL-DB-Instance.
-
Holen Sie sich den aktuellen Stand
WAL LSNvon der Quell-RDS für die PostgreSQL-DB-Instance:SELECT pg_current_wal_lsn();pg_current_wal_lsn -------------------- 0/F0000318 (1 row) -
Überprüfen Sie auf dem Aurora PostgreSQL Replica-Cluster, ob die wiedergegebene LSN größer ist als die LSN aus Schritt 2:
SELECT pg_last_wal_replay_lsn();pg_last_wal_replay_lsn ------------------------ 0/F0000400 (1 row)Alternativ können Sie die folgende Abfrage für die Quell-RDS für die PostgreSQL-DB-Instance verwenden:
SELECT restart_lsn FROM pg_replication_slots; -
Werben Sie für den Aurora PostgreSQL Replica-Cluster.
Wenn die Replikation beendet wird, wird der Replikatcluster zu einem eigenständigen Aurora PostgreSQL-DB-Cluster heraufgestuft, und der Reader wird zur Writer-Instance für den Cluster heraufgestuft. An dieser Stelle können Sie dem Aurora PostgreSQL-DB-Cluster Instances hinzufügen, um ihn entsprechend Ihrem Anwendungsfall zu dimensionieren. Wenn Sie die ursprüngliche RDS for PostgreSQL-DB-Instance nicht mehr benötigen, können Sie sie löschen.
Sie können kein Aurora-Lesereplikat erstellen, falls die RDS-for-PostgreSQL-DB-Instance bereits über ein Aurora-Lesereplikat verfügt oder ein regionsübergreifendes Lesereplikat enthält.
Vorbereiten der Migration von Daten mithilfe einer Aurora Read Replica
Während des Migrationsprozesses mit Aurora-Lesereplikat werden Aktualisierungen, die mit den Daten der Quell-RDS-for-PostgreSQL-DB-Instance vorgenommen werden, asynchron in diesem Aurora-Lesereplikat des Replica-Clusters repliziert. Der Prozess verwendet die native Streaming-Replikationsfunktion von PostgreSQL, die Write-Ahead-Log-Segmente (WAL) auf der Quell-Instance speichert. Bevor Sie mit diesem Migrationsprozess beginnen, stellen Sie sicher, dass die Instance über genügend Speicherkapazität verfügt, indem Sie die Werte für die in der Tabelle aufgeführten Metriken überprüfen.
| Metrik | Beschreibung |
|---|---|
|
|
Den verfügbaren Speicherplatz. Einheiten: Byte |
|
|
Der Verzögerungsgröße für WAL-Daten in der Replika, die die höchste Verzögerung aufweist. Einheiten: Megabyte |
|
|
Die Zeit in Sekunden, wie lange ein Aurora PostgreSQL-DB-Cluster hinter der RDS-DB-Quell-Instance liegt. |
|
|
Der von den Transaktionsprotokollen verwendete Festplattenspeicher. Einheiten: Megabyte |
Weitere Informationen zur Überwachung Ihrer RDS-Instance finden Sie unter Überwachung im Amazon RDS-Benutzerhandbuch.
Erstellen einer Aurora Read Replica
Sie können eine Aurora-Read Replica für eine RDS for PostgreSQL-DB-Instance erstellen, indem Sie den oder den AWS Management Console verwenden. AWS CLI Die Option zum Erstellen einer Aurora-Read Replica mit dem AWS Management Console ist nur verfügbar, wenn das eine kompatible Aurora PostgreSQL-Version AWS-Region anbietet. Das heißt, es ist nur verfügbar, wenn es eine Aurora-PostgreSQL-Version gibt, die mit der RDS-for-PostgreSQL-Version oder einer höheren Nebenversion in derselben Hauptversionsfamilie identisch ist.
Sie erstellen Sie eine Aurora Read Replica aus einer PostgreSQL-DB-Instance
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Datenbanken aus.
-
Wählen Sie die RDS-for-PostgreSQL-DB-Instance aus, die Sie als Quelle für Ihr Aurora-Lesereplikat verwenden möchten. Wählen Sie für Actions (Aktionen) Create Aurora read replica (Aurora Read Replica erstellen) aus. Wenn diese Auswahl nicht angezeigt wird, bedeutet dies, dass eine kompatible Aurora-PostgreSQL-Version in der Region nicht verfügbar ist.
