Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un cluster de bases de données Babelfish for Aurora PostgreSQL
Babelfish for Aurora PostgreSQL est pris en charge sur Aurora PostgreSQL version 13.4 et versions ultérieures.
Vous pouvez utiliser le AWS Management Console ou le AWS CLI pour créer un cluster Aurora PostgreSQL avec Babelfish.
Note
Dans un cluster Aurora PostgreSQL, le nom de base de données babelfish_db est réservé à Babelfish. La création de votre propre base de données « babelfish_db » sur un Babelfish for Aurora PostgreSQL empêche Aurora d'allouer Babelfish.
Pour créer un cluster doté de Babelfish à partir de la AWS Management Console
-
Ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
, puis choisissez Create database. 
-
Dans Choose a database creation method (Choisir une méthode de création de base de données), effectuez l'une des actions suivantes :
-
Pour spécifier des options de moteur détaillées, choisissez Standard create (Création standard).
-
Pour utiliser des options préconfigurées prenant en charge les bonnes pratiques relatives à un cluster Aurora, choisissez Easy create (Création facile).
-
-
Pour Type de moteur, choisissez Aurora (compatible avec PostgreSQL).
-
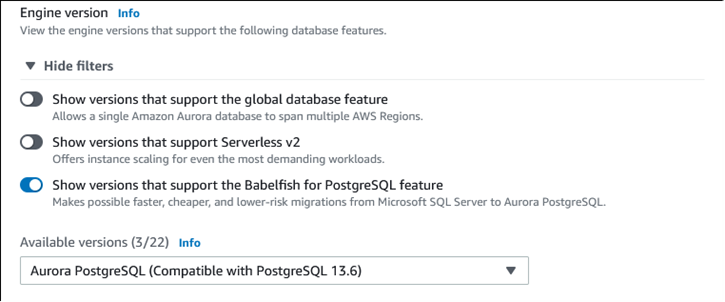
Choisissez Show filters (Afficher les filtres), puis Show versions that support the Babelfish for PostgreSQL feature (Afficher les versions prenant en charge la fonction Babelfish for PostgreSQL) pour répertorier les types de moteurs qui prennent en charge Babelfish. Babelfish est actuellement pris en charge sur Aurora PostgreSQL 13.4 et versions ultérieures.
-
Dans le champ Available versions (Versions disponibles), choisissez une version d'Aurora PostgreSQL. Pour obtenir les dernières fonctionnalités de Babelfish, choisissez la version majeure d'Aurora PostgreSQL la plus élevée.
-
Dans le champ Templates (Modèles), sélectionnez le modèle qui correspond à votre cas d'utilisation.
-
Dans le champ DB cluster identifier (Identifiant du cluster de bases de données), saisissez un nom facile à retrouver plus tard dans la liste des clusters de bases de données.
-
Dans le champ Master username (Nom d'utilisateur principal), saisissez un nom d'utilisateur administrateur. La valeur par défaut pour Aurora PostgreSQL est
postgres. Vous pouvez accepter la valeur par défaut ou choisir un autre nom. Par exemple, pour respecter la convention de dénomination utilisée sur vos bases de données SQL Server, vous pouvez saisirsa(administrateur système) pour le nom d'utilisateur principal.Si vous ne créez pas d'utilisateur nommé
sapour le moment, vous pourrez en créer un plus tard à l'aide du client de votre choix. Après avoir créé l'utilisateur, utilisez la commandeALTER SERVER ROLEpour l'ajouter au groupe (rôle)sysadminpour le cluster.Avertissement
Le nom d'utilisateur principal doit toujours utiliser des caractères minuscules, faute de quoi le cluster de base de données ne pourra pas se connecter à Babelfish via le port TDS.
-
Pour Mot de passe principal, créez un mot de passe fort et confirmez le mot de passe.
-
Pour les options suivantes, jusqu'à la section Babelfish settings (Paramètres Babelfish), spécifiez les paramètres de votre cluster de bases de données. Pour obtenir des informations sur chaque paramètre, consultez Paramètres pour les clusters de base de données Aurora.
