Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwendung von Amazon Aurora Machine Learning mit Aurora PostgreSQL
Wenn Sie Amazon Aurora Machine Learning mit Ihrem Aurora PostgreSQL-DB-Cluster verwenden, können Sie je nach Bedarf Amazon Comprehend oder Amazon SageMaker AI oder Amazon Bedrock verwenden. Diese Services unterstützen jeweils spezifische Anwendungsfälle für Machine Learning.
Aurora Machine Learning wird nur in bestimmten AWS-Regionen und für bestimmte Versionen von Aurora PostgreSQL unterstützt. Bevor Sie versuchen, Aurora Machine Learning einzurichten, überprüfen Sie die Verfügbarkeit Ihrer Aurora-PostgreSQL-Version und Ihrer Region. Details hierzu finden Sie unter Aurora Machine Learning mit Aurora PostgreSQL.
Themen
Voraussetzungen für die Verwendung von Aurora Machine Learning mit Aurora PostgreSQL
Unterstützte Funktionen und Einschränkungen von Aurora Machine Learning mit Aurora PostgreSQL
Einrichten Ihres DB-Clusters von Aurora PostgreSQL zur Verwendung von Aurora Machine Learning
Verwenden von Amazon Bedrock mit Ihrem DB-Cluster von Aurora PostgreSQL
Verwenden von Amazon Comprehend mit Ihrem DB-Cluster von Aurora PostgreSQL
SageMaker KI mit Ihrem Aurora PostgreSQL-DB-Cluster verwenden
Exportieren von Daten nach Amazon S3 für das SageMaker KI-Modelltraining (Fortgeschritten)
Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora PostgreSQL
Voraussetzungen für die Verwendung von Aurora Machine Learning mit Aurora PostgreSQL
AWS Dienste für maschinelles Lernen sind verwaltete Dienste, die in ihren eigenen Produktionsumgebungen eingerichtet und ausgeführt werden. Aurora Machine Learning unterstützt die Integration mit Amazon Comprehend, SageMaker AI und Amazon Bedrock. Bevor Sie versuchen, Ihren DB-Cluster von Aurora PostgreSQL für die Verwendung von Aurora Machine Learning einzurichten, stellen Sie sicher, dass Sie die folgenden Anforderungen und Voraussetzungen verstehen.
Die Amazon Comprehend-, SageMaker AI- und Amazon Bedrock-Services müssen in derselben Weise ausgeführt werden AWS-Region wie Ihr Aurora PostgreSQL-DB-Cluster. Sie können Amazon Comprehend- oder SageMaker AI- oder Amazon Bedrock-Services nicht von einem Aurora PostgreSQL-DB-Cluster in einer anderen Region aus verwenden.
Wenn sich Ihr Aurora PostgreSQL-DB-Cluster in einer anderen Virtual Public Cloud (VPC) befindet, die auf dem Amazon VPC-Service basiert, als Ihre Amazon Comprehend- und SageMaker AI-Services, muss die Sicherheitsgruppe der VPC ausgehende Verbindungen zum Aurora-Zielservice für maschinelles Lernen zulassen. Weitere Informationen finden Sie unter Aktivieren der Netzwerkkommunikation von Amazon Aurora zu anderen AWS-Services.
Für SageMaker KI müssen die Komponenten des maschinellen Lernens, die Sie für Inferenzen verwenden möchten, eingerichtet und einsatzbereit sein. Während des Konfigurationsprozesses für Ihren Aurora PostgreSQL-DB-Cluster müssen Sie den Amazon-Ressourcennamen (ARN) des SageMaker KI-Endpunkts verfügbar haben. Die Datenwissenschaftler in Ihrem Team sind wahrscheinlich am besten in der Lage, mit SageMaker KI zu arbeiten, um die Modelle vorzubereiten und die anderen derartigen Aufgaben zu erledigen. Informationen zu den ersten Schritten mit Amazon SageMaker AI finden Sie unter Erste Schritte mit Amazon SageMaker AI. Weitere Informationen zu Rückschlüssen und Endpunkten finden Sie unter Echtzeit-Inferenz.
-
Für Amazon Bedrock muss die Modell-ID der Bedrock-Modelle, die Sie für Inferenzen verwenden möchten, während des Konfigurationsprozesses Ihres DB-Clusters von Aurora PostgreSQL verfügbar sein. Die Datenwissenschaftler in Ihrem Team sind wahrscheinlich am besten in der Lage, mit Bedrock zu arbeiten, um zu entscheiden, welche Modelle verwendet werden sollen, sie bei Bedarf zu optimieren und andere entsprechende Aufgaben zu erledigen. Informationen zu den ersten Schritten mit Amazon Bedrock finden Sie unter So richten Sie Bedrock ein.
-
Amazon-Bedrock-Benutzer müssen den Zugriff auf Modelle anfordern, bevor sie verwendet werden können. Wenn Sie zusätzliche Modelle für die Text-, Chat- und Bildgenerierung hinzufügen möchten, müssen Sie den Zugriff auf Modelle in Amazon Bedrock anfordern. Weitere Informationen finden Sie unter Modellzugriff.
Unterstützte Funktionen und Einschränkungen von Aurora Machine Learning mit Aurora PostgreSQL
Aurora Machine Learning unterstützt jeden SageMaker KI-Endpunkt, der das CSV-Format (Comma Separated Value) mit einem ContentType Wert von lesen und schreiben kann. text/csv Die integrierten SageMaker KI-Algorithmen, die dieses Format derzeit akzeptieren, sind die folgenden.
Lineares Lernen
Random Cut Forest
XGBoost
Weitere Informationen zu diesen Algorithmen finden Sie unter Choose an Algorithm im Amazon SageMaker AI Developer Guide.
Bei der Verwendung von Amazon Bedrock mit Aurora Machine Learning gelten die folgenden Einschränkungen:
-
Die benutzerdefinierten Funktionen (UDFs) bieten eine native Möglichkeit, mit Amazon Bedrock zu interagieren. Sie haben UDFs keine spezifischen Anforderungen an Anfragen oder Antworten, sodass sie jedes Modell verwenden können.
-
Sie können UDFs damit jeden gewünschten Workflow erstellen. Sie können beispielsweise Basis-Primitive wie
pg_cronkombinieren, um eine Abfrage auszuführen, Daten abzurufen, Schlussfolgerungen zu generieren und in Tabellen zu schreiben, um Abfragen direkt zu bearbeiten. -
UDFs unterstützt keine Batch- oder Parallelanrufe.
-
Die Aurora Machine Learning-Erweiterung unterstützt keine Vektorschnittstellen. Als Teil der Erweiterung ist eine Funktion verfügbar, mit der die Einbettungen der Modellantwort im
float8[]-Format ausgegeben werden können, um diese Einbettungen in Aurora zu speichern. Weitere Informationen zur Verwendung vonfloat8[]finden Sie unter Verwenden von Amazon Bedrock mit Ihrem DB-Cluster von Aurora PostgreSQL.
Einrichten Ihres DB-Clusters von Aurora PostgreSQL zur Verwendung von Aurora Machine Learning
Damit Aurora Machine Learning mit Ihrem Aurora PostgreSQL-DB-Cluster funktioniert, müssen Sie für jeden der Dienste, die Sie verwenden möchten, eine AWS Identity and Access Management (IAM-) Rolle erstellen. Die IAM-Rolle ermöglicht es Ihrem DB-Cluster von Aurora PostgreSQL, den Aurora-Dienst für Machine Learning im Namen des Clusters zu verwenden. Sie müssen auch die Aurora-Erweiterung für Machine Learning installieren. In den folgenden Themen finden Sie Einrichtungsverfahren für jeden dieser Aurora-Dienste für Machine Learning.
Topics
Einrichten von Aurora PostgreSQL für die Verwendung von Amazon Bedrock
Im folgenden Verfahren erstellen Sie zunächst die IAM-Rolle und -Richtlinie, die Aurora PostgreSQL die Berechtigung erteilt, Amazon Bedrock im Namen des Clusters zu verwenden. Anschließend fügen Sie die Richtlinie einer IAM-Rolle an, die Ihren DB-Cluster von Aurora PostgreSQL für die Arbeit mit Amazon Bedrock verwendet. Der Einfachheit halber verwendet dieses Verfahren die AWS-Managementkonsole , um alle Aufgaben abzuschließen.
So richten Sie Ihren DB-Cluster von Aurora PostgreSQL zur Verwendung von Amazon Bedrock ein
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
Öffnen Sie unter https://console.aws.amazon.com/iam/
die IAM-Konsole. Wählen Sie im Konsolenmenü (IAM) die Option Richtlinien AWS Identity and Access Management (unter Zugriffsverwaltung) aus.
Wählen Sie Richtlinie erstellen aus. Wählen Sie auf der Seite „Visueller Editor“ die Option Service aus und geben Sie dann im Feld „Service auswählen“ Bedrock ein. Erweitern Sie die Lesezugriffsebene. Wählen Sie InvokeModelaus den Amazon Bedrock-Leseeinstellungen.
Wählen Sie über die Richtlinie das Foundation/Provisioned Modell aus, dem Sie Lesezugriff gewähren möchten.
