Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Betriebspraktiken für Amazon OpenSearch Service
Dieses Kapitel enthält bewährte Methoden für den Betrieb von Amazon OpenSearch Service-Domains und enthält allgemeine Richtlinien, die für viele Anwendungsfälle gelten. Jede Workload ist einzigartig und weist einzigartige Merkmale auf, sodass keine generische Empfehlung für jeden Anwendungsfall genau richtig ist. Die wichtigste bewährte Methode besteht darin, Ihre Domains in einem kontinuierlichen Zyklus bereitzustellen, zu testen und anzupassen, um die optimale Konfiguration, Stabilität und Kosten für Ihre Workload zu ermitteln.
Themen
Überwachen und Warnen
Die folgenden bewährten Methoden gelten für die Überwachung Ihrer OpenSearch Service-Domains.
CloudWatch Alarme konfigurieren
OpenSearch Der Service sendet Leistungskennzahlen an Amazon CloudWatch. Überprüfen Sie regelmäßig Ihre Cluster- und Instance-Metriken und konfigurieren Sie empfohlene CloudWatch Alarme auf der Grundlage Ihrer Workload-Leistung.
Aktivieren der Protokollveröffentlichung
OpenSearch Der Service macht OpenSearch Fehlerprotokolle, Suchprotokolle, Indexierungsprotokolle und Auditprotokolle in Amazon CloudWatch Logs verfügbar. Protokolle für langsame Suchen, Protokolle für langsame Indizierung und Fehlerprotokolle sind für die Problembehandlung bei Leistungs- und Stabilitätsproblemen nützlich. Überwachungsprotokolle, die nur verfügbar sind, wenn Sie eine differenzierte Zugriffskontrolle aktivieren, verfolgen die Benutzeraktivität. Weitere Informationen finden Sie in der Dokumentation unter Logs
Protokolle für langsame Suchen, Protokolle für langsame Indizierung sind ein wichtiges Tool, um die Leistung Ihrer Such- und Indizierungsvorgänge zu verstehen und Fehler zu beheben. Aktivieren Sie die Bereitstellung von Protokollen für langsame Suchen und Indizes für alle ProduktionsDomains. Sie müssen auch Schwellenwerte für die Protokollierung konfigurieren — andernfalls werden die Protokolle CloudWatch nicht erfasst.
Shard-Strategie
Shards verteilen Ihre Arbeitslast auf die Datenknoten in Ihrer OpenSearch Service-Domain. Richtig konfigurierte Indizes können dazu beitragen, die Gesamtleistung der Domain zu steigern.
Wenn Sie Daten an OpenSearch Service senden, senden Sie diese Daten an einen Index. Ein Index ist vergleichbar mit einer Datenbanktabelle, mit Dokumenten als Zeilen und Feldern als Spalten. Wenn Sie den Index erstellen, geben Sie an, OpenSearch wie viele primäre Shards Sie erstellen möchten. Die primären Shards sind unabhängige Partitionen des gesamten Datensatzes. OpenSearch Der Service verteilt Ihre Daten automatisch auf die primären Shards in einem Index. Sie können auch Replikate des Index konfigurieren. Jedes Replikat umfasst einen vollständigen Satz von Kopien der primären Shards für diesen Index.
OpenSearch Der Service ordnet die Shards für jeden Index den Datenknoten in Ihrem Cluster zu. Er stellt sicher, dass sich die Primär- und Replikat-Shards für den Index auf unterschiedlichen Datenknoten befinden. Das erste Replikat stellt sicher, dass Sie zwei Kopien der Daten im Index haben. Sie sollten immer mindestens ein Replikat verwenden. Zusätzliche Replikate bieten zusätzliche Redundanz und Lesekapazität.
OpenSearch sendet Indexierungsanfragen an alle Datenknoten, die Shards enthalten, die zum Index gehören. Indizierungsanforderungen werden zuerst an Datenknoten gesendet, die primäre Shards enthalten, und dann an Datenknoten, die Replikat-Shards enthalten. Suchanfragen werden vom Koordinationsknoten entweder an einen primären oder einen Replikat-Shard für alle zum Index gehörenden Shards weitergeleitet.
Bei einem Index mit fünf primären Shards und einem Replikat berührt beispielsweise jede Indizierungsanforderung 10 Shards. Im Gegensatz dazu werden Suchanfragen an n Shards gesendet, wobei n die Anzahl der primären Shards ist. Bei einem Index mit fünf primären Shards und einem Replikat berührt jede Suchanfrage fünf Shards (primär oder Replikat) aus diesem Index.