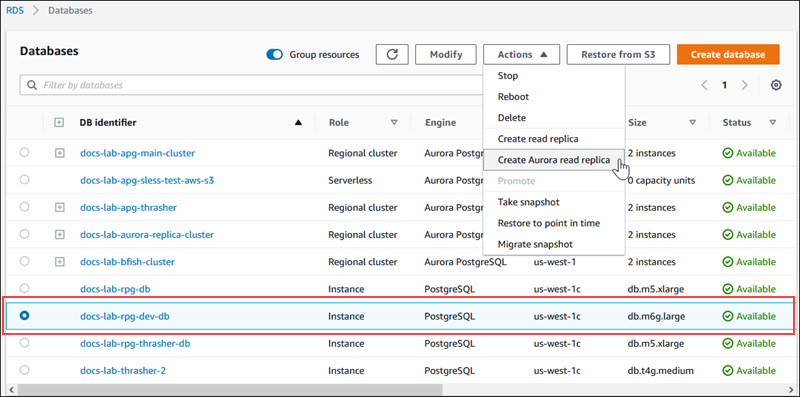
-
Auf der Seite Einstellungen für Aurora-Lesereplikat erstellen konfigurieren Sie die Eigenschaften für den Aurora-PostgreSQL-DB-Cluster wie in der folgenden Tabelle dargestellt. Das Replica-DB-Cluster wird aus einem Snapshot der Quell-DB-Instance unter Verwendung des gleichen Master-Benutzernamens und Kennworts wie die Quelle erstellt, sodass Sie diese derzeit nicht ändern können.
Option Beschreibung DB-Instance-Klasse
Wählen Sie eine DB-Instance-Klasse aus, die die Verarbeitungs- und Speicheranforderungen der primären Instance im DB-Cluster erfüllt. Weitere Informationen finden Sie unter Amazon Aurora Aurora-DB-Instance-Klassen.
Multi-AZ-Bereitstellung
Während der Migration nicht verfügbar
DB-Instance-Kennung
Geben Sie den Namen ein, den Sie der DB-Instance zuweisen möchten. Dieser Bezeichner wird in der Endpunktadresse für die primäre Instance des neuen DB-Clusters verwendet.
Für den DB-Instance-Bezeichner gelten folgende Einschränkungen:
-
Er muss zwischen 1 und 63 alphanumerische Zeichen oder Bindestriche enthalten.
-
Das erste Zeichen muss ein Buchstabe sein.
-
Darf nicht mit einem Bindestrich enden oder zwei aufeinanderfolgende Bindestriche enthalten.
-
Sie muss für alle DB-Instances, für jedes AWS Konto und für jedes Konto eindeutig sein AWS-Region.
Virtual Private Cloud (VPC)
Wählen Sie die VPC zum Hosten des DB-Clusters aus. Wählen Sie Create new VPC (Neue VPC erstellen) aus, damit Amazon RDS eine VPC für Sie erstellt. Weitere Informationen finden Sie unter Voraussetzungen für DB-Cluster.
DB-Subnetzgruppe
Wählen Sie die DB-Subnetzgruppe aus, die für den DB-Cluster verwendet werden soll. Wählen Sie Create new DB subnet group (Neue DB-Subnetzgruppe erstellen) aus, wenn Amazon RDS eine DB-Subnetzgruppe für Sie erstellen soll. Weitere Informationen finden Sie unter Voraussetzungen für DB-Cluster.
Öffentliche Zugänglichkeit
Klicken Sie auf Ja, um dem DB-Cluster eine öffentliche IP-Adresse zuzuweisen. Wählen Sie andernfalls Nein. Die Instances in Ihrem DB-Cluster können eine Mischung aus öffentlichen und privaten DB-Instances sein. Weitere Informationen darüber, wie Sie den öffentlichen Zugriff für Instances deaktivieren, finden Sie unter Ausblenden einer DB-Clusters in einer VPC vor dem Internet.
Availability Zone
Legen Sie fest, ob Sie eine bestimmte Availability Zone angeben möchten. Weitere Informationen über Availability Zones finden Sie unter Regionen und Availability Zones.
VPC-Sicherheitsgruppen
Wählen Sie eine oder mehrere VPC-Sicherheitsgruppen aus, um den Netzwerkzugriff auf den DB-Cluster zu sichern. Wählen Sie Create new VPC security group (Neue VPC-Sicherheitsgruppe erstellen) aus, damit Amazon RDS eine VPC-Sicherheitsgruppe für Sie erstellt. Weitere Informationen finden Sie unter Voraussetzungen für DB-Cluster.