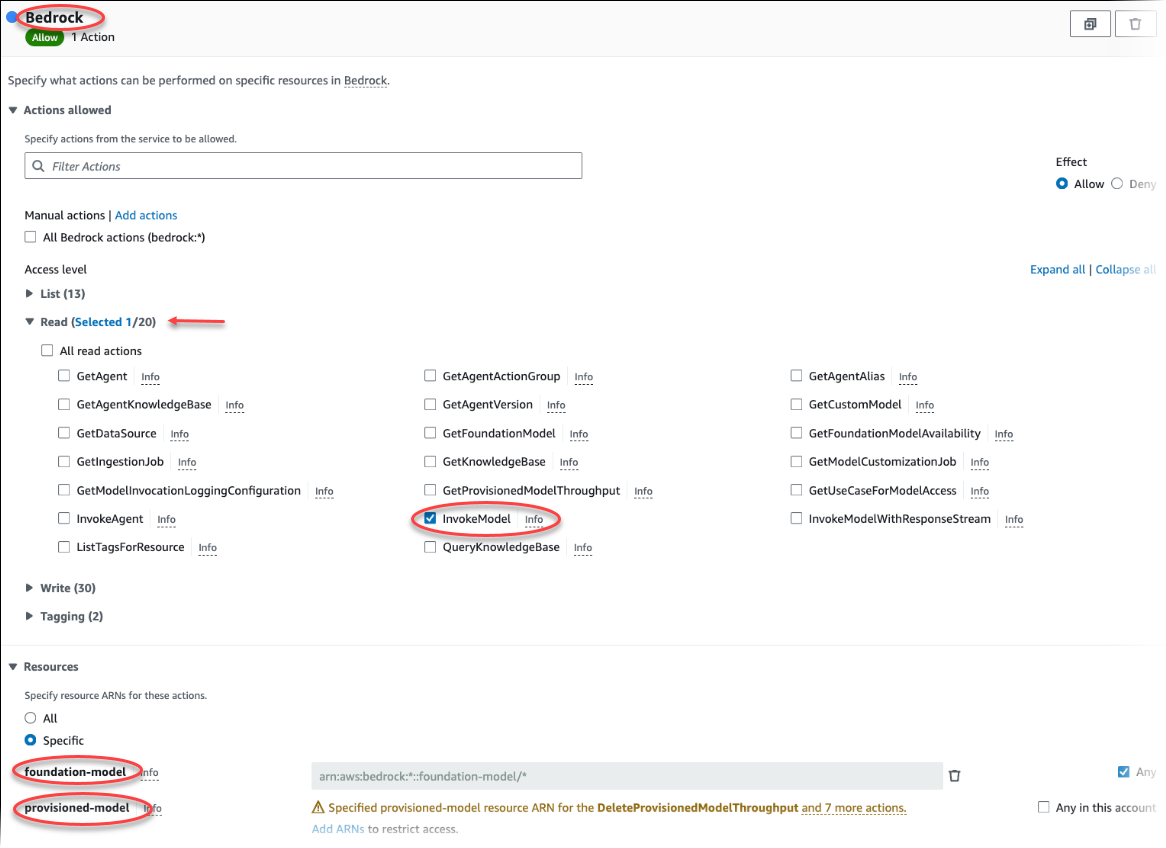
Wählen Sie Next: Tags (Weiter: Tags) aus und definieren Sie Tags (dies ist optional). Wählen Sie Weiter: Prüfen aus. Geben Sie einen Namen und eine Beschreibung für die Richtlinie ein, wie in der Abbildung gezeigt.
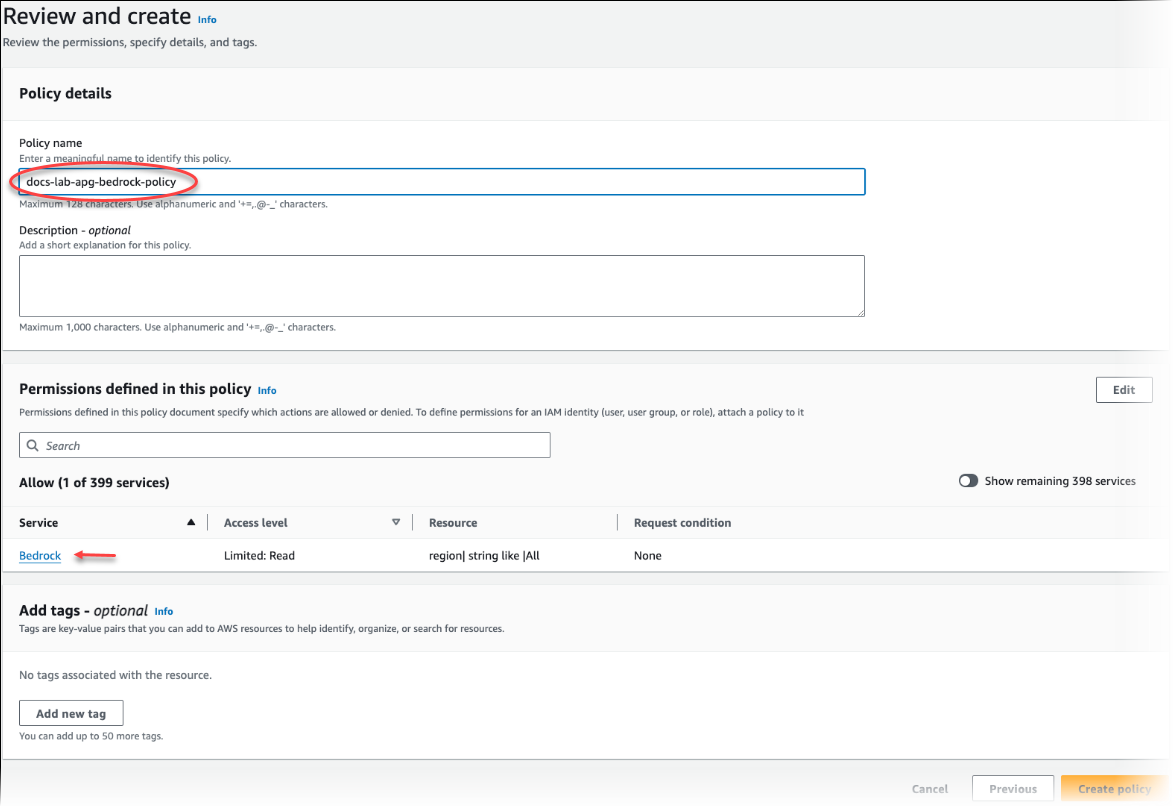
Wählen Sie Richtlinie erstellen aus. Die Konsole zeigt eine Warnung an, wenn die Richtlinie gespeichert wurde. Sie finden sie in der Liste der Richtlinien.
Wählen Sie in der IAM-Konsole die Option Roles (Rollen) (unter „Access management“ (Zugriffsverwaltung)) aus.
Wählen Sie Rolle erstellen aus.
Wählen Sie auf der Seite „Vertrauenswürdige Entitäten auswählen“ die Kachel AWS -Service und dann RDS aus, um die Auswahl zu öffnen.
Wählen Sie RDS – Add Role to Database (RDS – Rolle zu Datenbank hinzufügen) aus.
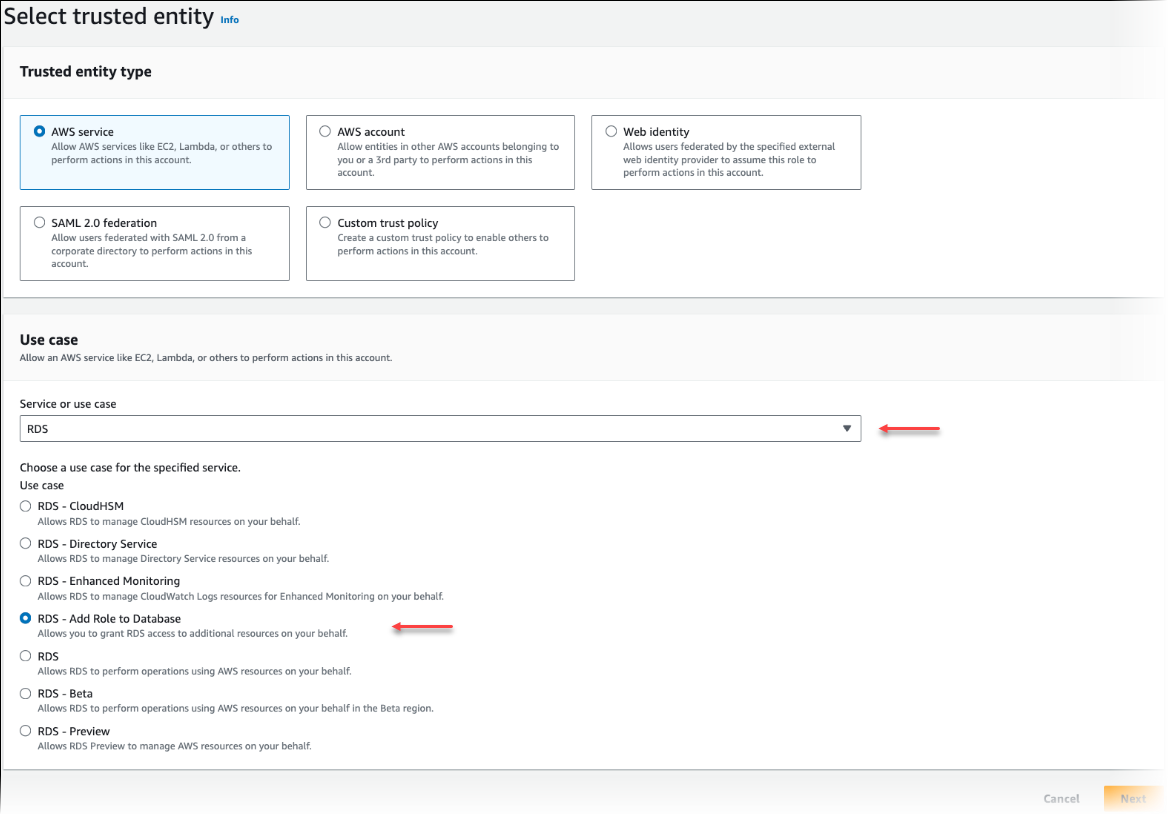
Wählen Sie Weiter aus. Suchen Sie auf der Seite „Add permissions“ (Berechtigungen hinzufügen) nach der im vorherigen Schritt erstellten Richtlinie und wählen Sie sie aus den aufgelisteten Richtlinien aus. Wählen Sie Weiter aus.
