Amazon Redshift ne prendra plus en charge la création de nouveaux UDFs Python à partir du patch 198. Les fonctions Python définies par l’utilisateur existantes continueront de fonctionner normalement jusqu’au 30 juin 2026. Pour plus d’informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Didacticiel : chargement des données à partir d’Amazon S3
Dans ce didacticiel, vous examinerez le processus de chargement de données dans vos tables de base de données Amazon Redshift depuis les fichiers de données d’un compartiment Amazon S3 de bout en bout.
Dans ce didacticiel, vous allez effectuer les opérations suivantes :
-
Téléchargez des fichiers de données qui utilisent des formats CSV, délimités par un caractère et à largeur fixe.
-
Créez un compartiment Amazon S3 pour contenir vos fichiers de données, puis chargez les fichiers de données dans le compartiment.
-
Lancez un cluster Amazon Redshift et créez des tables de base de données ;
-
Utilisez les commandes COPY pour charger les tables depuis les fichiers de données sur Amazon S3 ;
-
Résolvez les erreurs de chargement et modifiez vos commandes COPY pour corriger les erreurs.
Conditions préalables
Vous avez besoin des prérequis suivants :
-
Un AWS compte pour lancer un cluster Amazon Redshift et créer un compartiment dans Amazon S3.
-
Vos AWS informations d'identification (rôle IAM) pour charger les données de test depuis Amazon S3. Si vous avez besoin d’un nouveau rôle IAM, consultez Création de rôles IAM.
-
Client SQL tel que l’éditeur de requêtes de la console Amazon Redshift.
Ce didacticiel est conçu pour se suffire à lui-même. En plus de ce didacticiel, nous vous recommandons de suivre les didacticiels suivants pour avoir une compréhension plus complète de la conception et de l’utilisation des bases de données Amazon Redshift :
-
Le Guide de démarrage d’Amazon Redshift vous explique le processus de création d’un cluster Amazon Redshift et de chargement d’exemples de données.
Présentation de
Vous pouvez ajouter des données à vos tables Amazon Redshift en utilisant une commande INSERT ou une commande COPY. À l’échelle et à la vitesse d’un entrepôt des données Amazon Redshift, la commande COPY est beaucoup plus rapide et plus efficace que les commandes INSERT.
La commande COPY utilise l’architecture de traitement massivement parallèle (MPP) Amazon Redshift pour lire et charger des données en parallèle depuis plusieurs sources de données. Vous pouvez charger depuis des fichiers de données dans Amazon S3, Amazon EMR ou n’importe quel hôte distant accessible via une connexion SSH (Secure Shell). Ou vous pouvez charger directement depuis une table Amazon DynamoDB.
Dans ce didacticiel, vous utilisez la commande COPY pour charger les données à partir d’Amazon S3. Bon nombre des principes présentés ici s’appliquent également au chargement depuis d’autres sources de données.
Pour en savoir plus sur l’utilisation de la commande COPY, consultez les ressources suivantes :
Étape 1 : créer un cluster
Si vous disposez déjà d’un cluster que vous souhaitez utiliser, vous pouvez ignorer cette étape.
Pour les exercices de ce didacticiel, vous utilisez un cluster à quatre nœuds.
Pour créer un cluster
-
Connectez-vous à la console Amazon Redshift AWS Management Console et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
Dans le menu de navigation, choisissez le Tableau de bord des clusters alloués.
Important
Veillez à ce que vous disposiez des autorisations nécessaires pour exécuter les opérations de cluster. Pour plus d'informations sur l'octroi des autorisations nécessaires, consultez Autoriser Amazon Redshift à accéder aux AWS services.
-
En haut à droite, choisissez la AWS région dans laquelle vous souhaitez créer le cluster. Dans le cadre de ce didacticiel, sélectionnez USA Ouest (Oregon).
-
Dans le menu de navigation, choisissez Clusters, puis choisissez Créer un cluster. La page Créer un cluster s’affiche.
-
Dans la page Créer un cluster, saisissez les paramètres de votre cluster. Choisissez vos propres valeurs pour les paramètres, sauf pour modifier les valeurs suivantes :
Choisissez
dc2.largepour le type de nœud.Choisissez
4pour le nombre de nœuds.Dans la section Autorisations de cluster, choisissez un rôle IAM dans Rôles IAM disponibles. Ce rôle doit avoir été créé précédemment et avoir accès à Amazon S3. Choisissez ensuite Associate IAM role (Associer un rôle IAM) pour l’ajouter à la liste des Rôles IAM associés pour le cluster.
