Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Angebote für Data Mesh
Nutzen Sie die Analysefunktionen, AWS um die auf
-
Implementieren Sie Data Mesh mithilfe von Amazon DataZone
-
Implementieren Sie Data Mesh mithilfe von Open-Source-Frameworks AWS wie data.all
-
Implementieren Sie Data Mesh mithilfe von AWS Lake Formation
Diese drei Optionen verwenden Folgendes AWS-Services:
-
AWS Glue(einschließlich AWS Glue Data Catalog und eines AWS Glue Crawlers)
Die DataZone Amazon-Option verwendet auch Amazon EventBridge.
Für data.all und AWS Lake Formation options werden außerdem die folgenden AWS-Services Ressourcen verwendet:
Die AWS-Services , die Sie in Ihrer Implementierung verwenden, kann je nach den Anforderungen Ihres Unternehmens unterschiedlich sein.
Amazon DataZone
Wenn Sie einen vollständig verwalteten Service nutzen möchten, sollten Sie erwägen, Amazon DataZone zur Implementierung von Data Mesh für Ihr Unternehmen zu verwenden. Amazon DataZone ist ein Datenverwaltungsservice für die Katalogisierung, Erkennung, gemeinsame Nutzung und Verwaltung von Daten, die vor Ort und in AWS Quellen von Drittanbietern gespeichert sind. Das folgende Diagramm zeigt eine auf Amazon basierende Data-Mesh-Referenzarchitektur DataZone.
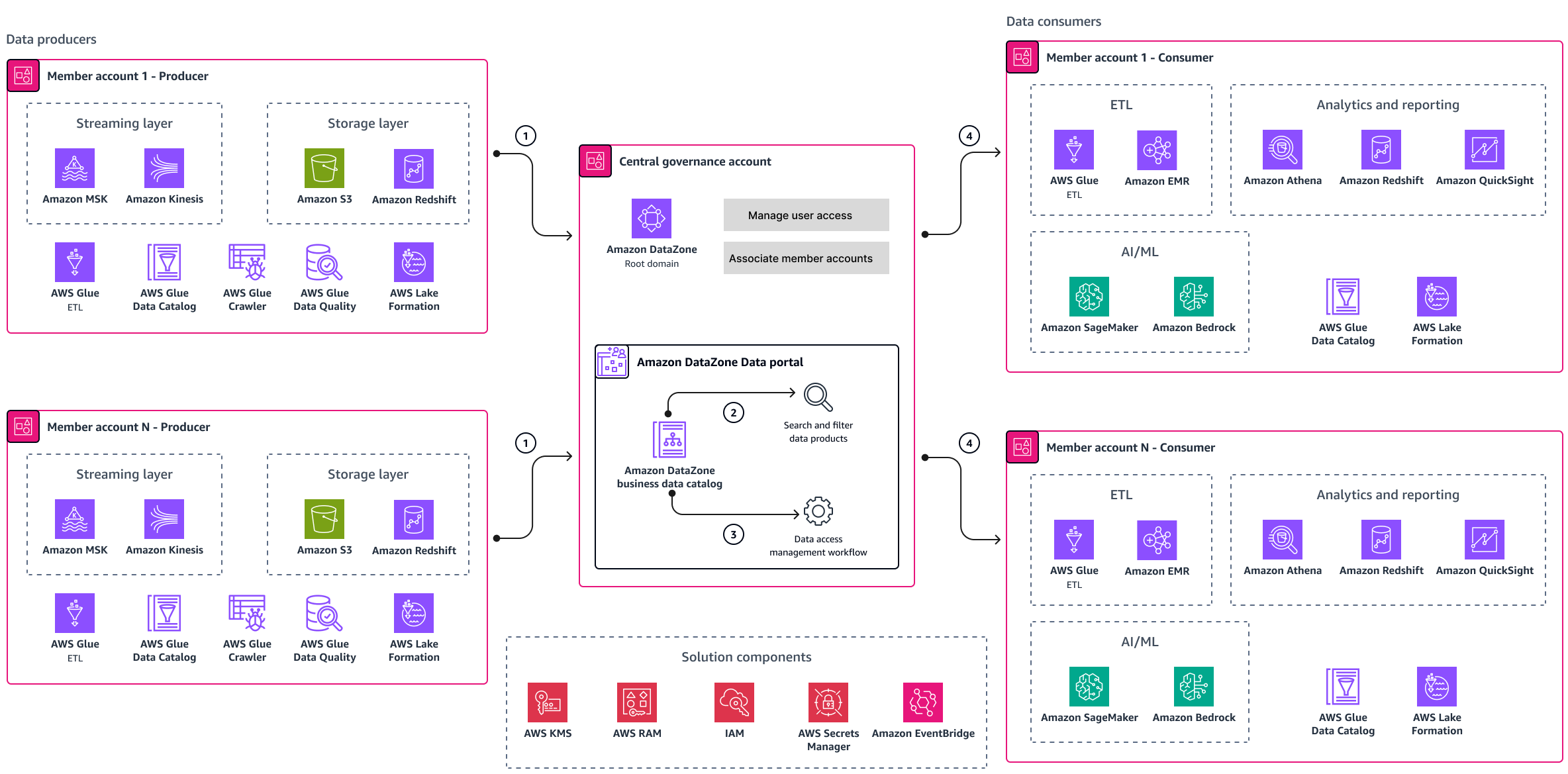
In der Referenzarchitektur gehören die Mitgliedskonten zu den Datendomänen. Sie sind in Datenproduzenten und Datenkonsumenten unterteilt. Das Architekturdiagramm enthält die folgenden Komponenten:
-
Die Datenproduzenten veröffentlichen Datenprodukte im Geschäftskatalog, der vom DataZone Amazon-Datenportal bereitgestellt wird. Das Datenportal wird im zentralen Governance-Konto gehostet.
-
Datenverbraucher (Benutzer) melden sich mit ihren AWS Anmeldeinformationen oder Single Sign-On-Anmeldeinformationen beim Datenportal an. Sie können den Katalog durchsuchen und mithilfe von Schlüsselwörtern nach den Datenprodukten suchen, für die sie sich interessieren. Sie können die Suchergebnisse filtern.
-