Next: Review (Weiter: Überprüfung). Geben Sie einen Namen und eine Beschreibung für die IAM-Rolle ein.
Öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Navigieren Sie zu dem AWS-Region Ort, an dem sich Ihr Aurora PostgreSQL-DB-Cluster befindet.
-
Wählen Sie im Navigationsbereich Datenbanken und dann den Aurora PostgreSQL-DB-Cluster aus, den Sie mit Bedrock verwenden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit) aus und scrollen Sie zum Abschnitt Manage IAM roles (IAM-Rollen verwalten) auf der Seite. Wählen Sie in der Auswahl Add IAM roles to this cluster (Diesem Cluster IAM-Rollen hinzufügen) die Rolle aus, die Sie in den vorherigen Schritten erstellt haben. Wählen Sie in der Auswahl Funktion „Bedrock“ und dann Rolle hinzufügen aus.
Die Rolle ist (mit ihrer Richtlinie) dem DB-Cluster von Aurora PostgreSQL zugeordnet. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste „Current IAM roles for this cluster“ (Aktuelle IAM-Rollen für diesen Cluster) angezeigt, wie in der folgenden Abbildung dargestellt.
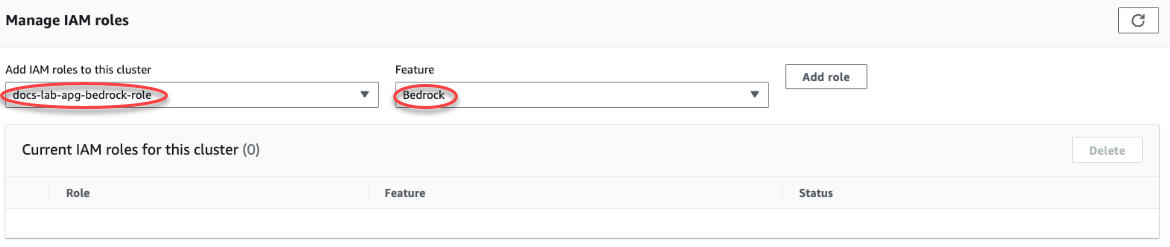
Die IAM-Einrichtung für Amazon Bedrock ist abgeschlossen. Fahren Sie mit der Einrichtung von Aurora PostgreSQL für Aurora Machine Learning fort, indem Sie die Erweiterung wie unter Installieren der Aurora-Erweiterung für Machine Learning beschrieben installieren.
Einrichten von Aurora PostgreSQL für die Verwendung von Amazon Comprehend
Im folgenden Verfahren erstellen Sie zunächst die IAM-Rolle und -Richtlinie, die Aurora PostgreSQL die Berechtigung erteilt, Amazon Comprehend im Namen des Clusters zu verwenden. Anschließend fügen Sie die Richtlinie einer IAM-Rolle an, die Ihr DB-Cluster von Aurora PostgreSQL für die Arbeit mit Amazon Comprehend verwendet. Der Einfachheit halber nutzt dieses Verfahren die AWS-Managementkonsole , um alle Aufgaben abzuschließen.
So richten Sie Ihren DB-Cluster von Aurora PostgreSQL zur Verwendung von Amazon Comprehend ein
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
Öffnen Sie unter https://console.aws.amazon.com/iam/
die IAM-Konsole. Wählen Sie im Konsolenmenü (IAM) die Option Richtlinien AWS Identity and Access Management (unter Zugriffsverwaltung) aus.
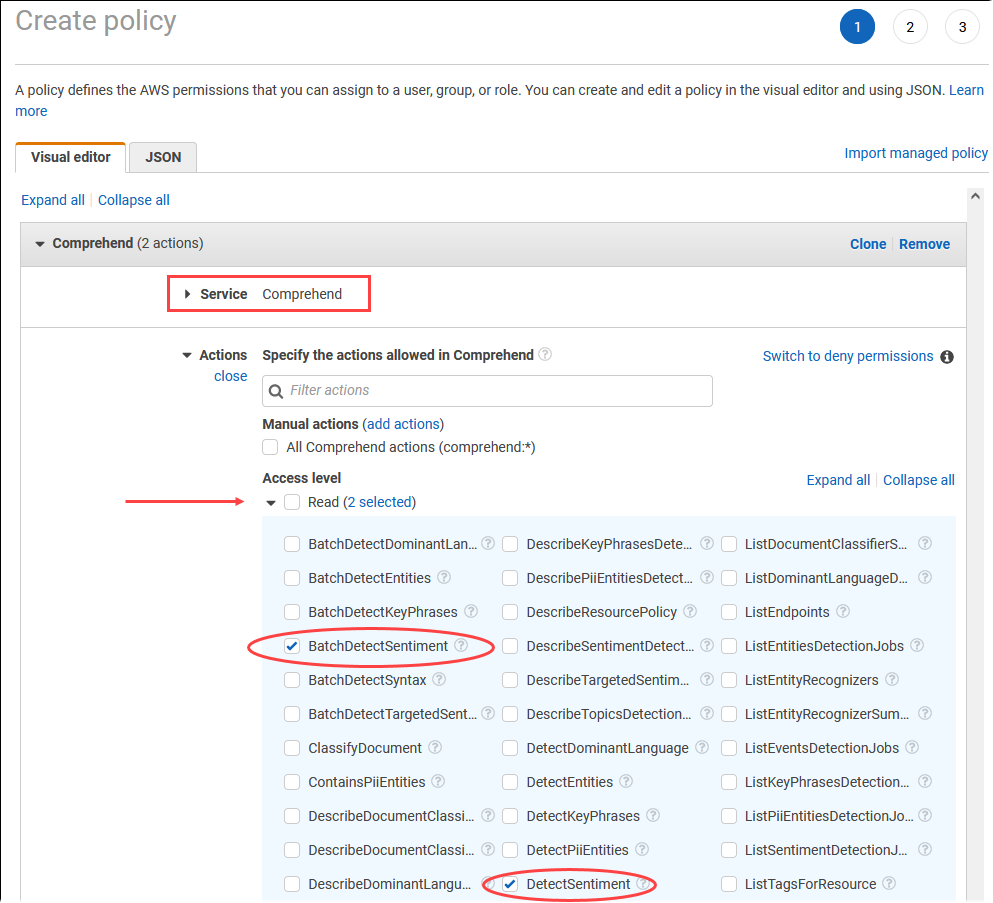
Wählen Sie Richtlinie erstellen aus. Wählen Sie auf der Seite „Visual editor“ (Visueller Editor) die Option Service (Service) aus und geben Sie dann im Feld „Select a service“ (Service auswählen) Comprehend ein. Erweitern Sie die Lesezugriffsebene. Wählen Sie BatchDetectSentimentund DetectSentimentaus den Amazon Comprehend Leseeinstellungen.
Wählen Sie Next: Tags (Weiter: Tags) aus und definieren Sie Tags (dies ist optional). Wählen Sie Weiter: Prüfen aus. Geben Sie einen Namen und eine Beschreibung für die Richtlinie ein, wie in der Abbildung gezeigt.
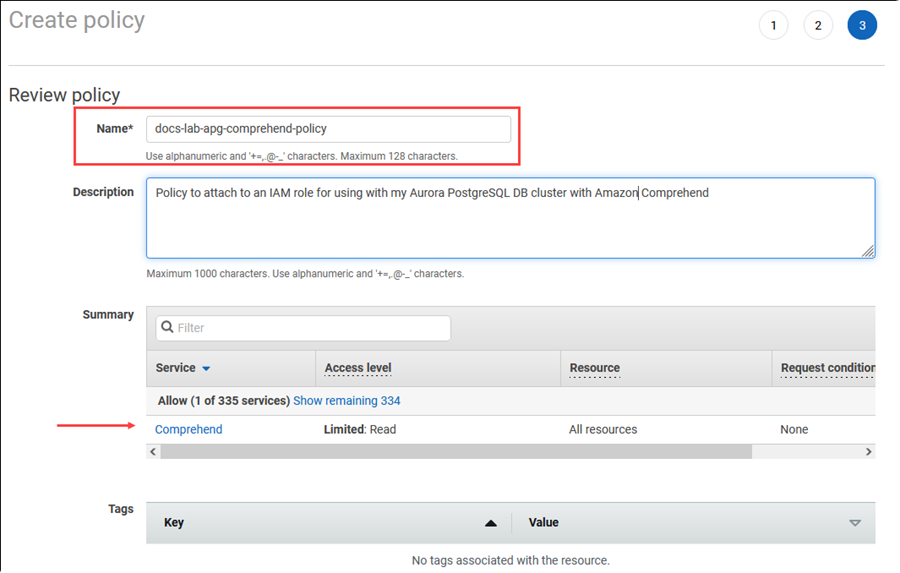
Wählen Sie Richtlinie erstellen aus. Die Konsole zeigt eine Warnung an, wenn die Richtlinie gespeichert wurde. Sie finden sie in der Liste der Richtlinien.
Wählen Sie in der IAM-Konsole die Option Roles (Rollen) (unter „Access management“ (Zugriffsverwaltung)) aus.
Wählen Sie Rolle erstellen aus.
Wählen Sie auf der Seite „Vertrauenswürdige Entitäten auswählen“ die Kachel AWS -Service und dann RDS aus, um die Auswahl zu öffnen.
Wählen Sie RDS – Add Role to Database (RDS – Rolle zu Datenbank hinzufügen) aus.