Ermitteln der Anzahl der Shards und Datenknoten
Verwenden Sie die folgenden bewährten Methoden, um die Anzahl der Shards und Datenknoten für Ihre Domain zu bestimmen.
Shard-Größe – Die Größe der Daten auf der Festplatte ist ein direktes Ergebnis der Größe Ihrer Quelldaten und ändert sich, wenn Sie mehr Daten indizieren. Das source-to-index Verhältnis kann stark variieren, von 1:10 bis 10:1 oder mehr, aber normalerweise liegt es bei etwa 1:1,10. Sie können dieses Verhältnis verwenden, um die Indexgröße auf der Festplatte vorherzusagen. Sie können auch einige Daten indizieren und die tatsächlichen Indexgrößen abrufen, um das Verhältnis für Ihre Workload zu bestimmen. Sobald Sie eine voraussichtliche Indexgröße haben, legen Sie eine Shard-Anzahl fest, sodass jeder Shard zwischen 10 und 30 GiB (für Such-Workloads) oder zwischen 30 und 50 GiB (für Protokoll-Workloads) liegt. 50 GiB sollten das Maximum sein; planen Sie auf jeden Fall einen Zuwachs ein.
Shard-Anzahl – Die Verteilung von Shards auf Datenknoten hat einen großen Einfluss auf die Leistung einer Domain. Wenn Sie Indizes mit mehreren Shards haben, versuchen Sie, dafür zu sorgen, dass der Shard ein Vielfaches der Anzahl der Datenknoten zählt. Dies sorgt dafür, dass Shards gleichmäßig über Datenknoten verteilt sind, und verhindert heiße Knoten. Wenn Sie beispielsweise 12 primäre Shards haben, sollte Ihre Datenknotenanzahl 2, 3, 4, 6 oder 12 betragen. Die Shard-Anzahl ist jedoch zweitrangig gegenüber der Shard-Größe; Wenn Sie über 5 GiB an Daten verfügen, sollten Sie dennoch einen einzelnen Shard verwenden.
Shards pro Datenknoten – Die Gesamtzahl der Shards, die ein Knoten verarbeiten kann, ist proportional zum Java Virtual Machine (JVM)-Speicher des Knotens. Streben Sie 25 Shards oder weniger pro GiB Heap-Speicher an. Beispielsweise sollte ein Knoten mit 32 GiB Heap-Speicher nicht mehr als 800 Shards verarbeiten. Obwohl die Shard-Verteilung je nach Ihren Workload-Mustern variieren kann, gibt es ein Limit von 1.000 Shards pro Node für Elasticsearch und von OpenSearch 1.1 bis 2.15 und 4.000 für 2.17 und höher. OpenSearch Die cat/allocation
Shard-zu-CPU-Verhältnis – Wenn ein Shard an einer Indexierungs- oder Suchanforderung beteiligt ist, verwendet es eine vCPU, um die Anforderung zu verarbeiten. Verwenden Sie als bewährte Methode einen anfänglichen Skalierungspunkt von 1,5 vCPU pro Shard. Wenn Ihr Instance-Typ 8 V hatCPUs, legen Sie die Anzahl Ihrer Datenknoten so fest, dass jeder Knoten nicht mehr als sechs Shards hat. Beachten Sie, dass dies eine Annäherung ist. Testen Sie unbedingt Ihren Workload und skalieren Sie Ihren Cluster entsprechend.
Empfehlungen zu Speichervolumen, Shard-Größe und Instance-Typ finden Sie in den folgenden Ressourcen:
Vermeiden von Speicherversatz
Speicherversatz tritt auf, wenn ein oder mehrere Knoten innerhalb eines Clusters einen höheren Anteil an Speicher für einen oder mehrere Indizes halten als die anderen. Anzeichen für Speicherversatz sind ungleichmäßige CPU-Auslastung, intermittierende und ungleichmäßige Latenzzeiten und ungleichmäßige Warteschlangen auf den Datenknoten. Um festzustellen, ob Sie Probleme mit dem Versatz haben, lesen Sie die folgenden Abschnitte zur Fehlerbehebung:
Stabilität
Die folgenden bewährten Methoden gelten für die Aufrechterhaltung einer stabilen und fehlerfreien OpenSearch Service-Domain.
