Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überwachung von OpenSearch Cluster-Metriken mit Amazon CloudWatch
Amazon OpenSearch Service veröffentlicht Daten von Ihren Domains bei Amazon CloudWatch. CloudWatch ermöglicht es Ihnen, Statistiken über diese Datenpunkte in Form eines geordneten Satzes von Zeitreihendaten, den so genannten Metriken, abzurufen. OpenSearch Der Service sendet die meisten Messwerte CloudWatch in 60-Sekunden-Intervallen an. Wenn Sie universelle oder magnetische EBS-Volumes verwenden, werden die EBS-Volume-Metriken nur alle fünf Minuten aktualisiert. Alle kumulativen Metriken (z. ThreadpoolWriteRejected B.ThreadpoolSearchRejected) befinden sich im Arbeitsspeicher und verlieren ihren Status. Die Metriken werden bei einem Node-Drop, Node-Bounce, Node-Austausch und Deployment zurückgesetzt. blue/green Weitere Informationen zu Amazon CloudWatch finden Sie im CloudWatch Amazon-Benutzerhandbuch.
Die OpenSearch Servicekonsole zeigt eine Reihe von Diagrammen an, die auf den Rohdaten von basieren CloudWatch. Je nach Ihren Anforderungen ziehen Sie es möglicherweise vor, die Clusterdaten CloudWatch anstelle der Diagramme in der Konsole anzuzeigen. Der Service archiviert die Metriken für zwei Wochen, bevor sie verworfen werden. Die Metriken werden ohne Aufpreis zur Verfügung gestellt, es fallen CloudWatch jedoch Gebühren für die Erstellung von Dashboards und Alarmen an. Weitere Informationen finden Sie unter CloudWatchAmazon-Preise
OpenSearch Service veröffentlicht die folgenden Kennzahlen für CloudWatch:
Metriken anzeigen in CloudWatch
CloudWatch Metriken werden zuerst nach dem Service-Namespace und dann nach den verschiedenen Dimensionskombinationen innerhalb der einzelnen Namespaces gruppiert.
Um Metriken mit der Konsole anzuzeigen CloudWatch
-
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. -
Suchen Sie im linken Navigationsbereich nach Metrics (Metriken) und wählen Sie All metrics (Alle Metriken) aus. Wählen Sie den ES/ OpenSearchService Namespace aus.
-
Wählen Sie eine Dimension aus, um die entsprechenden Metriken anzuzeigen. Metriken für einzelne Knoten befinden sich in der
ClientId, DomainName, NodeId-Dimension. Cluster-Metriken befinden sich in derPer-Domain, Per-Client Metrics-Dimension. Einige Knotenmetriken werden auf Clusterebene aggregiert und somit in beide Dimensionen eingeschlossen. Shard-Metriken befinden sich in derClientId, DomainName, NodeId, ShardRole-Dimension.
Um eine Liste von Metriken anzuzeigen, verwenden Sie AWS CLI
Führen Sie den folgenden Befehl aus:
aws cloudwatch list-metrics --namespace "AWS/ES"
Interpretieren von Zustandstabellen im OpenSearch Service
Verwenden Sie die Registerkarten Clusterstatus und Instanzstatus, um Metriken in OpenSearch Service anzuzeigen. Die Registerkarte Instanzstatus verwendet Boxdiagramme, um einen at-a-glance Überblick über den Zustand der einzelnen OpenSearch Knoten zu geben:
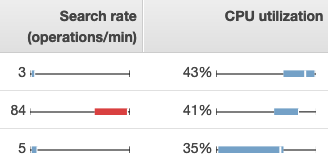
-
Jedes farbige Feld zeigt den Wertebereich für den Knoten im angegebenen Zeitraum.
-
Blaue Felder stehen für Werte, die mit anderen Knoten konsistent sind. Rote Felder stellen Ausreißer dar.
-
Die weiße Linie innerhalb der einzelnen Felder zeigt den aktuellen Wert des Knotens.
-
Die "Whisker" auf beiden Seiten jedes Feldes zeigen die minimalen und maximalen Werte für alle Knoten über den Zeitraum.
Wenn Sie Änderungen an der Konfiguration Ihrer Domain vornehmen, verdoppelt sich häufig die Größe der Liste mit den einzelnen Instances auf den Registerkarten Cluster health (Cluster-Zustand) und Instance health (Instance-Zustand) für einen kurzen Zeitraum, bevor wieder die richtige Zahl angezeigt wird. Eine Erklärung dieser Verhaltensweise finden Sie unter Konfigurationsänderungen in Amazon OpenSearch Service vornehmen.
Cluster-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für Cluster.
| Metrik | Beschreibung |
|---|---|
ClusterStatus.green |
Ein Wert von 1 gibt an, dass alle Index-Shards zu Knoten im Cluster zugeordnet sind. Relevante Statistiken: Maximum |
ClusterStatus.yellow |
Ein Wert von 1 bedeutet, dass die primären Shards für alle Indizes den Knoten im Cluster zugewiesen sind, die Replikat-Shards für mindestens einen Index jedoch nicht. Weitere Informationen finden Sie unter Gelber Cluster-Status. Relevante Statistiken: Maximum |
ClusterStatus.red |
Ein Wert von 1 gibt an, dass die Primär- und Replikat-Shards für mindestens einen Index keinen Knoten im Cluster zugeordnet sind. Weitere Informationen finden Sie unter Roter Cluster-Status. Relevante Statistiken: Maximum |
Shards.active |
Die Gesamtzahl der aktiven primären und Replikat-Shards. Relevante Statistiken: Maximum, Summe |
Shards.unassigned |
Die Anzahl der Shards, die Knoten im Cluster nicht zugeordnet sind. Relevante Statistiken: Maximum, Summe |
Shards.delayedUnassigned |
Die Anzahl der Shards, deren Knotenzuordnung durch die Timeout-Einstellungen verzögert wurde. Relevante Statistiken: Maximum, Summe |
Shards.activePrimary |
Die Anzahl der aktiven primären Shards. Relevante Statistiken: Maximum, Summe |
Shards.initializing |
Die Anzahl der Shards, die derzeit initialisiert werden. Relevante Statistiken: Summe |
Shards.relocating |
Die Anzahl der Shards, die derzeit verschoben werden. Relevante Statistiken: Summe |
Nodes |
Die Anzahl der Knoten im OpenSearch Service-Cluster, einschließlich dedizierter Master-Knoten und UltraWarm Knoten. Weitere Informationen finden Sie unter Konfigurationsänderungen in Amazon OpenSearch Service vornehmen. Relevante Statistiken: Maximum |
SearchableDocuments |
Die Gesamtzahl der durchsuchbaren Dokumente in allen Datenknoten im Cluster. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
DeletedDocuments |
Die Gesamtzahl der zum Löschen markierten Dokumente in allen Datenknoten im Cluster. Diese Dokumente erscheinen nicht mehr in den Suchergebnissen, sondern entfernen OpenSearch nur gelöschte Dokumente bei der Segmentzusammenführung von der Festplatte. Diese Metrik steigt nach Löschanfragen und sinkt nach Segmentzusammenführungen. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
CPUUtilization |
Der Prozentsatz der CPU-Nutzung für Datenknoten im Cluster. „Maximum“ zeigt den Knoten mit der höchsten CPU-Nutzung an. „Average“ (Durchschnitt) stellt alle Knoten im Cluster dar. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Maximum, Durchschnitt |
FreeStorageSpace |
Der freie Platz für Datenknoten im Cluster. Die OpenSearch Servicekonsole zeigt diesen Wert in GiB an. Die CloudWatch Amazon-Konsole zeigt es in MiB an. Anmerkung
Relevante Statistiken: Minimum, Maximum, Durchschnitt, Summe |
ClusterUsedSpace |
Der insgesamt für den Cluster verwendete Speicherplatz. Sie müssen den Zeitraum bei einer Minute belassen, um einen korrekten Wert zu erhalten. Die OpenSearch Servicekonsole zeigt diesen Wert in GiB an. Die CloudWatch Amazon-Konsole zeigt es in MiB an. Relevante Statistiken: Minimum, Maximum |
ClusterIndexWritesBlocked |
Gibt an, ob Ihr Cluster eingehende Schreibanforderungen akzeptiert oder blockiert. Ein Wert von 0 bedeutet, dass der Cluster Anforderungen akzeptiert. Ein Wert von 1 bedeutet, dass Anforderungen blockiert werden. Einige der häufigsten Faktoren sind folgende: Relevante Statistiken: Maximum |
JVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für alle Datenknoten im Cluster verwendet wird. OpenSearch Der Dienst verwendet die Hälfte des RAM einer Instanz für den Java-Heap, bis zu einer Heap-Größe von 32 GiB. Sie können Instances bis zu 64 GiB RAM vertikal skalieren. Dann können Sie eine horizontale Skalierung durchführen, indem Sie Instances hinzufügen. Siehe Empfohlene CloudWatch Alarme für Amazon OpenSearch Service. Relevante Statistiken: Maximum AnmerkungDie Logik für diese Metrik wurde in der Service-Software R20220323 geändert. Weitere Informationen finden Sie in den Versionshinweisen. |
OldGenJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für die „alte Generation“ auf allen Datenknoten im Cluster verwendet wird. Diese Metrik ist auch auf Knotenebene verfügbar. Relevante Statistiken: Maximum |
AutomatedSnapshotFailure |
Die Anzahl fehlgeschlagener automatischer Snapshots für den Cluster. Der Wert Relevante Statistiken: Minimum, Maximum |
CPUCreditBalance |
Das verbleibende CPU-Guthaben für die Datenknoten im Cluster. Ein CPU-Guthaben stellt die Leistung eines gesamten CPU-Kerns für eine Minute zur Verfügung. Weitere Informationen finden Sie unter CPU-Guthaben im Amazon EC2 Developer Guide. Diese Metrik ist nur für die T2-Instance-Typen verfügbar. Relevante Statistiken: Minimum |
OpenSearchDashboardsHealthyNodes |
Ein Gesundheitscheck für OpenSearch Dashboards. Wenn Minimum, Maximum und Durchschnitt alle gleich 1 sind, verhalten sich Dashboards normal. Wenn Sie 10 Knoten mit einem Maximum von 1, Minimum von 0 und Durchschnitt von 0,7 haben, bedeutet dies, dass 7 Knoten (70 %) gesund und 3 Knoten (30 %) ungesund sind. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
OpensearchDashboardsReportingFailedRequestSysErrCount |
Die Anzahl der Anfragen zur Generierung von OpenSearch Dashboard-Berichten, die aufgrund von Serverproblemen oder Funktionseinschränkungen fehlgeschlagen sind. Relevante Statistiken: Summe |
OpensearchDashboardsReportingFailedRequestUserErrCount |
Die Anzahl der Anfragen zur Generierung von OpenSearch Dashboard-Berichten, die aufgrund von Client-Problemen fehlgeschlagen sind. Relevante Statistiken: Summe |
OpensearchDashboardsReportingRequestCount |
Die Gesamtzahl der Anfragen zur Generierung von OpenSearch Dashboards-Berichten. Relevante Statistiken: Summe |
OpensearchDashboardsReportingSuccessCount |
Die Anzahl der erfolgreichen Anfragen zur Generierung von OpenSearch Dashboard-Berichten. Relevante Statistiken: Summe |
KMSKeyError |
Ein Wert von 1 gibt an, dass der AWS KMS Schlüssel, der zum Verschlüsseln von Daten im Ruhezustand verwendet wird, deaktiviert wurde. Aktivieren Sie den Schlüssel wieder, um den normalen Betrieb für die Domain wiederherzustellen. In der Konsole wird diese Metrik nur für Domains angezeigt, in denen Daten im Ruhezustand verschlüsselt werden. Relevante Statistiken: Minimum, Maximum |
KMSKeyInaccessible |
Der Wert 1 gibt an, dass der AWS KMS Schlüssel, der zum Verschlüsseln von Daten im Ruhezustand verwendet wurde, gelöscht wurde oder dass seine Berechtigungen für den Dienst aufgehoben wurden. OpenSearch Für Domains, die sich in diesem Zustand befinden, ist die Wiederherstellung nicht möglich. Aber wenn Sie über einen manuellen Snapshot verfügen, können Sie diesen verwenden, um die Daten der Domain zu einer neuen Domain zu migrieren. In der Konsole wird diese Metrik nur für Domains angezeigt, in denen Daten im Ruhezustand verschlüsselt werden. Relevante Statistiken: Minimum, Maximum |
InvalidHostHeaderRequests |
Die Anzahl der HTTP-Anfragen an den OpenSearch Cluster, die einen ungültigen (oder fehlenden) Host-Header enthielten. Gültige Anfragen enthalten den Domain-Hostnamen als Host-Header-Wert. OpenSearch Der Dienst lehnt ungültige Anfragen für Domänen mit öffentlichem Zugriff ab, für die es keine restriktive Zugriffsrichtlinie gibt. Wir empfehlen, auf alle Domains eine restriktive Zugriffsrichtlinie anzuwenden. Wenn für diese Metrik hohe Werte angezeigt werden, stellen Sie sicher, dass Ihre OpenSearch -Clients den Hostnamen der Domäne (und nicht z. B. die IP-Adresse) in ihren Anfragen beinhalten. Relevante Statistiken: Summe |
OpenSearchRequests (previously
ElasticsearchRequests) |
Die Anzahl der Anfragen an den OpenSearch Cluster. Relevante Statistiken: Summe |
2xx, 3xx, 4xx, 5xx |
Die Anzahl der Anforderungen an die Domain, die zum jeweiligen HTTP-Antwortcode (2xx, 3xx, 4xx, 5xx) geführt haben. Relevante Statistiken: Summe |
ThroughputThrottle |
Gibt an, ob Festplatten gedrosselt wurden oder nicht. Eine Drosselung erfolgt, wenn der kombinierte Durchsatz von Informationen zum Instance-Durchsatz finden Sie unter Amazon EBS-optimierte Instances. Informationen zum Volumendurchsatz finden Sie unter Amazon EBS-Volumetypen Relevante Statistiken: Minimum, Maximum |
IopsThrottle |
Gibt an, ob die Anzahl der input/output Operationen pro Sekunde (IOPS) auf der Domain gedrosselt wurde. Eine Drosselung erfolgt, wenn die IOPS des Datenknotens die maximal zulässige Grenze des EBS-Volumes oder der Instanz des Datenknotens überschreiten. EC2 Informationen zu Instance-IOPS finden Sie unter Amazon EBS-optimierte Instances. Informationen zu Volume-IOPS finden Sie unter Amazon EBS-Volumetypen Relevante Statistiken: Minimum, Maximum |
HighSwapUsage |
Ein Wert von 1 gibt an, dass das Auslagern aufgrund von Seitenfehlern möglicherweise zu Spitzenwerten bei der zugrunde liegenden Festplattennutzung während eines bestimmten Zeitraums geführt hat. Relevante Statistiken: Maximum |
Dedizierte Hauptknoten-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für dedizierte Master-Knoten.
| Metrik | Beschreibung |
|---|---|
MasterCPUUtilization |
Der maximale Prozentsatz der CPU-Ressourcen, die von den dedizierten Hauptknoten verwendet werden. Wir empfehlen, die Größe des Instance-Typs zu erhöhen, wenn diese Metrik 60 Prozent erreicht. Relevante Statistiken: Maximum |
MasterFreeStorageSpace |
Diese Metrik ist nicht relevant und kann ignoriert werden. Der Service verwendet keine Hauptknoten als Datenknoten. |
MasterJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heap, der für alle dedizierten Hauptknoten im Cluster verwendet wird. Wir empfehlen die Verlagerung auf einen größeren Instance-Typen, wenn diese Metrik 85 Prozent erreicht. Relevante Statistiken: Maximum AnmerkungDie Logik für diese Metrik wurde in der Service-Software R20220323 geändert. Weitere Informationen finden Sie in den Versionshinweisen. |
MasterOldGenJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heap pro Hauptknoten, der für die „alte Generation“ verwendet wird. Relevante Statistiken: Maximum |
MasterCPUCreditBalance |
Das verbleibende CPU-Guthaben für die dedizierte Hauptknoten im Cluster. Ein CPU-Guthaben stellt die Leistung eines gesamten CPU-Kerns für eine Minute zur Verfügung. Weitere Informationen finden Sie unter CPU-Guthaben im Amazon EC2 Developer Guide. Diese Metrik ist nur für die T2-Instance-Typen verfügbar. Relevante Statistiken: Minimum |
MasterReachableFromNode |
Eine Zustandsprüfung für Ausfälle bedeuten, dass der Master-Knoten vom Quellknoten aus nicht erreichbar ist. Sie sind normalerweise das Ergebnis eines Problems mit der Netzwerkkonnektivität oder eines AWS Abhängigkeitsproblems. Relevante Statistiken: Maximum |
MasterSysMemoryUtilization |
Der Prozentsatz des Arbeitsspeichers des Hauptknotens, der verwendet wird. Relevante Statistiken: Maximum |
Metriken für dedizierte Koordinatorknoten
Amazon OpenSearch Service bietet die folgenden Metriken für Dedicated Coordinator Nodes.