-
Choisissez Créer un cluster.
Suivez les étapes du Guide de démarrage d’Amazon Redshift pour vous connecter à votre cluster à partir d’un client SQL et tester une connexion. Vous n’avez pas besoin de suivre les dernières étapes de la mise en route pour créer des tables, télécharger des données et essayer des exemples de requêtes.
Étape 2 : Télécharger les fichiers de données
Au cours de cette étape, vous téléchargez un ensemble d’exemples de fichiers de données sur votre ordinateur. Dans l’étape suivante, vous chargez les fichiers dans un compartiment Amazon S3.
Pour télécharger les fichiers de données
-
Téléchargez le fichier compressé : LoadingDataSampleFiles.zip.
-
Extrayez les fichiers dans un dossier sur votre ordinateur.
-
Vérifiez que votre dossier contient les fichiers suivants.
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Étape 3 : Charger les fichiers dans un compartiment Amazon S3
Au cours de cette étape, vous allez créer un compartiment Amazon S3 et chargez les fichiers de données dans le compartiment.
Pour charger les fichiers dans un compartiment Amazon S3
-
Créez un compartiment dans Amazon S3.
Pour plus d’informations sur la création d’un compartiment, consultez Création d’un compartiment dans le Guide de l’utilisateur Amazon Simple Storage Service.
-
Connectez-vous à la console Amazon S3 AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/s3/
. -
Choisissez Créer un compartiment.
-
Choisissez un Région AWS.
Créez le compartiment dans la même région que votre cluster. Si votre cluster se trouve dans la région USA Ouest (Oregon), choisissez USA Ouest (Oregon) (us-west-2).
-
Dans la zone Nom du compartiment de la boîte de dialogue Créer un compartiment, entrez un nom de compartiment.
Le nom de compartiment que vous choisissez doit être unique parmi tous les noms de compartiment existants dans Amazon S3. Afin de garantir cette unicité, vous pouvez ajouter le nom de votre organisation en préfixe du nom de vos compartiments. Les noms de compartiment doivent respecter certaines règles. Pour plus d’informations, consultez Limites et restrictions applicables aux compartiments dans le Guide de l’utilisateur Amazon Simple Storage Service.
-
Choisissez les valeurs par défaut recommandées pour les autres options.
-
Choisissez Créer un compartiment.
Une fois le compartiment créé dans Amazon S3, celui-ci s’affiche dans la console, dans le volet Compartiments.
-
-
Créez un dossier.
-
Choisissez le nom du nouveau compartiment.
-
Choisissez le bouton Créer un dossier.
-
Nommez le nouveau dossier
load.Note
Le compartiment que vous avez créé ne figure pas dans un environnement de test (sandbox). Au cours de cet exercice, vous ajoutez des objets dans un véritable compartiment. Un montant nominal vous est facturé pour le temps de stockage des objets dans le compartiment. Pour plus d’informations sur les tarifs Amazon S3, consultez la page de Tarification Amazon S3
.
-
-
Chargez les fichiers de données dans le nouveau compartiment Amazon S3.
-
Choisissez le nom du dossier de données.
-
Dans l’assistant Charger, choisissez Ajouter des fichiers.
Suivez les instructions de la console Amazon S3 pour charger tous les fichiers que vous avez téléchargés et extraits.
-
Choisissez Charger.
-
Informations d’identification de l’utilisateur
La commande COPY Amazon Redshift doit avoir un accès en lecture aux objets du fichier du compartiment Amazon S3. Si vous utilisez les mêmes informations d’identification de l’utilisateur pour créer le compartiment Amazon S3 que pour exécuter la commande COPY Amazon Redshift, celle-ci dispose de toutes les autorisations nécessaires. Si vous souhaitez utiliser les informations d’identification d’un autre utilisateur, vous pouvez accorder l’accès en utilisant les contrôles d’accès Amazon S3. La commande Amazon Redshift COPY nécessite au moins ListBucket des GetObject autorisations pour accéder aux objets du fichier dans le compartiment Amazon S3. Pour plus d’informations sur le contrôle de l’accès aux ressources Amazon S3, consultez Gestion des autorisations d’accès à vos ressources Amazon S3.