Datenbankport
Geben Sie den Port an, über den Anwendungen und Dienstprogramme auf die Datenbank zugreifen können. Aurora PostgreSQL-DB-Cluster haben standardmäßig den Standard-PostgreSQL-Port 5432 eingestellt. Die Firewalls einiger Unternehmen blockieren Verbindungen mit diesem Port. Wenn die Firewall Ihres Unternehmens den Standardport blockiert, wählen Sie einen anderen Port für den neuen DB-Cluster aus.
DB-Parametergruppe
Wählen Sie eine DB-Parametergruppe für den Aurora-PostgreSQL-DB-Cluster aus. Aurora verfügt über eine DB-Standardparametergruppe, die Sie verwenden können, oder Sie können Ihre eigene DB-Parametergruppe erstellen. Weitere Informationen zu DB-Parametergruppen finden Sie unter Parametergruppen für Amazon Aurora.
DB-Cluster-Parametergruppe
Wählen Sie eine DB-Cluster-Parametergruppe für den Aurora-PostgreSQL-DB-Cluster aus. Aurora verfügt über eine DB-Cluster-Standardparametergruppe, die Sie verwenden können, oder Sie können Ihre eigene DB-Cluster-Parametergruppe erstellen. Weitere Informationen zu DB-Cluster-Parametergruppen finden Sie unter Parametergruppen für Amazon Aurora.
Verschlüsselung
Wählen Sie Enable encryption (Verschlüsselung aktivieren) aus, wenn das neue Aurora-DB-Cluster im Ruhezustand verschlüsselt werden soll. Wenn Sie Verschlüsselung aktivieren wählen, wählen Sie auch einen KMS-Schlüssel als Wert AWS KMS key .
Priorität
Wählen Sie eine Failover-Priorität für den DB-Cluster aus. Wenn Sie keinen Wert auswählen, wird als Standard tier-1 (Tier-1) eingestellt. Diese Priorität bestimmt die Reihenfolge, in der Aurora-Replikate bei der Wiederherstellung nach einem Ausfall der primären Instance hochgestuft werden. Weitere Informationen finden Sie unter Fehlertoleranz für einen Aurora-DB-Cluster.
Aufbewahrungszeitraum für Backups
Wählen Sie den Zeitraum (zwischen 1 und 35 Tage) für die Aufbewahrung von Sicherungskopien der Datenbank in Aurora aus. Sicherungskopien können sekundengenau für point-in-time Wiederherstellungen (PITR) Ihrer Datenbank verwendet werden.
Verbesserte Überwachung
Wählen Sie Erweiterte Überwachung aktivieren aus, um die Erfassung von Metriken in Echtzeit für das Betriebssystem zu aktivieren, in dem Ihr DB-Cluster ausgeführt wird. Weitere Informationen finden Sie unter Überwachen von Betriebssystem-Metriken mithilfe von „Enhanced Monitoring“·(Erweiterte·Überwachung).
Überwachungsrolle
Nur verfügbar, wenn Enable Enhanced Monitoring (Erweiterte Überwachung aktivieren) festgelegt ist. Legen Sie die zu „Enhanced Monitoring“ (Erweiterten Überwachung) verwendete AWS Identity and Access Management -(IAM)-Rolle fest. Weitere Informationen finden Sie unter Einrichten und Aktivieren von „Enhanced Monitoring“ (Erweiterte Überwachung).
Granularität
Nur verfügbar, wenn Enable Enhanced Monitoring (Erweiterte Überwachung aktivieren) festgelegt ist. Mit ihr können Sie die Zeitspanne zwischen den Erfassungen der Kennzahlen des DB-Clusters in Sekunden festlegen.
Kleinere Versions-Updates automatisch aktivieren
Klicken Sie auf Ja, wenn Sie möchten, dass Ihr Aurora PostgreSQL-DB-Cluster automatisch Upgrades für PostgreSQL-DB-Engine-Unterversionen erhält, sobald sie verfügbar werden.
Die Option Auto Minor Version Upgrade (Upgrade einer Unterversion automatisch durchführen) gilt nur bei Upgrades für Engine-Unterversionen von PostgreSQL für Ihren Aurora PostgreSQL-DB-Cluster. Regelmäßige Patches zur Aufrechterhaltung der Systemstabilität sind davon nicht betroffen.
