Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wie Lambda Datensätze aus Stream- und warteschlangenbasierten Ereignisquellen verarbeitet
Ein Zuordnung von Ereignisquellen ist eine Lambda-Ressource, die Elemente aus Stream- und Warteschlangen-basierten Diensten liest und eine Funktion mit Stapeln von Datensätzen aufruft. Innerhalb einer Zuordnung von Ereignisquellen fragen Ressourcen, sogenannte Event-Poller, aktiv nach neuen Nachrichten ab und rufen Funktionen auf. Standardmäßig skaliert Lambda Ereignisabfragen automatisch, aber für bestimmte Ereignisquellentypen können Sie den Bereitstellungsmodus verwenden, um die Mindest- und Höchstanzahl von Event-Pollern zu steuern, die für Ihre Zuordnung von Ereignisquellen vorgesehen sind.
Die folgenden Dienste verwenden Zuordnungen von Ereignisquellen, um Lambda-Funktionen aufzurufen:
Warnung
Zuordnung von Lambda-Ereignisquellen verarbeiten jedes Ereignis mindestens einmal und es kann zu einer doppelten Verarbeitung von Datensätzen kommen. Um mögliche Probleme im Zusammenhang mit doppelten Ereignissen zu vermeiden, empfehlen wir Ihnen dringend, Ihren Funktionscode idempotent zu machen. Weitere Informationen finden Sie im Knowledge Center unter Wie mache ich meine Lambda-Funktion idempotent
Wie unterscheiden sich Zuordnungen von Ereignisquellen von direkten Auslösern
Einige AWS-Services können Lambda-Funktionen mithilfe von Triggern direkt aufrufen. Diese Dienste leiten Ereignisse an Lambda weiter und die Funktion wird sofort aufgerufen, wenn das angegebene Ereignis eintritt. Trigger eignen sich für diskrete Ereignisse und die Verarbeitung in Echtzeit. Wenn Sie mit der Lambda-Konsole einen Trigger erstellen, interagiert die Konsole mit dem entsprechenden AWS Dienst, um die Ereignisbenachrichtigung für diesen Dienst zu konfigurieren. Der Auslöser wird tatsächlich von dem Dienst gespeichert und verwaltet, der die Ereignisse generiert, nicht von Lambda. Hier sind einige Beispiele für Dienste, die Auslöser zum Aufrufen von Lambda-Funktionen verwenden:
-
Amazon Simple Storage Service (Amazon S3): Ruft eine Funktion auf, wenn ein Objekt in einem Bucket erstellt, gelöscht oder geändert wird. Weitere Informationen finden Sie unter Tutorial: Verwenden eines Amazon-S3-Auslösers zum Aufrufen einer Lambda-Funktion.
-
Amazon Simple Notification Service (Amazon SNS): Ruft eine Funktion auf, wenn eine Nachricht in einem SNS-Thema veröffentlicht wird. Weitere Informationen finden Sie unter Tutorial: Verwenden AWS Lambda mit Amazon Simple Notification Service.
-
Amazon API Gateway: Ruft eine Funktion auf, wenn eine API-Anfrage an einen bestimmten Endpunkt gestellt wird. Weitere Informationen finden Sie unter Aufrufen einer Lambda-Funktion über einen Amazon API Gateway-Endpunkt.
Zuordnungen von Ereignisquellen sind Lambda-Ressourcen, die innerhalb des Lambda-Service erstellt und verwaltet werden. Zuordnungen von Ereignisquellen sind für die Verarbeitung umfangreicher Streaming-Daten oder Nachrichten aus Warteschlangen konzipiert. Die stapelweise Verarbeitung von Datensätzen aus einem Stream oder einer Warteschlange ist effizienter als die Verarbeitung einzelner Datensätze.
