Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS offres pour le maillage de données
Utilisez les fonctionnalités de l'analytique AWS pour créer la solution de données basée sur
-
Implémenter le maillage de données à l'aide d'Amazon DataZone
-
Implémentez le maillage des données en utilisant des frameworks open source AWS tels que data.all
-
Implémentez le maillage de données en utilisant AWS Lake Formation
Ces trois options utilisent les options suivantes Services AWS :
-
AWS Glue(y compris AWS Glue Data Catalog un AWS Glue robot)
L' DataZone option Amazon utilise également Amazon EventBridge.
Le data.all et les AWS Lake Formation options utilisent également Services AWS les ressources suivantes :
La Services AWS méthode que vous utilisez dans votre mise en œuvre peut être différente en fonction des exigences de votre organisation.
Amazon DataZone
Si vous souhaitez utiliser un service entièrement géré, pensez à utiliser Amazon DataZone pour implémenter le maillage de données pour votre organisation. Amazon DataZone est un service de gestion des données destiné au catalogage, à la découverte, au partage et à la gestion des données stockées auprès de sources tierces AWS, sur site ou auprès de sources tierces. Le schéma suivant montre une architecture de référence de maillage de données basée sur Amazon DataZone.
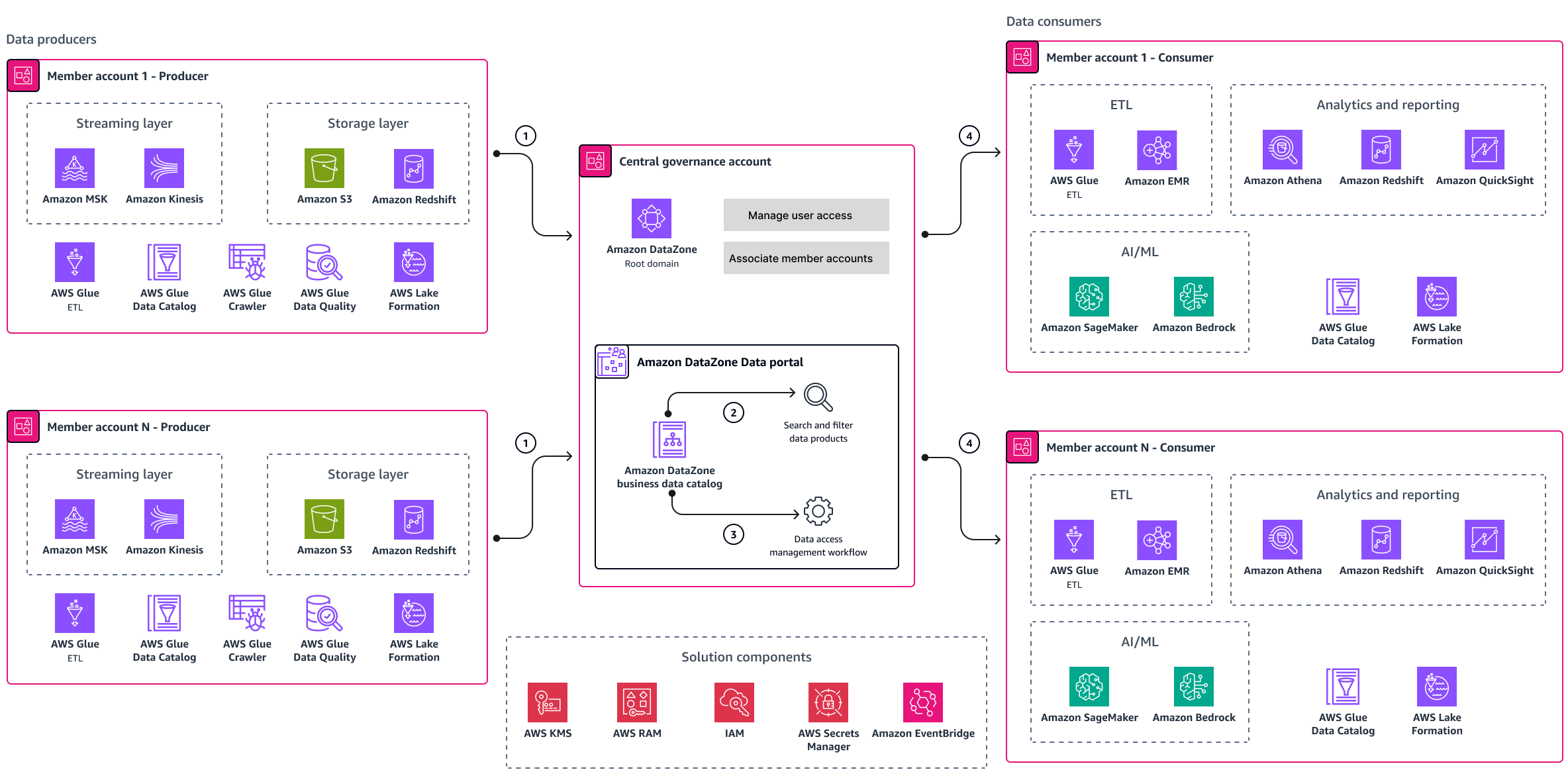
Dans l'architecture de référence, les comptes membres appartiennent aux domaines de données. Ils sont regroupés en producteurs de données et en consommateurs de données. Le schéma d'architecture contient les composants suivants :