Wartungsfenster
Wählen Sie den wöchentlichen Zeitraum aus, in dem Systemwartungen durchgeführt werden können.
-
-
Wählen Sie Read Replica erstellen aus.
Um mithilfe von eine Aurora-Read Replica aus einer RDS-Quell-DB-Instance für PostgreSQL zu erstellen, verwenden Sie zunächst den create-db-clusterCLI-Befehl AWS CLI, um einen leeren Aurora-DB-Cluster zu erstellen. Sobald der DB-Cluster existiert, verwenden Sie den Befehl create-db-instance, um die primäre Instance für Ihren DB-Cluster zu erstellen. Die primäre Instance ist die erste in einem Aurora-DB-Cluster erstellte Instance. In diesem Fall wird sie zunächst als Aurora-Lesereplikat Ihrer RDS-for-PostgreSQL-DB-Instance erstellt. Wenn der Prozess abgeschlossen wird, wurde Ihre RDS-for-PostgreSQL-DB-Instance effektiv zu einem Aurora-PostgreSQL-DB-Cluster migriert.
Sie müssen das Hauptbenutzerkonto (normalerweise postgres), sein Passwort oder den Datenbanknamen nicht angeben. Die Aurora-Read Replica bezieht diese automatisch von der Quell-RDS für PostgreSQL-DB-Instance, die Sie beim Aufrufen der Befehle identifizieren. AWS CLI
Sie müssen allerdings die Engine-Version angeben, die für den Aurora-PostgreSQL-DB-Cluster und die DB-Instance verwendet werden soll. Die von Ihnen angegebene Version sollte mit der Quell-DB-Instance von RDS for PostgreSQL übereinstimmen. Wenn die Quell-DB-Instance von RDS for PostgreSQL verschlüsselt ist, müssen Sie auch die Verschlüsselung für die primäre Instance des Aurora-PostgreSQL-DB-Clusters angeben. Die Migration einer verschlüsselten Instance zu einem unverschlüsselten Aurora-DB-Cluster wird nicht unterstützt.
In den folgenden Beispielen wird ein Aurora-PostgreSQL-DB-Cluster mit dem Namen my-new-aurora-cluster erstellt, der eine unverschlüsselte RDS-DB-Quell-Instance verwenden soll. Sie erstellen zuerst den Aurora-PostgreSQL-DB-Cluster, indem Sie den CLI-Befehl create-db-cluster aufrufen. Das Beispiel zeigt, wie Sie den optionalen Parameter --storage-encrypted verwenden, um anzugeben, dass der DB-Cluster verschlüsselt werden soll. Da die Quell-DB nicht verschlüsselt ist, wird --kms-key-id verwendet, um den zu verwendenden Schlüssel anzugeben. Weitere Informationen zu den erforderlichen und optionalen Parametern finden Sie in der Liste, die auf das Beispiel folgt.
Für, oder: Linux macOS Unix
aws rds create-db-cluster \ --db-cluster-identifiermy-new-aurora-cluster\ --db-subnet-group-namemy-db-subnet--vpc-security-group-idssg-11111111--engine aurora-postgresql \ --engine-versionsame-as-your-rds-instance-version\ --replication-source-identifier arn:aws:rds:aws-region:111122223333:db/rpg-source-db\ --storage-encrypted \ --kms-key-id arn:aws:kms:aws-region:111122223333:key/11111111-2222-3333-444444444444
Windows:
aws rds create-db-cluster ^ --db-cluster-identifiermy-new-aurora-cluster^ --db-subnet-group-namemy-db-subnet^ --vpc-security-group-idssg-11111111^ --engine aurora-postgresql ^ --engine-versionsame-as-your-rds-instance-version^ --replication-source-identifier arn:aws:rds:aws-region:111122223333:db/rpg-source-db^ --storage-encrypted ^ --kms-key-id arn:aws:kms:aws-region:111122223333:key/11111111-2222-3333-444444444444
In der folgenden Liste finden Sie weitere Informationen zu einigen der im Beispiel gezeigten Optionen. Sofern nicht anders angegeben, sind diese Parameter erforderlich.