Bleiben Sie auf dem Laufenden mit OpenSearch
Service-Software-Updates
OpenSearch Service veröffentlicht regelmäßig Softwareupdates, die Funktionen hinzufügen oder Ihre Domains auf andere Weise verbessern. Updates ändern weder die Version noch die OpenSearch Version der Elasticsearch-Engine. Wir empfehlen, dass Sie einen wiederkehrenden Zeitpunkt für die Ausführung des DescribeDomainAPI-Vorgangs einplanen und gegebenenfalls ein Service-Software-Update einleiten. UpdateStatus ELIGIBLE Wenn Sie Ihre Domain nicht innerhalb eines bestimmten Zeitraums (normalerweise zwei Wochen) aktualisieren, führt der OpenSearch Service das Update automatisch durch.
OpenSearch Versions-Upgrades
OpenSearch Der Service bietet regelmäßig Unterstützung für von der Community verwaltete Versionen von. OpenSearch Führen Sie immer ein Upgrade auf die neuesten OpenSearch Versionen durch, wenn diese verfügbar sind.
OpenSearch Der Service aktualisiert gleichzeitig OpenSearch sowohl OpenSearch Dashboards als auch Dashboards (oder Elasticsearch und Kibana, wenn auf Ihrer Domain eine ältere Engine läuft). Wenn der Cluster über dedizierte Master-Knoten verfügt, werden Upgrades ohne Ausfallzeiten abgeschlossen. Andernfalls reagiert der Cluster nach dem Upgrade möglicherweise einige Sekunden lang nicht, während er einen Master-Knoten auswählt. OpenSearch Dashboards sind möglicherweise während eines Teils oder des gesamten Upgrades nicht verfügbar.
Es gibt zwei Möglichkeiten, eine Domain zu aktualisieren:
-
Direktes Upgrade – Diese Option ist einfacher, da Sie denselben Cluster beibehalten.
-
Snapshot-/Wiederherstellungs-Upgrade – Diese Option ist gut geeignet zum Testen neuer Versionen auf einem neuen Cluster oder zum Migrieren zwischen Clustern.
Unabhängig davon, welchen Upgradeprozess Sie verwenden, empfehlen wir, eine Domain zu verwalten, die ausschließlich zu Entwicklungs- und Testzwecken dient, und sie auf die neue Version zu aktualisieren, bevor Sie Ihre Produktion-Domain aktualisieren. Wählen Sie Development and testing (Entwicklung und Prüfung) als Bereitstellungstyp aus, wenn Sie die Test-Domain erstellen. Stellen Sie sicher, dass Sie alle Clients unmittelbar nach dem Domain-Upgrade auf kompatible Versionen aktualisieren.
Verbessern Sie die Snapshot-
Um zu verhindern, dass Ihr Snapshot bei der Verarbeitung hängen bleibt, sollte der Instance-Typ für den dedizierten Master-Knoten mit der Anzahl der Shards übereinstimmen. Weitere Informationen finden Sie unter Auswählen von Instance-Typen für dedizierte Hauptknoten. Darüber hinaus sollte jeder Knoten nicht mehr als die empfohlenen 25 Shards pro GiB Java-Heap-Speicher haben. Weitere Informationen finden Sie unter Auswahl der Anzahl der Shards.
Dedizierte Hauptknoten aktivieren
Dedizierte Hauptknoten erhöhen die Cluster-Stabilität. Ein dedizierter Hauptknoten führt Cluster-Verwaltungsaufgaben aus, enthält jedoch keine Indexdaten und antwortet nicht auf Client-Anforderungen. Diese Auslagerung von Cluster-Verwaltungsaufgaben erhöht die Stabilität Ihrer Domain und ermöglicht es, einige Konfigurationsänderungen ohne Ausfallzeiten durchzuführen.
Aktivieren und verwenden Sie drei dedizierte Hauptknoten für optimale Domain-Stabilität in drei Availability Zones. Bei der Bereitstellung mit Multi-AZ mit Standby werden drei dedizierte Master-Knoten für Sie konfiguriert. Empfehlungen zu Instance-Typen finden Sie unter Auswählen von Instance-Typen für dedizierte Hauptknoten.
Bereitstellen über mehrere Availability Zones hinweg
Um Datenverlust zu vermeiden und die Ausfallzeit des Clusters im Falle einer Unterbrechung des Service zu minimieren, können Sie die Knoten auf zwei oder drei Availability Zones im selben AWS-Region verteilen. Eine bewährte Methode ist die Verwendung von Multi-AZ mit Standby, bei der drei Availability Zones konfiguriert werden, wobei zwei Zonen aktiv sind und eine als Standby-Zone fungiert, und mit zwei Replikat-Shards pro Index. Diese Konfiguration ermöglicht es dem OpenSearch Service, Replikat-Shards auf andere AZs als die entsprechenden primären Shards zu verteilen. Für die Cluster-Kommunikation zwischen Availability Zones fallen keine Availability-Zone-übergreifenden Datenübertragungsgebühren an.
