Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Supervisión de las métricas de los OpenSearch clústeres con Amazon CloudWatch
Amazon OpenSearch Service publica los datos de tus dominios en Amazon CloudWatch. CloudWatch le permite recuperar las estadísticas sobre esos puntos de datos como un conjunto ordenado de datos de series temporales, conocidos como métricas. OpenSearch El servicio envía la mayoría de las métricas CloudWatch en intervalos de 60 segundos. Si utiliza los volúmenes de EBS magnéticos o de uso general, las métricas de volumen de EBS solo se actualizan cada cinco minutos. Todas las métricas acumuladas (por ejemplo, ThreadpoolWriteRejected, ThreadpoolSearchRejected) están en la memoria y perderán estado. Las métricas se restablecerán durante la caída de un nodo, el rebote de un nodo, el reemplazo de un nodo y blue/green el despliegue. Para obtener más información sobre Amazon CloudWatch, consulta la Guía del CloudWatch usuario de Amazon.
La consola OpenSearch de servicio muestra una serie de gráficos basados en los datos sin procesar de CloudWatch. Según sus necesidades, es posible que prefiera ver los datos del clúster en CloudWatch lugar de los gráficos de la consola. El servicio archiva las métricas durante dos semanas antes de eliminarlas. Las métricas se proporcionan sin coste adicional, pero CloudWatch siguen cobrando por la creación de paneles y alarmas. Para obtener más información, consulta los CloudWatchprecios de Amazon
OpenSearch El servicio publica las siguientes métricas en CloudWatch:
Visualización de las métricas en CloudWatch
CloudWatch Las métricas se agrupan primero por el espacio de nombres del servicio y, después, por las distintas combinaciones de dimensiones de cada espacio de nombres.
Para ver las métricas mediante la consola CloudWatch
-
Abra la CloudWatch consola en https://console.aws.amazon.com/cloudwatch/
. -
En el panel de navegación, busque Métricas y elija, Todas las métricas. Seleccione el espacio de OpenSearchService nombres ES/.
-
Seleccione una dimensión para ver las métricas correspondientes. Las métricas de los nodos individuales se encuentran en la dimensión
ClientId, DomainName, NodeId. Las métricas de clúster se encuentran en la dimensiónPer-Domain, Per-Client Metrics. Algunas métricas de nodos se agregan a nivel de clúster y, por lo tanto, se incluyen en ambas dimensiones. Las métricas de particiones se encuentran en la dimensiónClientId, DomainName, NodeId, ShardRole.
Para ver una lista de métricas mediante el AWS CLI
Ejecuta el siguiente comando:
aws cloudwatch list-metrics --namespace "AWS/ES"
Interpretación de las historias clínicas en OpenSearch Service
Para ver las métricas de OpenSearch Service, utilice las pestañas Estado del clúster y Estado de las instancias. La pestaña de estado de la instancia utiliza gráficos de recuadros para proporcionar at-a-glance visibilidad del estado de cada OpenSearch nodo:
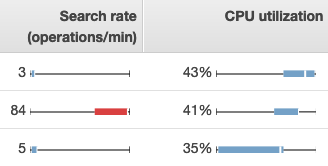
-
Cada cuadro de color muestra el rango de valores correspondiente al nodo durante el periodo de tiempo especificado.
-
Los cuadros azules representan valores que son coherentes con otros nodos. Los cuadros rojos representan los valores atípicos.
-
La línea blanca en cada cuadro muestra el valor actual del nodo.
-
Los “bigotes” a cada lado del cuadro muestran los valores mínimo y máximo de todas las instancias a lo largo del periodo de tiempo.
Cuando se realizan cambios de configuración en el dominio, a menudo la lista de instancias individuales de las pestañas Estado del clúster e Estado de instancia duplica su tamaño durante un breve periodo antes de volver al número correcto. Para obtener una explicación de este comportamiento, consulte Realizar cambios de configuración en Amazon OpenSearch Service.
Métricas de clúster
Amazon OpenSearch Service proporciona las siguientes métricas para los clústeres.
| Métrica | Descripción |
|---|---|
ClusterStatus.green |
Un valor de 1 indica que todas las particiones de índice se han asignado a los nodos del clúster. Estadísticas pertinentes: máximo |
ClusterStatus.yellow |
El valor 1 indica que las particiones principales de todos los índices se han asignado a nodos del clúster, pero las particiones de réplica de al menos un índice están sin asignar. Para más información, consulte Estado amarillo del clúster. Estadísticas pertinentes: Máximo |
ClusterStatus.red |
Un valor de 1 indica que las particiones principal y replicada de al menos un índice no se han asignado a los nodos del clúster. Para más información, consulte Estado rojo del clúster. Estadísticas pertinentes: Máximo |
Shards.active |
El número total de particiones primarias y de réplicas activas. Estadísticas relevantes: Máximo, Suma |
Shards.unassigned |
El número de particiones que no se asignaron a los nodos del clúster. Estadísticas relevantes: Máximo, Suma |
Shards.delayedUnassigned |
El número de particiones cuya asignación de nodos se retrasó por la configuración de tiempo de espera. Estadísticas relevantes: Máximo, Suma |
Shards.activePrimary |
El número de particiones primarias activas. Estadísticas relevantes: Máximo, Suma |
Shards.initializing |
El número de particiones que se encuentran en inicialización. Estadísticas pertinentes: Suma |
Shards.relocating |
El número de particiones que se encuentran en reubicación. Estadísticas pertinentes: suma |
Nodes |
El número de nodos del clúster de OpenSearch servicios, incluidos los nodos maestros dedicados y UltraWarm los nodos. Para obtener más información, consulte Realizar cambios de configuración en Amazon OpenSearch Service. Estadísticas pertinentes: Máximo |
SearchableDocuments |
El número total de documentos que admiten búsquedas para todos los nodos de datos del clúster. Estadísticas pertinentes: mínimo, máximo, promedio |
DeletedDocuments |
El número total de documentos marcados para su eliminación en todos los nodos de datos del clúster. Estos documentos ya no aparecen en los resultados de búsqueda, sino que OpenSearch solo eliminan los documentos eliminados del disco durante la combinación de segmentos. Esta métrica aumenta después de las solicitudes de eliminación y disminuye después de las combinaciones de segmentos. Estadísticas pertinentes: mínimo, máximo, promedio |
CPUUtilization |
El porcentaje de uso de CPU para los nodos de datos del clúster. Máximo muestra el nodo con el mayor uso de CPU. Promedio representa todos los nodos del clúster. Esta métrica también está disponible para los nodos individuales. Estadísticas relevantes: máximo, promedio |
FreeStorageSpace |
El espacio libre para los nodos de datos del clúster. La consola OpenSearch de servicio muestra este valor en GiB. La CloudWatch consola de Amazon lo muestra en MiB. nota
Estadísticas pertinentes: mínimo, máximo, promedio, suma |
ClusterUsedSpace |
El espacio utilizado total para el clúster. Debe dejar el periodo en un minuto para obtener un valor preciso. La consola OpenSearch de servicio muestra este valor en GiB. La CloudWatch consola de Amazon lo muestra en MiB. Estadísticas pertinentes: mínimo, máximo |
ClusterIndexWritesBlocked |
Indica si el clúster acepta o bloquea las solicitudes de escritura entrantes. Un valor de 0 indica que el clúster acepta solicitudes. Un valor de 1 indica que el clúster bloquea las solicitudes. Algunos factores comunes son los siguientes: Estadísticas pertinentes: máximo |
JVMMemoryPressure |