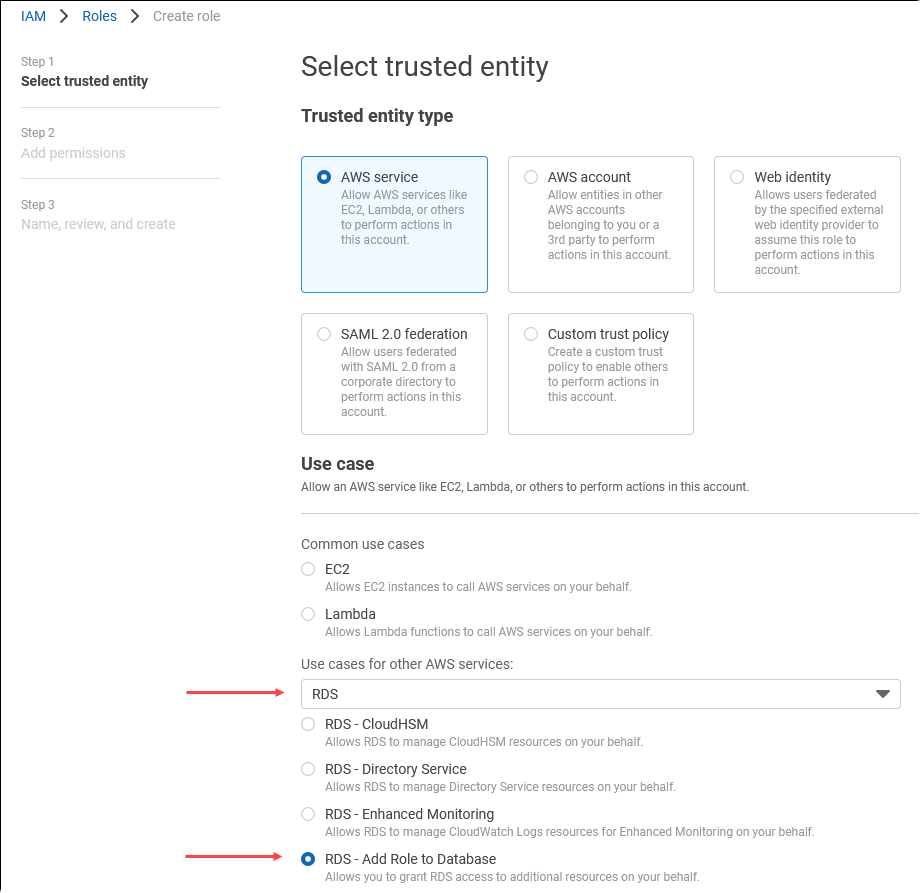
Wählen Sie Weiter aus. Suchen Sie auf der Seite „Add permissions“ (Berechtigungen hinzufügen) nach der im vorherigen Schritt erstellten Richtlinie und wählen Sie sie aus den aufgelisteten Richtlinien aus. Wählen Sie Next (Weiter) aus.
Next: Review (Weiter: Überprüfung). Geben Sie einen Namen und eine Beschreibung für die IAM-Rolle ein.
Öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Navigieren Sie zu dem AWS-Region Ort, an dem sich Ihr Aurora PostgreSQL-DB-Cluster befindet.
-
Wählen Sie im Navigationsbereich Databases (Datenbanken) und dann den DB-Cluster von Aurora PostgreSQL aus, den Sie mit Amazon Comprehend verwenden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit) aus und scrollen Sie zum Abschnitt Manage IAM roles (IAM-Rollen verwalten) auf der Seite. Wählen Sie in der Auswahl Add IAM roles to this cluster (Diesem Cluster IAM-Rollen hinzufügen) die Rolle aus, die Sie in den vorherigen Schritten erstellt haben. Wählen Sie in der Auswahl Funktion „Comprehend“ und dann Rolle hinzufügen aus.
Die Rolle ist (mit ihrer Richtlinie) dem DB-Cluster von Aurora PostgreSQL zugeordnet. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste „Current IAM roles for this cluster“ (Aktuelle IAM-Rollen für diesen Cluster) angezeigt, wie in der folgenden Abbildung dargestellt.

Die IAM-Einrichtung für Amazon Comprehend ist abgeschlossen. Fahren Sie mit der Einrichtung von Aurora PostgreSQL für Aurora Machine Learning fort, indem Sie die Erweiterung wie unter Installieren der Aurora-Erweiterung für Machine Learning beschrieben installieren.
Aurora PostgreSQL für die Verwendung von Amazon AI einrichten SageMaker
Bevor Sie die IAM-Richtlinie und -Rolle für Ihren Aurora PostgreSQL-DB-Cluster erstellen können, müssen Sie Ihr SageMaker KI-Modell einrichten und Ihren Endpunkt verfügbar haben.
So richten Sie Ihren Aurora PostgreSQL-DB-Cluster für die Verwendung von KI ein SageMaker
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
Wählen Sie im Konsolenmenü (IAM) die Option Richtlinien AWS Identity and Access Management (unter Zugriffsverwaltung) und wählen Sie dann Richtlinie erstellen aus. Wählen Sie im Visual Editor SageMakerden Service aus. Öffnen Sie für Aktionen die Leseauswahl (unter Zugriffsebene) und wählen Sie InvokeEndpoint. Daraufhin wird ein Warnsymbol angezeigt.
Öffnen Sie die Ressourcenauswahl und wählen Sie unter Endpunktressourcen-ARN angeben für die InvokeEndpoint Aktion den Link ARN hinzufügen, um den Zugriff einzuschränken.
Geben Sie Ihre SageMaker KI-Ressourcen und den Namen Ihres Endpunkts ein. AWS-Region Ihr AWS Konto ist vorausgefüllt.
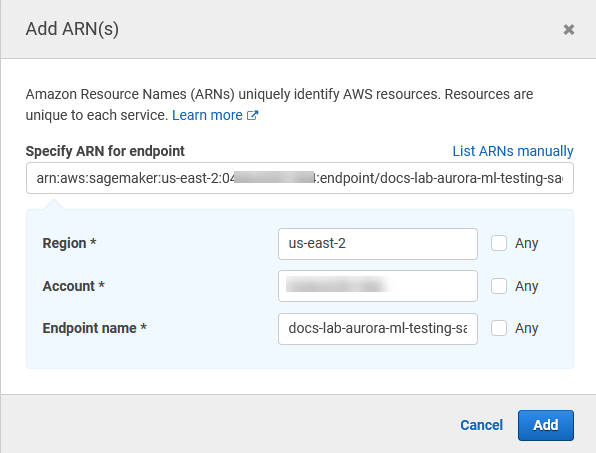
Wählen Sie zum Speichern Add (Hinzufügen) aus. Wählen Sie Next: Tags (Weiter: Tags) und Next: Review (Weiter: Überprüfen) aus, um zur letzten Seite des Richtlinienerstellungsprozesses zu gelangen.
Geben Sie einen Namen und eine Beschreibung für die Richtlinie ein und wählen Sie dann Create policy (Richtlinie erstellen) aus. Die Richtlinie wird erstellt und der Liste „Policies“ (Richtlinien) hinzugefügt. Dabei wird in der Konsole eine Warnung angezeigt.
Wählen Sie in der IAM-Konsole Roles (Rollen) aus.
Wählen Sie Rolle erstellen aus.
Wählen Sie auf der Seite „Vertrauenswürdige Entitäten auswählen“ die Kachel AWS -Service und dann RDS aus, um die Auswahl zu öffnen.
Wählen Sie RDS – Add Role to Database (RDS – Rolle zu Datenbank hinzufügen) aus.
Wählen Sie Weiter aus. Suchen Sie auf der Seite „Add permissions“ (Berechtigungen hinzufügen) nach der im vorherigen Schritt erstellten Richtlinie und wählen Sie sie aus den aufgelisteten Richtlinien aus. Wählen Sie Next (Weiter) aus.
Next: Review (Weiter: Überprüfung). Geben Sie einen Namen und eine Beschreibung für die IAM-Rolle ein.
Öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Navigieren Sie zu dem AWS-Region Ort, an dem sich Ihr Aurora PostgreSQL-DB-Cluster befindet.
-
Wählen Sie im Navigationsbereich Datenbanken und dann den Aurora PostgreSQL-DB-Cluster aus, den Sie mit SageMaker KI verwenden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit) aus und scrollen Sie zum Abschnitt Manage IAM roles (IAM-Rollen verwalten) auf der Seite. Wählen Sie in der Auswahl Add IAM roles to this cluster (Diesem Cluster IAM-Rollen hinzufügen) die Rolle aus, die Sie in den vorherigen Schritten erstellt haben. Wählen Sie in der Funktionsauswahl SageMaker AI und dann Rolle hinzufügen aus.
Die Rolle ist (mit ihrer Richtlinie) dem DB-Cluster von Aurora PostgreSQL zugeordnet. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste „Current IAM roles for this cluster“ (Aktuelle IAM-Rollen für diesen Cluster) angezeigt.
Das IAM-Setup für SageMaker KI ist abgeschlossen. Fahren Sie mit der Einrichtung von Aurora PostgreSQL für Aurora Machine Learning fort, indem Sie die Erweiterung wie unter Installieren der Aurora-Erweiterung für Machine Learning beschrieben installieren.
Aurora PostgreSQL für die Verwendung von Amazon S3 für SageMaker KI einrichten (Fortgeschritten)
Um SageMaker KI mit Ihren eigenen Modellen zu verwenden, anstatt die von SageMaker AI bereitgestellten vorgefertigten Komponenten zu verwenden, müssen Sie einen Amazon Simple Storage Service (Amazon S3) -Bucket einrichten, den der Aurora PostgreSQL-DB-Cluster verwenden kann. Dies ist ein Thema für Fortgeschrittene und wird in diesem Benutzerhandbuch für Amazon Aurora nicht vollständig dokumentiert. Der allgemeine Prozess ist derselbe wie bei der Integration der SageMaker KI-Unterstützung, und zwar wie folgt.