Nachdem die Datennutzer, die zu den Verbraucherteams gehören, das für sie interessante Datenprodukt gefunden haben, können sie Zugriff auf die Daten beantragen. Amazon DataZone verfügt über einen integrierten Workflow zur Zugriffsverwaltung, den der Dateninhaber verwendet, um die Anfrage zu überprüfen und zu genehmigen.
-
Die Datenverbraucherteams können die Daten nutzen, um ihre Anwendungsfälle für künstliche Intelligenz und maschinelles Lernen (KI/ML), Analysen und Berichte zu unterstützen sowie Anwendungsfälle zu extrahieren, zu transformieren und zu laden (). ETL
Daten.alles
Wenn Sie sich mit Open Source auskennen und Ihre eigene Lösung erstellen und verwalten möchten, sollten Sie die Verwendung von Open-Source-Frameworks wie data.all in Betracht ziehen.

Das Architekturdiagramm enthält die folgenden Komponenten:
-
Die Datenproduzenten veröffentlichen Datenprodukte in dem Katalog, der vom data.all-Frontend bereitgestellt wird. Das Frontend und das Backend von data.all werden im zentralen Governance-Konto gehostet.
-
Datenverbraucher (Benutzer) melden sich mit ihren Single Sign-On- oder Amazon Cognito Cognito-Anmeldeinformationen beim data.all-Frontend an. Sie können den Katalog durchsuchen und nach den Datenprodukten suchen, die sie interessieren. Sie können die Suchergebnisse filtern.
-
Nachdem die Datennutzer, die zu den Verbraucherteams gehören, das für sie interessante Datenprodukt gefunden haben, können sie den Zugriff auf die Daten beantragen. Data.all verfügt über einen integrierten Workflow zur Zugriffsverwaltung, mit dem der Dateneigentümer Zugriffsanfragen prüft und genehmigt.
-
Die Verbraucherteams können die Daten nutzen, um ihre KI/ML, Analysen und Berichte sowie Anwendungsfälle zu verbessern. ETL
AWS Lake Formation
Wenn Sie von Grund auf eine maßgeschneiderte Data-Mesh-Lösung entwickeln und diese verwalten möchten, sollten Sie die Verwendung dieser Lösung in Betracht ziehen. AWS Lake Formation Lake Formation hilft Ihnen dabei, Daten für Analysen und maschinelles Lernen zentral zu verwalten, zu sichern und weltweit auszutauschen. Das folgende Diagramm zeigt eine Data-Mesh-Referenzarchitektur, die auf Lake Formation basiert.