El porcentaje máximo del montón de Java utilizado para todos los nodos de datos del clúster. OpenSearch El servicio utiliza la mitad de la RAM de una instancia para el montón de Java, hasta un tamaño de pila de 32 GiB. Puede escalar las instancias verticalmente hasta 64 GiB de RAM y después escalarlas horizontalmente mediante el agregado de instancias. Consulte CloudWatch Alarmas recomendadas para Amazon OpenSearch Service. Estadísticas pertinentes: máximo notaLa lógica de esta métrica cambió en el software del servicio R20220323. Para más información, consulte las notas de la versión. |
OldGenJVMMemoryPressure |
El porcentaje máximo de la pila de Java que se emplea para la “anterior generación” en todos los nodos de datos del clúster. Esta métrica también está disponible a nivel de nodo. Estadísticas pertinentes: máximo |
AutomatedSnapshotFailure |
El número de instantáneas automatizadas que han producido un error para el clúster. Un valor de Estadísticas pertinentes: mínimo, máximo |
CPUCreditBalance |
Los créditos de CPU restantes que están disponibles para los nodos de datos del clúster. Un crédito de CPU proporciona el desempeño de un núcleo de CPU completo durante un minuto. Para obtener más información, consulta los créditos de CPU en la Guía para EC2 desarrolladores de Amazon. Esta métrica solo está disponible para el tipo de instancias T2. Estadísticas pertinentes: mínimo |
OpenSearchDashboardsHealthyNodes |
Una comprobación del estado de los OpenSearch paneles de control. Si el mínimo, el máximo y el promedio son todos iguales a 1, Dashboards se comporta con normalidad. Si tiene 10 nodos con un máximo de 1, mínimo de 0 y promedio de 0,7, esto significa que 7 nodos (70 %) están en buen estado y 3 nodos (30 %) no lo están. Estadísticas pertinentes: mínimo, máximo, promedio |
OpensearchDashboardsReportingFailedRequestSysErrCount |
El número de solicitudes para generar informes de OpenSearch paneles de control que fallaron debido a problemas con el servidor o limitaciones de las funciones. Estadísticas pertinentes: suma |
OpensearchDashboardsReportingFailedRequestUserErrCount |
El número de solicitudes para generar informes de OpenSearch paneles de control que fallaron debido a problemas con los clientes. Estadísticas pertinentes: suma |
OpensearchDashboardsReportingRequestCount |
El número total de solicitudes para generar informes de OpenSearch cuadros de mando. Estadísticas pertinentes: suma |
OpensearchDashboardsReportingSuccessCount |
El número de solicitudes aceptadas para generar informes de OpenSearch paneles de control. Estadísticas pertinentes: suma |
KMSKeyError |
Un valor de 1 indica que la AWS KMS clave utilizada para cifrar los datos en reposo se ha desactivado. Para restablecer el dominio a operaciones normales, rehabilita la clave. La consola solo muestra esta métrica para los dominios que encriptan los datos en reposo. Estadísticas pertinentes: mínimo, máximo |
KMSKeyInaccessible |
Un valor de 1 indica que la AWS KMS clave utilizada para cifrar los datos en reposo se ha eliminado o se ha revocado su concesión al Servicio. OpenSearch No puede recuperar los dominios que están en este estado. Sin embargo, si tiene una instantánea manual, puede utilizarla para migrar los datos del dominio a un nuevo dominio. La consola solo muestra esta métrica para los dominios que encriptan los datos en reposo. Estadísticas pertinentes: mínimo, máximo |
InvalidHostHeaderRequests |
El número de solicitudes HTTP realizadas al OpenSearch clúster que incluían un encabezado de host no válido (o faltante). Las solicitudes válidas incluyen el nombre de host del dominio como valor del encabezado del host. OpenSearch El servicio rechaza las solicitudes no válidas de dominios de acceso público que no tengan una política de acceso restrictiva. Es recomendable que aplique una política de acceso restrictiva a todos los dominios. Si se muestran valores altos para esta métrica, confirme que sus clientes de OpenSearch incluyen el nombre de host del dominio (y no, por ejemplo, su dirección IP) en sus solicitudes. Estadísticas pertinentes: suma |
OpenSearchRequests (previously
ElasticsearchRequests) |
El número de solicitudes realizadas al OpenSearch clúster. Estadísticas pertinentes: suma |
2xx, 3xx, 4xx, 5xx |
El número de solicitudes para el dominio que produjeron el código de respuesta HTTP especificado (2xx, 3xx, 4xx, 5xx). Estadísticas pertinentes: suma |
ThroughputThrottle |
Indica si los discos se han limitado o no. La limitación se produce cuando el rendimiento combinado de Para obtener más información sobre el rendimiento de la instancia, consulte Instancias optimizadas para Amazon EBS. Para obtener información sobre el rendimiento del volumen, consulte Tipos de volúmenes de Amazon EBS Estadísticas pertinentes: mínimo, máximo |
IopsThrottle |
Indica si se ha reducido o no el número de input/output operaciones por segundo (IOPS) en el dominio. La limitación se produce cuando las IOPS del nodo de datos superan el límite máximo permitido del volumen de EBS o de la instancia del nodo de datos. EC2 Para obtener más información sobre IOPS de instancias, consulte Tipos de instancias optimizadas para Amazon EBS. Para obtener información sobre IOPS de volúmenes, consulte Amazon EBS volume types Estadísticas pertinentes: mínimo, máximo |
HighSwapUsage |
Un valor de 1 indica que el intercambio debido a errores de página puede provocar picos en el uso del disco subyacente durante un periodo de tiempo específico. Estadísticas pertinentes: máximo |
Métricas de nodo maestro dedicado
Amazon OpenSearch Service proporciona las siguientes métricas para los nodos maestros dedicados.
| Métrica | Descripción |
|---|---|
MasterCPUUtilization |
El porcentaje máximo de recursos de CPU que se utilizan en los nodos maestros dedicados. Recomendamos aumentar el tamaño del tipo de instancia cuando esta métrica alcance el 60 por ciento. Estadísticas pertinentes: máximo |
MasterFreeStorageSpace |
Esta métrica no es pertinente y puede pasarse por alto. El servicio no usa los nodos maestros como nodos de datos. |
MasterJVMMemoryPressure |
El porcentaje máximo del montón de Java que se emplea para todos los nodos maestros dedicados del clúster. Recomendamos cambiar a un tipo de instancia mayor cuando esta métrica alcance el 85 por ciento. Estadísticas pertinentes: máximo notaLa lógica de esta métrica cambió en el software del servicio R20220323. Para más información, consulte las notas de la versión. |
MasterOldGenJVMMemoryPressure |
El porcentaje máximo de la pila de Java que se emplea para la “anterior generación” según el nodo maestro. Estadísticas pertinentes: máximo |
MasterCPUCreditBalance |
Los créditos de CPU restantes que están disponibles para los nodos maestros dedicados del clúster. Un crédito de CPU proporciona el desempeño de un núcleo de CPU completo durante un minuto. Para obtener más información, consulta los créditos de CPU en la Guía para EC2 desarrolladores de Amazon. Esta métrica solo está disponible para el tipo de instancias T2. Estadísticas pertinentes: mínimo |
MasterReachableFromNode |
Comprobación de estado de las excepciones Los errores significan que no se puede acceder al nodo maestro desde el nodo de origen. Suelen ser el resultado de un problema de conectividad de red o de AWS dependencia. Estadísticas pertinentes: máximo |
MasterSysMemoryUtilization |
El porcentaje de memoria del nodo maestro que está en uso. Estadísticas pertinentes: máximo |
Métricas de nodos coordinadores dedicados
Amazon OpenSearch Service proporciona las siguientes métricas para los nodos coordinadores dedicados.