Erstellen Sie die IAM-Richtlinie und -Rolle für Amazon S3.
Fügen Sie die IAM-Rolle und den Amazon-S3-Import oder -Export als Funktion auf der Registerkarte „Connectivity & security“ (Konnektivität und Sicherheit) Ihres DB-Clusters von Aurora PostgreSQL hinzu.
Fügen Sie den ARN der Rolle der benutzerdefinierten DB-Cluster-Parametergruppe für jeden Aurora-DB-Cluster hinzu.
Grundlegende Informationen zur Nutzung finden Sie unter Exportieren von Daten nach Amazon S3 für das SageMaker KI-Modelltraining (Fortgeschritten).
Installieren der Aurora-Erweiterung für Machine Learning
Die Aurora-Erweiterungen aws_ml 1.0 für maschinelles Lernen bieten zwei Funktionen, mit denen Sie Amazon Comprehend, SageMaker AI-Services, aufrufen können, und aws_ml 2.0 bieten zwei zusätzliche Funktionen, mit denen Sie Amazon Bedrock-Dienste aufrufen können. Durch die Installation der Erweiterung auf Ihrem DB-Cluster von Aurora PostgreSQL wird auch eine administrative Rolle für das Feature erstellt.
Anmerkung
Die Verwendung dieser Funktionen hängt davon ab, ob die IAM-Einrichtung für den Aurora-Service für maschinelles Lernen (Amazon Comprehend, SageMaker AI, Amazon Bedrock) abgeschlossen ist, wie unter beschrieben. Einrichten Ihres DB-Clusters von Aurora PostgreSQL zur Verwendung von Aurora Machine Learning
aws_comprehend.detect_sentiment – Sie verwenden diese Funktion, um Stimmungsanalysen auf Text anzuwenden, der in der Datenbank Ihres DB-Clusters von Aurora PostgreSQL gespeichert ist.
aws_sagemaker.invoke_endpoint — Sie verwenden diese Funktion in Ihrem SQL-Code, um mit dem KI-Endpunkt von Ihrem Cluster aus zu kommunizieren. SageMaker
aws_bedrock.invoke_model – Sie verwenden diese Funktion in Ihrem SQL-Code, um mit den Bedrock-Modellen aus Ihrem Cluster zu kommunizieren. Die Antwort dieser Funktion erfolgt im TEXT-Format. Wenn ein Modell also im JSON-Textformat antwortet, wird die Ausgabe dieser Funktion im Zeichenfolgenformat an den Endbenutzer weitergeleitet.
aws_bedrock.invoke_model_get_embeddings – Sie verwenden diese Funktion in Ihrem SQL-Code, um Bedrock-Modelle aufzurufen, die Ausgabeeinbettungen in einer JSON-Antwort zurückgeben. Dies kann genutzt werden, wenn Sie die direkt mit dem JSON-Key verknüpften Einbettungen extrahieren möchten, um die Antwort mit selbstverwalteten Workflows zu optimieren.
So richten Sie die Aurora-Erweiterung für Machine Learning in Ihrem DB-Cluster von Aurora PostgreSQL ein
Verwenden Sie
psql, um eine Verbindung mit der Writer-Instance Ihres DB-Clusters von Aurora PostgreSQL herzustellen. Stellen Sie eine Verbindung mit der entsprechenden Datenbank her, in der dieaws_ml-Erweiterung installiert werden soll.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
Durch das Installieren der aws_ml-Erweiterungen werden auch die administrative aws_ml-Rolle und drei neue Schemas wie folgt erstellt.
aws_comprehend– Schema für den Amazon-Comprehend-Service und die Quelle derdetect_sentiment-Funktion (aws_comprehend.detect_sentiment).aws_sagemaker— Schema für den SageMaker AI-Service und Quelle der Funktion ().invoke_endpointaws_sagemaker.invoke_endpointaws_bedrock– Schema für den Amazon-Comprehend-Service und die Quelle der Funktioneninvoke_model(aws_bedrock.invoke_model)undinvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings).
Der Rolle rds_superuser wird die administrative Rolle aws_ml zugewiesen und wird damit zum OWNER dieser beiden Aurora-Schemas für Machine Learning. Damit andere Datenbankbenutzer auf die Aurora-Funktionen für Machine Learning zugreifen können, muss der rds_superuser EXECUTE-Berechtigungen für die Aurora-Funktionen für Machine Learning erteilen. Standardmäßig werden EXECUTE-Berechtigungen von PUBLIC für die Funktionen in den beiden Aurora-Schemata für Machine Learning widerrufen.
In einer Datenbankkonfiguration mit mehreren Mandanten können Sie verhindern, dass Mandanten auf Aurora-Funktionen für Machine Learning zugreifen, indem Sie REVOKE USAGE für das spezifische Aurora-Schema für Machine Learning verwenden, das Sie schützen möchten.
Verwenden von Amazon Bedrock mit Ihrem DB-Cluster von Aurora PostgreSQL
Für Aurora PostgreSQL bietet Aurora Machine Learning die folgende Amazon-Bedrock-Funktion für die Arbeit mit Ihren Textdaten. Diese Funktion ist erst verfügbar, nachdem Sie die Erweiterung aws_ml 2.0 installiert und alle Einrichtungsvorgänge abgeschlossen haben. Weitere Informationen finden Sie unter Einrichten Ihres DB-Clusters von Aurora PostgreSQL zur Verwendung von Aurora Machine Learning.
- aws_bedrock.invoke_model
-
Diese Funktion verwendet Text im JSON-Format als Eingabe und verarbeitet ihn für eine Vielzahl von Modellen, die auf Amazon Bedrock gehostet werden, und gibt die JSON-Textantwort vom Modell zurück. Diese Antwort kann Texte, Bilder oder Einbettungen enthalten. Eine Zusammenfassung der Dokumentation der Funktion lautet wie folgt.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
Die Ein- und Ausgaben dieser Funktion sind wie folgt.
-
model_id– ID des Modells. content_type– Der Typ der Anforderung an das Bedrock-Modell.accept_type– Der vom Modell von Bedrock zu erwartende Antworttyp. Normalerweise application/JSON für die meisten Modelle.model_input– Eingabeaufforderungen; ein bestimmter Satz von Eingaben für das Modell in dem von content_type angegebenen Format. Weitere Informationen zu der Anfrage, die format/structure das Modell akzeptiert, finden Sie unter Inferenzparameter für Basismodelle.model_output– Die Ausgabe des Bedrock-Modells als Text.
Das folgende Beispiel zeigt, wie Sie mit invoke_model ein Modell von Anthropic Claude 2 für Bedrock aufrufen.
Beispiel: Eine einfache Abfrage mit Amazon-Bedrock-Funktionen
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
Die Modellausgabe kann in einigen Fällen auf Vektoreinbettungen verweisen. Da die Antwort je nach Modell unterschiedlich ist, kann eine weitere Funktion namens „invoke_model_get_embeddings“ genutzt werden, die genau wie „invoke_model“ funktioniert, die Einbettungen jedoch durch Angabe des entsprechenden JSON-Schlüssels ausgibt.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
Die Ein- und Ausgaben dieser Funktion sind wie folgt.
-
model_id– ID des Modells. content_type– Der Typ der Anforderung an das Bedrock-Modell. Hier ist „accept_type“ auf den Standardwertapplication/jsonfestgelegt.model_input– Eingabeaufforderungen; ein bestimmter Satz von Eingaben für das Modell in dem von content_type angegebenen Format. Weitere Informationen zu der Anforderung, die format/structure das Modell akzeptiert, finden Sie unter Inferenzparameter für Fundamentmodelle.json_key– Verweis auf das Feld, aus dem die Einbettung extrahiert werden soll. Dies kann variieren, wenn sich das Einbettungsmodell ändert.-
model_output– Die Ausgabe des Bedrock-Modells als Array von Einbettungen mit 16-Bit-Dezimalstellen.
Das folgende Beispiel zeigt, wie eine Einbettung mit dem Modell Titan Embeddings G1 — Text Embedding für den Begriff PostgreSQL-Überwachungsansichten generiert wird. I/O
Beispiel: Eine einfache Abfrage mit Amazon-Bedrock-Funktionen
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Verwenden von Amazon Comprehend mit Ihrem DB-Cluster von Aurora PostgreSQL
Für Aurora PostgreSQL bietet Aurora Machine Learning die folgende Amazon-Comprehend-Funktion für die Arbeit mit Ihren Textdaten. Diese Funktion ist erst verfügbar, nachdem Sie die aws_ml-Erweiterung installiert und alle Einrichtungsvorgänge abgeschlossen haben. Weitere Informationen finden Sie unter Einrichten Ihres DB-Clusters von Aurora PostgreSQL zur Verwendung von Aurora Machine Learning.
- aws_comprehend.detect_sentiment
-
Diese Funktion nimmt Text als Eingabe und wertet aus, ob der Text eine positive, negative, neutrale oder gemischte emotionale Haltung hat. Sie gibt diese Stimmung zusammen mit einem Wahrscheinlichkeitsgrad für ihre Bewertung aus. Eine Zusammenfassung der Dokumentation der Funktion lautet wie folgt.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
Die Ein- und Ausgaben dieser Funktion sind wie folgt.