Étape 4 : Créer des exemples de tables
Pour ce didacticiel, vous utilisez un ensemble de tables basées sur le schéma SSB (Star Schema Benchmark). Le diagramme suivant illustre le modèle de données SSB.
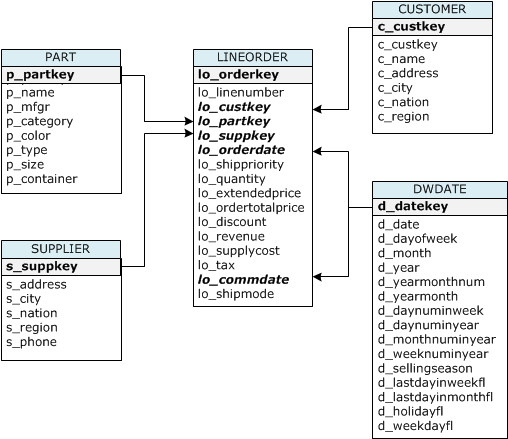
Il est possible que les tables SSB existent déjà dans la base de données actuelle. Le cas échéant, supprimez les tables de la base de données avant de les créer à l’aide des commandes CREATE TABLE de l’étape suivante. Les tables utilisées dans ce didacticiel peuvent avoir des attributs différents des tables existantes.
Pour créer des exemples de tables
-
Pour supprimer les tables SSB, exécutez les commandes suivantes dans votre client SQL.
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
Exécutez les commandes CREATE TABLE suivantes dans votre client SQL.
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
Étape 5 : Exécuter les commandes COPY
Vous exécutez des commandes COPY pour charger chacune des tables dans le schéma SSB. Les exemples de commande COPY illustrent le chargement dans différents formats, à l’aide de plusieurs options de la commande COPY, ainsi que la résolution des erreurs de chargement.
Syntaxe de la commande COPY
La syntaxe de base de la commande COPY est la suivante.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
Pour exécuter une commande COPY, fournissez les valeurs suivantes.
Nom de la table
Table cible de la commande COPY. La table doit déjà exister dans la base de données. La table peut être temporaire ou permanente. La commande COPY ajoute les nouvelles données d’entrée à toutes les lignes existantes de la table.
Liste de colonnes
Par défaut, la commande COPY charge les champs depuis les données source dans les colonnes de la table dans l’ordre. Vous pouvez spécifier facultativement une liste de colonnes,, qui une liste séparée par des virgules des noms de colonnes, pour mapper les champs de données à des colonnes spécifiques. Vous n’utilisez pas de listes de colonnes de ce didacticiel. Pour plus d’informations, consultez Column List dans la référence de la commande COPY.
Source de données
Vous pouvez utiliser la commande COPY pour charger les données à partir d’un compartiment Amazon S3, un cluster Amazon EMR, un hôte distant à l’aide d’une connexion SSH, ou d’une table Amazon DynamoDB. Dans le cadre de ce didacticiel, vous chargez des fichiers de données dans un compartiment Amazon S3. Lorsque vous chargez depuis Amazon S3, vous devez fournir le nom du compartiment et l’emplacement des fichiers de données. Pour cela, fournissez soit un chemin d’accès à l’objet pour les fichiers de données ou l’emplacement du fichier manifeste qui répertorie explicitement chaque fichier de données et son emplacement.
-
Préfixe de clé
Un objet stocké dans Amazon S3 est identifié par la clé d’objet, qui inclut le nom du compartiment, les noms des dossiers, le cas échéant, et le nom de l’objet. Un préfixe de clé fait référence à un ensemble d’objets portant le même préfixe. Le chemin d’accès de l’objet est un préfixe de clé que la commande COPY utilise pour charger tous les objets partageant le même préfixe de clé. Par exemple, le préfixe de clé
custdata.txtpeut faire référence à un seul fichier ou à un ensemble de fichiers, notammentcustdata.txt.001,custdata.txt.002et ainsi de suite. -
Fichier manifeste
Dans certains cas, vous aurez peut-être besoin de charger des fichiers avec des préfixes différentes, par exemple des fichiers provenant de plusieurs compartiments ou dossiers. Dans d’autres, vous devrez peut-être exclure des fichiers qui partagent un préfixe. Dans ces cas, vous pouvez utiliser un fichier manifeste. Un fichier manifeste répertorie explicitement chaque fichier de chargement et sa clé d’objet unique. Vous utilisez un fichier manifeste pour charger la table PART ultérieurement dans ce didacticiel.