| Métrica | Descripción |
|---|---|
CoordinatorCPUUtilization |
El porcentaje máximo de recursos de CPU que se utilizan en los nodos coordinadores dedicados. Recomendamos aumentar el tamaño del tipo de instancia cuando esta métrica alcance el 80 %. Estadísticas pertinentes: máximo |
CoordinatorJVMMemoryPressure |
El porcentaje máximo del montón de Java que se emplea para todos los nodos coordinadores dedicados del clúster. Recomendamos cambiar a un tipo de instancia mayor cuando esta métrica alcance el 85 por ciento. Estadísticas pertinentes: máximo |
CoordinatorOldGenJVMMemoryPressure |
El porcentaje máximo de la pila de Java que se emplea para la “anterior generación” según el nodo maestro. Estadísticas pertinentes: máximo |
CoordinatorSysMemoryUtilization |
El porcentaje de la memoria del nodo coordinador que está en uso. Estadísticas pertinentes: máximo |
CoordinatorFreeStorageSpace |
Esta métrica indica que el servicio no usa los nodos coordinadores como nodos de datos. |
Métricas de volumen de EBS
Amazon OpenSearch Service proporciona las siguientes métricas para los volúmenes de EBS.
| Métrica | Descripción |
|---|---|
ReadLatency |
La latencia en segundos para las operaciones de lectura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
WriteLatency |
La latencia en segundos para las operaciones de escritura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
ReadThroughput |
El rendimiento en bytes por segundo para las operaciones de lectura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
ReadThroughputMicroBursting |
Se tiene en cuenta el rendimiento, en bytes por segundo, de las operaciones de lectura en volúmenes de EBS cuando se tiene en cuenta la microrráfaga Estadísticas pertinentes: mínimo, máximo, promedio |
WriteThroughput |
El rendimiento en bytes por segundo para las operaciones de escritura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
WriteThroughputMicroBursting |
Se tiene en cuenta el rendimiento, en bytes por segundo, de las operaciones de escritura en volúmenes de EBS cuando se tiene en cuenta la microrráfaga Estadísticas pertinentes: mínimo, máximo, promedio |
DiskQueueDepth |
El número de solicitudes de entrada y salida (E/S) pendientes de un volumen de EBS. Estadísticas pertinentes: mínimo, máximo, promedio |
ReadIOPS |
El número de operaciones de entrada y salida (E/S) por segundo para las operaciones de lectura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
ReadIOPSMicroBursting |
El número de operaciones de entrada y salida (E/S) por segundo para las operaciones de lectura en los volúmenes de EBS cuando se tiene en cuenta la microrráfaga Estadísticas pertinentes: mínimo, máximo, promedio |
WriteIOPS |
El número de operaciones de entrada y salida (E/S) por segundo para las operaciones de escritura en los volúmenes de EBS. Esta métrica también está disponible para los nodos individuales. Estadísticas pertinentes: mínimo, máximo, promedio |
WriteIOPSMicroBursting |
El número de operaciones de entrada y salida (E/S) por segundo para las operaciones de escritura en los volúmenes de EBS cuando se tiene en cuenta la microrráfaga Estadísticas pertinentes: mínimo, máximo, promedio |
BurstBalance |
El porcentaje de los créditos de entrada y salida (E/S) que quedan en el bucket de ráfaga para un volumen de EBS. Un valor de 100 significa que el volumen ha acumulado el número máximo de créditos. Si este porcentaje cae por debajo del 70 %, consulte Bajo balance de ráfaga EBS. El balance de ráfagas se mantiene en 0 para los dominios con tipos de volúmenes gp3, así como para los dominios con volúmenes gp2 que tengan un tamaño de volumen superior a 1000 GiB. Estadísticas pertinentes: mínimo, máximo, promedio |
VolumeStalledIOcheck |
El estado de sus volúmenes de EBS para determinar cuándo están agotados. La métrica es un valor binario que devuelve un estado de 0 (aprobación) o 1 (error) en función de si el volumen de EBS puede completar las operaciones de entrada y salida. Estadísticas pertinentes: mínimo, máximo, promedio |
Métricas de la instancia
Amazon OpenSearch Service proporciona las siguientes métricas para cada instancia de un dominio. OpenSearch El servicio también agrega estas métricas de instancias para proporcionar información sobre el estado general del clúster. Puede verificar este comportamiento mediante la estadística Recuento de muestras en la consola. Tenga en cuenta que las métricas de la tabla siguiente disponen de estadísticas relevantes para el nodo y el clúster.
importante
Las diferentes versiones de Elasticsearch utilizan diferentes grupos de subprocesos para procesar las llamadas a la API _index. Elasticsearch 1.5 y 2.3 utilizan el grupo de subprocesos de indexación. Elasticsearch 5. x, 6.0 y 6.2 utilizan el grupo de subprocesos masivos. OpenSearch y Elasticsearch 6.3 y versiones posteriores usan el grupo de subprocesos de escritura. Actualmente, la consola OpenSearch de servicio no incluye un gráfico para el grupo de subprocesos masivos.
Utilice GET _cluster/settings?include_defaults=true para verificar el tamaño del grupo de subprocesos y las colas para el clúster.