-
input_text– Der Text zur Bewertung und Zuordnung der Stimmung (negativ, positiv, neutral, gemischt). language_code– Die Sprache des identifizierteninput_textunter Verwendung der aus zwei Buchstaben bestehenden ISO-639-1-Kennung mit regionalem Untertag (nach Bedarf) bzw. dem aus drei Buchstaben bestehenden ISO-639-2-Code. Zum Beispiel istender Code für Englisch,zhder Code für vereinfachtes Chinesisch. Weitere Informationen finden Sie unter Unterstützte Sprachen im Amazon-Comprehend-Entwicklerhandbuch.max_rows_per_batch– Die maximale Anzahl von Zeilen pro Batch für die Verarbeitung im Batch-Modus. Weitere Informationen finden Sie unter Grundlagen zum Batch-Modus und zu den Aurora-Funktionen für Machine Learning.sentiment– Die Stimmung des Eingabetexts, die als POSITIV, NEGATIV, NEUTRAL oder GEMISCHT identifiziert wird.confidence– Der Grad der Wahrscheinlichkeit für die Genauigkeit der angegebenensentiment. Die Werte können zwischen 0,0 und 1,0 liegen.
Nachstehend finden Sie Beispiele zur Verwendung dieser Funktion.
Beispiel: Eine einfache Abfrage mit Amazon-Comprehend-Funktionen
Hier ist ein Beispiel für eine einfache Abfrage, die diese Funktion aufruft, um die Kundenzufriedenheit mit Ihrem Support-Team zu bewerten. Angenommen, Sie haben eine Datenbanktabelle (support), in der Kundenfeedback nach jeder Supportanfrage gespeichert wird. Diese Beispielabfrage wendet die aws_comprehend.detect_sentiment-Funktion auf den Text in der feedback-Spalte der Tabelle an und gibt die Stimmung und den Wahrscheinlichkeitsgrad für diese Stimmung aus. Diese Abfrage gibt Ergebnisse außerdem in absteigender Reihenfolge aus.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Damit vermieden wird, dass Sie für die Stimmungserkennung mehr als einmal pro Tabellenzeile belastet werden, können Sie die Ergebnisse materialisieren. Tun Sie dies in den relevanten Zeilen. Beispielsweise werden die Notizen des Klinikers aktualisiert, sodass nur Personen auf Französisch (fr) die Stimmungserkennungsfunktion verwenden.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Weitere Informationen zur Optimierung Ihrer Funktionsaufrufe finden Sie unter Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora PostgreSQL.
SageMaker KI mit Ihrem Aurora PostgreSQL-DB-Cluster verwenden
Nachdem Sie Ihre SageMaker KI-Umgebung eingerichtet und wie unter beschrieben in Aurora PostgreSQL integriert habenAurora PostgreSQL für die Verwendung von Amazon AI einrichten SageMaker , können Sie mithilfe der Funktion Operationen aufrufen. aws_sagemaker.invoke_endpoint Die aws_sagemaker.invoke_endpoint-Funktion stellt nur eine Verbindung mit einem Modellendpunkt in derselben AWS-Region her. Wenn Ihre Datenbank-Instance über mehrere Replikate verfügt, stellen Sie AWS-Regionen
sicher, dass Sie jedes SageMaker KI-Modell einrichten und für alle bereitstellen. AWS-Region
Aufrufe von aws_sagemaker.invoke_endpoint werden mithilfe der IAM-Rolle authentifiziert, die Sie eingerichtet haben, um Ihren Aurora PostgreSQL-DB-Cluster mit dem SageMaker AI-Service und dem Endpunkt zu verknüpfen, den Sie während des Einrichtungsvorgangs angegeben haben. SageMaker Die Endpunkte des KI-Modells sind auf ein einzelnes Konto beschränkt und nicht öffentlich. Die endpoint_name URL enthält nicht die Konto-ID. SageMaker AI bestimmt die Konto-ID anhand des Authentifizierungstoken, das von der SageMaker AI-IAM-Rolle der Datenbankinstanz bereitgestellt wird.
- aws_sagemaker.invoke_endpoint
Diese Funktion verwendet den SageMaker AI-Endpunkt als Eingabe und die Anzahl der Zeilen, die als Stapel verarbeitet werden sollen. Sie verwendet auch die verschiedenen Parameter, die vom Endpunkt des SageMaker KI-Modells erwartet werden, als Eingabe. Die Referenzdokumentation dieser Funktion lautet wie folgt.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
Die Ein- und Ausgaben dieser Funktion sind wie folgt.
endpoint_name— Eine Endpunkt-URL, die AWS-Region—unabhängig ist.max_rows_per_batch– Die maximale Anzahl von Zeilen pro Batch für die Verarbeitung im Batch-Modus. Weitere Informationen finden Sie unter Grundlagen zum Batch-Modus und zu den Aurora-Funktionen für Machine Learning.model_input– Ein oder mehrere Eingabeparameter für das Modell. Dabei kann es sich um jeden Datentyp handeln, der vom SageMaker KI-Modell benötigt wird. Mit PostgreSQL können Sie bis zu 100 Eingabeparameter für eine Funktion angeben. Array-Datentypen müssen eindimensional sein, können aber so viele Elemente enthalten, wie vom SageMaker KI-Modell erwartet werden. Die Anzahl der Eingaben für ein SageMaker KI-Modell ist nur durch die SageMaker AI-Nachrichtengrößenbeschränkung von 6 MB begrenzt.model_output— Die Ausgabe des SageMaker KI-Modells als Text.
Erstellen einer benutzerdefinierten Funktion zum Aufrufen eines KI-Modells SageMaker
Erstellen Sie eine separate benutzerdefinierte Funktion, die aws_sagemaker.invoke_endpoint für jedes Ihrer SageMaker KI-Modelle aufgerufen wird. Ihre benutzerdefinierte Funktion stellt den SageMaker KI-Endpunkt dar, der das Modell hostet. Die aws_sagemaker.invoke_endpoint-Funktion wird innerhalb der benutzerdefinierten Funktion ausgeführt. Benutzerdefinierte Funktionen bieten viele Vorteile:
-
Sie können Ihrem SageMaker KI-Modell einen eigenen Namen geben, anstatt nur alle Ihre SageMaker KI-Modelle aufzurufen
aws_sagemaker.invoke_endpoint. -
Sie können die Modellendpunkt-URL an nur einer Stelle im SQL-Anwendungscode angeben.
-
Sie können
EXECUTE-Berechtigungen für jede Aurora-Funktion für Machine Learning unabhängig steuern. -
Sie können die Modellein- und Ausgabetypen mit SQL-Typen deklarieren. SQL erzwingt die Anzahl und Art der Argumente, die an Ihr SageMaker KI-Modell übergeben werden, und führt bei Bedarf eine Typkonvertierung durch. Die Verwendung von SQL-Typen führt auch
SQL NULLzu dem entsprechenden Standardwert, der von Ihrem SageMaker KI-Modell erwartet wird. -
Sie können die maximale Stapelgröße reduzieren, wenn Sie die ersten paar Zeilen etwas schneller zurückgeben möchten.
Um eine benutzerdefinierte Funktion anzugeben, verwenden Sie die SQL Data Definition Language (DDL)-Anweisung CREATE FUNCTION. Beim Definieren der Funktion geben Sie Folgendes an:
-
Die Eingabeparameter für das Modell.
-
Der spezifische SageMaker KI-Endpunkt, der aufgerufen werden soll.
-
Den Rückgabetyp.
Die benutzerdefinierte Funktion gibt die vom SageMaker KI-Endpunkt berechnete Inferenz zurück, nachdem das Modell mit den Eingabeparametern ausgeführt wurde. Das folgende Beispiel erstellt eine benutzerdefinierte Funktion für ein SageMaker KI-Modell mit zwei Eingabeparametern.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Beachten Sie Folgendes:
-
Die
aws_sagemaker.invoke_endpoint-Funktionseingabe kann ein oder mehrere Parameter eines beliebigen Datentyps sein. -
In diesem Beispiel wird ein INT-Ausgabetyp verwendet. Wenn Sie die Ausgabe von einem
varchar-Typ in einen anderen Typ umwandeln, muss sie in einen von PostgreSQL eingebauten skalaren Typ wieINTEGER,REAL,FLOAToderNUMERICumgewandelt werden. Weitere Informationen zu diesen Typen finden Sie unter Datentypenin der PostgreSQL-Dokumentation. -
Geben Sie
PARALLEL SAFEan, um die parallele Abfrageausführung zu aktivieren. Weitere Informationen finden Sie unter Verbessern von Antwortzeiten durch parallele Abfrageverarbeitung. -
Geben Sie
COST 5000an, um die Kosten für die Ausführung der Funktion zu schätzen. Verwenden Sie eine positive Zahl, welche die geschätzten Ausführungskosten für die Funktion in -Einheiten angibcpu_operator_cost.
Übergabe eines Arrays als Eingabe an ein SageMaker KI-Modell
Die aws_sagemaker.invoke_endpoint-Funktion kann bis zu 100 Eingabeparameter haben, was die Grenze für PostgreSQL-Funktionen ist. Wenn das SageMaker KI-Modell mehr als 100 Parameter desselben Typs benötigt, übergeben Sie die Modellparameter als Array.
Das folgende Beispiel definiert eine Funktion, die ein Array als Eingabe an das SageMaker KI-Regressionsmodell übergibt. Die Ausgabe wird in einen REAL-Wert umgewandelt.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Angabe der Batchgröße beim Aufrufen eines KI-Modells SageMaker
Im folgenden Beispiel wird eine benutzerdefinierte Funktion für ein SageMaker KI-Modell erstellt, die den Standardwert für die Batchgröße auf NULL setzt. Mit der Funktion können Sie auch eine andere Stapelgröße angeben, wenn Sie sie aufrufen.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Beachten Sie Folgendes:
-
Verwenden Sie den optionalen
max_rows_per_batch-Parameter, um die Anzahl der Zeilen für einen Stapelmodus-Funktionsaufruf zu steuern. Wenn Sie den Wert NULL verwenden, wählt der Abfrageoptimierer automatisch die maximale Stapelgröße aus. Weitere Informationen finden Sie unter Grundlagen zum Batch-Modus und zu den Aurora-Funktionen für Machine Learning. -
Standardmäßig wird die Übergabe von NULL als Parameterwert in eine leere Zeichenfolge übersetzt, bevor sie an SageMaker AI übergeben wird. Für dieses Beispiel haben die Eingaben unterschiedliche Typen.