-
--db-cluster-identifier– Sie müssen Ihrem neuen Aurora-PostgreSQL-DB-Cluster einen Namen geben. -
--db-subnet-group-name– Erstellen Sie Ihren Aurora-PostgreSQL-DB-Cluster im selben DB-Subnetz wie die DB-Quell-Instance. -
--vpc-security-group-ids– Legen Sie die Sicherheitsgruppe für Ihren Aurora-PostgreSQL-DB-Cluster fest. -
--engine-version– Legen Sie die Version fest, die Sie für den Aurora-PostgreSQL-DB-Cluster verwenden möchten. Dies sollte dieselbe oder eine höhere Nebenversion als die Version sein, die von Ihrer Quell-RDS für PostgreSQL-DB-Instance verwendet wird. -
--replication-source-identifier– Identifizieren Sie Ihre RDS-for-PostgreSQL-DB-Instance über den Amazon-Ressourcennamen (ARN). Weitere Informationen zu Amazon RDS ARNs finden Sie unter Amazon Relational Database Service (Amazon RDS) in der Allgemeine AWS-Referenz. Ihres DB-Clusters. -
--storage-encrypted– Optional. Verwenden Sie diese Option, wenn die Verschlüsselung wie folgt angegeben werden muss:Verwenden Sie diesen Parameter, wenn die Quell-DB-Instance über verschlüsselten Speicher verfügt. Der Aufruf von
create-db-clusterschlägt fehl, wenn Sie diesen Parameter nicht mit einer Quell-DB-Instance verwenden, die über verschlüsselten Speicher verfügt. Wenn Sie einen anderen Schlüssel für den Aurora-PostgreSQL-DB-Cluster verwenden möchten als den von der Quell-DB-Instance verwendeten Schlüssel, müssen Sie auch die--kms-key-idangeben.Verwenden Sie diese Option, wenn der Speicher der Quell-DB-Instance unverschlüsselt ist, der Aurora-PostgreSQL-DB-Cluster jedoch die Verschlüsselung verwenden soll. In diesem Fall müssen Sie auch den Verschlüsselungsschlüssel identifizieren, der mit dem
--kms-key-id-Parameter verwendet werden soll.
-
--kms-key-id– Optional. Wenn Sie diese Option verwenden, können Sie den Schlüssel angeben, der für die Speicherverschlüsselung (--storage-encrypted) verwendet werden soll, indem Sie den ARN, die ID, den Alias-ARN oder den Aliasnamen des Schlüssels angeben. Dieser Parameter wird nur für die folgenden Situationen benötigt:-
Wenn Sie einen anderen Schlüssel für den Aurora-PostgreSQL-DB-Cluster auswählen möchten als den, der von der Quell-DB-Instance verwendet wird.
Wenn Sie einen verschlüsselten Cluster aus einer unverschlüsselten Quelle erstellen möchten. In diesem Fall müssen Sie den Schlüssel angeben, den Aurora PostgreSQL für die Verschlüsselung verwenden soll.
-
Nachdem Sie den Aurora-PostgreSQL-DB-Cluster erstellt haben, erstellen Sie die primäre Instance mithilfe des CLI-Befehls create-db-instance, wie im Folgenden gezeigt:
Für LinuxmacOS, oderUnix:
aws rds create-db-instance \ --db-cluster-identifiermy-new-aurora-cluster\ --db-instance-classdb.x2g.16xlarge\ --db-instance-identifierrpg-for-migration\ --engine aurora-postgresql
Windows:
aws rds create-db-instance ^ --db-cluster-identifiermy-new-aurora-cluster^ --db-instance-classdb.x2g.16xlarge^ --db-instance-identifierrpg-for-migration^ --engine aurora-postgresql
In der folgenden Liste finden Sie weitere Informationen zu einigen der im Beispiel gezeigten Optionen.
-
--db-cluster-identifier– Der Name des neuen Aurora-PostgreSQL-DB-Clusters, den Sie im vorherigen Schritt mit dem Befehlcreate-db-instanceerstellt haben. -
--db-instance-class– Der Name der DB-Instance-Klasse, die für Ihre primäre Instance verwendet werden soll, z. B.db.r4.xlarge,db.t4g.medium,db.x2g.16xlargeusw. Eine Liste der verfügbaren DB-Instance-Klassen finden Sie unter DB-Instance-Klassenarten. -
--db-instance-identifier– Geben Sie den Namen an, den Ihre primäre Instance erhalten soll. -
--engine aurora-postgresql– Geben Sieaurora-postgresqlfür die Engine an.