-
Les producteurs de données publient des produits de données dans le catalogue professionnel fourni par le portail de DataZone données Amazon. Le portail de données est hébergé dans le compte de gouvernance central.
-
Les consommateurs de données (utilisateurs) se connectent au portail de données en utilisant leurs AWS informations d'identification ou leurs informations d'identification unique. Ils peuvent parcourir le catalogue et rechercher les produits de données qui les intéressent à l'aide de mots clés. Ils peuvent filtrer les résultats de recherche.
-
Une fois que les utilisateurs des données appartenant aux équipes chargées des consommateurs ont trouvé le produit de données qui les intéresse, ils peuvent demander l'accès aux données. Amazon DataZone dispose d'un flux de travail intégré de gestion des accès que le propriétaire des données utilise pour examiner et approuver la demande.
-
Les équipes chargées des consommateurs de données peuvent utiliser les données pour renforcer leurs capacités en matière d'intelligence artificielle et d'apprentissage automatique (IA/ML), d'analyse et de reporting, ainsi que pour extraire, transformer et charger (ETL) des cas d'utilisation.
Toutes les données
Si vous comprenez l'open source et que vous souhaitez créer et gérer votre propre solution, pensez à utiliser des frameworks open source tels que data.all
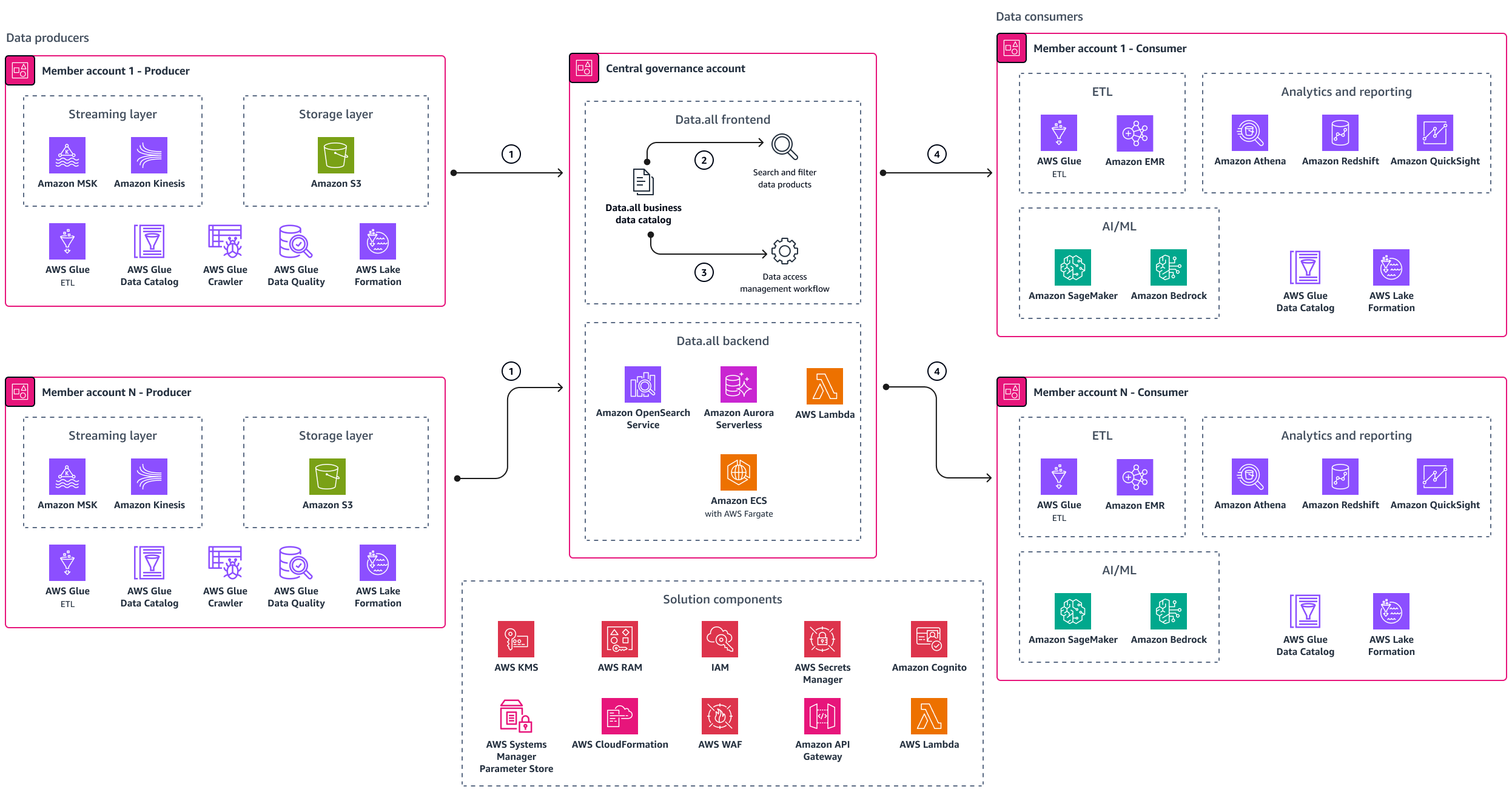