Informations d’identification
Pour accéder aux AWS ressources contenant les données à charger, vous devez fournir les informations d'identification d' AWS accès à un utilisateur disposant de privilèges suffisants. Ces informations d’identification incluent un rôle IAM Amazon Resource Name (ARN). Pour charger des données depuis Amazon S3, les informations d'identification doivent inclure les GetObject autorisations ListBucket et les autorisations. Des informations d’identification supplémentaires sont nécessaires si vos données sont chiffrées. Pour plus d’informations, consultez Paramètres d’autorisation dans la référence de la commande COPY. Pour plus d’informations sur la gestion de l’accès, consultez Gestion des autorisations d’accès à vos ressources Amazon S3.
Options
Vous pouvez spécifier un certain nombre de paramètres avec la commande COPY afin de définir les formats de fichiers, gérer les formats de données, gérer les erreurs et contrôler d’autres fonctions. Dans ce didacticiel, vous utilisez les fonctions et les options de la commande COPY suivantes :
-
Préfixe de clé
Pour plus d’informations sur le chargement à partir de plusieurs fichiers en spécifiant un préfixe de clé, consultez Charger la table PART à l’aide de NULL AS.
-
Format CSV
Pour plus d’informations sur le chargement de données au format CSV, consultez Charger la table PART à l’aide de NULL AS.
-
NULL AS
Pour plus d’informations sur le chargement de PART à l’aide de l’option NULL AS, consultez Charger la table PART à l’aide de NULL AS.
-
Character-delimited format
Pour plus d’informations sur l’utilisation de l’option DELIMITER, consultez Les options DELIMITER et REGION.
-
REGION
Pour plus d’informations sur l’utilisation de l’option REGION, consultez Les options DELIMITER et REGION.
-
Fixed-format largeur
Pour plus d’informations sur le chargement de la table CUSTOMER à partir de données de largeur fixe, consultez Charger la table CUSTOMER à l’aide de MANIFEST.
-
MAXERROR
Pour plus d’informations sur l’utilisation de l’option MAXERROR, consultez Charger la table CUSTOMER à l’aide de MANIFEST.
-
ACCEPTINVCHARS
Pour plus d’informations sur l’utilisation de l’option ACCEPTINVCHARS, consultez Charger la table CUSTOMER à l’aide de MANIFEST.
-
MANIFEST
Pour plus d’informations sur l’utilisation de l’option MANIFEST, consultez Charger la table CUSTOMER à l’aide de MANIFEST.
-
DATEFORMAT
Pour plus d’informations sur l’utilisation de l’option DATEFORMAT, consultez Charger la table DWDATE à l’aide de DATEFORMAT.
-
GZIP, LZOP et BZIP2
Pour plus d’informations sur la compression de vos fichiers, consultez Chargement de plusieurs fichiers de données.
-
COMPUPDATE
Pour plus d’informations sur l’utilisation de l’option COMPUPDATE, consultez Chargement de plusieurs fichiers de données.
-
Plusieurs fichiers
Pour plus d’informations sur le chargement de plusieurs fichiers, consultez Chargement de plusieurs fichiers de données.
Chargement des tables SSB
Vous utilisez les commandes COPY suivantes pour charger chacune des tables dans le schéma SSB. La commande de chaque table illustre les différentes options COPY et des techniques de résolution des problèmes.
Pour charger les tables SSB, procédez comme suit :
Remplacez le nom du bucket et AWS informations d’identification
Les commandes COPY de ce didacticiel sont présentées au format suivant.
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
Pour chaque commande COPY, procédez de la façon suivante :
-
<your-bucket-name>Remplacez-le par le nom d'un compartiment situé dans la même région que votre cluster.Cette étape suppose que le compartiment et le cluster se situent dans la même région. Vous pouvez aussi spécifier la région à l’aide de l’option REGION de la commande COPY.
