Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créez un pipeline de services ETL pour charger les données de manière incrémentielle d'Amazon S3 vers Amazon Redshift à l'aide d'AWS Glue
Rohan Jamadagni et Arunabha Datta, Amazon Web Services
Récapitulatif
Ce modèle fournit des conseils sur la façon de configurer Amazon Simple Storage Service (Amazon S3) pour des performances optimales en matière de data lake, puis de charger les modifications de données incrémentielles d'Amazon S3 dans Amazon Redshift à l'aide d'AWS Glue, en effectuant des opérations d'extraction, de transformation et de chargement (ETL).
Les fichiers source d'Amazon S3 peuvent avoir différents formats, notamment des valeurs séparées par des virgules (CSV), des fichiers XML et des fichiers JSON. Ce modèle décrit comment utiliser AWS Glue pour convertir les fichiers source dans un format optimisé en termes de coûts et de performances, tel qu'Apache Parquet. Vous pouvez interroger les fichiers Parquet directement depuis Amazon Athena et Amazon Redshift Spectrum. Vous pouvez également charger des fichiers Parquet dans Amazon Redshift, les agréger et partager les données agrégées avec les consommateurs, ou visualiser les données à l'aide d'Amazon. QuickSight
Conditions préalables et limitations
Prérequis
Un compte AWS actif.
Un compartiment source S3 doté des privilèges appropriés et contenant des fichiers CSV, XML ou JSON.
Hypothèses
Les fichiers source CSV, XML ou JSON sont déjà chargés dans Amazon S3 et sont accessibles depuis le compte sur lequel AWS Glue et Amazon Redshift sont configurés.
Les meilleures pratiques relatives au chargement des fichiers, au fractionnement des fichiers, à la compression et à l'utilisation d'un manifeste sont suivies, comme indiqué dans la documentation Amazon Redshift.
La structure du fichier source n'est pas modifiée.
Le système source est capable d'ingérer des données dans Amazon S3 en suivant la structure de dossiers définie dans Amazon S3.
Le cluster Amazon Redshift couvre une seule zone de disponibilité. (Cette architecture est appropriée car AWS Lambda, AWS Glue et Amazon Athena fonctionnent sans serveur.) Pour une haute disponibilité, les instantanés du cluster sont pris à une fréquence régulière.
Limites
Les formats de fichiers sont limités à ceux actuellement pris en charge par AWS Glue.
Les rapports en temps réel en aval ne sont pas pris en charge.
Architecture
Pile technologique source
Compartiment S3 avec fichiers CSV, XML ou JSON
Pile technologique cible