Wenn Sie ein Aurora-Lesereplikat aus einer Quell-DB-Instance von RDS for PostgreSQL erstellen möchten, verwenden Sie zuerst die RDS-API-Operation CreateDBCluster, um einen neuen Aurora-DB-Cluster für das Aurora-Lesereplikat zu erstellen, das aus Ihrer RDS-for-PostgreSQL-Quell-DB-Instance erstellt wird. Wenn der Aurora-PostgreSQL-DB-Cluster verfügbar ist, verwenden Sie CreateDBInstance, um die primäre Instance für den Aurora-DB-Cluster zu erstellen.
Sie müssen das Hauptbenutzerkonto (normalerweise postgres), sein Passwort oder den Datenbanknamen nicht angeben. Das Aurora-Lesereplikat bezieht diese Angaben automatisch aus der RDS-for-PostgreSQL-Quell-DB-Instance, die in ReplicationSourceIdentifier angegeben ist.
Sie müssen allerdings die Engine-Version angeben, die für den Aurora-PostgreSQL-DB-Cluster und die DB-Instance verwendet werden soll. Die von Ihnen angegebene Version sollte mit der Quell-DB-Instance von RDS for PostgreSQL übereinstimmen. Wenn die Quell-DB-Instance von RDS for PostgreSQL verschlüsselt ist, müssen Sie auch die Verschlüsselung für die primäre Instance des Aurora-PostgreSQL-DB-Clusters angeben. Die Migration einer verschlüsselten Instance zu einem unverschlüsselten Aurora-DB-Cluster wird nicht unterstützt.
Wenn Sie den Aurora-DB-Cluster für das Aurora-Lesereplikat erstellen möchten, verwenden Sie die RDS-API-Operation CreateDBCluster mit folgenden Parametern:
-
DBClusterIdentifier– Der Name des zu erstellenden DB-Clusters. -
DBSubnetGroupName– Der Name der DB-Subnetzgruppe, die mit diesem DB-Cluster verknüpft werden soll. -
Engine=aurora-postgresql– Der Name der zu verwendenden Engine. -
ReplicationSourceIdentifier– Der Amazon Resource Name (ARN) für die PostgreSQL-Quell-DB-Instance. Weitere Informationen zu Amazon RDS ARNs finden Sie unter Amazon Relational Database Service (Amazon RDS) in der Allgemeine Amazon Web Services-Referenz. WennReplicationSourceIdentifiereine verschlüsselte Quelle identifiziert, verwendet Amazon RDS Ihren Standard-KMS-Schlüssel, es sei denn, Sie geben mit der OptionKmsKeyIdeinen anderen Schlüssel an. -
VpcSecurityGroupIds— Die Liste der Amazon EC2 VPC-Sicherheitsgruppen, die diesem DB-Cluster zugeordnet werden sollen. -
StorageEncrypted– Gibt an, ob der DB-Cluster verschlüsselt ist. Wenn Sie diesen Parameter verwenden, ohne auch dieReplicationSourceIdentifieranzugeben, verwendet Amazon RDS Ihren KMS-Standardschlüssel. -
KmsKeyId– Der Schlüssel für einen verschlüsselten Cluster. Wenn Sie diese Option verwenden, können Sie den Schlüssel angeben, der für die Speicherverschlüsselung verwendet werden soll, indem Sie den ARN, die ID, den Alias-ARN oder den Aliasnamen des Schlüssels angeben.
Weitere Informationen finden Sie unter CreateDBCluster in der Amazon-RDS-API-Referenz.
Sobald der Aurora-DB-Cluster verfügbar ist, können Sie eine primäre Instance dafür erstellen, indem Sie die RDS-API-Operation CreateDBInstance mit folgenden Parametern verwenden:
-
DBClusterIdentifier– Der Name Ihres DB-Clusters. -
DBInstanceClass– Der Name der DB-Instance-Klasse, die für Ihre primäre Instance verwendet werden soll. -
DBInstanceIdentifier– Der Name Ihrer primären Instance. -
Engine=aurora-postgresql– Der Name der zu verwendenden Engine.
Weitere Informationen finden Sie unter CreateDBInstance in der Amazon-RDS-API-Referenz.