Availability Zones sind isolierte Standorte innerhalb jeder -Region. Bei einer Konfiguration mit zwei Availability Zones bedeutet der Verlust einer Availability Zone, dass Sie die Hälfte der gesamten Domain-Kapazität verlieren. Durch die Umstellung auf drei Availability Zones werden die Auswirkungen des Verlusts einer einzelnen Availability Zone weiter reduziert.
Steuern von Erfassungsablauf und Pufferung
Wir empfehlen, die Gesamtzahl der Anforderungen mithilfe des API-Vorgangs _bulk_bulk-Anforderung zu senden, die 5 000 Dokumente enthält, als 5 000 Anforderungen zu senden, die jeweils ein Dokument enthalten.
Für eine optimale Betriebsstabilität ist es manchmal erforderlich, den Upstream-Ablauf von Indizierungsanforderungen zu begrenzen oder sogar anzuhalten. Die Begrenzung der Rate von Indexanforderungen ist ein wichtiger Mechanismus für den Umgang mit unerwarteten oder gelegentlichen Spitzen bei Anfragen, die andernfalls den Cluster überfordern könnten. Erwägen Sie, einen Mechanismus zur Ablaufkontrolle in Ihre Upstream-Architektur einzubauen.
Das folgende Diagramm zeigt mehrere Komponentenoptionen für eine Protokollerfassungsarchitektur. Konfigurieren Sie die Aggregationsebene so, dass ausreichend Platz zum Puffern eingehender Daten für plötzliche Datenverkehrsspitzen und kurze Domain-Wartung vorhanden ist.
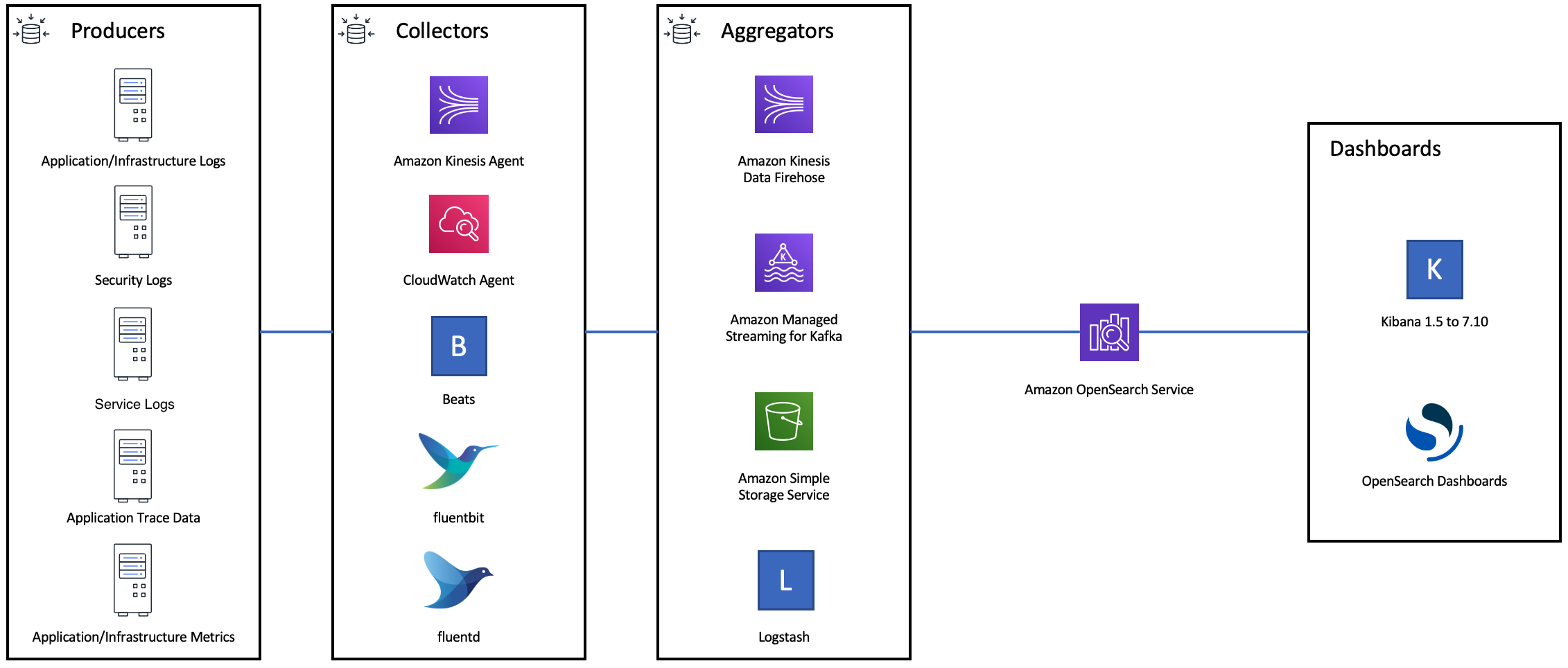
Erstellen von Zuordnungen für Such-Workloads
Erstellen Sie für Such-Workloads Zuordnungendynamic auf strict, um ein versehentliches Hinzufügen neuer Felder zu verhindern:
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Verwenden von Indexvorlagen
Mithilfe einer Indexvorlage
Die folgenden Einstellungen sind hilfreich bei der Konfiguration in Vorlagen:
-
Anzahl der Primär- und Replikat-Shards
-
Aktualisierungsintervall (wie oft der Index aktualisiert werden soll, damit die letzten Änderungen für die Suche verfügbar sind)
-
Dynamische Zuordnungssteuerung
-
Explizite Feldzuordnungen
Die folgende Beispielvorlage enthält jede dieser Einstellungen:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Auch wenn sie sich selten ändern, OpenSearch ist es einfacher, Einstellungen und Zuordnungen zentral zu definieren, als mehrere Upstream-Clients zu aktualisieren.