-
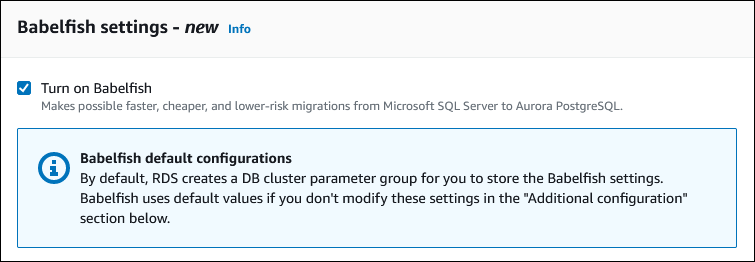
Pour rendre la fonctionnalité Babelfish disponible, cochez la case Turn on Babelfish (Activer Babelfish).
-
Dans le champ DB cluster parameter group (Groupe de paramètres du cluster de bases de données), effectuez l'une des actions suivantes :
-
Choisissez Create new (Créer) pour créer un nouveau groupe de paramètres avec Babelfish activé.
-
Choisissez Choose existing (Choisir un groupe existant) pour utiliser un groupe de paramètres existant. Si vous utilisez un groupe existant, veillez à le modifier avant de créer le cluster et à attribuer des valeurs aux paramètres Babelfish. Pour en savoir plus sur les paramètres Babelfish, consultez Paramètres du groupe de paramètres de cluster de bases de données pour Babelfish.
Si vous utilisez un groupe existant, indiquez son nom dans la zone qui suit.
-
-
Dans le champ Database migration mode (Mode de migration de base de données), choisissez l'une des options suivantes :
-
Single database (Base de données individuelle) pour migrer une base de données SQL Server individuelle.
Dans certains cas, vous pouvez migrer plusieurs bases de données utilisateur ensemble, avec pour objectif final une migration complète vers l'instance native d'Aurora PostgreSQL sans Babelfish. Si les applications finales nécessitent un regroupement des schémas (un seul schéma
dbo), commencez par regrouper vos bases de données SQL Server en une seule base de données SQL Server. Migrez ensuite vers Babelfish en utilisant le mode Single database (Base de données individuelle). -
Multiple databases (Plusieurs bases de données) pour migrer plusieurs bases de données SQL Server (issues d'un même environnement SQL Server). Le mode Plusieurs bases de données ne permet pas de regrouper plusieurs bases de données issues d'environnements SQL Server différents. Pour en savoir plus sur la migration de plusieurs bases de données, consultez Utilisation de Babelfish avec une ou plusieurs bases de données.
Note
À partir de la version Aurora PostgreSQL 16, plusieurs bases de données sont choisies par défaut comme mode de migration de base de données.

-
-
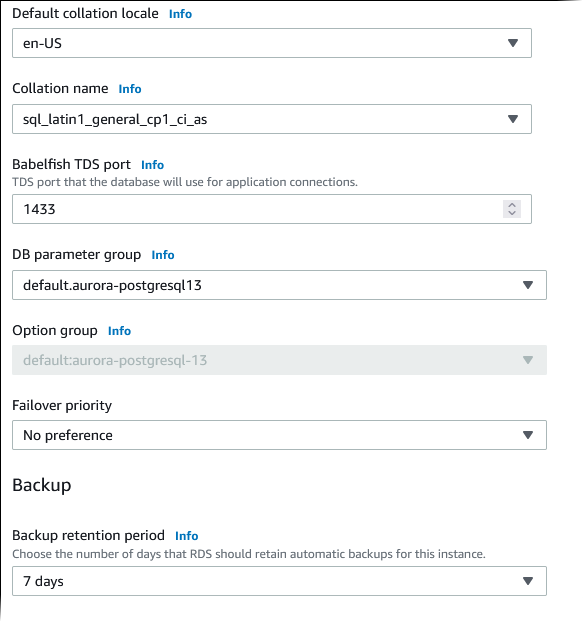
Dans le champ Default collation locale (Paramètres régionaux du classement par défaut), saisissez les paramètres régionaux de votre serveur. L’argument par défaut est
en-US. Pour en savoir plus sur les classements, consultez Comprendre les collations dans Babelfish pour Aurora Postgre SQL. -
Dans le champ Collation name (Nom du classement), saisissez le classement par défaut. L’argument par défaut est
sql_latin1_general_cp1_ci_as. Pour plus d’informations, consultez Comprendre les collations dans Babelfish pour Aurora Postgre SQL. -
Pour Port TDS de Babelfish, entrez le port par défaut
1433. Actuellement, Babelfish prend en charge uniquement le port1433pour votre cluster de base de données. -
Dans le champ DB parameter group (Groupe de paramètres de base de données), choisissez un groupe de paramètres ou demandez à Aurora de créer un groupe doté des paramètres par défaut.