| Metrik | Beschreibung |
|---|---|
CoordinatorCPUUtilization |
Der maximale Prozentsatz der CPU-Ressourcen, die von den dedizierten Koordinatorknoten genutzt werden. Wir empfehlen, die Größe des Instance-Typs zu erhöhen, wenn diese Metrik 80 Prozent erreicht. Relevante Statistiken: Maximum |
CoordinatorJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für alle dedizierten Koordinatorknoten im Cluster verwendet wird. Wir empfehlen die Verlagerung auf einen größeren Instance-Typen, wenn diese Metrik 85 Prozent erreicht. Relevante Statistiken: Maximum |
CoordinatorOldGenJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heap pro Hauptknoten, der für die „alte Generation“ verwendet wird. Relevante Statistiken: Maximum |
CoordinatorSysMemoryUtilization |
Der Prozentsatz des Speichers des Koordinatorknotens, der verwendet wird. Relevante Statistiken: Maximum |
CoordinatorFreeStorageSpace |
Diese Metrik gibt an, dass der Dienst keine Koordinatorknoten als Datenknoten verwendet. |
EBS-Volume-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für EBS-Volumes.
| Metrik | Beschreibung |
|---|---|
ReadLatency |
Die Latenz für Lesevorgänge auf EBS-Volumes in Sekunden. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
WriteLatency |
Die Latenz für Schreibvorgänge auf EBS-Volumes in Sekunden. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
ReadThroughput |
Der Durchsatz für Lesevorgänge auf EBS-Volumes in Byte pro Sekunde. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
ReadThroughputMicroBursting |
Der Durchsatz in Byte pro Sekunde für Lesevorgänge auf EBS-Volumes, wenn Micro-Bursting berücksichtigt Relevante Statistiken: Minimum, Maximum, Durchschnitt |
WriteThroughput |
Der Durchsatz für Schreibvorgänge auf EBS-Volumes in Byte pro Sekunde. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
WriteThroughputMicroBursting |
Der Durchsatz in Byte pro Sekunde für Schreibvorgänge auf EBS-Volumes, wenn Micro-Bursting berücksichtigt wird. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
DiskQueueDepth |
Die Anzahl der ausstehenden Eingabe- und Ausgabe(I/O)-Anforderungen für ein EBS-Volume. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
ReadIOPS |
Die Anzahl der Eingabe- und Ausgabe(I/O)-Vorgänge pro Sekunde für Lesevorgänge in EBS-Volumes. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
ReadIOPSMicroBursting |
Die Anzahl der Eingabe- und Ausgabevorgänge (I/O) pro Sekunde für Lesevorgänge auf EBS-Volumes, wenn Micro-Bursting berücksichtigt wird. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
WriteIOPS |
Die Anzahl der Eingabe- und Ausgabe(I/O)-Vorgänge pro Sekunde für Schreibvorgänge in EBS-Volumes. Diese Metrik ist auch für einzelne Knoten verfügbar. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
WriteIOPSMicroBursting |
Die Anzahl der Eingabe- und Ausgabevorgänge (I/O) pro Sekunde für Schreibvorgänge auf EBS-Volumes, wenn Micro-Bursting berücksichtigt wird. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
BurstBalance |
Der Prozentsatz der Ein- und Ausgabe (E/A)-Guthaben, die im Burst-Bucket für ein EBS-Volume verbleiben. Ein Wert von 100 bedeutet, dass das Volumen die maximale Anzahl von Credits erreicht hat. Wenn dieser Prozentsatz unter 70 % fällt, lesen Sie Niedrige EBS-Burst-Balance. Das Burst-Balance bleibt für Domains mit GP3-Volume-Typen und Domains mit GP2-Volumes mit einer Volume-Größe von über 1.000 GiB bei 0. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
VolumeStalledIOcheck |
Der Status Ihrer EBS-Volumes, um festzustellen, wann sie beeinträchtigt sind. Bei der Metrik handelt es sich um einen binären Wert, der den Status 0 (bestanden) oder 1 (nicht bestanden) zurückgibt, je nachdem, ob das EBS-Volume Eingabe- und Ausgabevorgänge abschließen kann. Relevante Statistiken: Minimum, Maximum, Durchschnitt |
Instance-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für jede Instance in einer Domain. OpenSearch Service aggregiert diese Instance-Metriken auch, um einen Einblick in den allgemeinen Zustand des Clusters zu erhalten. Sie können dieses Verhalten mithilfe der Statistik über Beispielzähler in der Konsole überprüfen. Beachten Sie, dass jede Metrik in der folgenden Tabelle relevante Statistiken für den Knoten und den Cluster enthält.
Wichtig
Verschiedene Versionen von Elasticsearch nutzen unterschiedliche Threadpools für die Verarbeitung von Aufrufen der _index-API. Elasticsearch 1.5 und 2.3 nutzen den Index-Threadpool. Elasticsearch 5. x, 6.0 und 6.2 verwenden den Bulk-Thread-Pool. OpenSearch und Elasticsearch 6.3 und höher verwenden den Write-Thread-Pool. Derzeit enthält die OpenSearch Service-Konsole kein Diagramm für den Bulk-Thread-Pool.
Verwenden Sie GET _cluster/settings?include_defaults=true, um die Thread-Pool- und Warteschlangengrößen für Ihren Cluster zu überprüfen.