Le schéma d'architecture contient les composants suivants :
-
Les producteurs de données publient des produits de données dans le catalogue fourni par le frontend data.all. Le frontend et le backend de data.all sont hébergés dans le compte de gouvernance central.
-
Les consommateurs de données (utilisateurs) se connectent à l'interface data.all à l'aide de leur authentification unique ou de leurs informations d'identification Amazon Cognito. Ils peuvent parcourir le catalogue et rechercher les produits de données qui les intéressent. Ils peuvent filtrer les résultats de recherche.
-
Une fois que les utilisateurs des données appartenant aux équipes chargées des consommateurs ont trouvé le produit de données qui les intéresse, ils peuvent demander l'accès aux données. Data.all dispose d'un flux de travail intégré de gestion des accès que le propriétaire des données utilise pour examiner et approuver les demandes d'accès.
-
Les équipes chargées des consommateurs peuvent utiliser les données pour renforcer leur IA/ML, leurs analyses et leurs rapports, ainsi que leurs cas ETL d'utilisation.
AWS Lake Formation
Si vous souhaitez créer une solution de maillage de données personnalisée à partir de zéro et la gérer, pensez à l'utiliser AWS Lake Formation. Lake Formation vous aide à gérer, sécuriser et partager les données de manière centralisée à l'échelle mondiale à des fins d'analyse et d'apprentissage automatique. Le schéma suivant montre une architecture de référence de maillage de données basée sur Lake Formation.