-
Dans le champ Failover priority (Priorité de basculement), choisissez une priorité de basculement pour l'instance. Si vous ne choisissez aucune valeur, la valeur par défaut est
tier-1. Cette priorité détermine l'ordre dans lequel les réplicas sont promus lors de la reprise après une défaillance de l'instance principale. Pour de plus amples informations, veuillez consulter Tolérance aux pannes pour un cluster de base de données Aurora. -
Dans le champ Backup retention period (Période de rétention des sauvegardes), choisissez la durée (comprise entre 1 et 35 jours) pendant laquelle Aurora doit conserver les copies de sauvegarde de la base de données. Vous pouvez utiliser des copies de sauvegarde pour les point-in-time restaurations (PITR) de votre base de données à la seconde près. La période de rétention par défaut est de sept jours.
-
Choisissez Copy tags to snapshots (Copier les identifications dans les instantanés) pour copier toutes les identifications de l'instance de base de données dans un instantané de bases de données lors de la création d'un instantané.
Note
Lorsque vous restaurez un cluster de base de données à partir d'un instantané, il ne sera pas restauré en tant que cluster de base de données Babelfish for Aurora PostgreSQL. Vous devez activer les paramètres qui contrôlent les préférences de Babelfish dans le groupe de paramètres du cluster de base de données pour réactiver Babelfish. Pour plus d'informations sur les paramètres de Babelfish, consultez. Paramètres du groupe de paramètres de cluster de bases de données pour Babelfish
-
Choisissez Enable encryption (Activer le chiffrement) afin d'activer le chiffrement au repos (chiffrement du stockage Aurora) pour ce cluster de bases de données.
-
Choisissez Enable Performance Insights (Activer Performance Insights) pour activer Amazon RDS Performance Insights.
-
Choisissez Enable Enhanced monitoring (Activer la surveillance améliorée) afin de commencer à collecter des métriques en temps réel pour le système d'exploitation sur lequel le cluster de bases de données est exécuté.
-
Choisissez le journal PostgreSQL pour publier les fichiers journaux sur Amazon Logs. CloudWatch
-
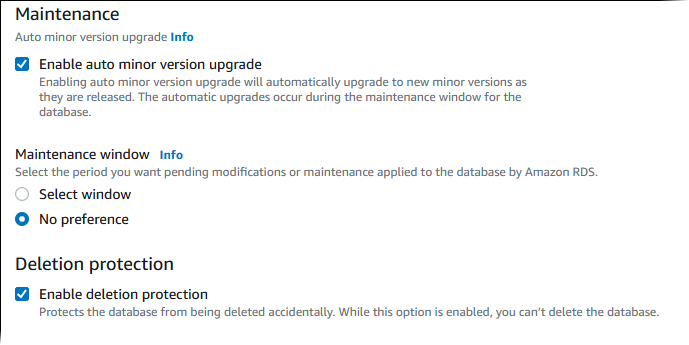
Choisissez Enable auto minor version upgrade (Activer la mise à niveau automatique des versions mineures) pour mettre automatiquement à jour votre cluster de bases de données Aurora lorsqu'une mise à niveau de version mineure est disponible.
-
Dans le champ Maintenance window (Fenêtre de maintenance), procédez comme suit :
-
Pour choisir quand Amazon RDS doit apporter des modifications ou effectuer des opérations de maintenance, choisissez Select window (Sélectionner la fenêtre).
-
Pour effectuer la maintenance d'Amazon RDS à une heure non planifiée, choisissez No preference (Aucune préférence).
-
-
Cochez la case Enable deletion protection (Activer la protection contre la suppression) pour protéger votre base de données d'une suppression accidentelle.
Si vous activez cette fonction, il vous est impossible d'effectuer une suppression directe de la base de données. Pour supprimer la base de données, vous devez modifier le cluster de bases de données et désactiver cette fonction.
-
Choisissez Créer une base de données.