| Metrik | Beschreibung |
|---|---|
FetchLatency |
Der Unterschied in Millisekunden in der Gesamtzeit aller Shard-Abruf-Operationen in einem Knoten zwischen Minute N und Minute (N — 1). Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
FetchRate |
Die Gesamtzahl der Shard-Abrufvorgänge pro Minute für alle Shards auf einem Datenknoten. Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
ScrollTotal |
Die Gesamtzahl der Shard-Scroll-Operationen pro Minute für alle Shards auf einem Datenknoten. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
ScrollCurrent |
Die Anzahl der Shard-Scroll-Operationen, die derzeit ausgeführt werden. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
OpenContexts |
Die Anzahl der offenen Suchkontexte. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
ThreadCount |
Die Gesamtzahl der Threads, die derzeit vom OpenSearch Prozess verwendet werden. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
ShardReactivateCount |
Gibt an, wie oft alle Shards aus einem Ruhezustand heraus aktiviert wurden. Relevante Knotenstatistiken: Summe, Maximum Relevante Cluster-Statistiken: Summe, Maximum |
ConcurrentSearchRate |
Die Gesamtzahl der Suchanfragen mit gleichzeitiger Segmentsuche pro Minute für alle Shards auf einem Datenknoten. Eine einzelner Aufruf der Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
ConcurrentSearchLatency |
Der Unterschied in der Gesamtzeit in Millisekunden, die bei allen Suchen mit gleichzeitiger Segmentsuche in einem Knoten zwischen Minute N und Minute (N-1) benötigt wird. Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
IndexingLatency |
Die Differenz in Millisekunden in der Gesamtzeit aller Indizierungsvorgänge in einem Knoten zwischen Minute N und Minute (N-1). Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
IndexingRate |
Die Anzahl der Indizierungsvorgänge pro Minute. Ein einzelner Aufruf der Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
SearchLatency |
Der Unterschied in der Gesamtzeit (in Millisekunden) aller Suchen in einem Knoten zwischen Minute N und Minute (N-1). Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
SearchRate |
Die Gesamtanzahl von Suchabfragen pro Minute für alle Shards in einem Datenknoten. Eine einzelner Aufruf der Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
SegmentCount |
Die Anzahl der Segmente auf einem Datenknoten. Je mehr Segmente Sie haben, desto länger dauert jede Suche. OpenSearch führt gelegentlich kleinere Segmente zu einem größeren zusammen. Relevante Statistiken für Knoten: Maximum, Durchschnitt Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
SysMemoryUtilization |
Der Prozentsatz des Arbeitsspeichers einer Instance, die in dem Cluster verwendet wird. Hohe Werte für diese Metrik sind normal und stellen normalerweise kein Problem mit Ihrem Cluster dar. Einen besseren Indikator für potenzielle Leistungs- und Stabilitätsprobleme finden Sie in der Relevante Statistiken für Knoten: Minimum, Maximum, Durchschnitt Relevante Statistiken für Cluster: Minimum, Maximum, Durchschnitt |
JVMGCYoungCollectionCount |
Die Anzahl der Ausführungen der automatischen Speicherbereinigung (Garbage Collection) "young generation". Eine stets zunehmende große Anzahl von Ausführungen ist ein normaler Aspekt bei Clustervorgängen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
JVMGCYoungCollectionTime |
Die Dauer in Millisekunden, die ein Cluster für die Ausführungen der automatischen Speicherbereinigung (Garbage Collection) „young generation“ aufgewendet hat. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
JVMGCOldCollectionCount |
Die Anzahl der Ausführungen der automatischen Speicherbereinigung (Garbage Collection) "old generation". In einem Cluster mit genügend Ressourcen sollte diese Zahl relativ klein bleiben und selten zunehmen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
JVMGCOldCollectionTime |
Die Dauer in Millisekunden, die ein Cluster für die Ausführungen der automatischen Speicherbereinigung (Garbage Collection) „old generation“ aufgewendet hat. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
OpenSearchDashboardsConcurrentConnections |
Die Anzahl der aktiven gleichzeitigen Verbindungen zu OpenSearch Dashboards. Wenn diese Zahl konstant hoch ist, sollten Sie Ihren Cluster skalieren. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
OpenSearchDashboardsHealthyNode |
Eine Zustandsprüfung für den einzelnen OpenSearch Dashboards-Knoten. Ein Wert von 1 zeigt ein normales Verhalten an. Ein Wert von 0 zeigt an, dass auf Dashboards nicht zugegriffen werden kann. Relevante Statistiken für Knoten: Minimum Relevante Statistiken für Cluster: Minimum, Maximum, Durchschnitt |
OpenSearchDashboardsHeapTotal |
Die Menge des den OpenSearch Dashboards zugewiesenen Heap-Speichers in MiB. Verschiedene EC2 Instance-Typen können sich auf die genaue Speicherzuweisung auswirken. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
OpenSearchDashboardsHeapUsed |
Die absolute Menge an Heap-Speicher, die von OpenSearch Dashboards in MiB verwendet wird. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
OpenSearchDashboardsHeapUtilization |
Der maximale Prozentsatz des verfügbaren Heap-Speichers, der von Dashboards verwendet wird. OpenSearch Erhöht dieser Wert über 80 %, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Minimum, Maximum, Durchschnitt |
OpenSearchDashboardsOS1MinuteLoad |
Die durchschnittliche CPU-Last von einer Minute für Dashboards. OpenSearch Die CPU-Last sollte idealerweise unter 1,00 liegen. Während temporäre Spitzen in Ordnung sind, empfehlen wir, die Größe des Instance-Typs zu erhöhen, wenn diese Metrik konsistent über 1,00 liegt. Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
OpenSearchDashboardsRequestTotal |
Die Gesamtzahl der HTTP-Anfragen an OpenSearch Dashboards. Wenn Ihr System langsam ist oder eine hohe Anzahl von Dashboards-Anforderungen angezeigt wird, sollten Sie die Größe des Instance-Typs erhöhen. Relevante Knoten-Statistiken: Summe Relevante Statistiken für Cluster: Summe |
OpenSearchDashboardsResponseTimesMaxInMillis |
Die maximale Zeit in Millisekunden, die OpenSearch Dashboards benötigen, um auf eine Anfrage zu antworten. Wenn Anforderungen konsistent lange brauchen, bis Ergebnisse zurückgegeben werden, sollten Sie die Größe des Instance-Typs erhöhen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Maximum, Durchschnitt |
SearchTaskCancelled |
Die Anzahl der Stornierungen von Koordinatorknoten. Relevante Knoten-Statistiken: Summe Relevante Statistiken für Cluster: Summe |
SearchShardTaskCancelled |
Die Anzahl der Stornierungen von Datenknoten. Relevante Knoten-Statistiken: Summe Relevante Cluster-Statistiken: Summe, |
ThreadpoolForce_mergeQueue |
Die maximale Anzahl von Aufgaben in einer Warteschlange im Threadpool erzwungener Zusammenführungen. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
ThreadpoolForce_mergeRejected |
Die Anzahl abgewiesener Aufgaben im Threadpool erzwungener Zusammenführungen. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
ThreadpoolForce_mergeThreads |
Die Größe des Threadpools erzwungener Zusammenführungen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolIndexQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Index-Threadpool. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Die maximale Größe der Index-Warteschlange beträgt 200. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
ThreadpoolIndexRejected |
Die Anzahl abgewiesener Aufgaben im Index-Threadpool. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
ThreadpoolIndexThreads |
Die Größe des Index-Threadpools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolSearchQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Such-Threadpool. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Die maximale Größe der Such-Warteschlange beträgt 1.000. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
ThreadpoolSearchRejected |
Die Anzahl abgewiesener Aufgaben im Such-Threadpool. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
ThreadpoolSearchThreads |
Die Größe des Such-Threadpools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
Threadpoolsql-workerQueue |
Die Anzahl von Aufgaben in einer Warteschlange im SQL-Such-Threadpool. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
Threadpoolsql-workerRejected |
Die Anzahl abgewiesener Aufgaben im SQL-Such-Threadpool. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
Threadpoolsql-workerThreads |
Die Größe des SQL-Such-Threadpools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolBulkQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Massen-Threadpool. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
ThreadpoolBulkRejected |
Die Anzahl abgewiesener Aufgaben im Massen-Threadpool. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
ThreadpoolBulkThreads |
Die Größe des Massen-Threadpools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolIndexSearcherQueue |
Die Anzahl der Aufgaben in der Warteschlange im Thread-Pool der Indexsuche. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
ThreadpoolIndexSearcherRejected |
Die Anzahl der abgelehnten Aufgaben im Thread-Pool der Indexsuche. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
ThreadpoolIndexSearcherThreads |
Die Größe des Threadpools für die Indexsuche. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolWriteThreads |
Die Größe des Schreib-Threadpools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolWriteQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Schreib-Threadpool. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
ThreadpoolWriteRejected |
Die Anzahl abgewiesener Aufgaben im Schreib-Threadpool. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe AnmerkungDa die Standardgröße der Schreibwarteschlange in Version 7.1 von 200 auf 10000 erhöht wurde, ist diese Metrik nicht mehr der einzige Indikator für Ablehnungen durch OpenSearch Service. Verwenden Sie die |
CoordinatingWriteRejected |
Die Gesamtzahl der Ablehnungen erfolgte auf dem koordinierenden Knoten aufgrund des Indexierungsdrucks seit dem letzten OpenSearch Start des Serviceprozesses. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
PrimaryWriteRejected |
Die Gesamtzahl der Ablehnungen auf den primären Shards ist auf den Indexierungsdruck seit dem letzten Start des Serviceprozesses zurückzuführen. OpenSearch Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
ReplicaWriteRejected |
Die Gesamtzahl der Ablehnungen auf den Replikat-Shards ist auf den Indexierungsdruck seit dem letzten Start des Serviceprozesses zurückzuführen. OpenSearch Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
WorkloadManagementEnabled |
Gibt an, ob die Funktion zur Arbeitslastverwaltung aktiviert ist. Ein Wert von 1 bedeutet, dass sie aktiviert ist, und ein Wert von 0 bedeutet, dass sie aktiviert Relevante Knotenstatistiken: Maximum, Minimum Relevante Statistiken für Cluster: Durchschnitt, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
SoftQueryGroupCount |
Anzahl der Abfragegruppen im Soft-Modus in der Domäne. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
EnforcedQueryGroupCount |
Anzahl der Abfragegruppen in der Domäne im erzwungenen Modus. Relevante Knotenstatistiken: Durchschnitt, Maximum Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe Diese Metrik ist in Version 7.1 und höher verfügbar. |
UltraWarm Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für UltraWarmKnoten.