Hochstufen einer Aurora Read Replica
Die Migration zu Aurora PostgreSQL ist erst abgeschlossen, wenn Sie den Replikat-Cluster hochgestuft haben. Löschen Sie also die RDS-for-PostgreSQL-Quell-DB-Instance noch nicht.
Stellen Sie vor dem Hochladen des Replikat-Clusters sicher, dass die RDS-for-PostgreSQL-DB-Instance keine prozessinternen Transaktionen oder andere Aktivitäten enthält, die in die Datenbank schreiben. Wenn die Replikatverzögerung auf dem Aurora-Lesereplikat Null (0) erreicht, können Sie den Replikatcluster heraufstufen. Weitere Informationen zum Überwachen der Replikatverzögerung finden Sie unter Überwachung einer Aurora PostgreSQL-Replikation und Metriken auf Instance-Ebene für Amazon Aurora.
So stufen Sie eine Aurora-Read Replica zu einem Aurora-DB-Cluster hoch:
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Datenbanken aus.
-
Wählen Sie den Replikatcluster aus.
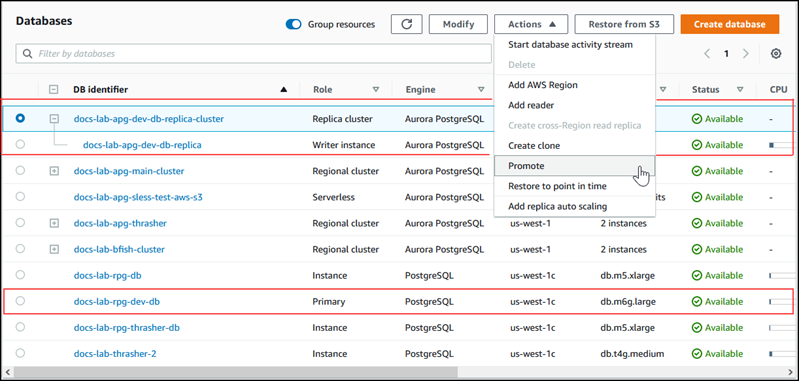
-
Wählen Sie für Actions (Aktionen)Promote (Hochstufen) aus. Dies kann einige Minuten dauern und zu Ausfallzeiten führen.
Wenn der Prozess abgeschlossen ist, ist der Aurora-Replikatcluster ein regionaler Aurora-PostgreSQL-DB-Cluster mit einer Writer-Instance, die die Daten aus der RDS-for-PostgreSQL-DB-Instance enthält.
Verwenden Sie den Befehl, um eine Aurora-Read Replica zu einem eigenständigen DB-Cluster hochzustufen. promote-read-replica-db-cluster AWS CLI
Beispiel
FürLinux, odermacOS: Unix
aws rds promote-read-replica-db-cluster \ --db-cluster-identifiermyreadreplicacluster
Windows:
aws rds promote-read-replica-db-cluster ^ --db-cluster-identifiermyreadreplicacluster
Verwenden Sie den RDS-API-Vorgang, um eine Aurora-Read Replica zu einem eigenständigen DB-Cluster hochzustufen. PromoteReadReplicaDBCluster
Nachdem Sie den Replikatcluster hochgestuft haben, können Sie bestätigen, dass das Hochstufen abgeschlossen wurde, indem Sie das Ereignisprotokoll wie folgt überprüfen.
Um zu bestätigen, dass das Aurora-Replikatcluster hochgestuft wurde
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich die Option Events.
-
Auf der Seite Events (Ereignisse) finden Sie den Namen Ihres Clusters in der Liste Source (Quelle). Jedes Ereignis hat eine Quelle, einen Typ, eine Uhrzeit und eine Nachricht. Sie können alle Ereignisse sehen, die in Ihrem AWS-Region für Ihr Konto aufgetreten sind. Ein erfolgreiches Hochstufen generiert die folgende Nachricht.
Promoted Read Replica cluster to a stand-alone database cluster.
Nach Abschluss der Hochstufung wird die Verknüpfung zwischen der Quell-RDS-for-PostgreSQL-DB-Instance und dem Aurora-PostgreSQL-DB-Cluster aufgehoben. Sie können Ihre Clientanwendungen für den Zugriff auf den Endpunkt des Aurora-Lesereplikats konfigurieren. Weitere Informationen zu den Aurora-Endpunkten finden Sie unter Amazon Aurora Aurora-Endpunktverbindungen. Nun können Sie die DB-Instance bei Bedarf sicher löschen.