Indizes mit Indexstatusmanagement verwalten
Wenn Sie Protokolle oder Zeitreihendaten verwalten, empfehlen wir die Verwendung von Indexstatusmanagement (ISM). Mit ISM können Sie regelmäßige Aufgaben zur Verwaltung des Indexlebenszyklus automatisieren. Mit ISM können Sie Richtlinien erstellen, die Index-Alias-Rollover aufrufen, Index-Snapshots erstellen, Indizes zwischen Speicherebenen verschieben und alte Indizes löschen. Sie können den ISM-Rollover
Richten Sie zuerst eine ISM-Richtlinie ein. Ein Beispiel finden Sie unter Beispielrichtlinien. Fügen Sie dann die Richtlinie einem oder mehreren Indizes zu. Wenn Sie ein ISM-Vorlagenfeld in die Richtlinie aufnehmen, wendet der OpenSearch Service die Richtlinie automatisch auf jeden Index an, der dem angegebenen Muster entspricht.
Entferne nicht verwendete Indizes
Überprüfen Sie regelmäßig die Indizes in Ihrem Cluster und identifizieren Sie alle, die nicht verwendet werden. Erstellen Sie einen Snapshot dieser Indizes, damit sie in S3 gespeichert werden, und löschen Sie sie dann. Wenn Sie nicht verwendete Indizes entfernen, reduzieren Sie die Anzahl der Shards und ermöglichen knotenübergreifend eine ausgewogenere Speicherverteilung und Ressourcenauslastung. Selbst im Leerlauf verbrauchen Indizes während der internen Indexwartung einige Ressourcen.
Anstatt ungenutzte Indizes manuell zu löschen, können Sie ISM verwenden, um automatisch einen Snapshot zu erstellen und Indizes nach einem bestimmten Zeitraum zu löschen.
Verwenden mehrerer Domains für hohe Verfügbarkeit
Um eine hohe Verfügbarkeit von über 99,9 % Betriebszeit
Entwickeln Sie Ihre Upstream- und Downstream-Anwendungen unter Berücksichtigung von Failover. Stellen Sie sicher, dass Sie den Failover-Prozess zusammen mit anderen Notfallwiederherstellungsprozessen testen.
Leistung
Die folgenden bewährten Methoden gelten für die Abstimmung Ihrer Domains für eine optimale Leistung.
Größe und Komprimierung von Massenanfragen optimieren
Die Massengröße hängt von Ihren Daten, Ihrer Analyse und Ihrer Clusterkonfiguration ab, aber ein guter Ausgangspunkt sind 3–5 MiB pro Massenanforderung.