-
Remplacez
<aws-account-id>et<role-name>par votre propre rôle Compte AWS et celui d'IAM. Le segment de la chaîne d’informations d’identification entre guillemets simples ne doit pas comporter d’espaces ou de sauts de ligne. Notez que le format de l’ARN peut être légèrement différent de celui de l’exemple. Il est préférable de copier l’ARN du rôle depuis la console IAM afin de garantir son exactitude lorsque vous exécutez les commandes COPY.
Charger la table PART à l’aide de NULL AS
Au cours de cette étape, vous utilisez les options CSV et NULL AS pour charger la table PART.
La commande COPY peut charger des données depuis plusieurs fichiers en parallèle, ce qui est beaucoup plus rapide que le chargement depuis un seul fichier. Pour illustrer ce principe, les données de chaque table de ce didacticiel sont divisées réparties dans huit fichiers, même si les fichiers sont très petits. Au cours d’une étape ultérieure, vous comparez la différence de temps entre le chargement d’un fichier unique et le chargement de plusieurs fichiers. Pour plus d'informations, consultez Chargement de fichiers de données.
Préfixe de clé
Vous pouvez charger à partir de plusieurs fichiers en spécifiant un préfixe de clé à l’ensemble de fichiers ou en répertoriant explicitement les fichiers dans un fichier manifeste. Au cours de cette étape, vous utilisez un préfixe de clé. Au cours d’une étape ultérieure, vous utilisez un fichier manifeste. Le préfixe de clé 's3://amzn-s3-demo-bucket/load/part-csv.tbl' charge l’ensemble de fichiers suivant dans le dossier load.
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Format CSV
Le format CSV, qui signifie des valeurs séparées par une virgule, est un format couramment utilisé pour importer et exporter les données de feuille de calcul. Le format CSV est plus souple que le format séparé par une virgule, car il vous permet d’inclure des chaînes entre guillemets dans les champs. Le type de guillemets par défaut pour la commande COPY exécutée depuis le format CSV est celui des guillemets doubles ( " ), mais vous pouvez spécifier un autre type de guillemets à l’aide de l’option QUOTE AS. Lorsque vous utilisez les guillemets dans un champ, précédez le caractère de guillemets supplémentaires.
L'extrait suivant d'un fichier de CSV-formatted données pour la table PART montre des chaînes entre guillemets doubles ("LARGE ANODIZED
BRASS"). Il montre également une chaîne entourée de doubles guillemets dans une chaîne entourée de guillemets ("MEDIUM ""BURNISHED"" TIN").
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
Les données de la table PART contiennent des caractères qui entraînent l’échec de la commande COPY. Dans cet exercice, vous allez résoudre les erreurs et les corriger.
Pour charger des données au format , ajoutez csvcsv à votre commande COPY. Exécutez la commande suivante afin de charger la table PART.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
Vous pourriez recevoir un message d’erreur similaire au suivant.
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
Pour obtenir plus d’informations sur l’erreur, interrogez la table STL_LOAD_ERRORS. La requête suivante utilise la fonction SUBSTRING pour réduire les colonnes afin de faciliter la lecture et utilise LIMIT 10 pour réduire le nombre de lignes renvoyées. Vous pouvez ajuster les valeurs dans substring(filename,22,25) afin d’autoriser la longueur du nom de votre compartiment.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL AS
Les fichiers de données part-csv.tbl utilisent la marque de fin NUL (\x000 ou \x0) pour indiquer des valeurs NULL.
Note
Malgré une orthographe très similaire, NUL et NULL ne sont pas identiques. NUL est un UTF-8 caractère dont le point de code x000 est souvent utilisé pour indiquer la fin de l'enregistrement (EOR). NULL est une valeur SQL qui représente l’absence de données.
Par défaut, COPY traite une marque de fin NUL comme une marque de fin d’enregistrement et met fin à l’enregistrement, ce qui entraîne souvent des résultats inattendus ou une erreur. Il n’existe pas de méthode standard unique pour indiquer NULL dans les données de texte. Par conséquent, l’option de commande NULL AS COPY vous permet de spécifier le caractère à remplacer par NULL lors du chargement de la table. Dans cet exemple, vous voulez exécuter la commande COPY pour traiter la marque de fin NUL en tant que valeur NULL.
Note
La colonne de la table qui reçoit la valeur NULL doit être configurée comme acceptant la valeur null. Autrement dit, elle ne doit pas inclure la contrainte NOT NULL dans la spécification CREATE TABLE.