Lac de données S3 (avec stockage de fichiers Parquet partitionné)
Amazon Redshift
Architecture cible
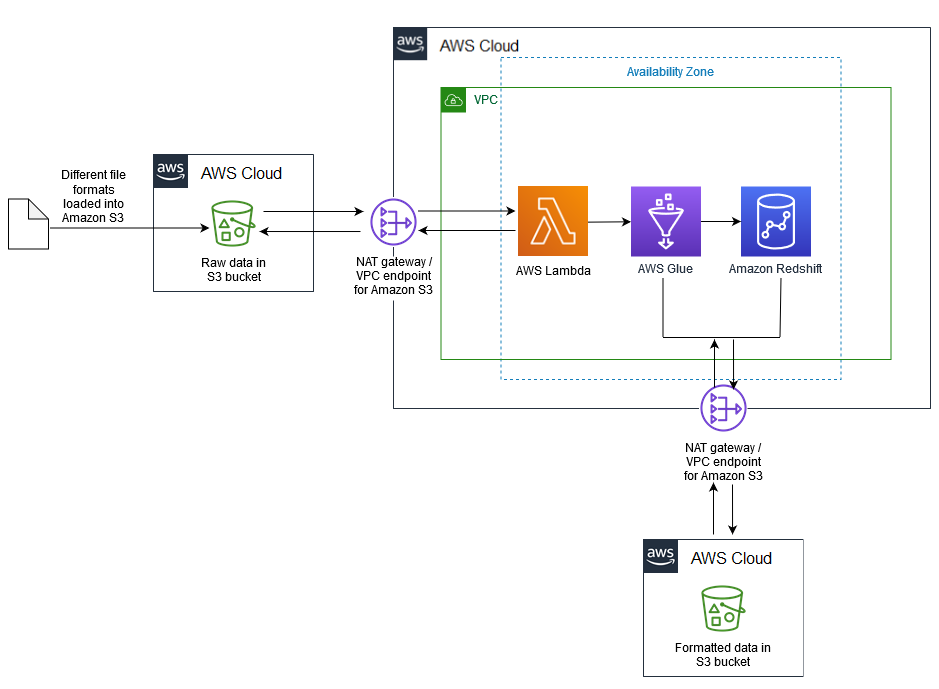
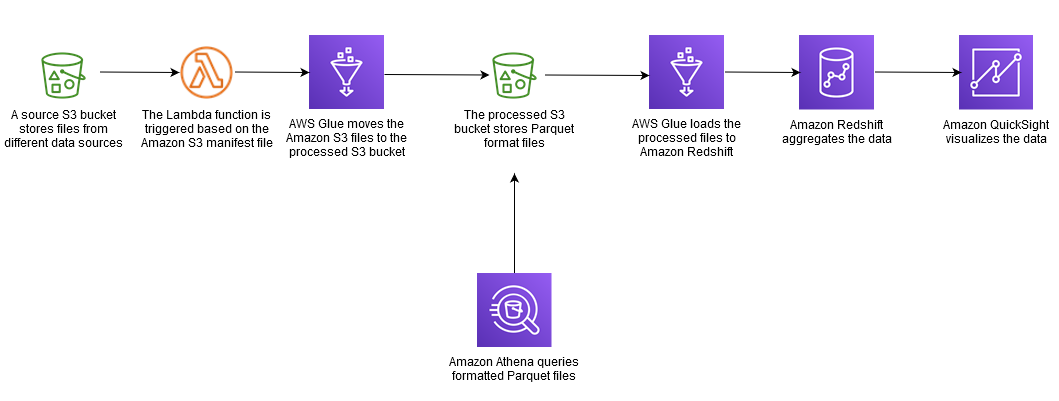
Flux de données
Outils
Amazon S3
— Amazon Simple Storage Service (Amazon S3) est un service de stockage d'objets hautement évolutif. Amazon S3 peut être utilisé pour un large éventail de solutions de stockage, notamment les sites Web, les applications mobiles, les sauvegardes et les lacs de données. AWS Lambda
— AWS Lambda vous permet d'exécuter du code sans provisionner ni gérer de serveurs. AWS Lambda est un service piloté par des événements ; vous pouvez configurer votre code pour qu'il soit lancé automatiquement à partir d'autres services AWS. Amazon Redshift — Amazon Redshift
est un service d'entrepôt de données de plusieurs pétaoctets entièrement géré. Avec Amazon Redshift, vous pouvez interroger des pétaoctets de données structurées et semi-structurées dans votre entrepôt de données et votre lac de données à l'aide du SQL standard. AWS Glue
— AWS Glue est un service ETL entièrement géré qui facilite la préparation et le chargement des données à des fins d'analyse. AWS Glue découvre vos données et stocke les métadonnées associées (par exemple, les définitions de tables et le schéma) dans le catalogue de données AWS Glue. Vos données cataloguées sont immédiatement consultables, peuvent être consultées et sont disponibles pour l'ETL. AWS Secrets Manager
— AWS Secrets Manager facilite la protection et la gestion centralisée des secrets nécessaires à l'accès aux applications ou aux services. Le service stocke les informations d'identification de base de données, les clés d'API et d'autres secrets, et élimine le besoin de coder en dur les informations sensibles au format texte brut. Secrets Manager propose également une rotation des clés pour répondre aux besoins de sécurité et de conformité. Il intègre une intégration à Amazon Redshift, Amazon Relational Database Service (Amazon RDS) et Amazon DocumentDB. Vous pouvez stocker et gérer les secrets de manière centralisée à l'aide de la console Secrets Manager, de l'interface de ligne de commande (CLI) ou de l'API Secrets Manager et. SDKs Amazon Athena
— Amazon Athena est un service de requête interactif qui facilite l'analyse des données stockées dans Amazon S3. Athena fonctionne sans serveur et est intégrée à AWS Glue, ce qui lui permet d'interroger directement les données cataloguées à l'aide d'AWS Glue. Athena est dimensionnée de manière élastique pour fournir des performances de requête interactives.