Senden Sie Anfragen und empfangen Sie Antworten von Ihren OpenSearch Domains, indem Sie die Gzip-Komprimierung verwenden, um die Nutzlast von Anfragen und Antworten zu reduzieren. Sie können die Gzip-Komprimierung mit dem OpenSearch Python-Client verwenden oder indem Sie die folgenden Header von der Clientseite aus einbeziehen:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Zum Optimieren der Größe Ihrer Massenanforderungen beginnen Sie mit einer Massenanfragengröße von 3 MiB. Erhöhen Sie dann langsam die Anforderungsgröße, bis sich die Indizierungsleistung nicht mehr verbessert.
Anmerkung
Um die gzip-Komprimierung auf Domains zu aktivieren, auf denen Elasticsearch Version 6.x ausgeführt wird, müssen Sie http_compression.enabled auf Cluster-Ebene festlegen. Diese Einstellung ist standardmäßig in Elasticsearch-Versionen 7.x und allen Versionen von wahr. OpenSearch
Größe der Antworten auf Massenanfragen reduzieren
Um die Größe der OpenSearch Antworten zu reduzieren, schließen Sie unnötige Felder mit dem filter_path Parameter aus. Achten Sie darauf, keine Felder herauszufiltern, die zur Identifizierung oder Wiederholung fehlgeschlagener Anforderungen erforderlich sind. Weitere Informationen und Beispiele finden Sie unter Reduzierung der Antwortgröße.
Aktualisierungsintervalle optimieren
OpenSearch Indizes weisen letztendlich Lesekonsistenz auf. Ein Aktualisierungsvorgang macht alle Aktualisierungen, die an einem Index durchgeführt werden, für die Suche verfügbar. Das standardmäßige Aktualisierungsintervall beträgt eine Sekunde, was bedeutet, dass OpenSearch jede Sekunde eine Aktualisierung durchgeführt wird, während in einen Index geschrieben wird.
Je seltener Sie einen Index aktualisieren (höheres Aktualisierungsintervall), desto besser ist die Indizierungsleistung insgesamt. Der Nachteil der Verlängerung des Aktualisierungsintervalls besteht darin, dass es eine längere Verzögerung zwischen einer Indexaktualisierung und dem Zeitpunkt gibt, zu dem die neuen Daten für die Suche verfügbar sind. Stellen Sie Ihr Aktualisierungsintervall so hoch wie möglich ein, um die Gesamtleistung zu verbessern.
Wir empfehlen, den refresh_interval-Parameter für alle Ihre Indizes auf 30 Sekunden oder mehr einzustellen.
Automatische Optimierung aktivieren
Auto-Tune verwendet Leistungs- und Nutzungsmetriken aus Ihrem OpenSearch Cluster, um Änderungen an den Warteschlangengrößen, Cachegrößen und den Einstellungen der Java Virtual Machine (JVM) auf Ihren Knoten vorzuschlagen. Diese optionalen Änderungen verbessern die Clustergeschwindigkeit und -stabilität. Sie können jederzeit zu den standardmäßigen OpenSearch Serviceeinstellungen zurückkehren. Automatische Optimierung ist bei neuen Domains standardmäßig aktiviert, es sei denn, Sie deaktivieren sie ausdrücklich.
Wir empfehlen, die automatische Optimierung für alle Domains zu aktivieren und entweder ein wiederkehrendes Wartungsfenster festzulegen oder die Empfehlungen regelmäßig zu überprüfen.
Sicherheit
Die folgenden bewährten Methoden gelten für die Sicherung Ihrer Domains.
Differenzierte Zugriffskontrolle aktivieren
Mit einer detaillierten Zugriffskontrolle können Sie steuern, wer auf bestimmte Daten innerhalb einer OpenSearch Dienstdomäne zugreifen kann. Im Vergleich zur allgemeinen Zugriffskontrolle gibt die differenzierte Zugriffssteuerung jedem Cluster, Index, Dokument und Feld eine eigene festgelegte Zugriffsrichtlinie. Zugriffskriterien können auf einer Reihe von Faktoren basieren, einschließlich der Rolle der Person, die den Zugriff anfordert, und der Aktion, die sie mit den Daten durchführen möchte. Beispielsweise können Sie einem Benutzer Zugriff zum Schreiben in einen Index gewähren, während ein anderer nur Zugriff zum Lesen der Daten im Index erhält, ohne Änderungen vorzunehmen.
Durch die differenzierte Zugriffskontrolle können Daten mit unterschiedlichen Zugriffsanforderungen auf demselben Speicherplatz vorhanden sein, ohne dass Sicherheits- oder Compliance-Probleme auftreten.