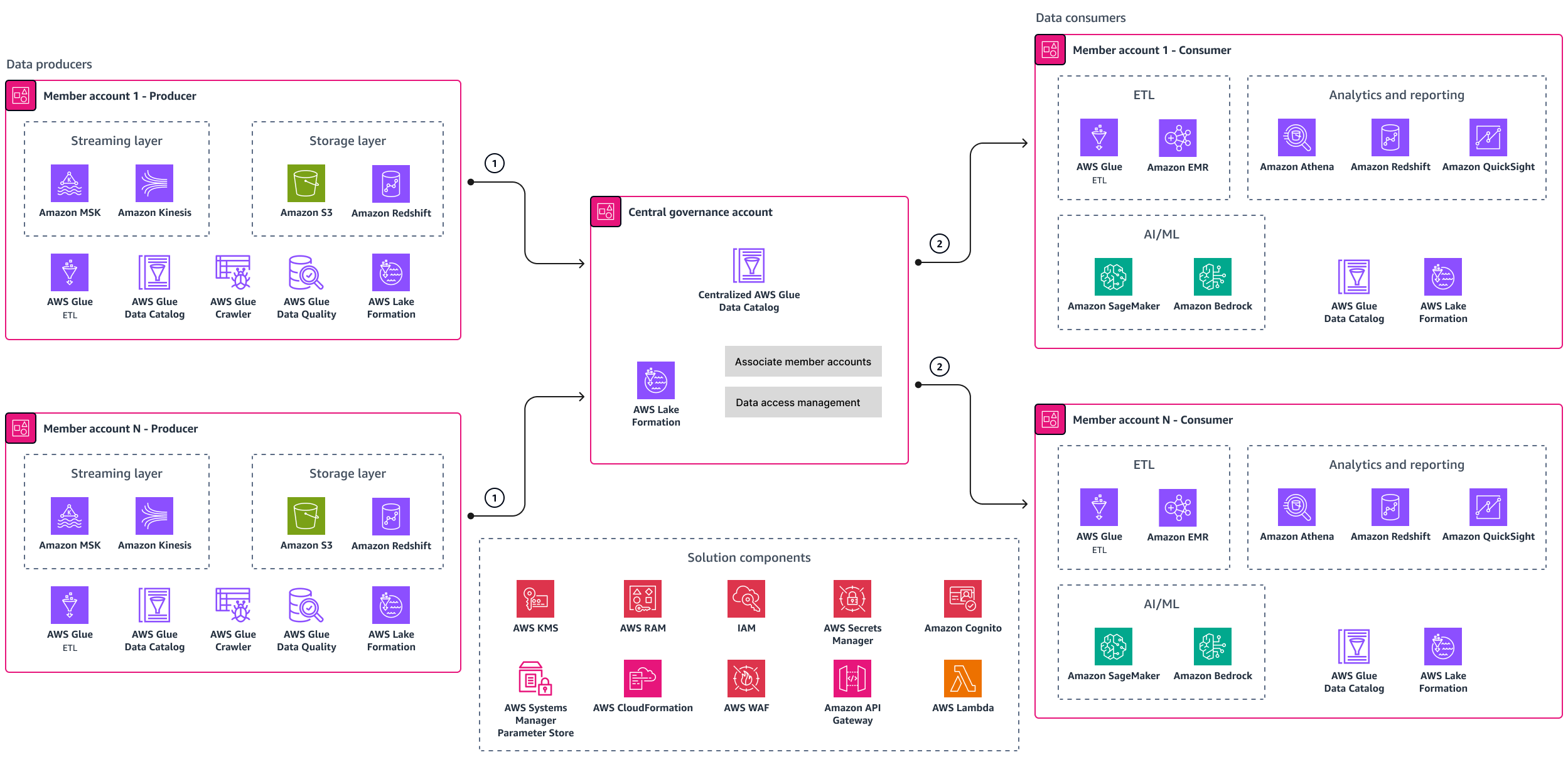
Das Architekturdiagramm enthält die folgenden Komponenten:
-
Die Datenproduzenten veröffentlichen Datenprodukte im AWS Glue Data Catalog zentralen Verwaltungskonto. AWS Lake Formation verwaltet den Zugriff auf die Entitäten des zentralen Datenkatalogs.
-
Sobald der Zugriff gewährt wurde, können die Verbraucherteams die Daten nutzen, um ihre KI/ML, Analysen und Berichte sowie Anwendungsfälle zu verbessern. ETL