Épopées
| Tâche | Description | Compétences requises |
|---|---|---|
Analysez la structure des données et leurs attributs dans les systèmes sources. | Effectuez cette tâche pour chaque source de données qui contribue au lac de données Amazon S3. | Ingénieur de données |
Définissez la stratégie de partition et d'accès. | Cette stratégie doit être basée sur la fréquence des captures de données, le traitement du delta et les besoins de consommation. Assurez-vous que les compartiments S3 ne sont pas ouverts au public et que l'accès est contrôlé uniquement par des politiques spécifiques basées sur les rôles de service. Pour plus d’informations, consultez la documentation Amazon S3. | Ingénieur de données |
Créez des compartiments S3 distincts pour chaque type de source de données et un compartiment S3 distinct par source pour les données traitées (Parquet). | Créez un compartiment distinct pour chaque source, puis créez une structure de dossiers basée sur la fréquence d'ingestion des données du système source, par exemple, | Ingénieur de données |
| Tâche | Description | Compétences requises |
|---|---|---|
Lancez le cluster Amazon Redshift avec les groupes de paramètres et la stratégie de maintenance et de sauvegarde appropriés. | Utilisez le secret de base de données Secrets Manager pour les informations d'identification des utilisateurs administrateurs lors de la création du cluster Amazon Redshift. Pour plus d'informations sur la création et le dimensionnement d'un cluster Amazon Redshift, consultez la documentation Amazon Redshift et le livre blanc Sizing Cloud Data Warehouses | Ingénieur de données |
Créez et attachez le rôle de service IAM au cluster Amazon Redshift. | Le rôle de service AWS Identity and Access Management (IAM) garantit l'accès à Secrets Manager et aux compartiments S3 source. Pour plus d'informations, consultez la documentation AWS sur l'autorisation et l'ajout d'un rôle. | Ingénieur de données |
Créez le schéma de base de données. | Suivez les meilleures pratiques d'Amazon Redshift pour la conception des tables. En fonction du cas d'utilisation, choisissez les clés de tri et de distribution appropriées, ainsi que le meilleur codage de compression possible. Pour connaître les meilleures pratiques, consultez la documentation AWS. | Ingénieur de données |
Configurer la gestion de la charge de travail. | Configurez les files d'attente pour la gestion de la charge de travail (WLM), l'accélération des requêtes courtes (SQA) ou le dimensionnement de la simultanéité, en fonction de vos besoins. Pour plus d'informations, consultez la section Implémentation de la gestion de la charge de travail dans la documentation Amazon Redshift. | Ingénieur de données |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez un nouveau secret pour stocker les informations de connexion Amazon Redshift dans Secrets Manager. | Ce secret stocke les informations d'identification de l'utilisateur administrateur ainsi que celles des utilisateurs individuels du service de base de données. Pour obtenir des instructions, consultez la documentation de Secrets Manager. Choisissez Amazon Redshift Cluster comme type de secret. De plus, sur la page Rotation secrète, activez la rotation. Cela créera l'utilisateur approprié dans le cluster Amazon Redshift et effectuera une rotation des secrets clés à des intervalles définis. | Ingénieur de données |
Créez une politique IAM pour restreindre l'accès à Secrets Manager. | Limitez l'accès à Secrets Manager aux seuls administrateurs Amazon Redshift et à AWS Glue. | Ingénieur de données |
| Tâche | Description | Compétences requises |
|---|---|---|
Dans le catalogue de données AWS Glue, ajoutez une connexion pour Amazon Redshift. | Pour obtenir des instructions, consultez la documentation AWS Glue. | Ingénieur de données |
Créez et attachez un rôle de service IAM pour AWS Glue afin d'accéder à Secrets Manager, Amazon Redshift et aux compartiments S3. | Pour plus d'informations, consultez la documentation AWS Glue. | Ingénieur de données |
