Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
MyDumper
MyDumper
-
MyDumper exporta una copia de seguridad coherente de las bases de datos MySQL. Permite realizar copias de seguridad de la base de datos mediante el uso de varios subprocesos paralelos, hasta un subproceso por núcleo de CPU disponible.
-
myloader lee los archivos de copia de seguridad creados por MyDumper, se conecta a la instancia de base de datos de destino y, a continuación, restaura la base de datos.
El siguiente diagrama muestra los pasos de alto nivel necesarios para migrar una base de datos mediante un archivo de MyDumper respaldo. Este diagrama de arquitectura incluye tres opciones para migrar el archivo de respaldo del centro de datos local a una EC2 instancia del. Nube de AWS
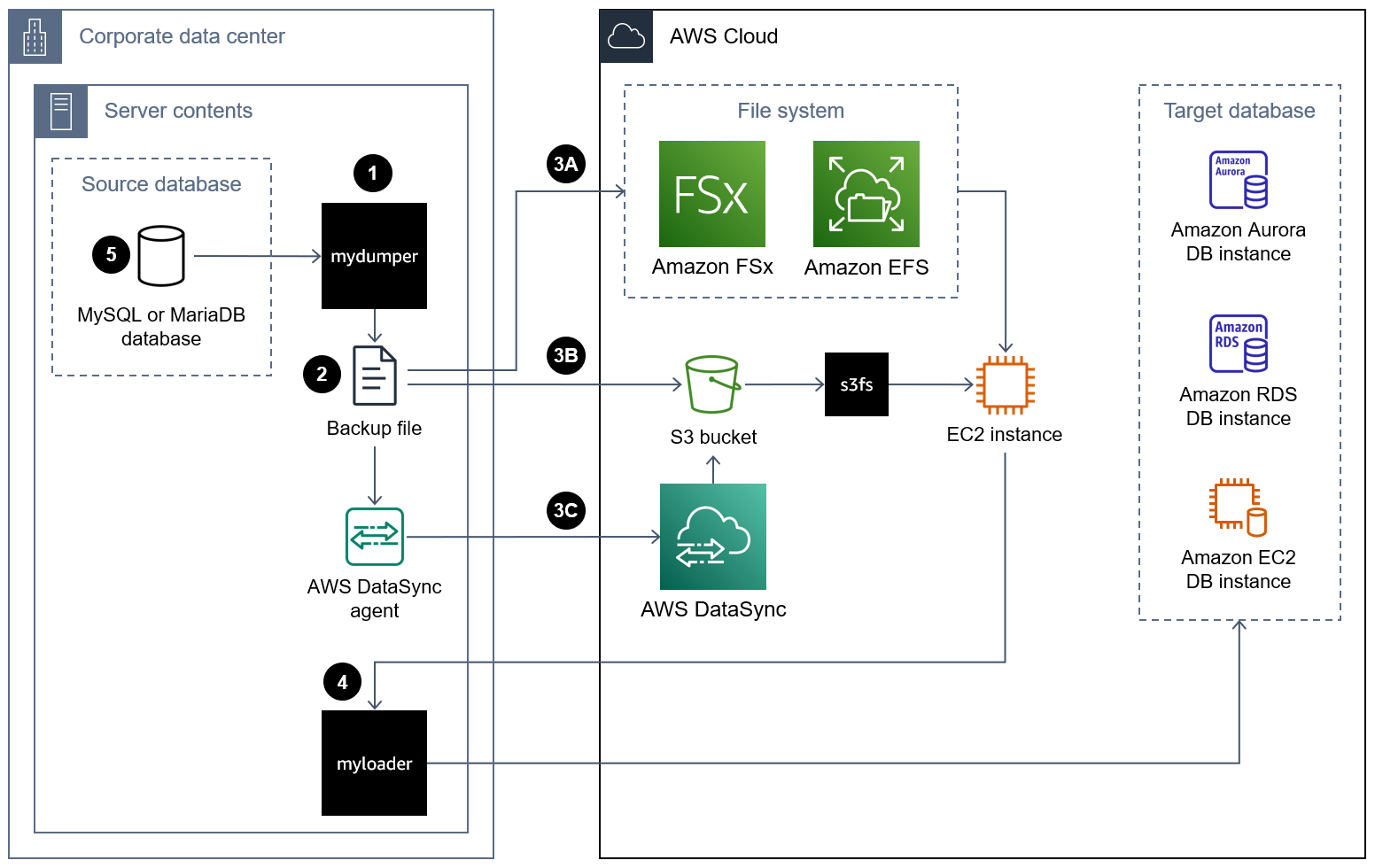
Los siguientes son los pasos que se deben seguir para MyDumper migrar una base de datos a: Nube de AWS
-
Install MyDumper y myloader. Para obtener instrucciones, consulte Cómo instalar mydumper/myloader
(). GitHub -
Se utiliza MyDumper para crear una copia de seguridad de la base de datos MySQL o MariaDB de origen. Para obtener instrucciones, consulte Cómo usarlo
. MyDumper -
Mueva el archivo de respaldo a una EC2 instancia de la Nube de AWS mediante uno de los siguientes enfoques:
Método 3A: monte un sistema de archivos Amazon FSx o Amazon Elastic File System (Amazon EFS) en el servidor local que ejecuta la instancia de base de datos. Puede usar AWS Direct Connect o AWS VPN para establecer la conexión. Puede hacer una copia de seguridad de la base de datos directamente en el recurso compartido de archivos montado o puede realizar la copia de seguridad en dos pasos: hacer una copia de seguridad de la base de datos en un sistema de archivos local y, a continuación, cargarla en el volumen montado FSx o EFS. A continuación, monte el sistema de archivos Amazon FSx o Amazon EFS, que también está montado en el servidor local, en una EC2 instancia.