Pour charger la table PART en utilisant l’option AS NULL, exécutez la commande COPY suivante.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
Pour vérifier que la commande COPY a chargé des valeurs NULL, exécutez la commande suivante pour sélectionner uniquement les lignes qui contiennent la valeur NULL.
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
Les options DELIMITER et REGION
Les options DELIMITER et REGION sont importantes pour comprendre comment charger des données.
Character-delimited format
Les champs d'un fichier délimité par des caractères sont séparés par un caractère spécifique, tel qu'un tube (|), une virgule (,) ou un onglet (\ t). Character-delimited les fichiers peuvent utiliser n'importe quel caractère ASCII, y compris l'un des caractères ASCII non imprimables, comme séparateur. Vous spécifiez le délimiteur à l’aide de l’option DELIMITER. Le délimiteur par défaut est une barre verticale ( | ).
L’extrait suivant des données de la table SUPPLIER utilise le format délimité par une barre verticale.
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
REGION
Dans la mesure du possible, vous devez localiser vos données de chargement dans la même AWS région que votre cluster Amazon Redshift. Si vos données et votre cluster se trouvent dans la même région, cela vous permet de réduire la latence et d’éviter des coûts de transfert régional de données. Pour de plus amples informations, veuillez consulter Bonnes pratiques de chargement des données sur Amazon Redshift.
Si vous devez charger des données provenant d'une autre AWS région, utilisez l'option REGION pour spécifier la AWS région dans laquelle se trouvent les données de chargement. Si vous spécifiez une région, toutes les données de chargement, notamment les fichiers manifestes, doivent se situer dans la région désignée. Pour plus d’informations, consultez REGION.
Si votre cluster se trouve dans la région USA Est (Virginie du Nord) et que votre compartiment Amazon S3 se trouve dans la région USA Ouest (Oregon), la commande COPY suivante montre comment charger la table SUPPLIER à partir de données séparées par une barre verticale.
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
Charger la table CUSTOMER à l’aide de MANIFEST
Au cours de cette étape, vous utilisez les options FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS et MANIFEST pour charger la table CUSTOMER.
Les exemples de données de cet exercice contiennent des caractères qui entraînent des erreurs lorsque COPY tente de les charger. Vous utilisez l’option MAXERRORS et la table système STL_LOAD_ERRORS pour résoudre les erreurs de chargement, puis utiliser les options ACCEPTINVCHARS et MANIFEST pour éliminer les erreurs.
Fixed-Width Format
Fixed-width format définit chaque champ comme un nombre fixe de caractères, plutôt que de séparer les champs par un délimiteur. L’extrait suivant des données de la table CUSTOMER utilise le format à largeur fixe.
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
L'ordre des label/width paires doit correspondre exactement à l'ordre des colonnes du tableau. Pour de plus amples informations, veuillez consulter FIXEDWIDTH.
La chaîne de spécification à largeur fixe pour les données de la table CUSTOMER est la suivante.
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
Pour charger la table CUSTOMER à partir de données à largeur fixe, exécutez la commande suivante.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
Vous devez recevoir un message d’erreur similaire au suivant.
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
Par défaut, la première fois que COPY rencontre une erreur, la commande échoue et renvoie un message d’erreur. Pour gagner du temps pendant le test, vous pouvez utiliser l’option MAXERROR pour indiquer à COPY d’ignorer un nombre d’erreurs spécifié avant d’échouer. Du fait que nous anticipons des erreurs la première fois que nous testons le chargement des données de la table CUSTOMER, ajoutez maxerror 10 à la commande COPY.
Pour effectuer le test en utilisant les options FIXEDWIDTH et MAXERROR, exécutez la commande suivante.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
Cette fois-ci, au lieu d’un message d’erreur, vous recevez un message d’avertissement semblable au suivant.
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
L’avertissement indique que la commande COPY a rencontré sept erreurs. Pour vérifier les erreurs, interrogez la table STL_LOAD_ERRORS, comme illustré dans l’exemple suivant.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
Les résultats de la requête STL_LOAD_ERRORS doivent être similaires à ce qui suit.