Batching-Verhalten
Standardmäßig batcht eine Ereignisquellenzuordnung Datensätze in einer einzigen Nutzlast, die Lambda an Ihre Funktion sendet. Um das Batching-Verhalten zu optimieren, können Sie ein Batching-Fenster (MaximumBatchingWindowInSeconds) und eine Batch-Größe (BatchSize) konfigurieren. Ein Batch-Fenster ist die maximale Zeitspanne zur Erfassung von Datensätzen in einer einzigen Nutzlast. Eine Batch-Größe ist die maximale Anzahl von Datensätzen in einem einzigen Batch. Lambda ruft Ihre Funktion auf, wenn eines der folgenden drei Kriterien erfüllt ist:
-
Das Batching-Fenster erreicht seinen Maximalwert. Das standardmäßige Batch-Fensterverhalten unterscheidet sich je nach Ereignisquelle.
Für Kinesis-, DynamoDB- und Amazon SQS SQS-Ereignisquellen: Das Standard-Batch-Fenster beträgt 0 Sekunden. Das bedeutet, dass Lambda Ihre Funktion aufruft, sobald Datensätze verfügbar sind. Um ein Batching-Fenster festzulegen, konfigurieren Sie
MaximumBatchingWindowInSeconds. Sie können diesen Parameter auf einen beliebigen Wert zwischen 0 und 300 Sekunden in Schritten von 1 Sekunde einstellen. Wenn Sie ein Stapelverarbeitungsfenster konfigurieren, beginnt das nächste Fenster, sobald der vorherige Funktionsaufruf abgeschlossen ist.Für Amazon-MSK-, selbstverwaltete Apache-Kafka-, Amazon-MQ- und Amazon-DocumentDB-Ereignisquellen: Das standardmäßige Batching-Fenster beträgt 500 ms. Sie können
MaximumBatchingWindowInSecondsauf einen beliebigen Wert von 0 Sekunden bis 300 Sekunden in Sekundenschritten einstellen. Wenn Sie im Bereitstellungsmodus für Kafka-Zuordnungen von Ereignisquellen ein Batching-Fenster konfigurieren, beginnt das nächste Fenster, sobald der vorherige Batch abgeschlossen ist. Wenn Sie ein Batching-Fenster konfigurieren, beginnt das nächste Fenster, sobald der vorherige Funktionsaufruf abgeschlossen ist. Um die Latenz bei der Verwendung von Kafka-Zuordnungen von Ereignisquellen im Bereitstellungsmodus zu minimieren, setzen SieMaximumBatchingWindowInSecondsauf 0. Diese Einstellung stellt sicher, dass Lambda unmittelbar nach Abschluss des aktuellen Funktionsaufrufs mit der Verarbeitung des nächsten Batches beginnt. Weitere Informationen zur Verarbeitung mit niedriger Latenz finden Sie unter Niedrige Latenz für Apache-Kafka.-
Für die Ereignisquellen Amazon MQ und Amazon DocumentDB: Das standardmäßige Batching-Fenster beträgt 500 ms. Sie können
MaximumBatchingWindowInSecondsauf einen beliebigen Wert von 0 Sekunden bis 300 Sekunden in Sekundenschritten einstellen. Ein Batch-Fenster beginnt, sobald der erste Datensatz eintrifft.Anmerkung
Da Sie
MaximumBatchingWindowInSecondsnur in Sekundenschritten ändern können, können Sie nicht zu dem Standard-Batch-Fenster von 500 ms zurückkehren, nachdem Sie es geändert haben. Um das Standard-Batch-Fenster wiederherzustellen, müssen Sie eine neue Ereignisquellenzuordnung erstellen.
-
Die Batch-Größe wird erreicht. Die minimale Batch-Größe beträgt 1. Die Standard- und die maximale Batch-Größe hängen von der Ereignisquelle ab. Weitere Informationen zu diesen Werten finden Sie unter BatchSize-Spezifikation für die
CreateEventSourceMapping-API-Operation. -
Die Nutzlastgröße erreicht 6 MB. Sie können dieses Limit nicht ändern.