| Métrica | Descripción |
|---|---|
FetchLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las operaciones de búsqueda de fragmentos en un nodo entre el minuto N y el minuto (N - 1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
FetchRate |
El número total de operaciones de recuperación de fragmentos por minuto para todos los fragmentos de un nodo de datos. Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo, suma |
ScrollTotal |
El número total de operaciones de desplazamiento de fragmentos por minuto para todos los fragmentos de un nodo de datos. Estadísticas de nodos relevantes: promedio, máximo Estadísticas de clúster pertinentes: promedio, máximo, suma |
ScrollCurrent |
El número de operaciones de desplazamiento de fragmentos que se están ejecutando actualmente. Estadísticas de nodos relevantes: media y máxima Estadísticas de clúster pertinentes: promedio, máximo, suma |
OpenContexts |
El número de contextos de búsqueda abiertos. Estadísticas de nodos relevantes: promedio, máximo Estadísticas de clúster pertinentes: promedio, máximo, suma |
ThreadCount |
El número total de subprocesos que utiliza actualmente el OpenSearch proceso. Estadísticas de nodos relevantes: promedio, máximo Estadísticas de clúster pertinentes: promedio, máximo, suma |
ShardReactivateCount |
El número total de veces que todos los fragmentos se han activado desde un estado inactivo. Estadísticas de nodos relevantes: suma, máximo Estadísticas de conglomerados relevantes: suma, máximo |
ConcurrentSearchRate |
El número total de solicitudes de búsqueda con búsqueda de segmentos simultánea por minuto de todas las particiones de un nodo de datos. Una sola llamada a la API Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo, suma |
ConcurrentSearchLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las búsquedas que usan la búsqueda de segmentos simultánea en un nodo entre el minuto N y el minuto (N-1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
IndexingLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las operaciones de indexación en un nodo entre el minuto N y el minuto (N-1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
IndexingRate |
El número de operaciones de indexación por minuto. Una sola llamada a la API Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo, suma |
SearchLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las búsquedas en un nodo entre el minuto N y el minuto (N-1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
SearchRate |
El número total de peticiones de búsqueda por minuto de todas las particiones de un nodo de datos. Una sola llamada a la API Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo, suma |
SegmentCount |
El número de segmentos de un nodo de datos. Cuantos más segmentos tenga, más tardará cada búsqueda. OpenSearch de vez en cuando fusiona segmentos más pequeños en uno más grande. Estadísticas de nodo pertinentes: máximo, promedio Estadísticas de clúster pertinentes: suma, máximo, promedio |
SysMemoryUtilization |
El porcentaje de memoria de la instancia que está en uso. Es normal obtener valores altos para esta métrica y, por lo general, no representan un problema con el clúster. Para obtener un mejor indicador de posibles problemas de rendimiento y estabilidad, consulte la métrica Estadísticas de nodo pertinentes: mínimo, máximo, promedio Estadísticas de clúster pertinentes: mínimo, máximo, promedio |
JVMGCYoungCollectionCount |
Número de veces que se ha ejecutado la recopilación de elementos no utilizados “nueva generación”. Un número grande y en continuo crecimiento de ejecuciones es normal para las operaciones de clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
JVMGCYoungCollectionTime |
La cantidad de tiempo en milisegundos que el clúster ha empleado en realizar la recopilación de elementos no utilizados “nueva generación”. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
JVMGCOldCollectionCount |
Número de veces que se ha ejecutado la recopilación de elementos no utilizados “generación anterior”. En un clúster con suficientes recursos, este número debe ser pequeño y crecer con poca frecuencia. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
JVMGCOldCollectionTime |
La cantidad de tiempo en milisegundos que el clúster ha empleado en realizar la recopilación de elementos no utilizados “generación anterior”. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
OpenSearchDashboardsConcurrentConnections |
El número de conexiones simultáneas activas a OpenSearch los paneles de control. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
OpenSearchDashboardsHealthyNode |
Una comprobación del estado del nodo individual de los OpenSearch paneles de control. Un valor de 1 indica un comportamiento normal. Un valor de 0 indica que Dashboards es inaccesible. Estadísticas de nodo pertinentes: mínimo Estadísticas de clúster pertinentes: mínimo, máximo, promedio |
OpenSearchDashboardsHeapTotal |
La cantidad de memoria dinámica asignada a los OpenSearch paneles en MiB. Los diferentes tipos de EC2 instancias pueden afectar a la asignación exacta de memoria. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
OpenSearchDashboardsHeapUsed |
La cantidad absoluta de memoria dinámica que utilizan los OpenSearch paneles de control en MiB. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
OpenSearchDashboardsHeapUtilization |
El porcentaje máximo de memoria de pila disponible que utilizan los paneles. OpenSearch Si este valor aumenta por encima del 80 %, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: mínimo, máximo, promedio |
OpenSearchDashboardsOS1MinuteLoad |
El promedio de carga de CPU en un minuto para los paneles. OpenSearch La carga de la CPU idealmente debería permanecer por debajo de 1,00. Aunque los picos temporales están bien, se recomienda aumentar el tamaño del tipo de instancias si esta métrica está constantemente por encima de 1,00. Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
OpenSearchDashboardsRequestTotal |
El recuento total de solicitudes HTTP realizadas a OpenSearch Dashboards. Si su sistema es lento o ve un número elevado de solicitudes de Dashboards, considere aumentar el tamaño del tipo de instancias. Estadísticas de nodos pertinentes: suma Estadísticas de clúster pertinentes: suma |
OpenSearchDashboardsResponseTimesMaxInMillis |
El tiempo máximo, en milisegundos, que tarda OpenSearch Dashboards en responder a una solicitud. Si las solicitudes tardan mucho tiempo en devolver resultados, considere aumentar el tamaño del tipo de instancias. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: máximo, promedio |
SearchTaskCancelled |
El número de cancelaciones del nodo coordinador. Estadísticas de nodos pertinentes: suma Estadísticas de clúster pertinentes: suma |
SearchShardTaskCancelled |
El número de cancelaciones del nodo de datos. Estadísticas de nodos pertinentes: suma Estadísticas de clúster pertinentes: suma, |
ThreadpoolForce_mergeQueue |
El número de tareas en cola en el grupo de subprocesos de combinación forzada. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
ThreadpoolForce_mergeRejected |
El número de tareas rechazadas en el grupo de subprocesos de combinación forzada. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
ThreadpoolForce_mergeThreads |
El tamaño del grupo de subprocesos de combinación forzada. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolIndexQueue |
El número de tareas en cola en el grupo de subprocesos de indexación. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. El tamaño de la cola de indexación máximo es 200. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
ThreadpoolIndexRejected |
El número de tareas rechazadas en el grupo de subprocesos de indexación. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
ThreadpoolIndexThreads |
El tamaño del grupo de subprocesos de indexación. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolSearchQueue |
El número de tareas en cola en el grupo de subprocesos de búsqueda. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. El tamaño máximo de la cola de búsqueda es 1000. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
ThreadpoolSearchRejected |
El número de tareas rechazadas en el grupo de subprocesos de búsqueda. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
ThreadpoolSearchThreads |
El tamaño del grupo de subprocesos de búsqueda. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
Threadpoolsql-workerQueue |
El número de tareas en cola en el grupo de subprocesos de búsqueda de SQL. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
Threadpoolsql-workerRejected |
El número de tareas rechazadas en el grupo de subprocesos de búsqueda de SQL. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
Threadpoolsql-workerThreads |
El tamaño del grupo de subprocesos de búsqueda de SQL. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolBulkQueue |
El número de tareas en cola en el grupo de subprocesos por lotes. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
ThreadpoolBulkRejected |
El número de tareas rechazadas en el grupo de subprocesos por lotes. Si este número crece continuamente, considere la posibilidad de escalar el clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
ThreadpoolBulkThreads |
El tamaño del grupo de subprocesos por lotes. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolIndexSearcherQueue |
El número de tareas en cola del grupo de subprocesos del buscador de índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
ThreadpoolIndexSearcherRejected |
El número de tareas rechazadas en el grupo de subprocesos del buscador de índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
ThreadpoolIndexSearcherThreads |
El tamaño del grupo de subprocesos del buscador de índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolWriteThreads |
El tamaño del grupo de subprocesos de escritura. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolWriteQueue |
El número de tareas en cola en el grupo de subprocesos de escritura. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
ThreadpoolWriteRejected |
El número de tareas rechazadas en el grupo de subprocesos de escritura. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma notaComo el tamaño predeterminado de la cola de escritura se incrementó de 200 a 10 000 en la versión 7.1, esta métrica ya no es el único indicador de los rechazos de Service. OpenSearch Utilice las métricas |
CoordinatingWriteRejected |
El número total de rechazos se produjo en el nodo coordinador debido a la presión de indexación desde el último OpenSearch inicio del proceso de servicio. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
PrimaryWriteRejected |
El número total de rechazos se produjo en los fragmentos principales debido a la presión de indexación desde el último inicio del proceso de servicio. OpenSearch Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
ReplicaWriteRejected |
El número total de rechazos que se produjeron en los fragmentos de réplica se debió a la presión ejercida por la indexación desde el último inicio del proceso de servicio. OpenSearch Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
WorkloadManagementEnabled |
Indica si la función de administración de la carga de trabajo está habilitada. Un valor de 1 significa que está habilitada y un valor de 0 significa que está Estadísticas de nodo relevantes: máximo, mínimo Estadísticas de clúster pertinentes: promedio, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
SoftQueryGroupCount |
Número de grupos de consultas en modo flexible en el dominio. Estadísticas de nodos relevantes: promedio, máximo Estadísticas de clúster pertinentes: promedio, máximo, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
EnforcedQueryGroupCount |
Número de grupos de consultas en modo obligatorio en el dominio. Estadísticas de nodos relevantes: promedio, máximo Estadísticas de clúster pertinentes: promedio, máximo, suma Esta métrica está disponible en la versión 7.1 y posteriores. |
UltraWarm métricas
Amazon OpenSearch Service proporciona las siguientes métricas para UltraWarmlos nodos.