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
En examinant les résultats, vous pouvez voir qu’il y a deux messages dans la colonne error_reasons :
-
Invalid digit, Value '#', Pos 0, Type: IntegCes erreurs sont entraînées par le fichier
customer-fw.tbl.log. Le problème est qu’il existe un fichier journal, pas un fichier de données et qu’il ne doit pas être chargé. Vous pouvez utiliser un fichier manifeste pour éviter le chargement du fichier incorrect. -
String contains invalid or unsupported UTF8Le type de données VARCHAR prend en charge les UTF-8 caractères multioctets d'une taille maximale de trois octets. Si les données de chargement contiennent des caractères non pris en charge ou non valides, vous pouvez utiliser l’option ACCEPTINVCHARS pour remplacer chaque caractère non valide par un caractère alternatif spécifié.
Un autre problème se pose avec la charge qui est plus difficile à détecter : les résultats inattendus produits par la charge. Afin d’étudier ce problème, exécutez la commande suivante pour interroger la table CUSTOMER.
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
Les lignes doivent être uniques, mais il existe des doublons.
Pour vérifier les résultats inattendus, vous pouvez également vérifier le nombre de lignes qui ont été chargées. Dans notre cas, 100 000 lignes ont été chargées, mais le message de chargement a signalé le chargement de 112 497 enregistrements. Des lignes supplémentaires ont été chargées, car la commande COPY a chargé un fichier superflu, customer-fw.tbl0000.bak.
Dans cet exercice, vous utilisez un fichier manifeste pour éviter de charger des fichiers incorrects.
ACCEPTINVCHARS
Par défaut, lorsque la commande COPY rencontre un caractère qui n’est pas pris en charge par le type de données de la colonne, il ignore la ligne et renvoie une erreur. Pour plus d'informations sur les UTF-8 caractères non valides, consultezErreurs de chargement de caractères multioctets.
Vous pouvez utiliser l’option MAXERRORS pour ignorer les erreurs et continuer le chargement, puis interroger STL_LOAD_ERRORS pour rechercher les caractères non valides et corriger les fichiers de données. Cependant, MAXERRORS est plus utile pour résoudre les problèmes de chargement et ne doit pas être utilisé, en général, dans un environnement de production.
L’option ACCEPTINVCHARS est généralement un choix plus adapté à la gestion des caractères non valides. ACCEPTINVCHARS indique que la commande COPY doit remplacer chaque caractère non valide par un caractère valide spécifié et poursuivre l’opération de chargement. Vous pouvez spécifier n’importe quel caractère ASCII valide, sauf NULL, comme caractère de remplacement. Le caractère de remplacement par défaut est un point d’interrogation ( ? ). La commande COPY remplace les caractères de plusieurs octets par une chaîne de remplacement de la même longueur. Par exemple, un caractère de 4 octets serait remplacé par '????'.
COPY renvoie le nombre de lignes contenant des UTF-8 caractères non valides. Cette commande ajoute également une entrée à la table système STL_REPLACEMENTS pour chaque ligne affectée, jusqu’à un maximum de 100 lignes par tranche de nœud. Les UTF-8 caractères non valides supplémentaires sont également remplacés, mais ces événements de remplacement ne sont pas enregistrés.
ACCEPTINVCHARS est valide uniquement pour les colonnes VARCHAR.
Pour cette étape, vous ajoutez ACCEPTINVCHARS au caractère de remplacement '^'.
MANIFEST
Lorsque vous exécutez la commande COPY à partir d’Amazon S3 à l’aide d’un préfixe de clé, il y a un risque que vous chargiez des tables indésirables. Par exemple, le dossier 's3://amzn-s3-demo-bucket/load/ contient huit fichiers de données partageant le préfixe de clé customer-fw.tbl : customer-fw.tbl0000, customer-fw.tbl0001 et ainsi de suite. Cependant, le même dossier contient également les fichiers superflus customer-fw.tbl.log et customer-fw.tbl-0001.bak.
Pour vous assurer que vous chargez tous les fichiers corrects et uniquement les fichiers corrects, utilisez un fichier manifeste. Le manifeste est un fichier texte au format JSON qui répertorie explicitement la clé d’objet unique de chaque fichier source à charger. Les objets de fichier peuvent se situer dans différents dossiers ou compartiments, mais ils doivent se trouver dans la même région. Pour plus d'informations, consultez MANIFEST.
L’exemple suivant illustre le texte customer-fw-manifest.
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
Pour charger les données de la table CUSTOMER en utilisant le fichier manifeste
-
Ouvrez le fichier
customer-fw-manifestdans un éditeur de texte. -
Remplacez
<your-bucket-name>par le nom de votre compartiment. -
Enregistrez le fichier.
