Integration model reference
There are several pre-built integrations for third-party services to help build existing customer tools into the pipeline release process. Partners, or third-party service providers, use an integration model to implement action types for use in CodePipeline.
Use this reference when you are planning or working with action types that are managed with a supported integration model in CodePipeline.
To certify your third-party action type as a partner integration with CodePipeline, reference the AWS Partner Network (APN). This information is a supplement to the AWS CLI Reference.
Topics
How third-party action types work with the integrator
You can add third-party action types to customer pipelines to complete tasks on customer resources. The integrator manages job requests and runs the action with CodePipeline. The following diagram shows a third-party action type created for customers to use in their pipeline. After the customer configures the action, the action runs and creates job requests that are handled by the integrator's action engine.
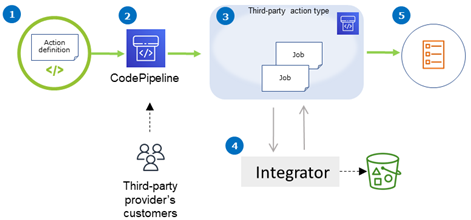
The diagram shows the following steps:
-
The action definition is registered and made available in CodePipeline. The third-party action is available for customers of the third-party provider.
-
The provider's customer chooses and configures the action in CodePipeline.
-
The action runs and jobs are queued in CodePipeline. When the job is ready in CodePipeline, it sends a job request.
-
The integrator (the job worker for third-party polling APIs or the Lambda function) picks up the job request, returns a confirmation, and works on the artifacts for the actions.
-
The integrator returns success/failure output (the job worker uses success/failure APIs or the Lambda function sends success/failure output) with a job result and a continuation token.
For information about the steps you can use to request, view, and update an action type, see Working with action types.
Concepts
This section uses the following terms for third-party action types:
- Action type
-
A repeatable process that can be re-used in pipelines that performs the same continuous delivery workloads. Action types are identified by an
Owner,Category,Provider, andVersion. For example:{ "Category": "Deploy", "Owner": "AWS", "Provider": "CodeDeploy", "Version": "1" },All actions of the same type share the same implementation.
- Action
-
A single instance of an action type, one of the discrete processes that happens inside a stage of a pipeline. This typically includes the user values specific to the pipeline that this action runs in.
- Action definition
-
The schema for an action type that defines the properties required to configure the action and input/output artifacts.
- Action execution
-
A collection of jobs that have been run to determine whether the action on the customer’s pipeline was successful or not.
- Action execution engine
-
A property of the action execution configuration that defines the integration type used by an action type. Valid values are
JobWorkerandLambda. - Integration
-
Describes a piece of software run by an integrator to implement an action type. CodePipeline supports two integration types corresponding to the two supported action engines
JobWorkerandLambda. - Integrator
-
The person who owns the implementation of an action type.
- Job
-
A piece of work with pipeline and customer context to execute an integration. An action execution is composed of one or more jobs.
- Job worker
-
The service that processes the customer input and runs a job.
Supported integration models
CodePipeline has two integration models:
-
Lambda integration model: This integration model is the preferred way to work with action types in CodePipeline. The Lambda integration model uses a Lambda function to process job requests when your action runs.
-
Job worker integration model: The job worker integration model is the previously used model for third-party integrations. The job worker integration model uses a job worker configured to contact the CodePipeline APIs to process job requests when your action runs.
For comparison, the following table describes the features of the two models:
| Lambda integration model | Job worker integration model | |
|---|---|---|
| Description | The integrator writes the integration as a Lambda function, which is invoked by CodePipeline whenever there is a job available for the action. The Lambda function does not poll for available jobs but instead waits until the next job request is received. | The integrator writes the integration as a job worker that polls constantly for available jobs on the customer's pipelines. The job worker then executes the job and submits the job result back to CodePipeline by using CodePipeline APIs. |
| Infrastructure | AWS Lambda | Deploy job worker code to integrator's infrastructure, like Amazon EC2 instances. |
| Development effort | The integration only contains the business logic. | The integration needs to interact with CodePipeline APIs in addition to containing the business logic. |
| Ops effort | Lesser ops effort since infrastructure is only AWS resources. | Higher ops effort because the job worker needs its standalone hardware. |
| Max Job Run Time | If the integration needs to actively run for more than 15 minutes, this model cannot be used. This action is for integrators who need to start a process (for example, initiate a build on customer's code artifact) and return a result when it finishes. We do not recommend that the integrator continue waiting on the build to finish. Instead, return a continuation. CodePipeline creates a new job in another 30 seconds if a continuation is received from the integrator's code to check on the job until it finishes. | Very long running jobs (hours/days) can be sustained using this model. |
Lambda integration model
The supported Lambda integration model includes creating the Lambda function and defining output for the third-party action type.
Update your Lambda function to handle the input from CodePipeline
You can create a new Lambda function. You can add business logic to your Lambda function that is run whenever there’s a job available on your pipeline for your action type. For instance, given the context of the customer and pipeline, you might want to start a build in your service for the customer.