-
Wenn Sie über eine Nicht-Texteingabe oder eine Texteingabe verfügen, die standardmäßig auf einen anderen Wert als eine leere Zeichenfolge gesetzt werden muss, verwenden Sie die
COALESCE-Anweisung. Verwenden SieCOALESCE, um NULL in den gewünschten Nullersetzungswert im Aufruf vonaws_sagemaker.invoke_endpointzu übersetzen. Für denamount-Parameter in diesem Beispiel wird ein NULL-Wert in 0,0 konvertiert.
Aufrufen eines SageMaker KI-Modells mit mehreren Ausgaben
Das folgende Beispiel erstellt eine benutzerdefinierte Funktion für ein SageMaker KI-Modell, das mehrere Ausgaben zurückgibt. Ihre Funktion muss die Ausgabe der aws_sagemaker.invoke_endpoint-Funktion in einen entsprechenden Datentyp umwandeln. Beispielsweise können Sie den integrierten PostgreSQL-Punkttyp für (x,y)-Paare oder einen benutzerdefinierten zusammengesetzten Typ verwenden.
Diese benutzerdefinierte Funktion gibt Werte aus einem Modell zurück, das mehrere Ausgaben zurückgibt, indem ein zusammengesetzter Typ für die Ausgaben verwendet wird.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Verwenden Sie für den zusammengesetzten Typ Felder in der gleichen Reihenfolge wie sie in der Modellausgabe angezeigt werden und wandeln Sie die Ausgabe von aws_sagemaker.invoke_endpoint in den zusammengesetzten Typ um. Der Aufrufer kann die einzelnen Felder entweder nach Namen oder mit der PostgreSQL-".*"-Notation extrahieren.
Exportieren von Daten nach Amazon S3 für das SageMaker KI-Modelltraining (Fortgeschritten)
Wir empfehlen Ihnen, sich anhand der bereitgestellten Algorithmen und Beispiele mit Aurora Machine Learning und SageMaker KI vertraut zu machen, anstatt zu versuchen, Ihre eigenen Modelle zu trainieren. Weitere Informationen finden Sie unter Erste Schritte mit Amazon SageMaker AI
Um SageMaker KI-Modelle zu trainieren, exportieren Sie Daten in einen Amazon S3 S3-Bucket. Der Amazon S3 S3-Bucket wird von SageMaker KI verwendet, um Ihr Modell vor der Bereitstellung zu trainieren. Sie können Daten aus einem Aurora PostgreSQL-DB-Cluster abfragen und direkt in Textdateien speichern, die in einem Amazon S3-Bucket gespeichert sind. Dann SageMaker verwendet KI die Daten aus dem Amazon S3 S3-Bucket für das Training. Weitere Informationen zum Training von SageMaker KI-Modellen finden Sie unter Trainieren eines Modells mit Amazon SageMaker AI.
Anmerkung
Wenn Sie einen Amazon S3 S3-Bucket für SageMaker KI-Modelltraining oder Batch-Scoring erstellen, verwenden Sie sagemaker den Namen des Amazon S3 S3-Buckets. Weitere Informationen finden Sie unter Spezifizieren eines Amazon S3 S3-Buckets zum Hochladen von Trainingsdatensätzen und Speichern von Ausgabedaten im Amazon SageMaker AI Developer Guide.
Weitere Informationen zum Exportieren der Daten finden Sie unter Exportieren von Daten aus einem/einer Aurora PostgreSQL-DB-Cluster zu Amazon S3.
Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora PostgreSQL
Die Amazon Comprehend- und SageMaker KI-Services erledigen die meiste Arbeit, wenn sie von einer Aurora-Funktion für maschinelles Lernen aufgerufen werden. Das bedeutet, dass Sie diese Ressourcen nach Bedarf unabhängig voneinander skalieren können. Für Ihren DB-Cluster von Aurora PostgreSQL können Sie Ihre Funktionsaufrufe so effizient wie möglich gestalten. Im Folgenden finden Sie einige Leistungsaspekte, die Sie bei der Arbeit mit Aurora Machine Learning und Aurora PostgreSQL beachten sollten.
Themen
Grundlagen zum Batch-Modus und zu den Aurora-Funktionen für Machine Learning
Normalerweise führt PostgreSQL Funktionen zeilenweise aus. Aurora Machine Learning kann diesen Overhead reduzieren, indem die Aufrufe an den externen Aurora-Service für Machine Learning für viele Zeilen in Batches mit einem Ansatz kombiniert werden, der als Ausführung im Batch-Modus bezeichnet wird. Im Batch-Modus empfängt Aurora Machine Learning die Antworten für einen Batch von Eingabezeilen und sendet dann die Antworten eine Zeile nach der anderen an die laufende Abfrage zurück. Diese Optimierung verbessert den Durchsatz Ihrer Aurora-Abfragen, ohne den PostgreSQL-Abfrageoptimierer zu beschränken.
Aurora verwendet automatisch den Stapelmodus, wenn die Funktion aus der SELECT-Liste, einer WHERE-Klausel oder einer HAVING-Klausel referenziert wird. Beachten Sie, dass einfache CASE-Ausdrücke der obersten Ebene für die Ausführung im Stapelmodus geeignet sind. Gesuchte CASE-Ausdrücke der obersten Ebene sind auch für die Ausführung im Stapelmodus berechtigt, vorausgesetzt, die erste WHEN-Klausel ist ein einfaches Prädikat mit einem Stapelmodus-Funktionsaufruf.
Ihre benutzerdefinierte Funktion muss eine LANGUAGE SQL-Funktion sein und sollte PARALLEL SAFE und COST 5000 angeben.
Funktionsmigration von der SELECT-Anweisung zur FROM-Klausel
Normalerweise wird eine aws_ml-Funktion, die für die Ausführung im Stapelmodus berechtigt ist, automatisch von Aurora in die FROM-Klausel migriert.
Die Migration berechtigter Funktionen im Stapelmodus in die FROM-Klausel kann manuell auf Abfrageebene untersucht werden. Dazu verwenden Sie EXPLAIN-Anweisungen (und ANALYZE und VERBOSE) und finden unter jedem im Stapelmodus die "Stapelverarbeitungs"-Informatione Function Scan. Sie können EXPLAIN (mit VERBOSE) auch verwenden, ohne die Abfrage auszuführen. Sie beobachten dann, ob die Aufrufe der Funktion als Function
Scan unter einem eingebetteten Loop-Join erscheinen, der nicht in der ursprünglichen Anweisung angegeben wurde.
Im folgenden Beispiel zeigt der eingebettete Loop-Join-Operator im Plan, dass Aurora die anomaly_score-Funktion migriert hat. Sie migrierte diese Funktion von der SELECT-Liste in die FROM-Klausel, wo sie für die Ausführung im Stapelmodus berechtigt ist.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Um die Ausführung im Stapelmodus zu deaktivieren, setzen Sie den apg_enable_function_migration-Parameter auf false. Dies verhindert die Migration von aws_ml-Funktionen von der SELECT in die FROM-Klausel. Nachfolgend wird gezeigt, wie Sie dies tun.
SET apg_enable_function_migration = false;Der apg_enable_function_migration-Parameter ist ein GUC-Parameter (Grand Unified Configuration), der von der Aurora PostgreSQL apg_plan_mgmt-Erweiterung für die Abfrageplanverwaltung erkannt wird. Um die Funktionsmigration in einer Sitzung zu deaktivieren, speichern Sie den resultierenden Plan mithilfe der Abfrageplanverwaltung als approved-Plan. Zur Laufzeit erzwingt die Abfrageplanverwaltung den approved-Plan mit seiner apg_enable_function_migration-Einstellung. Diese Erzwingung erfolgt unabhängig von der Einstellung des apg_enable_function_migration-GUC-Parameters. Weitere Informationen finden Sie unter Verwalten von Abfrageausführungsplänen für Aurora PostgreSQL.
Verwenden des max_rows_per_batch-Parameters
Sowohl die aws_comprehend.detect_sentiment- als auch die aws_sagemaker.invoke_endpoint-Funktion verfügen über einen max_rows_per_batch-Parameter. Dieser Parameter gibt die Anzahl der Zeilen an, die an den Aurora-Service für Machine Learning gesendet werden können. Je größer der von Ihrer Funktion verarbeitete Datensatz ist, umso größer kann die Batch-Größe gewählt werden.
Funktionen im Batch-Modus verbessern die Effizienz, indem sie Batches von Zeilen erstellen, welche die Kosten der Aurora Machine Learning-Funktionsaufrufe über eine große Anzahl von Zeilen verteilen. Wenn jedoch eine SELECT-Anweisung aufgrund einer LIMIT-Klausel früh beendet wird, kann der Stapel über mehr Zeilen konstruiert werden, als die Abfrage verwendet. Dieser Ansatz kann zu zusätzlichen Gebühren für Ihr Konto führen. AWS Um die Vorteile der Ausführung im Stapelmodus zu nutzen, aber das Erstellen zu großer Stapel zu vermeiden, verwenden Sie einen kleineren Wert für den max_rows_per_batch-Parameter in Ihren Funktionsaufrufen.