Das folgende Diagramm verdeutlicht diese Bedingungen. Angenommen, ein Batch-Fenster beginnt bei t = 7 Sekunden. Im ersten Szenario erreicht das Batch-Fenster sein Maximum von 40 Sekunden bei t = 47 Sekunden nach dem Erfassen von 5 Datensätzen. Im zweiten Szenario erreicht die Batch-Größe 10, bevor das Batch-Fenster abläuft, sodass das Batch-Fenster früh endet. Im dritten Szenario wird die maximale Nutzlastgröße erreicht, bevor das Batch-Fenster abläuft, sodass das Batch-Fenster frühzeitig endet.
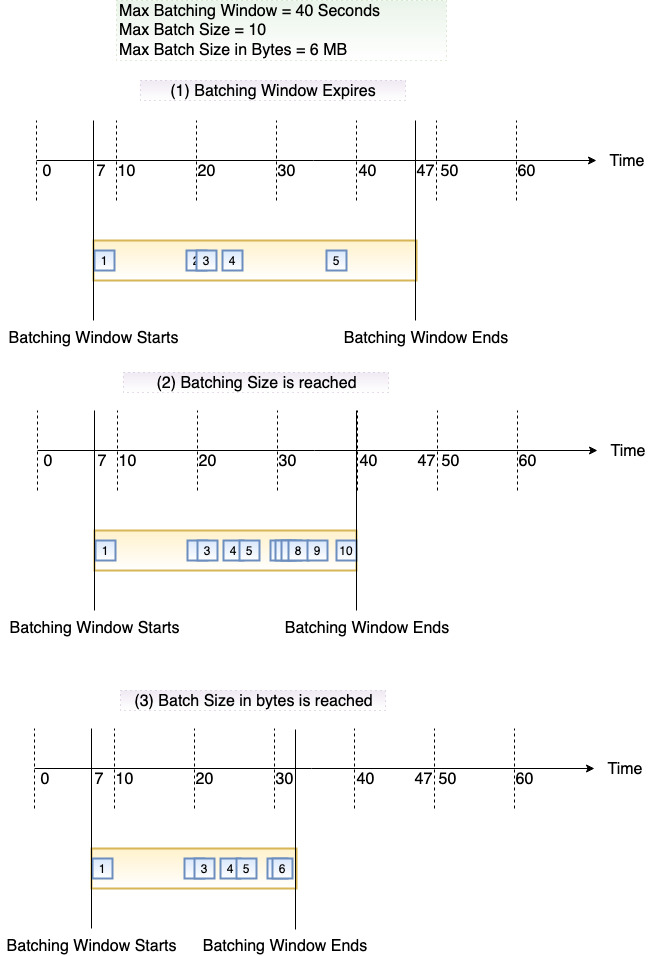
Wir empfehlen Ihnen, mit verschiedenen Stapel- und Datensatzgrößen zu testen, damit die Abfragefrequenz jeder Ereignisquelle darauf abgestimmt ist, wie schnell Ihre Funktion ihre Aufgabe erledigen kann. Der CreateEventSourceMappingBatchSizeParameter steuert die maximale Anzahl von Datensätzen, die bei jedem Aufruf an Ihre Funktion gesendet werden können. Eine höhere Stapelgröße kann den mit dem Aufruf-Overhead über eine größere Datensatzgruppe hinweg oft effizienter verarbeiten und Ihren Durchsatz erhöhen.
Lambda wartet mit dem Senden des nächsten zu verarbeitenden Stapels nicht, bis ggf. konfigurierte Erweiterungen abgeschlossen sind. Anders ausgedrückt: Ihre Erweiterungen werden möglicherweise weiter ausgeführt, während Lambda den nächsten Stapel von Datensätzen verarbeitet. Dies kann zu Drosselungsproblemen führen, wenn Sie gegen eine Einstellung oder gegen einen Grenzwert im Zusammenhang mit der Parallelität Ihres Kontos verstoßen. Um zu erkennen, ob möglicherweise ein Problem vorliegt, müssen Sie Ihre Funktionen überwachen sowie überprüfen, ob für Ihre Zuordnung von Ereignisquellen unerwartet hohe Parallelitätsmetriken vorliegen. Aufgrund der kurzen Zeit zwischen den Aufrufen kann Lambda kurzzeitig eine höhere Gleichzeitigkeitsnutzung als die Anzahl der Shards melden. Dies kann sogar für Lambda-Funktionen ohne Erweiterungen gelten.