Use the following parameters to update your Lambda function to handle the input from CodePipeline.
Format:
-
jobId:-
The unique system-generated ID of the job.
-
Type: String
-
Pattern: [0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}
-
-
accountId:-
The ID of the customer's AWS account to use when performing the job.
-
Type: String
-
Pattern: [0-9]{12}
-
-
data:-
Other information about a job that an integration uses to complete the job.
-
Contains a map of the following:
-
actionConfiguration:-
The configuration data for the action. The action configuration fields are a mapping of key-value pairs for your customer to enter values. The keys are determined by the key parameters in the action type definition file when you set up your action. In this example, the values are determined by the user of the action specifying information in the
UsernameandPasswordfields. -
Type: String to string map, optionally present
Example:
"configuration": { "Username": "MyUser", "Password": "MyPassword" },
-
-
encryptionKey:-
Represents information about the key used to encrypt data in the artifact store, such as an AWS KMS key.
-
Contents: Type of the data type
encryptionKey, optionally present
-
-
inputArtifacts:-
List of information about an artifact to be worked on, such as a test or build artifact.
-
Contents: List of the data type
Artifact, optionally present
-
-
outputArtifacts:-
List of information about the output of an action.
-
Contents: List of the data type
Artifact, optionally present
-
-
actionCredentials:-
Represents an AWS session credentials object. These credentials are temporary credentials that are issued by AWS STS. They can be used to access input and output artifacts in the S3 bucket used to store artifacts for the pipeline in CodePipeline.
These credentials also have the same permissions as the specified policy statements template in the action type definition file.
-
Contents: Type of the data type
AWSSessionCredentials, optionally present
-
-
actionExecutionId:-
The external ID of the run of the action.
-
Type: String
-
-
continuationToken:-
A system-generated token, such as a deployment ID, required by a job to continue the job asynchronously.
-
Type: String, optionally present
-
-
-
Data Types:
-
encryptionKey:-
id:-
The ID used to identify the key. For an AWS KMS key, you can use the key ID, the key ARN, or the alias ARN.
-
Type: String
-
-
type:-
The type of encryption key, such as an AWS KMS key.
-
Type: String
-
Valid values:
KMS
-
-
-
Artifact:-
name:-
The artifact's name.
-
Type: String, optionally present
-
-
revision:-
The artifact's revision ID. Depending on the type of object, this could be a commit ID (GitHub) or a revision ID (Amazon S3).
-
Type: String, optionally present
-
-
location:-
The location of an artifact.
-
Contents: Type of the data type
ArtifactLocation, optionally present
-
-
-
ArtifactLocation:-
type:-
The type of artifact in the location.
-
Type: String, optionally present
-
Valid values:
S3
-
-
s3Location:-
The location of the S3 bucket that contains a revision.
-
Contents: Type of the data type
S3Location, optionally present
-
-
-
S3Location:-
bucketName:-
The name of the S3 bucket.
-
Type: String
-
-
objectKey:-
The key of the object in the S3 bucket, which uniquely identifies the object in the bucket.
-
Type: String
-
-
-
AWSSessionCredentials:-
accessKeyId:-
The access key for the session.
-
Type: String
-
-
secretAccessKey:-
The secret access key for the session.
-
Type: String
-
-
sessionToken:-
The token for the session.
-
Type: String
-
-
Example:
{ "jobId": "01234567-abcd-abcd-abcd-012345678910", "accountId": "012345678910", "data": { "actionConfiguration": { "key1": "value1", "key2": "value2" }, "encryptionKey": { "id": "123-abc", "type": "KMS" }, "inputArtifacts": [ { "name": "input-art-name", "location": { "type": "S3", "s3Location": { "bucketName": "inputBucket", "objectKey": "inputKey" } } } ], "outputArtifacts": [ { "name": "output-art-name", "location": { "type": "S3", "s3Location": { "bucketName": "outputBucket", "objectKey": "outputKey" } } } ], "actionExecutionId": "actionExecutionId", "actionCredentials": { "accessKeyId": "access-id", "secretAccessKey": "secret-id", "sessionToken": "session-id" }, "continuationToken": "continueId-xxyyzz" } }
Return the results from your Lambda function to CodePipeline
The integrator's job worker resource must return a valid payload in success, failure, or continuation cases.
Format:
-
result: The result of the job.-
Required
-
Valid values (case insensitive):
-
Success: Indicates a job is successful and terminal. -
Continue: Indicates a job is successful and must continue, for example if the job worker is reinvoked for the same action execution. -
Fail: Indicates a job has failed and is terminal.
-
-
-
failureType: A failure type to be associated with a failed job.The
failureTypecategory for partner actions describes the type of failure that was encountered while running the job. Integrators set the type along with the failure message when returning a job failure result back to CodePipeline.-
Optional. Required if result is
Fail. -
Must be null if
resultisSuccessorContinue -
Valid values:
-
ConfigurationError
-
JobFailed
-
PermissionsError
-
RevisionOutOfSync
-
RevisionUnavailable
-
SystemUnavailable
-
-
-
continuation: Continuation state to be passed to the next job within the current action execution.-
Optional. Required if result is
Continue. -
Must be null if
resultisSuccessorFail. -
Properties:
-
State: A hash of the state to be passed.