| Métrica | Descripción |
|---|---|
WarmCPUUtilization |
El porcentaje de uso de la CPU para UltraWarm los nodos del clúster. Máximo muestra el nodo con el mayor uso de CPU. El promedio representa todos UltraWarm los nodos del clúster. Esta métrica también está disponible para UltraWarm nodos individuales. Estadísticas relevantes: máximo, promedio |
WarmFreeStorageSpace |
La cantidad de espacio de almacenamiento en caliente libre en MiB. Dado que UltraWarm utiliza Amazon S3 en lugar de discos adjuntos, Estadísticas pertinentes: suma |
WarmSearchableDocuments |
Número total de documentos en los que se pueden realizar búsquedas de todos los índices templados del clúster. Debe dejar el periodo en un minuto para obtener un valor preciso. Estadísticas pertinentes: suma |
WarmSearchLatency
|
La diferencia en el tiempo total, en milisegundos, que registran todas las búsquedas UltraWarm entre el minuto N y el minuto (N-1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo |
WarmSearchRate
|
El número total de solicitudes de búsqueda por minuto para todos los fragmentos de un UltraWarm nodo. Una sola llamada a la API Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: promedio, máximo, suma |
WarmStorageSpaceUtilization |
Cantidad total del espacio de almacenamiento templado, en MiB, que utiliza el clúster. Estadísticas pertinentes: máximo |
HotStorageSpaceUtilization
|
Cantidad total del espacio de almacenamiento en caliente que utiliza el clúster. Estadísticas pertinentes: máximo |
WarmSysMemoryUtilization |
Porcentaje de la memoria del nodo maestro que está en uso. Estadísticas pertinentes: máximo |
HotToWarmMigrationQueueSize
|
Número de índices a la espera actualmente para migrar del almacenamiento caliente al almacenamiento templado. Estadísticas pertinentes: máximo |
WarmToHotMigrationQueueSize
|
Número de índices a la espera actualmente para migrar del almacenamiento templado al almacenamiento caliente. Estadísticas pertinentes: máximo |
HotToWarmMigrationFailureCount
|
El número total de errores de migración del almacenamiento en caliente al almacenamiento templado. Estadísticas pertinentes: suma |
HotToWarmMigrationForceMergeLatency
|
Latencia media de la etapa de fusión de fuerzas del proceso de migración. Si esta etapa lleva demasiado tiempo, considere aumentar Estadísticas pertinentes: promedio |
HotToWarmMigrationSnapshotLatency
|
Latencia media de la etapa de instantánea del proceso de migración. Si esta etapa tarda demasiado tiempo, asegúrese de que las particiones estén correctamente dimensionadas y distribuidas por todo el clúster. Estadísticas pertinentes: promedio |
HotToWarmMigrationProcessingLatency
|
La latencia media de migraciones exitosas del almacenamiento en caliente al almacenamiento templado, sin incluir el tiempo que estuvo en la cola. Este valor es la suma de la cantidad de tiempo que se tarda en completar las etapas de fusión de fuerza, instantánea y reubicación de particiones del proceso de migración. Estadísticas pertinentes: promedio |
HotToWarmMigrationSuccessCount
|
El número total de migraciones exitosas del almacenamiento en caliente al almacenamiento templado. Estadísticas pertinentes: suma |
HotToWarmMigrationSuccessLatency
|
La latencia media de migraciones exitosas del almacenamiento en caliente al almacenamiento templado, incluido el tiempo que estuvo en la cola. Estadísticas pertinentes: promedio |
WarmThreadpoolSearchThreads |
El tamaño del conjunto de hilos UltraWarm de búsqueda. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: promedio, suma |
WarmThreadpoolSearchRejected |
El número de tareas rechazadas en el grupo UltraWarm de hilos de búsqueda. Si este número aumenta continuamente, considere la posibilidad de añadir más UltraWarm nodos. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
WarmThreadpoolSearchQueue |
El número de tareas en cola en el grupo de hilos UltraWarm de búsqueda. Si el tamaño de la cola es siempre alto, considere la posibilidad de añadir más UltraWarm nodos. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmJVMMemoryPressure |
El porcentaje máximo del montón de Java utilizado para los UltraWarm nodos. Estadísticas pertinentes: máximo notaLa lógica de esta métrica cambió en el software del servicio R20220323. Para más información, consulte las notas de la versión. |
WarmOldGenJVMMemoryPressure |
El porcentaje máximo del montón de Java utilizado para la «generación anterior» por UltraWarm nodo. Estadísticas pertinentes: máximo |
WarmJVMGCYoungCollectionCount |
El número de veces que la recolección de basura de la «generación joven» se ha ejecutado en UltraWarm los nodos. Un número grande y en continuo crecimiento de ejecuciones es normal para las operaciones de clúster. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmJVMGCYoungCollectionTime |
La cantidad de tiempo, en milisegundos, que el clúster ha dedicado a la recolección de basura de la «generación joven» en UltraWarm los nodos. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmJVMGCOldCollectionCount |
El número de veces que la recolección de basura de la «generación anterior» se ha ejecutado en UltraWarm los nodos. En un clúster con suficientes recursos, este número debe ser pequeño y crecer con poca frecuencia. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmConcurrentSearchRate |
El número total de solicitudes de búsqueda que utilizan la búsqueda de segmentos simultánea por minuto para todos los fragmentos de un UltraWarm nodo. Una sola llamada a la API Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmConcurrentSearchLatency |
La diferencia en el tiempo total, en milisegundos, obtenida por todas las búsquedas que utilizan la búsqueda de segmentos simultánea en un UltraWarm nodo entre el minuto N y el minuto (N-1). Estadísticas de nodo pertinentes: promedio Estadísticas de clúster pertinentes: máximo, promedio |
WarmThreadpoolIndexSearcherQueue |
El número de tareas en cola en el conjunto de subprocesos del buscador UltraWarm de índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, máximo, promedio |
WarmThreadpoolIndexSearcherRejected |
El número de tareas rechazadas en el grupo de subprocesos del buscador de UltraWarm índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma |
WarmThreadpoolIndexSearcherThreads |
El tamaño del conjunto de subprocesos del buscador de UltraWarm índices. Estadísticas de nodo pertinentes: máximo Estadísticas de clúster pertinentes: suma, promedio |
Métricas de almacenamiento en frío
Amazon OpenSearch Service proporciona las siguientes métricas para el almacenamiento en frío.