Wir empfehlen, eine differenzierte Zugriffssteuerung für Ihre Domains zu aktivieren.
Bereitstellen von Domains innerhalb einer VPC
Wenn Sie Ihre OpenSearch Service-Domain in einer Virtual Private Cloud (VPC) platzieren, können Sie eine sichere Kommunikation zwischen dem OpenSearch Service und anderen Diensten innerhalb der VPC ermöglichen — ohne dass ein Internet-Gateway, ein NAT-Gerät oder eine VPN-Verbindung erforderlich ist. Der gesamte Datenverkehr bleibt sicher in der Cloud. AWS Domains, die sich innerhalb einer VPC befinden, verfügen aufgrund ihrer logischen Isolierung im Vergleich zu Domains, die öffentliche Endpunkte nutzen, über eine zusätzliche Sicherheitsebene.
Wir empfehlen, dass Sie Ihre Domains innerhalb einer VPC erstellen.
Anwenden einer restriktiven Zugriffsrichtlinie
Selbst wenn Ihre Domain innerhalb einer VPC bereitgestellt wird, ist das Implementieren der Sicherheit in mehreren Schichten eine bewährte Methode. Stellen Sie sicher, dass Sie die Konfiguration Ihrer aktuellen Zugriffsrichtlinien überprüfen.
Wenden Sie eine restriktive, ressourcenbasierte Zugriffsrichtlinie auf Ihre Domains an und folgen Sie dem Prinzip der geringsten Rechte, wenn Sie Zugriff auf die Konfigurations-API und die OpenSearch API-Operationen gewähren. Vermeiden Sie in der Regel die Verwendung des anonymen Benutzerprinzipals "Principal": {"AWS": "*" } in Ihren Zugriffsrichtlinien.
In einigen Situationen ist es jedoch akzeptabel, eine offene Zugriffsrichtlinie zu verwenden, z. B. wenn Sie eine differenzierte Zugriffssteuerung aktivieren. Eine offene Zugriffsrichtlinie kann Ihnen den Zugriff auf die Domain in Fällen ermöglichen, in denen das Signieren von Anforderungen schwierig oder unmöglich ist, z. B. von bestimmten Clients und Tools.
Verschlüsselung im Ruhezustand aktivieren
OpenSearch Service-Domains bieten die Verschlüsselung ruhender Daten, um unbefugten Zugriff auf Ihre Daten zu verhindern. Encryption at Rest verwendet AWS Key Management Service (AWS KMS) zum Speichern und Verwalten Ihrer Verschlüsselungsschlüssel und den Advanced Encryption Standard-Algorithmus mit 256-Bit-Schlüsseln (AES-256) zur Verschlüsselung.
Wenn Ihre Domain sensible Daten speichert, aktivieren Sie die Verschlüsselung der Daten im Ruhezustand.
Aktivieren Sie die Verschlüsselung node-to-node
Node-to-node Die Verschlüsselung bietet zusätzlich zu den Standardsicherheitsfunktionen des OpenSearch Dienstes eine zusätzliche Sicherheitsebene. Es implementiert Transport Layer Security (TLS) für die gesamte Kommunikation zwischen den Knoten, die innerhalb OpenSearch des Systems bereitgestellt werden. Node-to-nodeVerschlüsselung: Alle Daten, die über HTTPS an Ihre OpenSearch Service-Domain gesendet werden, bleiben während der Übertragung verschlüsselt, während sie zwischen den Knoten verteilt und repliziert werden.
Wenn Ihre Domain vertrauliche Daten speichert, aktivieren Sie die node-to-node Verschlüsselung.
Überwachen Sie mit AWS Security Hub
Überwachen Sie Ihre Nutzung des OpenSearch Dienstes in Bezug auf bewährte Sicherheitsverfahren, indem Sie AWS Security Hub Security Hub verwendet Sicherheitskontrollen für die Bewertung von Ressourcenkonfigurationen und Sicherheitsstandards, um Sie bei der Einhaltung verschiedener Compliance-Frameworks zu unterstützen. Weitere Informationen zur Verwendung von Security Hub zur Evaluierung von OpenSearch Serviceressourcen finden Sie unter Amazon OpenSearch Service Steuerelemente im AWS Security Hub Benutzerhandbuch.
Kostenoptimierung
Die folgenden bewährten Methoden gelten für die Optimierung und Einsparung Ihrer OpenSearch Servicekosten.
