Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen Sie eine ETL-Servicepipeline, um Daten mithilfe von AWS Glue inkrementell von Amazon S3 nach Amazon Redshift zu laden
Rohan Jamadagni und Arunabha Datta, Amazon Web Services
Übersicht
Dieses Muster enthält Anleitungen zur Konfiguration von Amazon Simple Storage Service (Amazon S3) für eine optimale Data-Lake-Leistung und zum anschließenden Laden inkrementeller Datenänderungen von Amazon S3 in Amazon Redshift mithilfe von AWS Glue, wobei Extraktions-, Transformations- und Ladevorgänge (ETL) ausgeführt werden.
Die Quelldateien in Amazon S3 können verschiedene Formate haben, darunter kommagetrennte Werte (CSV), XML- und JSON-Dateien. Dieses Muster beschreibt, wie Sie AWS Glue verwenden können, um die Quelldateien in ein kosten- und leistungsoptimiertes Format wie Apache Parquet zu konvertieren. Sie können Parquet-Dateien direkt von Amazon Athena und Amazon Redshift Spectrum aus abfragen. Sie können Parquet-Dateien auch in Amazon Redshift laden, sie aggregieren und die aggregierten Daten mit Verbrauchern teilen oder die Daten mithilfe von Amazon visualisieren. QuickSight
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto.
Ein S3-Quell-Bucket mit den richtigen Rechten, der CSV-, XML- oder JSON-Dateien enthält.
Annahmen
Die CSV-, XML- oder JSON-Quelldateien wurden bereits in Amazon S3 geladen und sind von dem Konto aus zugänglich, in dem AWS Glue und Amazon Redshift konfiguriert sind.
Bewährte Methoden für das Laden der Dateien, das Teilen der Dateien, die Komprimierung und die Verwendung eines Manifests werden befolgt, wie in der Amazon Redshift Redshift-Dokumentation beschrieben.
Die Struktur der Quelldatei ist unverändert.
Das Quellsystem kann Daten in Amazon S3 aufnehmen, indem es der in Amazon S3 definierten Ordnerstruktur folgt.
Der Amazon Redshift Redshift-Cluster erstreckt sich über eine einzige Availability Zone. (Diese Architektur ist angemessen, da AWS Lambda, AWS Glue und Amazon Athena serverlos sind.) Um eine hohe Verfügbarkeit zu gewährleisten, werden Cluster-Snapshots in regelmäßigen Abständen erstellt.
Einschränkungen
Die Dateiformate sind auf diejenigen beschränkt, die derzeit von AWS Glue unterstützt werden.
Downstream-Berichte in Echtzeit werden nicht unterstützt.
Architektur
Quelltechnologie-Stack
S3-Bucket mit CSV-, XML- oder JSON-Dateien
Zieltechnologie-Stack
S3-Datensee (mit partitioniertem Parquet-Dateispeicher)
Amazon Redshift
Zielarchitektur
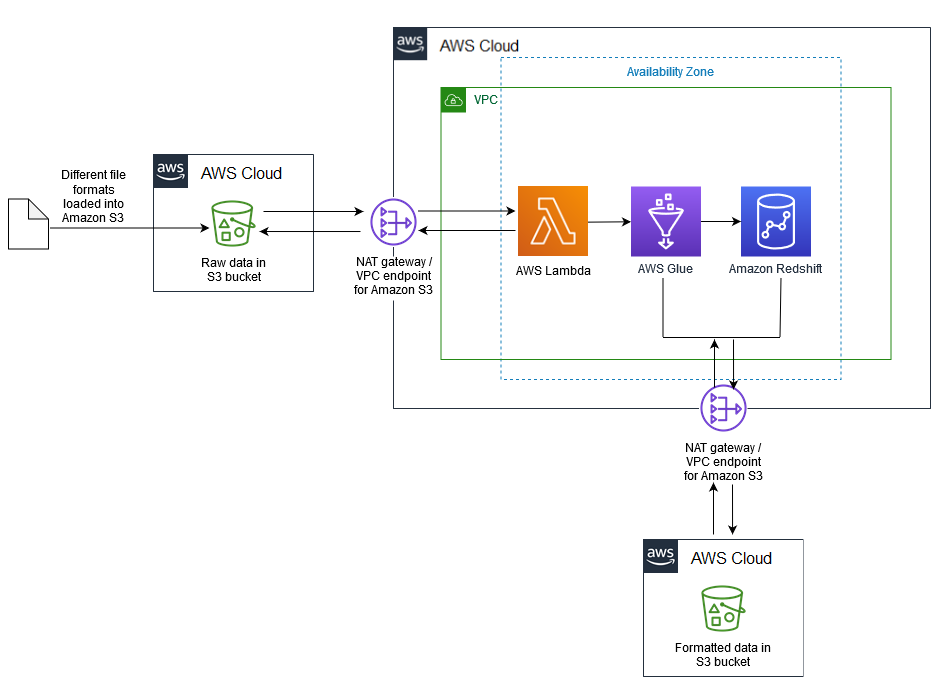
Datenfluss

Tools
Amazon S3
— Amazon Simple Storage Service (Amazon S3) ist ein hoch skalierbarer Objektspeicherservice. Amazon S3 kann für eine Vielzahl von Speicherlösungen verwendet werden, darunter Websites, mobile Anwendungen, Backups und Data Lakes. AWS Lambda
— Mit AWS Lambda können Sie Code ausführen, ohne Server bereitzustellen oder zu verwalten. AWS Lambda ist ein ereignisgesteuerter Service. Sie können Ihren Code so einrichten, dass er automatisch von anderen AWS-Services initiiert wird. Amazon Redshift
— Amazon Redshift ist ein vollständig verwalteter Data-Warehouse-Service im Petabyte-Bereich. Mit Amazon Redshift können Sie Petabyte an strukturierten und halbstrukturierten Daten in Ihrem Data Warehouse und Ihrem Data Lake mithilfe von Standard-SQL abfragen. AWS Glue