| Métrica | Descripción |
|---|---|
ColdStorageSpaceUtilization
|
La cantidad total de espacio de almacenamiento en frío, en MiB, que el clúster utiliza. Estadísticas pertinentes: máximo |
ColdToWarmMigrationFailureCount |
El número total de errores de migración del almacenamiento en frío al almacenamiento templado. Estadísticas pertinentes: suma |
ColdToWarmMigrationLatency |
Cantidad de tiempo para que se completen de forma correcta las migraciones del almacenamiento en frío al almacenamiento templado. Estadísticas pertinentes: promedio |
ColdToWarmMigrationQueueSize |
Número de índices a la espera actualmente para migrar del almacenamiento frío al almacenamiento templado. Estadísticas pertinentes: máximo |
ColdToWarmMigrationSuccessCount
|
El número total de migraciones exitosas del almacenamiento en frío al almacenamiento templado. Estadísticas pertinentes: suma |
WarmToColdMigrationFailureCount
|
El número total de errores de migración del almacenamiento templado al almacenamiento en frío. Estadísticas pertinentes: suma |
WarmToColdMigrationLatency |
Cantidad de tiempo para que se completen de forma correcta las migraciones del almacenamiento templado al almacenamiento en frío. Estadísticas pertinentes: promedio |
WarmToColdMigrationQueueSize |
Número de índices a la espera actualmente para migrar del almacenamiento templado al almacenamiento frío. Estadísticas pertinentes: máximo |
WarmToColdMigrationSuccessCount |
El número total de migraciones exitosas del almacenamiento templado al almacenamiento en frío. Estadísticas pertinentes: suma |
OR1 métricas
Amazon OpenSearch Service proporciona las siguientes métricas para las OR1instancias.
| Métrica | Descripción |
|---|---|
RemoteStorageUsedSpace
|
Cantidad total del espacio de Amazon S3, en MiB, que utiliza el clúster. Estadísticas pertinentes: suma |
RemoteStorageWriteRejected |
El número total de solicitudes rechazadas en las particiones principales debido a la presión de replicación y almacenamiento remoto. Se calcula a partir del último inicio del proceso del OpenSearch servicio. Estadísticas pertinentes: suma |
ReplicationLagMaxTime |
El tiempo, en milisegundos, que las particiones de la réplica permanecen detrás de las particiones primarias. Estadísticas pertinentes: máximo |
Métricas de alertas
Amazon OpenSearch Service proporciona las siguientes métricas para las alertas.
| Métrica | Descripción |
|---|---|
AlertingDegraded |
Un valor de 1 significa que el índice de alerta es rojo o que uno o más nodos no van según lo programado. Un valor de 0 indica un comportamiento normal. Estadísticas pertinentes: máximo |
AlertingIndexExists |
Un valor de 1 significa que el índice Estadísticas pertinentes: máximo |
AlertingIndexStatus.green |
El estado de salud del índice. Un valor de 1 significa verde. Un valor de 0 significa que el índice no existe o no es verde. Estadísticas pertinentes: máximo |
AlertingIndexStatus.red |
El estado de salud del índice. Un valor de 1 significa rojo. Un valor de 0 significa que el índice no existe o no es rojo. Estadísticas pertinentes: máximo |
AlertingIndexStatus.yellow |
El estado de salud del índice. Un valor de 1 significa amarillo. Un valor de 0 significa que el índice no existe o no es amarillo. Estadísticas pertinentes: máximo |
AlertingNodesNotOnSchedule |
Un valor de 1 significa que algunos trabajos no se están ejecutando según lo programado. Un valor de 0 significa que todos los trabajos de alerta se están ejecutando según lo programado (o que no hay trabajos de alerta). Comprueba la consola OpenSearch de servicio o realiza una Estadísticas pertinentes: máximo |
AlertingNodesOnSchedule |
Un valor de 1 significa que todos los trabajos de alerta se están ejecutando según lo programado (o que no hay trabajos de alerta). Un valor de 0 significa que algunos trabajos no se están ejecutando según lo programado. Estadísticas pertinentes: máximo |
AlertingScheduledJobEnabled |
Un valor de 1 significa que la configuración del clúster Estadísticas pertinentes: máximo |
Métricas de detección de anomalías
Amazon OpenSearch Service proporciona las siguientes métricas para la detección de anomalías.
| Métrica | Descripción |
|---|---|
ADPluginUnhealthy |
El valor 1 significa que el complemento de detección de anomalías no funciona correctamente, bien debido a un gran número de errores o bien porque uno de los índices que utiliza es rojo. Un valor de 0 indica que el complemento funciona como se esperaba. Estadísticas pertinentes: máximo |
ADExecuteRequestCount |
El número de solicitudes para detectar anomalías. Estadísticas pertinentes: suma |
ADExecuteFailureCount
|
El número de solicitudes erróneas para detectar anomalías. Estadísticas pertinentes: suma |
ADHCExecuteFailureCount |
El número de errores de solicitud al detectar anomalías para los detectores de alta cardinalidad. Estadísticas pertinentes: suma |
ADHCExecuteRequestCount |
El número de solicitudes al detectar anomalías para detectores de alta cardinalidad. Estadísticas pertinentes: suma |
ADAnomalyResultsIndexStatusIndexExists |
Un valor de 1 significa que existe el índice al que apunta el alias Estadísticas pertinentes: máximo |
ADAnomalyResultsIndexStatus.red |
Un valor de 1 significa que el índice al que apunta el alias Estadísticas pertinentes: máximo |
ADAnomalyDetectorsIndexStatusIndexExists |
Un valor de 1 significa que el índice Estadísticas pertinentes: máximo |
ADAnomalyDetectorsIndexStatus.red |
Un valor de 1 significa que el índice Estadísticas pertinentes: máximo |
ADModelsCheckpointIndexStatusIndexExists |
Un valor de 1 significa que el índice Estadísticas pertinentes: máximo |
ADModelsCheckpointIndexStatus.red |
Un valor de 1 significa que el índice Estadísticas pertinentes: máximo |
Métricas de búsqueda asíncrona
Amazon OpenSearch Service proporciona las siguientes métricas para la búsqueda asíncrona.
Estadísticas del nodo coordinador de búsqueda asíncrona (por nodo coordinador)
| Métrica | Descripción |
|---|---|
AsynchronousSearchSubmissionRate |
El número de búsquedas asíncronas enviadas en el último minuto. |
AsynchronousSearchInitializedRate |
El número de búsquedas asíncronas inicializadas en el último minuto. |
AsynchronousSearchRunningCurrent |
El número de búsquedas asíncronas que se ejecutan actualmente. |
AsynchronousSearchCompletionRate |
El número de búsquedas asíncronas realizadas correctamente en el último minuto. |
AsynchronousSearchFailureRate |
El número de búsquedas asíncronas que se completaron y fallaron en el último minuto. |
AsynchronousSearchPersistRate |
El número de búsquedas asíncronas que persistieron en el último minuto. |
AsynchronousSearchPersistFailedRate |
El número de búsquedas asíncronas que no pudieron persistir en el último minuto. |
AsynchronousSearchRejected |
El número total de búsquedas asíncronas rechazadas desde el tiempo de actividad del nodo. |
AsynchronousSearchCancelled |
El número total de búsquedas asíncronas canceladas desde el tiempo de actividad del nodo. |
AsynchronousSearchMaxRunningTime |
Duración de la búsqueda asíncrona de ejecución más larga en un nodo en el último minuto. |
Estadísticas del clúster de búsqueda asíncrona
| Métrica | Descripción |
|---|---|
AsynchronousSearchStoreHealth |
El estado de la tienda en el índice persistente (ROJO/no ROJO) en el último minuto. |
AsynchronousSearchStoreSize |
El tamaño del índice del sistema en todas las particiones en el último minuto. |
AsynchronousSearchStoredResponseCount |
El número de respuestas almacenadas en el índice del sistema en el último minuto. |
Métricas de ajuste automático
Amazon OpenSearch Service proporciona las siguientes métricas para Auto-Tune.