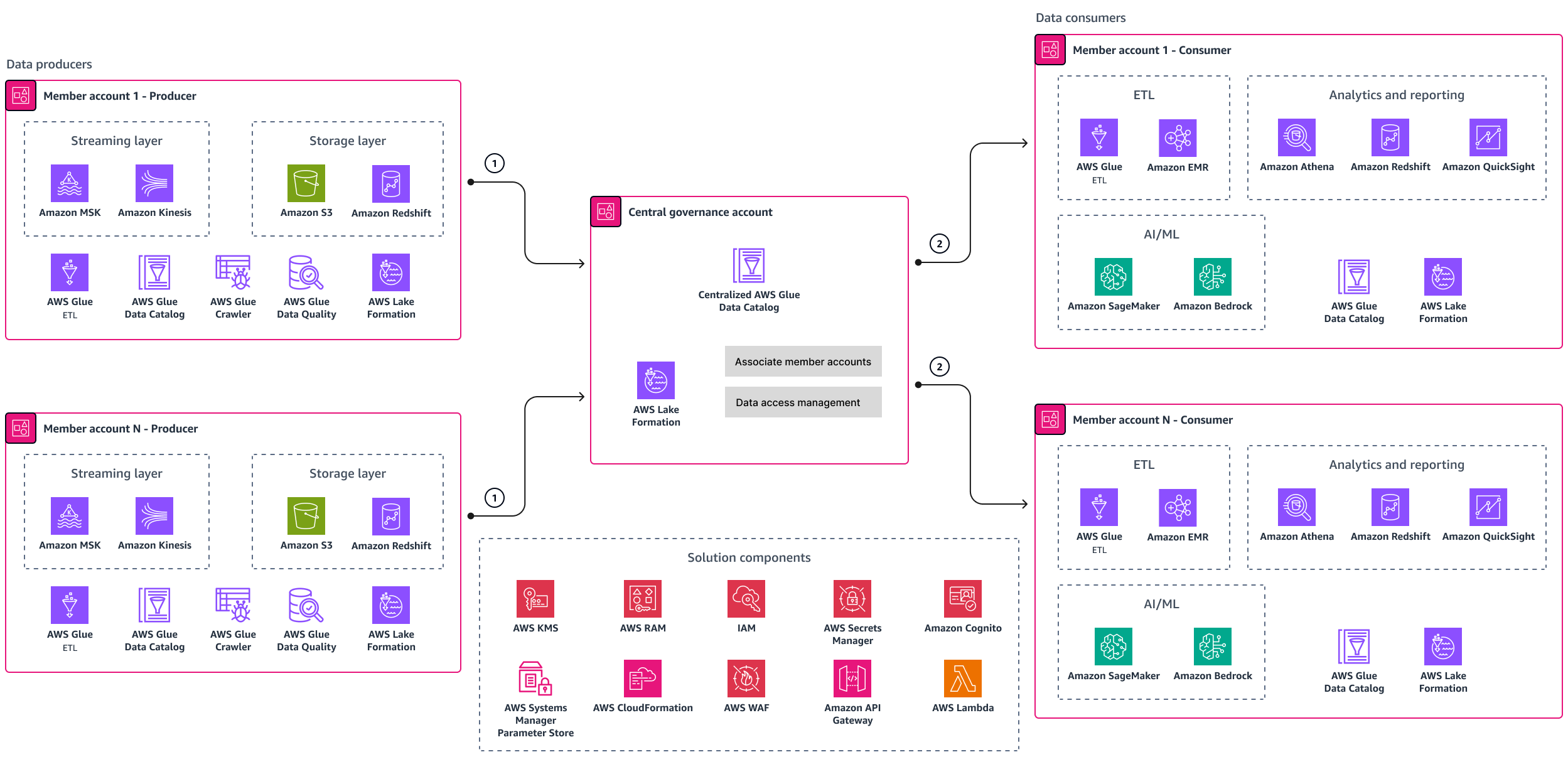
Le schéma d'architecture contient les composants suivants :
-
Les producteurs de données publient les produits AWS Glue Data Catalog de données dans le compte de gouvernance central. AWS Lake Formation gère l'accès aux entités du catalogue de données central.
-
Une fois l'accès accordé, les équipes chargées des consommateurs peuvent utiliser les données pour renforcer leur IA/ML, leurs analyses et leurs rapports, ainsi que leurs cas d'utilisation. ETL