Instance-Typen der neuesten Generation verwenden
OpenSearch Der Service führt ständig neue EC2 Amazon-Instance-Typen ein, die eine bessere Leistung zu geringeren Kosten bieten. Wir empfehlen, immer die Instances der neuesten Generation zu verwenden.
Vermeiden Sie es, T2 oder t3.small-Instances für Produktion-Domains zu verwenden, da diese bei anhaltender hoher Last instabil werden können. r6g.large-Instances sind eine Option für kleine Produktion-Workloads (sowohl als Datenknoten als auch als dedizierte Hauptknoten).
Verwenden Sie die neuesten Amazon-EBS-gp3-Volumes
OpenSearch Datenknoten benötigen Speicher mit geringer Latenz und hohem Durchsatz, um eine schnelle Indizierung und Abfrage zu ermöglichen. Durch die Verwendung von Amazon-EBS-gp3-Volumes erhalten Sie eine höhere Basisleistung (IOPS und Durchsatz) zu 9,6 % niedrigeren Kosten als mit dem zuvor angebotenen Amazon-EBS-gp2-Volume-Typ. Mit gp3 können Sie unabhängig von der Volume-Größe zusätzliche IOPS und Durchsätze bereitstellen. Diese Volumes sind auch stabiler als Volumes der vorherigen Generation, da sie keine Burst-Gutschriften verwenden. Der GP3-Volumetyp verdoppelt außerdem die per-data-node Volumengrößenbeschränkungen des GP2-Volumetyps. Mit diesen größeren Volumina können Sie die Kosten für passive Daten senken, indem Sie die Speichermenge pro Datenknoten erhöhen.
Verwendung UltraWarm und Cold Storage für Zeitreihen-Protokolldaten
Wenn Sie sie OpenSearch für Protokollanalysen verwenden, verschieben Sie Ihre Daten in einen UltraWarm Kühlraum, um die Kosten zu senken. Verwenden Sie Indexstatusmanagement (ISM), um Daten zwischen Speicherebenen zu migrieren und die Datenaufbewahrung zu verwalten.
UltraWarmbietet eine kostengünstige Möglichkeit, große Mengen schreibgeschützter Daten im OpenSearch Service zu speichern. UltraWarm verwendet Amazon S3 für die Speicherung, was bedeutet, dass die Daten unveränderlich sind und nur eine Kopie benötigt wird. Sie zahlen nur für den Speicherplatz, der der Größe der primären Shards in Ihren Indizes entspricht. Die Latenzen für UltraWarm Abfragen steigen mit der Menge an S3-Daten, die für die Bearbeitung der Abfrage benötigt werden. Nachdem die Daten auf den Knoten zwischengespeichert wurden, verhalten sich Abfragen an UltraWarm Indizes ähnlich wie Abfragen an Hot-Indizes.
Cold Storage wird auch von S3 unterstützt. Wenn Sie kalte Daten abfragen müssen, können Sie sie selektiv an vorhandene Knoten anhängen. UltraWarm Für kalte Daten fallen dieselben verwalteten Speicherkosten an wie UltraWarm, aber Objekte im Cold Storage verbrauchen keine UltraWarm Knotenressourcen. Daher bietet Cold Storage eine beträchtliche Menge an Speicherkapazität, ohne die Größe oder Anzahl der UltraWarm Knoten zu beeinflussen.
UltraWarm wird kostengünstig, wenn Sie etwa 2,5 TiB an Daten aus dem Hot-Storage migrieren müssen. Überwachen Sie Ihre Füllrate und planen Sie, Indizes zu verschieben, UltraWarm bevor Sie dieses Datenvolumen erreichen.
Empfehlungen für Reserved Instances überprüfen
Erwägen Sie den Kauf von Reserved Instances (RIs), wenn Sie einen guten Basiswert für Ihre Leistung und Ihren Rechenverbrauch haben. Rabatte beginnen bei etwa 30 % für 1-Jahres-Reservierungen ohne Vorauszahlung und können bis zu 50 % für alle 3-Jahres-Verpflichtungen im Voraus erhöhen.
Wenn Sie einen stabilen Betrieb für mindestens 14 Tage beobachtet haben, lesen Sie im AWS Cost Management Benutzerhandbuch den Abschnitt Zugriff auf Reservierungsempfehlungen. In der Überschrift Amazon OpenSearch Service werden spezifische Kaufempfehlungen von RI und prognostizierte Einsparungen angezeigt.