Wenn Sie eine EXPLAIN (VERBOSE, ANALYZE) einer Abfrage ausführen, welche die Ausführung im Stapelmodus verwendet, sehen Sie einen FunctionScan-Operator, der unterhalb eines eingebetteten Loop-Joins ist. Die Anzahl der von EXPLAIN gemeldeten Schleifen entspricht der Angabe, wie oft eine Zeile vom FunctionScan-Operator abgerufen wurde. Wenn eine Anweisung eine LIMIT-Klausel verwendet, ist die Anzahl der Abrufe konsistent. Um die Größe des Stapels zu optimieren, setzen Sie den max_rows_per_batch-Parameter auf diesen Wert. Wenn jedoch die Funktion im Stapelmodus in einem Prädikat in der WHERE-Klausel oder HAVING-Klausel referenziert wird, können Sie die Anzahl der Abrufe wahrscheinlich nicht im Voraus kennen. Verwenden Sie in diesem Fall die Schleifen als Richtlinie und experimentieren Sie mit max_rows_per_batch, um eine Einstellung zu finden, welche die Leistung optimiert.
Überprüfen der Ausführung im Stapelmodus
Um festzustellen, ob eine Funktion im Batch-Modus ausgeführt wurde, verwenden Sie EXPLAIN ANALYZE. Wenn die Ausführung im Stapelmodus verwendet wurde, enthält der Abfrageplan die Informationen in einem Abschnitt "Stapelverarbeitung".
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273In diesem Beispiel gab es 1 Stapel, der 3.333 Zeilen enthielt, deren Verarbeitung 146,273 ms dauerte. Der Abschnitt "Stapelverarbeitung" zeigt Folgendes:
-
Wie viele Stapel es für diese Scan-Operation der Funktion gab
-
Die durchschnittliche, minimale und maximale Stapelgröße
-
Die durchschnittliche, minimale und maximale Stapel-Ausführungszeit
In der Regel ist der letzte Stapel kleiner als der Rest, was häufig zu einer minimalen Stapelgröße führt, die viel kleiner als der Durchschnitt ist.
Um die ersten Zeilen schneller zurückzugeben, setzen Sie den max_rows_per_batch-Parameter auf einen kleineren Wert.
Um die Anzahl der Aufrufe im Stapelmodus an den ML-Service zu reduzieren, wenn Sie ein LIMIT in Ihrer benutzerdefinierten Funktion verwenden, setzen Sie den max_rows_per_batch-Parameter auf einen kleineren Wert.
Verbessern von Antwortzeiten durch parallele Abfrageverarbeitung
Damit Sie möglichst schnell Ergebnisse aus einer großen Anzahl von Zeilen erhalten, können Sie die parallele Abfrageverarbeitung mit der Verarbeitung im Batch-Modus kombinieren. Sie können die parallele Abfrageverarbeitung für SELECT-, CREATE TABLE AS SELECT- und CREATE
MATERIALIZED VIEW-Anweisungen verwenden.
Anmerkung
PostgreSQL unterstützt noch keine parallele Abfrage für DML-Anweisungen (Data Manipulation Language).
Die parallele Abfrageverarbeitung erfolgt sowohl innerhalb der Datenbank als auch innerhalb des ML-Services. Die Anzahl der Kerne in der Instance-Klasse der Datenbank begrenzt den Parallelitätsgrad, der während der Abfrageausführung verwendet werden kann. Der Datenbankserver kann einen Ausführungsplan für parallele Abfragen erstellen, der die Aufgabe unter einer Gruppe von parallelen Workern partitioniert. Dann kann jeder dieser Worker Stapelanforderungen erstellen, die Zehntausende von Zeilen enthalten (oder so viele, wie es von jedem Service erlaubt ist).
Die gebündelten Anfragen aller parallel Worker werden an den SageMaker KI-Endpunkt gesendet. Der Grad der Parallelität, den der Endpunkt unterstützen kann, hängt von der Anzahl und Art der Instances ab, die ihn unterstützen. Für K Grade der Parallelität benötigen Sie eine Datenbank-Instance-Klasse mit mindestens K Kernen. Außerdem müssen Sie den SageMaker KI-Endpunkt für Ihr Modell so konfigurieren, dass er über K Anfangsinstanzen einer ausreichend leistungsstarken Instanzklasse verfügt.
Zur Nutzung der parallelen Abfrageverarbeitung können Sie den parallel_workers-Speicherparameter der Tabelle festlegen, welche die Daten enthält, die Sie übergeben möchten. Sie setzen parallel_workers auf eine Funktion im Stapelmodus wie aws_comprehend.detect_sentiment. Wenn der Optimierer einen parallelen Abfrageplan wählt, können die AWS ML-Dienste sowohl im Batch als auch parallel aufgerufen werden.
Sie können die folgenden Parameter mit der aws_comprehend.detect_sentiment-Funktion verwenden, um einen Plan mit 4-Wege-Parallelität zu erhalten. Wenn Sie einen der beiden folgenden Parameter ändern, müssen Sie die Datenbank-Instance neu starten, damit die Änderungen wirksam werden.
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Weitere Informationen zum Steuern paralleler Abfragen finden Sie unter Parallele Pläne
Verwenden von materialisierten Ansichten und materialisierten Spalten
Wenn Sie einen AWS Service wie SageMaker AI oder Amazon Comprehend aus Ihrer Datenbank aufrufen, wird Ihr Konto gemäß der Preispolitik dieses Dienstes belastet. Um die Gebühren für Ihr Konto zu minimieren, können Sie das Ergebnis des Aufrufs des AWS Dienstes in einer materialisierten Spalte materialisieren, sodass der AWS Service nicht mehr als einmal pro Eingabezeile aufgerufen wird. Wenn gewünscht, können Sie eine materializedAt-Zeitstempelspalte hinzufügen, um die Zeit aufzuzeichnen, zu der die Spalten materialisiert wurden.
Die Latenz einer gewöhnlichen einzeiligen INSERT-Anweisung ist in der Regel viel geringer als die Latenz beim Aufrufen einer Funktion im Stapelmodus. Daher können Sie möglicherweise die Latenzanforderungen Ihrer Anwendung nicht erfüllen, wenn Sie die Funktion im Stapelmodus für jede einzeilige INSERT aufrufen, die Ihre Anwendung ausführt. Um das Ergebnis des Aufrufs eines AWS Dienstes in einer materialisierten Spalte zu materialisieren, müssen Hochleistungsanwendungen in der Regel die materialisierten Spalten auffüllen. Dazu geben sie regelmäßig eine UPDATE-Anweisung aus, die gleichzeitig für einen großen Stapel von Zeilen ausgeführt wird.
UPDATE führt eine Sperre auf Zeilenebene durch, die sich auf eine laufende Anwendung auswirken kann. Sie müssen also möglicherweise SELECT ... FOR UPDATE SKIP LOCKED oder MATERIALIZED
VIEW verwenden.
Analyseabfragen, die mit einer großen Anzahl von Zeilen in Echtzeit arbeiten, können die Materialisierung im Batch-Modus mit der Echtzeitverarbeitung kombinieren. Dazu fügen diese Abfragen eine UNION ALL der vormaterialisierten Ergebnisse mit einer Abfrage über die Zeilen zusammen, die noch keine materialisierten Ergebnisse haben. In einigen Fällen wird eine solche UNION ALL an mehreren Stellen benötigt oder die Abfrage wird von einer Drittanbieteranwendung generiert. Wenn ja, können Sie eine VIEW erstellen, um die UNION ALL-Operation zu kapseln, damit dieses Detail nicht für den Rest der SQL-Anwendung verfügbar gemacht wird.
Sie können eine materialisierte Ansicht verwenden, um die Ergebnisse einer beliebigen SELECT-Anweisung rechtzeitig zu einem Snapshot zu materialisieren. Sie können sie auch verwenden, um die materialisierte Ansicht jederzeit in der Zukunft zu aktualisieren. Derzeit unterstützt PostgreSQL keine inkrementelle Aktualisierung, so dass jedes Mal, wenn die materialisierte Ansicht aktualisiert wird, die materialisierte Ansicht vollständig neu berechnet wird.
Sie können materialisierte Ansichten mit der CONCURRENTLY-Option aktualisieren, die den Inhalt der materialisierten Ansicht aktualisiert, ohne eine exklusive Sperre durchzuführen. Dadurch kann eine SQL-Anwendung aus der materialisierten Ansicht lesen, während sie aktualisiert wird.
Überwachung von Aurora Machine Learning
Sie können die aws_ml-Funktionen überwachen, indem Sie den track_functions-Parameter in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe auf all festlegen. Standardmäßig ist dieser Parameter auf pl eingestellt, was bedeutet, dass nur „procedure-language“-Funktionen verfolgt werden. Wenn Sie diese Einstellung in all ändern, werden auch die aws_ml-Funktionen verfolgt. Weitere Informationen finden Sie unter Laufzeitstatistik
Informationen zur Überwachung der Leistung der SageMaker KI-Operationen, die von Aurora-Funktionen für maschinelles Lernen aufgerufen werden, finden Sie unter Monitor Amazon SageMaker AI im Amazon SageMaker AI Developer Guide.
Wenn track_functions auf all festgelegt ist, können Sie die pg_stat_user_functions-Ansicht abfragen, um Statistiken über die Funktionen zu erhalten, die Sie definieren und zum Aufrufen von Aurora-Services für Machine Learning verwenden. Die Ansicht gibt die Anzahl der calls, total_time und self_time für jede Funktion an.
Wenn Sie die Statistiken für die aws_sagemaker.invoke_endpoint- und aws_comprehend.detect_sentiment-Funktionen anzeigen möchten, können Sie die Ergebnisse mit der folgenden Abfrage nach Schemanamen filtern.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Gehen Sie wie folgt vor, um die Statistiken zu löschen.
SELECT pg_stat_reset();
Sie können die Namen Ihrer SQL-Funktionen, die die aws_sagemaker.invoke_endpoint-Funktion aufrufen, abrufen, indem Sie den pg_proc-Systemkatalog von PostgreSQL abfragen. Dieser Katalog speichert Informationen zu Funktionen, Prozeduren und mehr. Weitere Informationen finden Sie unter pg_procproname) zu erhalten, deren Quelle (prosrc) den Text invoke_endpoint enthält.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