| Metrik | Beschreibung |
|---|---|
WarmCPUUtilization |
Der Prozentsatz der CPU-Auslastung für UltraWarm Knoten im Cluster. „Maximum“ zeigt den Knoten mit der höchsten CPU-Nutzung an. Der Durchschnitt steht für alle UltraWarm Knoten im Cluster. Diese Metrik ist auch für einzelne UltraWarm Knoten verfügbar. Relevante Statistiken: Maximum, Durchschnitt |
WarmFreeStorageSpace |
Die Menge an Warm-Speicherplatz in MiB. Weil Amazon S3 anstelle von angeschlossenen Festplatten UltraWarm verwendet Relevante Statistiken: Summe |
WarmSearchableDocuments |
Die Gesamtzahl der durchsuchbaren Dokumente in allen Warm-Indizes im Cluster. Sie müssen den Zeitraum bei einer Minute belassen, um einen korrekten Wert zu erhalten. Relevante Statistiken: Summe |
WarmSearchLatency
|
Der Unterschied in der Gesamtzeit in Millisekunden für alle Suchanfragen UltraWarm zwischen Minute N und Minute (N-1). Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum |
WarmSearchRate
|
Die Gesamtzahl der Suchanfragen pro Minute für alle Shards auf einem Knoten. UltraWarm Eine einzelner Aufruf der Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Durchschnitt, Maximum, Summe |
WarmStorageSpaceUtilization |
Die Gesamtmenge an Warm-Speicherplatz, in MiB, die vom Cluster belegt wird. Relevante Statistiken: Maximum |
HotStorageSpaceUtilization
|
Die Gesamtmenge an „Hot Storage“-Speicherplatz, die vom Cluster belegt wird. Relevante Statistiken: Maximum |
WarmSysMemoryUtilization |
Der Prozentsatz des Arbeitsspeichers des Warm-Knotens, der verwendet wird. Relevante Statistiken: Maximum |
HotToWarmMigrationQueueSize
|
Die Anzahl der Indizes, die derzeit darauf warten, vom Hot- zum Warm-Speicher zu migrieren. Relevante Statistiken: Maximum |
WarmToHotMigrationQueueSize
|
Die Anzahl der Indizes, die derzeit darauf warten, vom Warm zum Hot Storage zu migrieren. Relevante Statistiken: Maximum |
HotToWarmMigrationFailureCount
|
Die Gesamtzahl der fehlgeschlagenen Hot-zu-Warm-Migrationen. Relevante Statistiken: Summe |
HotToWarmMigrationForceMergeLatency
|
Die durchschnittliche Latenz der erzwungenen Verschmelzungsphase des Migrationsprozesses. Wenn diese Phase durchweg zu lange dauert, ziehen Sie in Betracht, Relevante Statistiken: Durchschnitt |
HotToWarmMigrationSnapshotLatency
|
Die durchschnittliche Latenz der Snapshot-Phase des Migrationsprozesses. Wenn dieser Schritt konsistent zu lange dauert, stellen Sie sicher, dass die Shards entsprechend dimensioniert und im gesamten Cluster verteilt sind. Relevante Statistiken: Durchschnitt |
HotToWarmMigrationProcessingLatency
|
Die durchschnittliche Latenz erfolgreicher Hot-to-Warm-Migrationen, ohne die in der Warteschlange verbrachte Zeit. Dieser Wert ist die Summe der Zeit, die benötigt wird, um die Phasen Zusammenführung zu erzwingen, Snapshot und Shard-Verlagerung des Migrationsprozesses abzuschließen. Relevante Statistiken: Durchschnitt |
HotToWarmMigrationSuccessCount
|
Die Gesamtzahl der erfolgreichen Hot-zu-Warm-Migrationen. Relevante Statistiken: Summe |
HotToWarmMigrationSuccessLatency
|
Die durchschnittliche Latenz erfolgreicher Hot-to-Warm-Migrationen, mit der in der Warteschlange verbrachten Zeit. Relevante Statistiken: Durchschnitt |
WarmThreadpoolSearchThreads |
Die Größe des UltraWarm Such-Thread-Pools. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Durchschnitt, Summe |
WarmThreadpoolSearchRejected |
Die Anzahl der abgelehnten Aufgaben im UltraWarm Such-Thread-Pool. Wenn diese Zahl kontinuierlich zunimmt, sollten Sie erwägen, weitere UltraWarm Knoten hinzuzufügen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
WarmThreadpoolSearchQueue |
Die Anzahl der Aufgaben in der Warteschlange im UltraWarm Such-Thread-Pool. Wenn die Warteschlangengröße konstant hoch ist, sollten Sie erwägen, weitere UltraWarm Knoten hinzuzufügen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für die UltraWarm Knoten verwendet wird. Relevante Statistiken: Maximum AnmerkungDie Logik für diese Metrik wurde in der Service-Software R20220323 geändert. Weitere Informationen finden Sie in den Versionshinweisen. |
WarmOldGenJVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für die „alte Generation“ pro UltraWarm Knoten verwendet wird. Relevante Statistiken: Maximum |
WarmJVMGCYoungCollectionCount |
Gibt an, wie oft die Garbage-Collection der „jungen Generation“ auf UltraWarm Knoten ausgeführt wurde. Eine stets zunehmende große Anzahl von Ausführungen ist ein normaler Aspekt bei Clustervorgängen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmJVMGCYoungCollectionTime |
Die Zeit in Millisekunden, die der Cluster mit der Garbage-Collection der „jungen Generation“ auf Knoten verbracht hat. UltraWarm Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmJVMGCOldCollectionCount |
Die Häufigkeit, mit der die Speicherbereinigung der „alten Generation“ auf Knoten ausgeführt wurde. UltraWarm In einem Cluster mit genügend Ressourcen sollte diese Zahl relativ klein bleiben und selten zunehmen. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmConcurrentSearchRate |
Die Gesamtzahl der Suchanfragen mit gleichzeitiger Segmentsuche pro Minute für alle Shards auf einem UltraWarm Knoten. Eine einzelner Aufruf der Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmConcurrentSearchLatency |
Der Unterschied in der Gesamtzeit in Millisekunden, die bei allen Suchen mit gleichzeitiger Segmentsuche in einem UltraWarm Knoten zwischen Minute N und Minute (N-1) benötigt wird. Relevante Statistiken für Knoten: Durchschnitt Relevante Statistiken für Cluster: Maximum, Durchschnitt |
WarmThreadpoolIndexSearcherQueue |
Die Anzahl der Aufgaben in der Warteschlange im Threadpool der Indexsuche. UltraWarm Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe, Maximum, Durchschnitt |
WarmThreadpoolIndexSearcherRejected |
Die Anzahl der abgelehnten Aufgaben im Thread-Pool der UltraWarm Indexsuche. Relevante Statistiken für Knoten: Maximum Relevante Statistiken für Cluster: Summe |
WarmThreadpoolIndexSearcherThreads |
Die Größe des Threadpools für die UltraWarm Indexsuche. Relevante Statistiken für Knoten: Maximum Relevante Cluster-Statistiken: Summe, Durchschnitt |
Cold-Storage-Metriken
Amazon OpenSearch Service bietet die folgenden Kennzahlen für Cold Storage.
| Metrik | Beschreibung |
|---|---|
ColdStorageSpaceUtilization
|
Die Gesamtmenge an Cold-Storage-Platz, in MiB, die vom Cluster belegt wird. Relevante Statistiken: Maximum |
ColdToWarmMigrationFailureCount |
Die Gesamtzahl der fehlgeschlagenen Cold-zu-Warm-Migrationen. Relevante Statistiken: Summe |
ColdToWarmMigrationLatency |
Die Zeitspanne für erfolgreiche Cold-zu-Warm-Migrationen. Relevante Statistiken: Durchschnitt |
ColdToWarmMigrationQueueSize |
Die Anzahl der Indizes, die derzeit darauf warten, vom Cold- zum Warm-Speicher zu migrieren. Relevante Statistiken: Maximum |
ColdToWarmMigrationSuccessCount
|
Die Gesamtzahl der erfolgreichen Cold-zu-Warm-Migrationen. Relevante Statistiken: Summe |
WarmToColdMigrationFailureCount
|
Die Gesamtzahl der fehlgeschlagenen Warm-zu-Cold-Migrationen. Relevante Statistiken: Summe |
WarmToColdMigrationLatency |
Die Zeitspanne für erfolgreiche Warm-zu-Cold-Migrationen. Relevante Statistiken: Durchschnitt |
WarmToColdMigrationQueueSize |
Die Anzahl der Indizes, die derzeit darauf warten, vom Warm zum Cold Storage zu migrieren. Relevante Statistiken: Maximum |
WarmToColdMigrationSuccessCount |
Die Gesamtzahl der erfolgreichen Warm-zu-Cold-Migrationen. Relevante Statistiken: Summe |
OR1 Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für OR1Instances.