Wenn Ihre Funktion einen Fehler zurückgibt, verarbeitet die Ereignisquellenzuordnung standardmäßig das gesamte Batch erneut, bis die Funktion erfolgreich ist oder die Elemente im Batch ablaufen. Um eine ordnungsgemäße Verarbeitung zu gewährleisten, unterbricht die Ereignisquellenzuordnung die Verarbeitung für den betroffenen Shard, bis der Fehler behoben ist. Für Stream-Quellen (DynamoDB und Kinesis) können Sie die maximale Anzahl von Wiederholungsversuchen von Lambda konfigurieren, wenn Ihre Funktion einen Fehler zurückgibt. Service-Fehler oder Drosselungen, bei denen der Stapel Ihre Funktion nicht erreicht, zählen nicht zu den Wiederholungsversuchen. Sie können die Zuordnung von Ereignisquellen auch so konfigurieren, dass ein Aufrufdatensatz an ein Ziel gesendet wird, wenn ein Ereignisbatch verworfen wird.
Modus bereitgestellter Kapazität
Lambda-Ereignisquellenzuordnungen verwenden Ereignisabfragen, um Ihre Ereignisquelle nach neuen Nachrichten abzufragen. Standardmäßig verwaltet Lambda die automatische Skalierung dieser Poller auf der Grundlage des Nachrichtenvolumens. Wenn der Nachrichtenverkehr zunimmt, erhöht Lambda automatisch die Anzahl der Event-Poller, um die Last zu bewältigen und reduziert sie, wenn der Verkehr abnimmt.
Im Bereitstellungsmodus können Sie den Durchsatz Ihrer Ereignisquellenzuordnung feinabstimmen, indem Sie Mindest- und Höchstgrenzen für dedizierte Abfrageressourcen definieren, die bereit sind, die erwarteten Datenverkehrsmuster zu verarbeiten. Diese Ressourcen werden dreimal schneller automatisch skaliert, um plötzliche Spitzen im Ereignisverkehr zu bewältigen, und bieten eine 16-mal höhere Kapazität zur Verarbeitung von Millionen von Ereignissen. Auf diese Weise können Sie reaktionsschnelle ereignisgesteuerte Workloads mit strengen Leistungsanforderungen erstellen.
In Lambda ist ein Event Poller eine Recheneinheit mit Durchsatzmöglichkeiten, die je nach Art der Ereignisquelle variieren. Bei Amazon MSK und selbstverwaltetem Apache Kafka kann jeder Event Poller bis zu 5% MB/sec des Durchsatzes oder bis zu 5 gleichzeitige Aufrufe verarbeiten. Wenn Ihre Ereignisquelle beispielsweise eine durchschnittliche Nutzlast von 1 MB erzeugt und die durchschnittliche Dauer Ihrer Funktion 1 Sekunde beträgt, kann ein einziger Kafka-Event-Poller 5 MB/sec Durchsatz- und 5 gleichzeitige Lambda-Aufrufe unterstützen (vorausgesetzt, es gibt keine Payload-Transformation). Für Amazon SQS kann jeder Event Poller bis zu 1 MB/sec Durchsatz oder bis zu 10 gleichzeitige Aufrufe verarbeiten. Bei der Verwendung des Bereitstellungsmodus fallen zusätzliche Kosten an, die von Ihrer Nutzung des Event-Pollers abhängen. Details zu den Preisen finden Sie unter AWS Lambda -Preise
Der Bereitstellungsmodus ist für Amazon MSK, selbstverwaltete Apache Kafka- und Amazon SQS SQS-Ereignisquellen verfügbar. Während Sie mit den Gleichzeitigkeitseinstellungen die Skalierung Ihrer Funktion steuern können, haben Sie im Bereitstellungsmodus die Kontrolle über den Durchsatz Ihrer Zuordnung von Ereignisquellen. Um eine maximale Leistung zu gewährleisten, müssen Sie möglicherweise beide Einstellungen unabhängig voneinander anpassen.