La nouvelle base de données configurée pour Babelfish figure dans la liste Databases (Bases de données). La colonne Status (Statut) indique Available (Disponible) une fois le déploiement terminé.
Lorsque vous créez un Babelfish pour Aurora PostgreSQL, à l'aide du AWS CLI, vous devez transmettre à la commande le nom du groupe de paramètres du cluster de base de données à utiliser pour le cluster. Pour de plus amples informations, veuillez consulter Prérequis des clusters de bases de données.
Avant de pouvoir utiliser le AWS CLI pour créer un cluster Aurora PostgreSQL avec Babelfish, procédez comme suit :
-
Choisissez l'URL de votre point de terminaison dans la liste des services disponible dans Points de terminaison et quotas Amazon Aurora.
-
Créez un groupe de paramètres pour le cluster. Pour plus d'informations sur les groupes de paramètres, consultez Groupes de paramètres pour Amazon Aurora ().
-
Modifiez le groupe de paramètres en ajoutant le paramètre permettant d'activer Babelfish.
Pour créer un cluster de base de données Aurora PostgreSQL avec Babelfish à l'aide du AWS CLI
Les exemples suivants utilisent le nom d'utilisateur principal par défaut, postgres. Remplacez-le si nécessaire par le nom d'utilisateur que vous avez créé pour votre cluster de bases de données, tel que sa, ou par le nom d'utilisateur que vous avez choisi si vous n'avez pas accepté la valeur par défaut.
-
Créez un groupe de paramètres.
Pour LinuxmacOS, ou Unix :
aws rds create-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --db-parameter-group-familyaurora-postgresql14\ --description"description"Dans Windows :
aws rds create-db-cluster-parameter-group ^ --endpoint-urlendpoint-URL^ --db-cluster-parameter-group-nameparameter-group^ --db-parameter-group-familyaurora-postgresql14^ --description"description" -
Modifiez votre groupe de paramètres pour activer Babelfish.
Pour LinuxmacOS, ou Unix :
aws rds modify-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot"Dans Windows :
aws rds modify-db-cluster-parameter-group ^ --endpoint-urlendpoint-url^ --db-cluster-parameter-group-nameparamater-group^ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" -
Identifiez votre groupe de sous-réseaux de base de données et l'ID de groupe de sécurité du cloud privé virtuel (VPC) pour votre nouveau cluster de bases de données, puis appelez create-db-clusterla commande.
Pour LinuxmacOS, ou Unix :
aws rds create-db-cluster \ --db-cluster-identifiercluster-name\ --master-usernamepostgres\ --manage-master-user-password \ --engine aurora-postgresql \ --engine-version14.3\ --vpc-security-group-idssecurity-group\ --db-subnet-group-namesubnet-group-name\ --db-cluster-parameter-group-nameparameter-groupDans Windows :
aws rds create-db-cluster ^ --db-cluster-identifiercluster-name^ --master-usernamepostgres^ --manage-master-user-password ^ --engine aurora-postgresql ^ --engine-version14.3^ --vpc-security-group-idssecurity-group^ --db-subnet-group-namesubnet-group^ --db-cluster-parameter-group-nameparameter-groupCet exemple spécifie l'option
--manage-master-user-passwordpermettant de générer le mot de passe de l'utilisateur principal et de le gérer dans Secrets Manager. Pour de plus amples informations, veuillez consulter Gestion des mots de passe avec Amazon Aurora et AWS Secrets Manager. Vous pouvez également utiliser l'option--master-passwordpour spécifier et gérer vous-même le mot de passe. -
Créer de manière explicite l'instance principale pour votre cluster de bases de données. Utilisez le nom du cluster que vous avez créé à l'étape 3 comme
--db-cluster-identifierargument lorsque vous appelez la create-db-instancecommande, comme indiqué ci-dessous.Pour LinuxmacOS, ou Unix :
aws rds create-db-instance \ --db-instance-identifierinstance-name\ --db-instance-classdb.r6g\ --db-subnet-group-namesubnet-group\ --db-cluster-identifiercluster-name\ --engine aurora-postgresqlDans Windows :
aws rds create-db-instance ^ --db-instance-identifierinstance-name^ --db-instance-classdb.r6g^ --db-subnet-group-namesubnet-group^ --db-cluster-identifiercluster-name^ --engine aurora-postgresql