— AWS Glue ist ein vollständig verwalteter ETL-Service, der das Aufbereiten und Laden von Daten für Analysen erleichtert. AWS Glue erkennt Ihre Daten und speichert die zugehörigen Metadaten (z. B. Tabellendefinitionen und Schema) im AWS Glue Glue-Datenkatalog. Ihre katalogisierten Daten sind sofort durchsuchbar, können abgefragt werden und sind für ETL verfügbar. AWS Secrets Manager
— AWS Secrets Manager erleichtert den Schutz und die zentrale Verwaltung von Geheimnissen, die für den Anwendungs- oder Servicezugriff benötigt werden. Der Service speichert Datenbankanmeldedaten, API-Schlüssel und andere Geheimnisse und macht es überflüssig, vertrauliche Informationen im Klartextformat fest zu codieren. Secrets Manager bietet auch eine Schlüsselrotation, um Sicherheits- und Compliance-Anforderungen zu erfüllen. Es verfügt über eine integrierte Integration für Amazon Redshift, Amazon Relational Database Service (Amazon RDS) und Amazon DocumentDB. Sie können Geheimnisse speichern und zentral verwalten, indem Sie die Secrets Manager-Konsole, die Befehlszeilenschnittstelle (CLI) oder die Secrets Manager API und verwenden. SDKs Amazon Athena
— Amazon Athena ist ein interaktiver Abfrageservice, der die Analyse von in Amazon S3 gespeicherten Daten vereinfacht. Athena ist serverlos und in AWS Glue integriert, sodass es die mit AWS Glue katalogisierten Daten direkt abfragen kann. Athena ist elastisch skaliert, um interaktive Abfrageleistung zu bieten.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Analysieren Sie Quellsysteme auf Datenstruktur und Attribute. | Führen Sie diese Aufgabe für jede Datenquelle aus, die zum Amazon S3 S3-Data Lake beiträgt. | Dateningenieur |
Definieren Sie die Partitions- und Zugriffsstrategie. | Diese Strategie sollte auf der Häufigkeit der Datenerfassung, der Delta-Verarbeitung und den Nutzungsanforderungen basieren. Stellen Sie sicher, dass S3-Buckets nicht öffentlich zugänglich sind und dass der Zugriff nur durch spezifische, auf Servicerollen basierende Richtlinien gesteuert wird. Weitere Informationen finden Sie in der Amazon S3-Dokumentation. | Dateningenieur |
Erstellen Sie separate S3-Buckets für jeden Datenquellentyp und einen separaten S3-Bucket pro Quelle für die verarbeiteten (Parquet-) Daten. | Erstellen Sie für jede Quelle einen separaten Bucket und anschließend eine Ordnerstruktur, die auf der Datenaufnahmefrequenz des Quellsystems basiert, z. B. | Dateningenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Starten Sie den Amazon Redshift Redshift-Cluster mit den entsprechenden Parametergruppen und der Wartungs- und Sicherungsstrategie. | Verwenden Sie das Secrets Manager Manager-Datenbankgeheimnis für Administratoranmeldedaten, während Sie den Amazon Redshift Redshift-Cluster erstellen. Informationen zur Erstellung und Dimensionierung eines Amazon Redshift Redshift-Clusters finden Sie in der Amazon Redshift Redshift-Dokumentation und im Whitepaper Sizing Cloud Data Warehouses | Dateningenieur |
Erstellen Sie die IAM-Servicerolle und fügen Sie sie dem Amazon Redshift Redshift-Cluster hinzu. | Die Servicerolle AWS Identity and Access Management (IAM) gewährleistet den Zugriff auf Secrets Manager und die S3-Quell-Buckets. Weitere Informationen finden Sie in der AWS-Dokumentation zur Autorisierung und zum Hinzufügen einer Rolle. | Dateningenieur |