Der Bereitstellungsmodus ist ideal für Echtzeitanwendungen, die eine konstante Latenz bei der Ereignisverarbeitung erfordern, z. B. Finanzdienstleister, die Marktdatenfeeds verarbeiten, E-Commerce-Plattformen, die personalisierte Empfehlungen in Echtzeit bereitstellen, und Spieleunternehmen, die Live-Spielerinteraktionen verwalten.
Jeder Event Poller unterstützt unterschiedliche Durchsatzkapazitäten:
-
Für Amazon MSK und selbstverwalteten Apache Kafka: bis zu 5 MB/sec Durchsatz oder bis zu 5 gleichzeitige Aufrufe
-
Für Amazon SQS: bis zu 1 MB/sec Durchsatz oder bis zu 10 gleichzeitige Aufrufe oder bis zu 10 SQS-Polling-API-Aufrufe pro Sekunde.
Für Amazon SQS SQS-Ereignisquellenzuordnungen können Sie die Mindestanzahl von Pollern zwischen 2 und 200 mit einer Standardeinstellung von 2 und die maximale Anzahl zwischen 2 und 2.000 mit einer Standardeinstellung von 200 festlegen. Lambda skaliert die Anzahl der Event-Poller zwischen Ihrem konfigurierten Minimum und Maximum und fügt schnell bis zu 1.000 Parallelität pro Minute hinzu, um eine konsistente Verarbeitung Ihrer Ereignisse mit niedriger Latenz zu gewährleisten.
Für Kafka-Ereignisquellenzuordnungen können Sie die Mindestanzahl von Pollern zwischen 1 und 200 mit dem Standardwert 1 und die Höchstanzahl zwischen 1 und 2.000 mit einem Standardwert von 200 festlegen. Lambda skaliert die Anzahl der Event-Poller auf der Grundlage Ihres Event-Backlogs in Ihrem Thema zwischen Ihrem konfigurierten Minimum und Maximum, um eine Verarbeitung Ihrer Ereignisse mit geringer Latenz zu ermöglichen.
Beachten Sie, dass für Amazon SQS SQS-Ereignisquellen die Einstellung für maximale Parallelität nicht im Bereitstellungsmodus verwendet werden kann. Wenn Sie den Bereitstellungsmodus verwenden, steuern Sie die Parallelität über die Einstellung „Maximale Anzahl von Event-Pollers“.
Weitere Informationen zur Konfiguration des Bereitstellungsmodus finden Sie in folgenden Abschnitten:
Um die Latenz im Bereitstellungsmodus zu minimieren, legen Sie den Wert auf 0 fest. MaximumBatchingWindowInSeconds Diese Einstellung stellt sicher, dass Lambda unmittelbar nach Abschluss des aktuellen Funktionsaufrufs mit der Verarbeitung des nächsten Batches beginnt. Weitere Informationen zur Verarbeitung mit niedriger Latenz finden Sie unter Niedrige Latenz für Apache-Kafka.
Nachdem Sie den Bereitstellungsmodus konfiguriert haben, können Sie die Verwendung von Event-Pollern für Ihren Workload beobachten, indem Sie die ProvisionedPollers-Metrik überwachen. Weitere Informationen finden Sie unter Metriken zur Zuordnung von Ereignisquellen.
API für die Ereignisquellenzuordnung
Um eine Ereignisquelle mit der AWS Command Line Interface (AWS CLI) oder einem AWS -SDK