-
-
-
status: Status of the action execution.-
Optional.
-
Properties:
-
ExternalExecutionId: An optional external execution ID or commit ID to associate with the job. -
Summary: An optional summary of what occurred. In failure scenarios, this becomes the failure message that the user sees.
-
-
-
outputVariables: A set of key/value pairs to be passed to the next action execution.-
Optional.
-
Must be null if
resultisContinueorFail.
-
Example:
{ "result":"success", "failureType": null, "continuation": null, "status": { "externalExecutionId":"my-commit-id-123", "summary":"everything is dandy"}, "outputVariables": { "FirstOne":"Nice", "SecondOne":"Nicest", ... } }
Use continuation tokens to wait for results from an asynchronous process
The continuation token is part of the payload and result of your Lambda
function. It is a way to pass job state to CodePipeline and indicate that the job needs to be
continued. For example, after an integrator starts a build for the customer on their
resource, it does not wait for the build to complete, but indicates to CodePipeline that it does
not havea terminal result by returning the result as continue and
returning the build’s unique ID to CodePipeline as continuation token.
Note
Lambda functions can only run up to 15 minutes. If the job needs to run longer, you can use continuation tokens.
The CodePipeline team invokes the integrator after 30 seconds with the same
continuation token in its payload so that it can check on it for completion.
If the build completes, the integrator returns terminal success/fail result, else
continues.
Provide CodePipeline the permissions to invoke the integrator Lambda function at runtime
You add permissions to your integrator Lambda function to provide the CodePipeline service with
permissions to invoke it using the CodePipeline service principal:
codepipeline.amazonaws.com. You can add permissions by using AWS CloudFormation or the
command line. For an example, see Working with action types.
Job worker integration model
After you have designed your high-level workflow, you can create your job worker. Although the specifics of the third-party action determine what is needed for the job worker, most job workers for third-party actions include the following functionality:
-
Polling for jobs from CodePipeline using
PollForThirdPartyJobs. -
Acknowledging jobs and returning results to CodePipeline using
AcknowledgeThirdPartyJob,PutThirdPartyJobSuccessResult, andPutThirdPartyJobFailureResult. -
Retrieving artifacts from and/or putting artifacts into the Amazon S3 bucket for the pipeline. To download artifacts from the Amazon S3 bucket, you must create an Amazon S3 client that uses Signature Version 4 signing (Sig V4). Sig V4 is required for AWS KMS.
To upload artifacts to the Amazon S3 bucket, you must also configure the Amazon S3
PutObjectrequest to use encryption through AWS Key Management Service (AWS KMS). AWS KMS uses AWS KMS keys. In order to know whether to use the AWS managed key or a customer managed key to upload artifacts, your job worker must look at the job data and check the encryption key property. If the property is set, you should use that customer managed key ID when configuring AWS KMS. If the key property is null, you use the AWS managed key. CodePipeline uses the AWS managed key unless otherwise configured.For an example that shows how to create the AWS KMS parameters in Java or .NET, see Specifying the AWS Key Management Service in Amazon S3 Using the AWS SDKs. For more information about the Amazon S3 bucket for CodePipeline, see CodePipeline concepts.
Choose and configure a permissions management strategy for your job worker
To develop a job worker for your third-party action in CodePipeline, you need a strategy for the integration of user and permission management.
The simplest strategy is to add the infrastructure you need for your job worker by creating Amazon EC2 instances with an AWS Identity and Access Management (IAM) instance role, which allow you to easily scale up the resources you need for your integration. You can use the built-in integration with AWS to simplify the interaction between your job worker and CodePipeline.
Learn more about Amazon EC2 and determine whether it is the right choice for your
integration. For information, see Amazon EC2 - Virtual Server
Hosting
Another strategy to consider is using identity federation with IAM to integrate your
existing identity provider system and resources. This strategy is useful if you already have
a corporate identity provider or are already configured to support users using web identity
providers. Identity federation allows you to grant secure access to AWS resources,
including CodePipeline, without having to create or manage IAM users. You can use features and
policies for password security requirements and credential rotation. You can use sample
applications as templates for your own design. For information, see Manage Federation
To provide access, add permissions to your users, groups, or roles:
-
Users and groups in AWS IAM Identity Center:
Create a permission set. Follow the instructions in Create a permission set in the AWS IAM Identity Center User Guide.
-
Users managed in IAM through an identity provider:
Create a role for identity federation. Follow the instructions in Create a role for a third-party identity provider (federation) in the IAM User Guide.
-
IAM users:
-
Create a role that your user can assume. Follow the instructions in Create a role for an IAM user in the IAM User Guide.
-
(Not recommended) Attach a policy directly to a user or add a user to a user group. Follow the instructions in Adding permissions to a user (console) in the IAM User Guide.
-
The following is an example policy you might create for use with your third-party job worker. This policy is meant as an example only and is provided as-is.