| Metrik | Beschreibung |
|---|---|
RemoteStorageUsedSpace
|
Die Gesamtmenge an Amazon S3 S3-Speicherplatz in MiB, die der Cluster verwendet. Relevante Statistiken: Summe |
RemoteStorageWriteRejected |
Die Gesamtzahl der Anfragen, die aufgrund von Remote-Speicher- und Replikationsdruck auf primären Shards abgelehnt wurden. Dies wird ab dem letzten Start des OpenSearch Serviceprozesses berechnet. Relevante Statistiken: Summe |
ReplicationLagMaxTime |
Der Zeitraum in Millisekunden, für den sich Replikat-Shards hinter den primären Shards befinden. Relevante Statistiken: Maximum |
Warnungsmetriken
Amazon OpenSearch Service bietet die folgenden Metriken für Benachrichtigungen.
| Metrik | Beschreibung |
|---|---|
AlertingDegraded |
Ein Wert von 1 bedeutet, dass entweder der Warnungsindex rot ist, oder ein oder mehrere Knoten nicht im Zeitplan sind. Ein Wert von 0 zeigt ein normales Verhalten an. Relevante Statistiken: Maximum |
AlertingIndexExists |
Ein Wert von 1 bedeutet, dass der Relevante Statistiken: Maximum |
AlertingIndexStatus.green |
Der Zustand des Index. Ein Wert von 1 bedeutet „grün“. Der Wert 0 bedeutet, dass der Index entweder nicht existiert oder nicht grün ist. Relevante Statistiken: Maximum |
AlertingIndexStatus.red |
Der Zustand des Index. Ein Wert von 1 bedeutet „rot“. Der Wert 0 bedeutet, dass der Index entweder nicht existiert oder nicht rot ist. Relevante Statistiken: Maximum |
AlertingIndexStatus.yellow |
Der Zustand des Index. Ein Wert von 1 bedeutet „gelb“. Der Wert 0 bedeutet, dass der Index entweder nicht vorhanden ist oder nicht gelb ist. Relevante Statistiken: Maximum |
AlertingNodesNotOnSchedule |
Ein Wert von 1 bedeutet, dass einige Aufgaben nicht termingerecht ausgeführt werden. Der Wert 0 bedeutet, dass alle Alarmaufgaben termingerecht ausgeführt werden (oder dass keine Alarmaufgaben vorhanden sind). Sehen Sie in der OpenSearch Service-Konsole nach oder stellen Sie eine Relevante Statistiken: Maximum |
AlertingNodesOnSchedule |
Ein Wert von 1 bedeutet, dass alle Alarmaufgaben termingerecht ausgeführt werden (oder dass keine Alarmaufgaben vorhanden sind). Der Wert 0 bedeutet, dass einige Aufgaben nicht termingerecht ausgeführt werden. Relevante Statistiken: Maximum |
AlertingScheduledJobEnabled |
Der Wert 1 bedeutet, dass die Relevante Statistiken: Maximum |
Metriken zur Anomalieerkennung
Amazon OpenSearch Service bietet die folgenden Metriken für die Erkennung von Anomalien.
| Metrik | Beschreibung |
|---|---|
ADPluginUnhealthy |
Ein Wert von 1 bedeutet, dass das Plug-in zur Anomalieerkennung nicht ordnungsgemäß funktioniert, entweder wegen einer hohen Anzahl von Fehlern oder weil einer der Indizes, die es verwendet, rot ist. Ein Wert 0 gibt an, dass das Plug-in wie erwartet funktioniert. Relevante Statistiken: Maximum |
ADExecuteRequestCount |
Die Anzahl der Anfragen zur Erkennung von Anomalien. Relevante Statistiken: Summe |
ADExecuteFailureCount
|
Die Anzahl der fehlgeschlagenen Anfragen zur Erkennung von Anomalien. Relevante Statistiken: Summe |
ADHCExecuteFailureCount |
Die Anzahl der fehlgeschlagenen Anforderungen zum Erkennen von Anomalien für Detektoren mit hoher Kardinalität. Relevante Statistiken: Summe |
ADHCExecuteRequestCount |
Die Anzahl der Anforderungen zum Erkennen von Anomalien für Detektoren mit hoher Kardinalität. Relevante Statistiken: Summe |
ADAnomalyResultsIndexStatusIndexExists |
Ein Wert 1 bedeutet, dass der Index, auf den der Relevante Statistiken: Maximum |
ADAnomalyResultsIndexStatus.red |
Ein Wert 1 bedeutet, dass der Index, auf den der Relevante Statistiken: Maximum |
ADAnomalyDetectorsIndexStatusIndexExists |
Ein Wert von 1 bedeutet, dass der Relevante Statistiken: Maximum |
ADAnomalyDetectorsIndexStatus.red |
Ein Wert von 1 bedeutet, dass der Relevante Statistiken: Maximum |
ADModelsCheckpointIndexStatusIndexExists |
Ein Wert von 1 bedeutet, dass der Relevante Statistiken: Maximum |
ADModelsCheckpointIndexStatus.red |
Ein Wert von 1 bedeutet, dass der Relevante Statistiken: Maximum |
Asynchrone Suchmetriken
Amazon OpenSearch Service bietet die folgenden Metriken für die asynchrone Suche.
Asynchrone Suchkoordinator-Knotenstatistik (pro Koordinator-Knoten)
| Metrik | Beschreibung |
|---|---|
AsynchronousSearchSubmissionRate |
Die Anzahl der asynchronen Suchen, die in der letzten Minute gesendet wurden. |
AsynchronousSearchInitializedRate |
Die Anzahl der asynchronen Suchen, die in der letzten Minute initialisiert wurden. |
AsynchronousSearchRunningCurrent |
Die Anzahl der derzeit ausgeführten asynchronen Suchen. |
AsynchronousSearchCompletionRate |
Die Anzahl der asynchronen Suchen, die in der letzten Minute erfolgreich beendet wurden. |
AsynchronousSearchFailureRate |
Die Anzahl der asynchronen Suchen, die in der letzten Minute beendet wurden und fehlgeschlagen sind. |
AsynchronousSearchPersistRate |
Die Anzahl der asynchronen Suchen, die in der letzten Minute beibehalten wurden. |
AsynchronousSearchPersistFailedRate |
Die Anzahl der asynchronen Suchen, deren Beibehaltung in der letzten Minute fehlgeschlagen ist. |
AsynchronousSearchRejected |
Die Gesamtzahl der seit der Knotenbetriebszeit abgelehnten asynchronen Suchen. |
AsynchronousSearchCancelled |
Die Gesamtzahl der seit der Knotenbetriebszeit abgebrochenen asynchronen Suchen. |
AsynchronousSearchMaxRunningTime |
Die Dauer der längsten asynchronen Suche auf einem Knoten in der letzten Minute. |
Asynchrone Suchcluster-Statistiken
| Metrik | Beschreibung |
|---|---|
AsynchronousSearchStoreHealth |
Der Zustand des Speichers im anhaltenden Index (Rot/Nicht-Rot) in der letzten Minute. |
AsynchronousSearchStoreSize |
Die Größe des Systemindex über alle Shards in der letzten Minute. |
AsynchronousSearchStoredResponseCount |
Die Anzahl der gespeicherten Antworten im Systemindex in der letzten Minute. |
Metriken automatisch abstimmen
Amazon OpenSearch Service bietet die folgenden Metriken für Auto-Tune.
| Metrik | Beschreibung |
|---|---|
AutoTuneChangesHistoryHeapSize |
Die Änderungshistorie in MiB für Werte zur Optimierung der Heap-Größe. |
AutoTuneChangesHistoryJVMYoungGenArgs |
Die Änderungshistorie für JVM-Argumente YongGen . |
AutoTuneFailed |
Ein boolescher Wert, der angibt, ob die Auto-Tune-Änderung fehlgeschlagen ist. |
AutoTuneSucceeded |
Ein boolescher Wert, der angibt, ob die Auto-Tune-Änderung erfolgreich war. |
AutoTuneValue |
Der Änderungsverlauf der Warteschlange (Anzahl) und die Cache-Tunings ändern den Verlauf (in MiB) für unterbrechungsfreie Änderungen. |
Multi-AZ mit Standby-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für Multi-AZ mit Standby.