| Métrica | Descripción |
|---|---|
AutoTuneChangesHistoryHeapSize |
El historial de cambios en MiB para los valores de ajuste del tamaño del montón. |
AutoTuneChangesHistoryJVMYoungGenArgs |
El historial de cambios de los argumentos de JVM YongGen . |
AutoTuneFailed |
Un valor booleano que indica si el cambio de ajuste automático produjo un error. |
AutoTuneSucceeded |
Un valor booleano que indica si el cambio de ajuste automático se realizó correctamente. |
AutoTuneValue |
El historial de cambios de cola (recuento) y el historial de cambios de ajustes de caché (en MiB) para los cambios no disruptivos. |
Métricas de Multi-AZ con modo de espera
Amazon OpenSearch Service proporciona las siguientes métricas para Multi-AZ con modo de espera.
Métricas a nivel de nodo para los nodos de datos en zonas de disponibilidad activas
| Métrica | Descripción |
|---|---|
CPUUtilization |
El porcentaje de uso de CPU para los nodos de datos del clúster. Máximo muestra el nodo con el mayor uso de CPU. Promedio representa todos los nodos del clúster. Esta métrica también está disponible para los nodos individuales. |
FreeStorageSpace |
El espacio libre para los nodos de datos del clúster. La consola OpenSearch de servicio muestra este valor en GiB. La CloudWatch consola de Amazon lo muestra en MiB. |
JVMMemoryPressure |
El porcentaje máximo del montón de Java utilizado para todos los nodos de datos del clúster. OpenSearch El servicio utiliza la mitad de la RAM de una instancia para el montón de Java, hasta un tamaño de pila de 32 GiB. Puede escalar las instancias verticalmente hasta 64 GiB de RAM y después escalarlas horizontalmente mediante el agregado de instancias. Consulte CloudWatch Alarmas recomendadas para Amazon OpenSearch Service. |
SysMemoryUtilization |
El porcentaje de memoria de la instancia que está en uso. Es normal obtener valores altos para esta métrica y, por lo general, no representan un problema con el clúster. Para obtener un mejor indicador de posibles problemas de rendimiento y estabilidad, consulte la métrica JVMMemoryPressure. |
IndexingLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las operaciones de indexación en un nodo entre el minuto N y el minuto (N-1). |
IndexingRate |
El número de operaciones de indexación por minuto. |
SearchLatency |
La diferencia en el tiempo total, en milisegundos, calculada por todas las búsquedas en un nodo entre el minuto N y el minuto (N-1). |
SearchRate |
El número total de peticiones de búsqueda por minuto de todas las particiones de un nodo de datos. |
ThreadpoolSearchQueue |
El número de tareas en cola en el grupo de subprocesos de búsqueda. Si el tamaño de la cola es sistemáticamente elevado, considere la posibilidad de escalar el clúster. El tamaño máximo de la cola de búsqueda es 1000. |
ThreadpoolWriteQueue |
El número de tareas en cola en el grupo de subprocesos de escritura. |
ThreadpoolSearchRejected |
El número de tareas rechazadas en el grupo de subprocesos de búsqueda. Si este número crece continuamente, considere la posibilidad de escalar el clúster. |
ThreadpoolWriteRejected |
El número de tareas rechazadas en el grupo de subprocesos de escritura. |
Métricas de nivel de clúster para clústeres en zonas de disponibilidad activas
| Métrica | Descripción |
|---|---|
DataNodes |
El número total de particiones activas y en espera. |
DataNodesShards.active |
El número total de particiones primarias y de réplicas activas. |
DataNodesShards.unassigned |
El número de particiones que no se asignaron a los nodos del clúster. |
DataNodesShards.initializing |
El número de particiones que se encuentran en inicialización. |
DataNodesShards.relocating |
El número de particiones que se encuentran en reubicación. |
Métricas de rotación de zonas de disponibilidad
Si ActiveReads., entonces la zona está activa. Si Availability-Zone = 1ActiveReads., entonces la zona está en espera.Availability-Zone =
0
Métricas de un momento dado
Amazon OpenSearch Service proporciona las siguientes métricas para las búsquedas puntuales (PIT).
Estadísticas del nodo coordinador de PIT (por nodo coordinador)
| Métrica | Descripción |
|---|---|
CurrentPointInTime |
El número de contextos de búsqueda PIT activos en el nodo. |
TotalPointInTime |
El número de contextos de búsqueda PIT caducados desde el tiempo de actividad del nodo. |
AvgPointInTimeAliveTime |
El keep-alive promedio de los contextos de búsqueda PIT desde el tiempo de actividad del nodo. |
HasActivePointInTime |
Un valor de 1 indica que hay contextos PIT activos en los nodos desde el tiempo de actividad del nodo. Un valor de 0 indica que no hay. |
HasUsedPointInTime |
Un valor de 1 indica que hay contextos PIT vencidos en los nodos desde el tiempo de actividad del nodo. Un valor de 0 indica que no hay. |
Métricas de SQL
Amazon OpenSearch Service proporciona las siguientes métricas para el soporte de SQL.
| Métrica | Descripción |
|---|---|
SQLFailedRequestCountByCusErr |
El número de solicitudes a la API Estadísticas pertinentes: suma |
SQLFailedRequestCountBySysErr |
El número de solicitudes a la API Estadísticas pertinentes: suma |
SQLRequestCount |
El número de solicitudes a la API Estadísticas pertinentes: suma |
SQLDefaultCursorRequestCount |
Similar a Estadísticas pertinentes: suma |
SQLUnhealthy |
Un valor de 1 indica que, en respuesta a determinadas solicitudes, el complemento SQL devuelve códigos de respuesta 5xx o pasa un DSL de consulta no válida a OpenSearch. Las demás solicitudes deberían realizarse correctamente. Un valor de 0 indica que no hay errores recientes. Si aparece sistemáticamente un valor de 1, solucione los problemas en las solicitudes que sus clientes están realizando al complemento. Estadísticas pertinentes: máximo |
Métricas k-NN
Amazon OpenSearch Service incluye las siguientes métricas para el complemento k-Nearest neighbor (k-NN).