Erstellen Sie das Datenbankschema. | Folgen Sie den Best Practices von Amazon Redshift für das Tabellendesign. Wählen Sie je nach Anwendungsfall die geeigneten Sortier- und Verteilungsschlüssel sowie die bestmögliche Komprimierungskodierung aus. Bewährte Methoden finden Sie in der AWS-Dokumentation. | Dateningenieur |
Konfigurieren Sie das Workload-Management. | Konfigurieren Sie je nach Ihren Anforderungen Warteschlangen für Workload Management (WLM), Short Query Acceleration (SQA) oder Parallelitätsskalierung. Weitere Informationen finden Sie unter Implementieren des Workload-Managements in der Amazon Redshift Redshift-Dokumentation. | Dateningenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie ein neues Geheimnis, um die Amazon Redshift Redshift-Anmeldeinformationen in Secrets Manager zu speichern. | In diesem Secret werden die Anmeldeinformationen für den Admin-Benutzer sowie für einzelne Benutzer des Datenbankdienstes gespeichert. Anweisungen finden Sie in der Secrets Manager Manager-Dokumentation. Wählen Sie Amazon Redshift Cluster als geheimen Typ. Aktivieren Sie außerdem auf der Seite „Secret Rotation“ die Rotation. Dadurch wird der entsprechende Benutzer im Amazon Redshift Redshift-Cluster erstellt und die Schlüsselgeheimnisse werden in definierten Intervallen rotiert. | Dateningenieur |
Erstellen Sie eine IAM-Richtlinie, um den Zugriff auf Secrets Manager einzuschränken. | Beschränken Sie den Secrets Manager Manager-Zugriff nur auf Amazon Redshift Redshift-Administratoren und AWS Glue. | Dateningenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Fügen Sie im AWS Glue Glue-Datenkatalog eine Verbindung für Amazon Redshift hinzu. | Anweisungen finden Sie in der AWS Glue Glue-Dokumentation. | Dateningenieur |
Erstellen Sie eine IAM-Servicerolle für AWS Glue und fügen Sie sie hinzu, um auf Secrets Manager-, Amazon Redshift- und S3-Buckets zuzugreifen. | Weitere Informationen finden Sie in der AWS Glue Glue-Dokumentation. | Dateningenieur |
Definieren Sie den AWS Glue Glue-Datenkatalog für die Quelle. | Dieser Schritt beinhaltet die Erstellung einer Datenbank und der erforderlichen Tabellen im AWS Glue Glue-Datenkatalog. Sie können entweder einen Crawler verwenden, um die Tabellen in der AWS Glue Glue-Datenbank zu katalogisieren, oder sie als externe Amazon Athena Athena-Tabellen definieren. Sie können auch über den AWS Glue Glue-Datenkatalog auf die in Athena definierten externen Tabellen zugreifen. Weitere Informationen zur Definition des Datenkatalogs und zur Erstellung einer externen Tabelle in Athena finden Sie in der AWS-Dokumentation. | Dateningenieur |
Erstellen Sie einen AWS Glue Glue-Job zur Verarbeitung von Quelldaten. | Bei dem AWS Glue Glue-Job kann es sich um eine Python-Shell handeln oder PySpark um die Quelldatendateien zu standardisieren, zu deduplizieren und zu bereinigen. Um die Leistung zu optimieren und zu vermeiden, dass der gesamte S3-Quell-Bucket abgefragt werden muss, partitionieren Sie den S3-Bucket nach Datum, aufgeschlüsselt nach Jahr, Monat, Tag und Stunde als Pushdown-Prädikat für den AWS Glue Glue-Job. Weitere Informationen finden Sie in der AWS Glue Glue-Dokumentation. Laden Sie die verarbeiteten und transformierten Daten im Parquet-Format in die verarbeiteten S3-Bucket-Partitionen. Sie können die Parquet-Dateien von Athena abfragen. | Dateningenieur |