Metriken auf Knotenebene für Datenknoten in aktiven Availability Zones
| Metrik | Beschreibung |
|---|---|
CPUUtilization |
Der Prozentsatz der CPU-Nutzung für Datenknoten im Cluster. „Maximum“ zeigt den Knoten mit der höchsten CPU-Nutzung an. „Average“ (Durchschnitt) stellt alle Knoten im Cluster dar. Diese Metrik ist auch für einzelne Knoten verfügbar. |
FreeStorageSpace |
Der freie Platz für Datenknoten im Cluster. Die OpenSearch Servicekonsole zeigt diesen Wert in GiB an. Die CloudWatch Amazon-Konsole zeigt es in MiB an. |
JVMMemoryPressure |
Der maximale Prozentsatz des Java-Heaps, der für alle Datenknoten im Cluster verwendet wird. OpenSearch Der Dienst verwendet die Hälfte des RAM einer Instanz für den Java-Heap, bis zu einer Heap-Größe von 32 GiB. Sie können Instances bis zu 64 GiB RAM vertikal skalieren. Dann können Sie eine horizontale Skalierung durchführen, indem Sie Instances hinzufügen. Siehe Empfohlene CloudWatch Alarme für Amazon OpenSearch Service. |
SysMemoryUtilization |
Der Prozentsatz des Arbeitsspeichers einer Instance, die in dem Cluster verwendet wird. Hohe Werte für diese Metrik sind normal und stellen normalerweise kein Problem mit Ihrem Cluster dar. Einen besseren Indikator für potenzielle Leistungs- und Stabilitätsprobleme finden Sie in der JVMMemoryPressure-Metrik. |
IndexingLatency |
Der Unterschied zwischen Minute N und Minute (N-1) in Millisekunden in der Gesamtzeit aller Indizierungsvorgänge in einem Knoten. |
IndexingRate |
Die Anzahl der Indizierungsvorgänge pro Minute. |
SearchLatency |
Der Unterschied in der Gesamtzeit in Millisekunden, gemessen an allen Suchvorgängen in einem Knoten zwischen Minute N und Minute (N-1). |
SearchRate |
Die Gesamtanzahl von Suchabfragen pro Minute für alle Shards in einem Datenknoten. |
ThreadpoolSearchQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Such-Threadpool. Wenn die Größe der Warteschlange gleichbleibend hoch ist, erwägen Sie eine Skalierung Ihres Clusters. Die maximale Größe der Such-Warteschlange beträgt 1.000. |
ThreadpoolWriteQueue |
Die Anzahl von Aufgaben in einer Warteschlange im Schreib-Threadpool. |
ThreadpoolSearchRejected |
Die Anzahl abgewiesener Aufgaben im Such-Threadpool. Wenn die Anzahl stätig wächst, erwägen Sie eine Skalierung Ihres Clusters. |
ThreadpoolWriteRejected |
Die Anzahl abgewiesener Aufgaben im Schreib-Threadpool. |
Metriken auf Clusterebene für Cluster in aktiven Availability Zones
| Metrik | Beschreibung |
|---|---|
DataNodes |
Die Gesamtzahl der aktiven Shards und Standby-Shards. |
DataNodesShards.active |
Die Gesamtzahl der aktiven primären und Replikat-Shards. |
DataNodesShards.unassigned |
Die Anzahl der Shards, die Knoten im Cluster nicht zugeordnet sind. |
DataNodesShards.initializing |
Die Anzahl der Shards, die derzeit initialisiert werden. |
DataNodesShards.relocating |
Die Anzahl der Shards, die derzeit verschoben werden. |
Kennzahlen zur Rotation der Verfügbarkeitszone
WennActiveReads., dann ist die Zone aktiv. WennAvailability-Zone = 1ActiveReads., dann befindet sich die Zone im Standby-Modus.Availability-Zone =
0
Metriken zum aktuellen Zeitpunkt
Amazon OpenSearch Service bietet die folgenden Metriken für Point-in-Time-Suchen (PIT).
Statistiken zum PIT-Koordinatorknoten (pro Koordinatorknoten)
| Metrik | Beschreibung |
|---|---|
CurrentPointInTime |
Die Anzahl der aktiven PIT-Suchkontexte im Knoten. |
TotalPointInTime |
Die Anzahl der abgelaufenen PIT-Suchkontexte seit der Betriebszeit des Knotens. |
AvgPointInTimeAliveTime |
Die durchschnittliche Verfügbarkeit von PIT-Suchkontexten seit der Betriebszeit des Knotens. |
HasActivePointInTime |
Ein Wert von 1 gibt an, dass es seit der Verfügbarkeit des Knotens aktive PIT-Kontexte auf Knoten gibt. Ein Wert von 0 bedeutet, dass keine vorhanden sind. |
HasUsedPointInTime |
Ein Wert von 1 gibt an, dass seit der Betriebszeit des Knotens abgelaufene PIT-Kontexte auf Knoten vorhanden sind. Ein Wert von 0 bedeutet, dass keine vorhanden sind. |
SQL-Metriken
Amazon OpenSearch Service bietet die folgenden Metriken für die SQL-Unterstützung.
| Metrik | Beschreibung |
|---|---|
SQLFailedRequestCountByCusErr |
Die Anzahl der Anforderungen an die Relevante Statistiken: Summe |
SQLFailedRequestCountBySysErr |
Die Anzahl der Anforderungen an die Relevante Statistiken: Summe |
SQLRequestCount |
Die Anzahl der Anforderungen an die Relevante Statistiken: Summe |
SQLDefaultCursorRequestCount |
Ähnlich wie Relevante Statistiken: Summe |
SQLUnhealthy |
Ein Wert von 1 gibt an, dass das SQL-Plugin als Reaktion auf bestimmte Anforderungen 5xx Antwortcodes zurückgibt oder ungültige Abfrage-DSL an OpenSearch übergibt. Andere Anfragen sollten weiterhin erfolgreich sein. Der Wert 0 zeigt an, dass keine aktuellen Fehler vorliegen. Wenn Sie einen dauerhaften Wert von 1 sehen, beheben Sie die Anforderungen, die Ihre Clients an das Plug-in stellen. Relevante Statistiken: Maximum |
k-NN-Metriken
Amazon OpenSearch Service umfasst die folgenden Metriken für das K-Nearest Neighbor (k-NN) -Plugin.