| Métrica | Descripción |
|---|---|
KNNCacheCapacityReached |
Métrica por nodo para saber si se alcanzó la capacidad de caché. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: máximo |
KNNCircuitBreakerTriggered |
Métrica por clúster para saber si se activa el disyuntor. Si algún nodo devuelve un valor de 1 para Estadísticas pertinentes: máximo |
KNNEvictionCount |
Métrica por nodo para el número de gráficos que se expulsaron de la caché debido a limitaciones de memoria o tiempo de inactividad. Las expulsiones explícitas que se producen debido a la eliminación de indexación no se cuentan. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
KNNGraphIndexErrors |
Métrica por nodo para el número de solicitudes para agregar el campo Estadísticas pertinentes: suma |
KNNGraphIndexRequests |
Métrica por nodo para el número de solicitudes para agregar el campo Estadísticas pertinentes: suma |
KNNGraphMemoryUsage |
Métrica por nodo para el tamaño actual de caché (tamaño total de todos los gráficos en memoria) en kilobytes. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: promedio |
KNNGraphQueryErrors |
Métrica por nodo para el número de consultas de gráficos que produjeron un error. Estadísticas pertinentes: suma |
KNNGraphQueryRequests |
Métrica por nodo para el número de consultas de gráficos. Estadísticas pertinentes: suma |
KNNHitCount |
Métrica por nodo para el número de aciertos de caché. Un acierto de caché se produce cuando un usuario consulta un gráfico que ya está cargado en la memoria. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
KNNLoadExceptionCount |
Métrica por nodo para el número de veces que se produjo una excepción al intentar cargar un gráfico en la caché. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
KNNLoadSuccessCount |
Métrica por nodo para el número de veces que el complemento cargó correctamente un gráfico en la caché. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
KNNMissCount |
Métrica por nodo para el número de errores de caché. Un error de caché se produce cuando un usuario consulta un gráfico que aún no está cargado en la memoria. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
KNNQueryRequests |
Métrica por nodo para el número de solicitudes de consulta que recibió el complemento k-NN. Estadísticas pertinentes: suma |
KNNScriptCompilationErrors |
Métrica por nodo para el número de errores durante la compilación del script. Esta estadística solo es relevante para la búsqueda de scripts de puntuación k-NN. Estadísticas pertinentes: suma |
KNNScriptCompilations |
Métrica por nodo para el número de veces que se ha compilado el script k-NN. Por lo general, este valor debe ser 1 o 0, pero si se llena la caché que contiene los scripts compilados, el script k-NN podría ser recompilado. Esta estadística solo es relevante para la búsqueda de scripts de puntuación k-NN. Estadísticas pertinentes: suma |
KNNScriptQueryErrors |
Métrica por nodo para el número de errores durante las consultas de scripts. Esta estadística solo es relevante para la búsqueda de scripts de puntuación k-NN. Estadísticas pertinentes: suma |
KNNScriptQueryRequests |
Métrica por nodo para el número total de consultas de script. Esta estadística solo es relevante para la búsqueda de scripts de puntuación k-NN. Estadísticas pertinentes: suma |
KNNTotalLoadTime |
El tiempo en nanosegundos que k-NN tardó en cargar gráficos en la caché. Esta métrica solo es pertinente para la búsqueda aproximada de k-NN. Estadísticas pertinentes: suma |
Métricas de búsqueda entre clústeres
Amazon OpenSearch Service proporciona las siguientes métricas para la búsqueda entre clústeres.
Métricas de dominio de origen
| Métrica | Dimensión | Descripción |
|---|---|---|
CrossClusterOutboundConnections |
|
Número de nodos conectados. Si la respuesta incluye uno o más dominios omitidos, utilice esta métrica para rastrear las conexiones que no estén en buen estado. Si este número cae a 0, entonces la conexión no está en buen estado. |
CrossClusterOutboundRequests |
|
El número de peticiones de búsqueda enviadas al dominio de destino. Utilícelo para comprobar si la carga de peticiones de búsqueda en clústeres está sobrecargando su dominio, correlacione cualquier pico en esta métrica con cualquier pico JVM/CPU. |
Métrica de dominio de destino
| Métrica | Dimensión | Descripción |
|---|---|---|
CrossClusterInboundRequests |
|
El número de solicitudes de conexión entrantes recibidas desde el dominio de origen. |
Añade una CloudWatch alarma en caso de que pierdas una conexión de forma inesperada. Para ver los pasos para crear una alarma, consulte Crear una CloudWatch alarma basada en un umbral estático.
Métricas de replicación entre clústeres
Amazon OpenSearch Service proporciona las siguientes métricas para la replicación entre clústeres.
| Métrica | Descripción |
|---|---|
ReplicationRate |
La tasa media de operaciones de replicación por segundo. Esta métrica es similar a |
LeaderCheckPoint |
Para lograr una conexión específica, la suma de los valores de punto de control líder entre todos los índices de replicación. Puede utilizar esta métrica para medir la latencia de replicación. |
FollowerCheckPoint |
Para lograr una conexión específica, la suma de los valores de punto de control seguidor entre todos los índices de replicación. Puede utilizar esta métrica para medir la latencia de replicación. |
ReplicationNumSyncingIndices |
El número de índices que tienen un estado de replicación de |
ReplicationNumBootstrappingIndices |
El número de índices que tienen un estado de replicación de |
ReplicationNumPausedIndices |
El número de índices que tienen un estado de replicación de |
ReplicationNumFailedIndices |
El número de índices que tienen un estado de replicación de |
|
|
El número de solicitudes de transporte de replicación en el dominio seguidor. Las solicitudes de transporte son internas y se producen cada vez que se llama una operación de la API de replicación. También se producen cuando el dominio seguidor sondea los cambios con respecto al dominio líder. |
|
|
El número de solicitudes de transporte de replicación en el dominio principal. Las solicitudes de transporte son internas y se producen cada vez que se llama una operación de API de replicación. |
AutoFollowNumSuccessStartReplication |
El número de índices de seguidores que ha creado correctamente una regla de replicación para una conexión específica. |
AutoFollowNumFailedStartReplication |
El número de índices de seguidores que no pudo crear una regla de replicación cuando había un patrón coincidente. Este problema puede deberse a un problema de red en el clúster remoto o a un problema de seguridad (es decir, el rol asociado no tiene permiso para iniciar la replicación). |
AutoFollowLeaderCallFailure |
Si ha habido alguna consulta fallida del índice de seguidores al índice de líderes para obtener nuevos datos. Un valor de |
Aprender a clasificar métricas
Amazon OpenSearch Service proporciona las siguientes métricas para aprender a clasificar.
| Métrica | Descripción |
|---|---|
LTRRequestTotalCount |
Recuento total de solicitudes de clasificación. |
LTRRequestErrorCount |
Recuento total de solicitudes fallidas. |
LTRStatus.red |
Comprueba si uno de los índices necesarios para ejecutar el complemento es rojo. |
LTRMemoryUsage |
Memoria total utilizada por el complemento. |
LTRFeatureMemoryUsageInBytes |
La cantidad de memoria, en bytes, utilizada por los campos de características de Learning to Rank (Aprender a clasificar). |
LTRFeaturesetMemoryUsageInBytes |
La cantidad de memoria, en bytes, que utiliza todos los conjuntos de características de Learning to Rank (Aprender a clasificar). |
LTRModelMemoryUsageInBytes |
La cantidad de memoria, en bytes, utilizada por todos los modelos Learning to Rank (Aprender a clasificar). |
Métricas del lenguaje de procesamiento de canalizaciones
Amazon OpenSearch Service proporciona las siguientes métricas para Piped Processing Language.
| Métrica | Descripción |
|---|---|
PPLFailedRequestCountByCusErr |
El número de solicitudes a la API |
PPLFailedRequestCountBySysErr |
El número de solicitudes a la API |
PPLRequestCount |
El número de solicitudes a la API |