Erstellen Sie einen AWS Glue Glue-Job, um Daten in Amazon Redshift zu laden. | Der AWS Glue Glue-Job kann eine Python-Shell sein oder PySpark die Daten laden, indem die Daten aktualisiert werden, gefolgt von einer vollständigen Aktualisierung. Einzelheiten finden Sie in der AWS Glue Glue-Dokumentation und im Abschnitt Zusätzliche Informationen. | Dateningenieur |
(Optional) Planen AWS Glue Glue-Jobs, indem Sie bei Bedarf Trigger verwenden. | Die inkrementelle Datenlast wird hauptsächlich durch ein Amazon S3 S3-Ereignis ausgelöst, das eine AWS Lambda Lambda-Funktion veranlasst, den AWS Glue Glue-Job aufzurufen. Verwenden Sie die triggerbasierte Planung von AWS Glue für alle Datenladungen, die eine zeitbasierte statt einer ereignisbasierten Planung erfordern. | Dateningenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie eine mit dem IAM-Service verknüpfte Rolle für AWS Lambda, um auf S3-Buckets und den AWS Glue Glue-Job zuzugreifen, und fügen Sie sie hinzu. | Erstellen Sie eine mit dem IAM-Service verknüpfte Rolle für AWS Lambda mit einer Richtlinie zum Lesen von Amazon S3 S3-Objekten und -Buckets und einer Richtlinie für den Zugriff auf die AWS Glue Glue-API, um einen AWS Glue Glue-Job zu starten. Weitere Informationen finden Sie im Knowledge Center. | Dateningenieur |
Erstellen Sie eine Lambda-Funktion, um den AWS Glue Glue-Job auf der Grundlage des definierten Amazon S3 S3-Ereignisses auszuführen. | Die Lambda-Funktion sollte durch die Erstellung der Amazon S3-Manifestdatei initiiert werden. Die Lambda-Funktion sollte den Speicherort des Amazon S3 S3-Ordners (z. B. source_bucket/year/month/date/hour) als Parameter an den AWS Glue Glue-Job übergeben. Der AWS Glue Glue-Job verwendet diesen Parameter als Pushdown-Prädikat, um den Dateizugriff und die Auftragsverarbeitungsleistung zu optimieren. Weitere Informationen finden Sie in der AWS Glue Glue-Dokumentation. | Dateningenieur |
Erstellen Sie ein Amazon S3 S3-PUT-Objektereignis, um die Objekterstellung zu erkennen, und rufen Sie die entsprechende Lambda-Funktion auf. | Das Amazon S3 S3-PUT-Objektereignis sollte nur durch die Erstellung der Manifestdatei ausgelöst werden. Die Manifestdatei steuert die Lambda-Funktion und die Parallelität des AWS Glue Glue-Jobs und verarbeitet den Ladevorgang als Batch, anstatt einzelne Dateien zu verarbeiten, die in einer bestimmten Partition des S3-Quell-Buckets ankommen. Weitere Informationen finden Sie in der Lambda-Dokumentation. | Dateningenieur |
Zugehörige Ressourcen
Zusätzliche Informationen
Detaillierter Ansatz für Upsert und Complete Refresh
Upsert: Dies ist für Datensätze vorgesehen, die je nach geschäftlichem Anwendungsfall eine historische Aggregation erfordern. Folgen Sie je nach Ihren Geschäftsanforderungen einem der unter Aktualisieren und Einfügen neuer Daten (Amazon Redshift Redshift-Dokumentation) beschriebenen Methoden.
Vollständige Aktualisierung: Dies ist für kleine Datensätze vorgesehen, für die keine historischen Aggregationen erforderlich sind. Folgen Sie einem der folgenden Ansätze:
Kürzen Sie die Amazon Redshift Redshift-Tabelle.
Lädt die aktuelle Partition aus dem Staging-Bereich
oder:
Erstellen Sie eine temporäre Tabelle mit aktuellen Partitionsdaten.
Löschen Sie die Amazon Redshift Redshift-Zieltabelle.
Benennen Sie die temporäre Tabelle in die Zieltabelle um.