| Metrik | Beschreibung |
|---|---|
KNNCacheCapacityReached |
Metrik pro Knoten, ob die Cache-Kapazität erreicht wurde. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Maximum |
KNNCircuitBreakerTriggered |
Metrik pro Cluster, ob der Leistungsschalter ausgelöst wird. Wenn Knoten einen Wert von 1 für Relevante Statistiken: Maximum |
KNNEvictionCount |
Metrik pro Knoten für die Anzahl der Diagramme, die aufgrund von Speichereinschränkungen oder Leerlaufzeit aus dem Cache entfernt wurden. Explizite Bereinigungen, die aufgrund des Indexlöschens auftreten, werden nicht gezählt. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
KNNGraphIndexErrors |
Metrik pro Knoten für die Anzahl der Anforderungen, um das Relevante Statistiken: Summe |
KNNGraphIndexRequests |
Metrik pro Knoten für die Anzahl der Anforderungen, um das Relevante Statistiken: Summe |
KNNGraphMemoryUsage |
Metrik pro Knoten für die aktuelle Cachegröße (Gesamtgröße aller Diagramme im Speicher) in Kilobyte. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Durchschnitt |
KNNGraphQueryErrors |
Metrik pro Knoten für die Anzahl der Diagrammabfragen, die einen Fehler verursacht haben. Relevante Statistiken: Summe |
KNNGraphQueryRequests |
Metrik pro Knoten für die Anzahl der Diagrammabfragen. Relevante Statistiken: Summe |
KNNHitCount |
Metrik pro Knoten für die Anzahl der Cache-Treffer. Ein Cache-Treffer tritt auf, wenn ein Benutzer ein Diagramm abfragt, das bereits in den Speicher geladen ist. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
KNNLoadExceptionCount |
Metrik pro Knoten für die Häufigkeit, mit der eine Ausnahme aufgetreten ist, während versucht wurde, ein Diagramm in den Cache zu laden. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
KNNLoadSuccessCount |
Metrik pro Knoten, wie oft das Plug-In ein Diagramm erfolgreich in den Cache geladen hat. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
KNNMissCount |
Metrik pro Knoten für die Anzahl der Cache-Fehlschläge. Ein Cache-Fehlschlag tritt auf, wenn ein Benutzer ein Diagramm abfragt, das noch nicht in den Speicher geladen ist. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
KNNQueryRequests |
Metrik pro Knoten für die Anzahl der Abfrageanforderungen, die das k–NN-Plug-In empfangen hat. Relevante Statistiken: Summe |
KNNScriptCompilationErrors |
Metrik pro Knoten für die Anzahl der Fehler während der Skript-Kompilierung. Diese Statistik ist nur relevant für die Suche nach k-NN-Skripten. Relevante Statistiken: Summe |
KNNScriptCompilations |
Metrik pro Knoten für die Anzahl der Kompilierung des k-NN-Skripts. Dieser Wert sollte normalerweise 1 oder 0 sein, aber wenn der Cache mit den kompilierten Skripten gefüllt ist, wird das k-NN-Skript möglicherweise neu kompiliert. Diese Statistik ist nur relevant für die Suche nach k-NN-Skripten. Relevante Statistiken: Summe |
KNNScriptQueryErrors |
Metrik pro Knoten für die Anzahl der Fehler bei Skriptabfragen. Diese Statistik ist nur relevant für die Suche nach k-NN-Skripten. Relevante Statistiken: Summe |
KNNScriptQueryRequests |
Metrik pro Knoten für die Gesamtzahl der Skriptabfragen. Diese Statistik ist nur relevant für die Suche nach k-NN-Skripten. Relevante Statistiken: Summe |
KNNTotalLoadTime |
Die Zeit in Nanosekunden, die k-NN benötigt hat, um Diagramme in den Cache zu laden. Diese Metrik ist nur für die ungefähre k-NN-Suche relevant. Relevante Statistiken: Summe |
Metriken für Cluster-übergreifende Suchen
Amazon OpenSearch Service bietet die folgenden Metriken für die clusterübergreifende Suche.
Metriken der Quell-Domain
| Metrik | Dimension | Beschreibung |
|---|---|---|
CrossClusterOutboundConnections |
|
Anzahl der verbundenen Knoten. Wenn Ihre Antwort eine oder mehrere übersprungene Domains enthält, verwenden Sie diese Metrik, um alle fehlerhaften Verbindungen nachzuverfolgen. Wenn diese Zahl auf 0 fällt, ist die Verbindung fehlerhaft. |
CrossClusterOutboundRequests |
|
Anzahl der an die Ziel-Domain gesendeten Suchabfragen. Verwenden Sie dies, um zu überprüfen, ob die Last von Cluster-übergreifenden Suchabfragen Ihre Domain überfordert, korrelieren Sie jede Spitze in dieser Metrik mit jeder JVM/CPU-Spitze. |
Metrik der Ziel-Domain
| Metrik | Dimension | Beschreibung |
|---|---|---|
CrossClusterInboundRequests |
|
Anzahl der eingehenden Verbindungsanforderungen, die von der Quell-Domain empfangen wurden. |
Fügen Sie einen CloudWatch Alarm für den Fall hinzu, dass Sie unerwartet eine Verbindung verlieren. Schritte zum Erstellen eines Alarms finden Sie unter Erstellen eines CloudWatch Alarms auf der Grundlage eines statischen Schwellenwerts.
Cluster-übergreifende Replikationsmetriken
Amazon OpenSearch Service bietet die folgenden Metriken für die clusterübergreifende Replikation.
| Metrik | Beschreibung |
|---|---|
ReplicationRate |
Die durchschnittliche Rate der Replikationsvorgänge pro Sekunde. Diese Metrik ähnelt der |
LeaderCheckPoint |
Die Summe der Leader-Checkpoint-Werte für eine bestimmte Verbindung über alle replizierenden Indizes. Sie können diese Metrik verwenden, um die Latenz der Replikation zu messen. |
FollowerCheckPoint |
Die Summe der Follower-Checkpoint-Werte für eine bestimmte Verbindung über alle replizierenden Indizes. Sie können diese Metrik verwenden, um die Latenz der Replikation zu messen. |
ReplicationNumSyncingIndices |
Die Anzahl der Indizes, die den Replikationsstatus |
ReplicationNumBootstrappingIndices |
Die Anzahl der Indizes, die den Replikationsstatus |
ReplicationNumPausedIndices |
Die Anzahl der Indizes, die den Replikationsstatus |
ReplicationNumFailedIndices |
Die Anzahl der Indizes, die den Replikationsstatus |
|
|
Die Anzahl der Replikationstransportanfragen auf der Follower-Domain. Transportanfragen sind intern und treten bei jedem Aufruf eines Replikations-API-Vorgangs auf. Sie treten auch auf, wenn die Follower-Domain Änderungen gegenüber der Leader-Domain abfragt. |
|
|
Die Anzahl der Replikationstransportanfragen in der Leader-Domäne. Transportanfragen sind intern und treten jedes Mal auf, wenn ein Replikations-API-Vorgang aufgerufen wird. |
AutoFollowNumSuccessStartReplication |
Die Anzahl der Follower-Indizes, die durch eine Replikationsregel für eine bestimmte Verbindung erfolgreich erstellt wurden. |
AutoFollowNumFailedStartReplication |
Die Anzahl der Follower-Indizes, die von einer Replikationsregel nicht erstellt werden konnten, wenn ein übereinstimmendes Muster vorhanden war. Dieses Problem kann aufgrund eines Netzwerkproblems auf dem Remote-Cluster oder eines Sicherheitsproblems auftreten (d. h. die zugeordnete Rolle hat keine Berechtigung zum Starten der Replikation). |
AutoFollowLeaderCallFailure |
Ob es fehlgeschlagene Abfragen vom Follower-Index zum Leader-Index gegeben hat, um neue Daten abzurufen. Ein Wert von |
Learning-to-Rank-Metriken
Amazon OpenSearch Service bietet die folgenden Kennzahlen für Learning to Rank.
| Metrik | Beschreibung |
|---|---|
LTRRequestTotalCount |
Gesamtzahl der Ranglistenanforderungen. |
LTRRequestErrorCount |
Gesamtzahl der fehlgeschlagenen Anforderungen. |
LTRStatus.red |
Verfolgt, ob einer der Indizes, die zum Ausführen des Plug-Ins benötigt werden, rot ist. |
LTRMemoryUsage |
Der Gesamtspeicher, der vom Plug-In verwendet wird. |
LTRFeatureMemoryUsageInBytes |
Die Menge an Arbeitsspeicher in Byte, die von den Learning-to-Rank-Funktionsfeldern verwendet wird. |
LTRFeaturesetMemoryUsageInBytes |
Die Menge an Arbeitsspeicher in Byte, die von allen Learning-to-Rank-Funktionssets verwendet wird. |
LTRModelMemoryUsageInBytes |
Die Menge an Arbeitsspeicher in Byte, die von allen Learning-to-Rank-Modellen verwendet wird. |
Metriken für Piped Processing Language
Amazon OpenSearch Service bietet die folgenden Metriken für Piped Processing Language.
| Metrik | Beschreibung |
|---|---|
PPLFailedRequestCountByCusErr |
Die Anzahl der Anforderungen an die |
PPLFailedRequestCountBySysErr |
Die Anzahl der Anforderungen an die |
PPLRequestCount |
Die Anzahl der Anforderungen an die |