Método 3B: utilice el AWS CLI AWS SDK o la API REST de Amazon S3 para mover directamente el archivo de respaldo del servidor local a un bucket de S3. Si el depósito S3 de destino se encuentra en un Región de AWS lugar alejado del centro de datos, puede utilizar Amazon S3 Transfer Acceleration para transferir el archivo con mayor rapidez. Utilice el sistema de archivos s3fs-fuse
para montar el bucket de S3 en la instancia. EC2 Método 3C: instale el AWS DataSync agente en el centro de datos local y utilícelo AWS DataSyncpara mover el archivo de respaldo a un bucket de Amazon S3. Usa el sistema de archivos s3fs-fuse
para montar el bucket de S3 en la instancia. EC2 nota
También puede usar Amazon S3 File Gateway para transferir los archivos de respaldo de bases de datos de gran tamaño a un bucket de S3 en el Nube de AWS. Para obtener más información, consulte la sección Uso de Amazon S3 File Gateway para transferir archivos de respaldo de esta guía.
-
Utilice myloader para restaurar la copia de seguridad en la instancia de base de datos de destino. Para obtener instrucciones, consulte myloader usage
()GitHub. -
(Opcional) Puede configurar la replicación entre la base de datos de origen y la instancia de base de datos de destino. Puede utilizar la replicación de registros binarios (binlog) para reducir el tiempo de inactividad. Para obtener más información, consulte los siguientes temas:
-
Establecer la configuración de la fuente de replicación
en la documentación de MySQL -
Para Amazon Aurora, consulte lo siguiente:
-
Sincronización del clúster de base de datos MySQL de Amazon Aurora con la base de datos MySQL mediante la replicación en la documentación de Aurora
-
Uso de la replicación binlog en Amazon Aurora en la documentación de Aurora
-
-
Para Amazon RDS, consulte lo siguiente:
-
Uso de la replicación de MySQL en la documentación de Amazon RDS
-
Trabajar con la replicación de MariaDB en la documentación de Amazon RDS
-
-
Para Amazon EC2, consulta lo siguiente:
-
Configuración de la replicación basada en la posición de un archivo de registro binario
en la documentación de MySQL -
Configuración de réplicas
en la documentación de MySQL -
Configuración de la replicación
en la documentación de MariaDB
-
-
Ventajas
-
MyDumper admite el paralelismo mediante el uso de subprocesos múltiples, lo que mejora la velocidad de las operaciones de respaldo y restauración.
-
MyDumper evita costosas rutinas de conversión de conjuntos de caracteres, lo que ayuda a garantizar que el código sea altamente eficiente.
-
MyDumper simplifica la visualización y el análisis de los datos mediante la descarga de archivos separados para las tablas y los metadatos.
-
MyDumper mantiene instantáneas en todos los subprocesos y proporciona posiciones precisas de los registros principales y secundarios.
-
Puede utilizar las expresiones regulares compatibles con Perl (PCRE) para especificar si desea incluir o excluir tablas o bases de datos.
Limitaciones
-
Puede elegir una herramienta diferente si sus procesos de transformación de datos requieren archivos de volcado intermedios en formato plano en lugar de formato SQL.
-
myloader no importa automáticamente las cuentas de usuario de la base de datos. Si va a restaurar la copia de seguridad en Amazon RDS o Aurora, vuelva a crear los usuarios con los permisos necesarios. Para obtener más información, consulte Privilegios de la cuenta de usuario maestra en la documentación de Amazon RDS. Si va a restaurar la copia de seguridad en una instancia de EC2 base de datos de Amazon, puede exportar manualmente las cuentas de usuario de la base de datos de origen e importarlas a la EC2 instancia.
Prácticas recomendadas
-
Configure MyDumper para dividir cada tabla en segmentos, por ejemplo, 10 000 filas en cada segmento, y escriba cada segmento en un archivo independiente. Esto permite importar los datos en paralelo más adelante.
-
Si utiliza el motor InnoDB, utilice la
--trx-consistency-onlyopción para minimizar el bloqueo. -
Su uso MyDumper para exportar la base de datos puede resultar intensivo en lectura y el proceso puede afectar al rendimiento general de la base de datos de producción. Si tiene una instancia de base de datos de réplica, ejecute el proceso de exportación desde la réplica. Antes de ejecutar la exportación desde la réplica, detenga el subproceso SQL de replicación. Esto ayuda a que el proceso de exportación se ejecute con mayor rapidez.
-
No exporte la base de datos durante las horas pico de trabajo. Evitar las horas punta puede estabilizar el rendimiento de la base de datos de producción principal durante la exportación de la base de datos.
-
Amazon RDS for MySQL no es compatible con
keyring_awsel complemento. Para obtener más información, consulte Problemas y limitaciones conocidos. Para migrar las tablas cifradas locales a la instancia de Amazon RDS, en los scripts de respaldo, debe eliminarENCRYPTIONoDEFAULT ENCRYPTIONde laCREATE TABLEsintaxis. Para el cifrado en reposo, puede utilizar una clave AWS Key Management Service (AWS KMS). Para obtener más información, consulte Cifrado de recursos de Amazon RDS.