Définissez le catalogue de données AWS Glue pour la source. | Cette étape implique la création d'une base de données et des tables requises dans le catalogue de données AWS Glue. Vous pouvez utiliser un robot pour cataloguer les tables de la base de données AWS Glue ou les définir comme des tables externes Amazon Athena. Vous pouvez également accéder aux tables externes définies dans Athena via le catalogue de données AWS Glue. Consultez la documentation AWS pour plus d'informations sur la définition du catalogue de données et la création d'une table externe dans Athena. | Ingénieur de données |
Créez une tâche AWS Glue pour traiter les données sources. | La tâche AWS Glue peut être un shell Python ou servir PySpark à normaliser, dédupliquer et nettoyer les fichiers de données sources. Pour optimiser les performances et éviter d'avoir à interroger l'intégralité du compartiment source S3, partitionnez le compartiment S3 par date, ventilé par année, mois, jour et heure sous forme de prédicat push down pour la tâche AWS Glue. Pour plus d'informations, consultez la documentation AWS Glue. Chargez les données traitées et transformées dans les partitions du bucket S3 traitées au format Parquet. Vous pouvez consulter les dossiers du parquet auprès d'Athéna. | Ingénieur de données |
Créez une tâche AWS Glue pour charger des données dans Amazon Redshift. | La tâche AWS Glue peut être un shell Python ou une tâche consistant PySpark à charger les données en les insérant, puis en les actualisant complètement. Pour plus de détails, consultez la documentation d'AWS Glue et la section Informations supplémentaires. | Ingénieur de données |
(Facultatif) Planifiez les tâches AWS Glue en utilisant des déclencheurs si nécessaire. | Le chargement de données incrémentiel est principalement provoqué par un événement Amazon S3 qui amène une fonction AWS Lambda à appeler la tâche AWS Glue. Utilisez la planification basée sur des déclencheurs AWS Glue pour tous les chargements de données nécessitant une planification basée sur le temps plutôt qu'une planification basée sur des événements. | Ingénieur de données |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez et attachez un rôle lié à un service IAM pour qu'AWS Lambda accède aux compartiments S3 et à la tâche AWS Glue. | Créez un rôle lié à un service IAM pour AWS Lambda avec une politique pour lire les objets et les compartiments Amazon S3, et une politique pour accéder à l'API AWS Glue pour démarrer une tâche AWS Glue. Pour plus d'informations, consultez le centre de connaissances | Ingénieur de données |
Créez une fonction Lambda pour exécuter la tâche AWS Glue en fonction de l'événement Amazon S3 défini. | La fonction Lambda doit être initiée par la création du fichier manifeste Amazon S3. La fonction Lambda doit transmettre l'emplacement du dossier Amazon S3 (par exemple, source_bucket/year/month/date/hour) à la tâche AWS Glue en tant que paramètre. La tâche AWS Glue utilisera ce paramètre comme prédicat pushdown afin d'optimiser l'accès aux fichiers et les performances de traitement des tâches. Pour plus d'informations, consultez la documentation AWS Glue. | Ingénieur de données |
Créez un événement d'objet Amazon S3 PUT pour détecter la création d'un objet et appelez la fonction Lambda correspondante. | L'événement d'objet Amazon S3 PUT ne doit être initié que par la création du fichier manifeste. Le fichier manifeste contrôle la simultanéité de la fonction Lambda et de la tâche AWS Glue, et traite le chargement par lots au lieu de traiter les fichiers individuels qui arrivent dans une partition spécifique du compartiment source S3. Pour plus d'informations, consultez la documentation Lambda. | Ingénieur de données |
Ressources connexes
Informations supplémentaires
Approche détaillée pour l'amélioration et l'actualisation complète
Upsert : Cela concerne les ensembles de données qui nécessitent une agrégation historique, selon le cas d'utilisation métier. Suivez l'une des approches décrites dans la section Mise à jour et insertion de nouvelles données (documentation Amazon Redshift) en fonction des besoins de votre entreprise.
Actualisation complète : cela concerne les petits ensembles de données qui ne nécessitent pas d'agrégations historiques. Suivez l'une des approches suivantes :
Tronquez le tableau Amazon Redshift.
Charger la partition actuelle depuis la zone de transit
ou :
Créez une table temporaire avec les données de partition actuelles.
Supprimez la table Amazon Redshift cible.
Renommez la table temporaire en table cible.