-
Chargez le fichier dans le dossier de chargement de votre compartiment.
-
Exécutez la commande COPY suivante.
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
Charger la table DWDATE à l’aide de DATEFORMAT
Au cours de cette étape, vous utilisez les options DELIMITER et DATEFORMAT pour charger la table DWDATE.
Lors du chargement des colonnes DATE et TIMESTAMP, COPY s'attend au format par défaut, à savoir YYYY-MM-DD les dates et YYYY-MM-DD HH:MI:SS les horodatages. Si les données de chargement n’utilisent pas un format par défaut, vous pouvez utiliser DATEFORMAT et TIMEFORMAT pour spécifier le format.
L’extrait suivant présente les formats de date du tableau DWDATE. Notez que les formats de date de la colonne deux sont incompatibles.
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
DATEFORMAT
Vous ne pouvez spécifier qu’un seul format de date. Si les données de chargement contiennent des formats incompatibles, éventuellement dans différentes colonnes, ou si le format n’est pas connu au moment du chargement, vous utilisez DATEFORMAT avec l’argument 'auto'. Lorsque 'auto' est spécifié, la commande COPY reconnaît tous les formats d’heure ou de date valides et les convertira au format par défaut. L’option 'auto' reconnaît plusieurs formats qui ne sont pas pris en charge lors de l’utilisation d’une chaîne DATEFORMAT et TIMEFORMAT. Pour plus d'informations, consultez Utilisation de la reconnaissance automatique avec DATEFORMAT et TIMEFORMAT.
Pour charger la table DWDATE, exécutez la commande COPY suivante.
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
Chargement de plusieurs fichiers de données
Vous pouvez utiliser les options GZIP et COMPUPDATE pour charger une table.
Vous pouvez charger une table à partir d’un seul fichier de données ou de plusieurs fichiers. Cela vous permet de comparer les temps de chargement pour les deux méthodes.
GZIP, LZOP et BZIP2
Vous pouvez compresser vos fichiers à l’aide des formats de compression gzip, lzop ou bzip2. Lors du chargement de fichiers compressés, la commande COPY décompresse les fichiers pendant le processus de chargement. La compression de vos fichiers enregistre l’espace de stockage et réduit les temps de chargement.
COMPUPDATE
Lorsque la commande COPY charge une table vide sans aucun codage de compression, elle analyse les données de chargement pour déterminer les encodages optimaux. Elle modifie ensuite la table afin d’utiliser ces encodages avant de commencer le chargement. Ce processus d’analyse prend du temps, mais il se produit, tout au plus, une fois par table. Pour gagner du temps, vous pouvez ignorer cette étape en désactivant COMPUPDATE. Pour permettre une évaluation précise de temps de la commande COPY, vous désactivez COMPUPDATE pour cette étape.
Plusieurs fichiers
La commande COPY peut charger les données de manière très efficace en chargeant plusieurs fichiers en parallèle plutôt qu’un seul fichier. Vous pouvez scinder vos données en fichiers de telle sorte que le nombre de fichiers soit un multiple du nombre de tranches de votre cluster. Le cas échéant, Amazon Redshift divise la charge de travail et répartit les données de façon uniforme entre les tranches. Le nombre de tranches par nœud dépend de la taille de nœud du cluster. Pour plus d’informations sur le nombre de tranches pour chaque taille de nœud, consultez la rubrique À propos des clusters et nœuds dans le Guide de gestion Amazon Redshift.
Par exemple, les nœuds de calcul de votre cluster dans ce didacticiel se composent de deux tranches chacun, afin que le cluster à quatre nœuds se compose de huit tranches. Au cours des étapes précédentes, les données de chargement étaient contenues dans huit fichiers, même si les fichiers étaient très petits. Vous pouvez comparer la différence de temps entre le chargement d’un fichier volumineux unique et le chargement de plusieurs fichiers.
Même les fichiers qui contiennent 15 millions d’enregistrements et occupent environ 1,2 Go sont très petits à l’échelle Amazon Redshift. Ils sont toutefois suffisants pour démontrer l’avantage que représente le chargement de plusieurs fichiers en termes de performances.
L’image suivante présente les fichiers de données pour LINEORDER.
Pour évaluer les performances de la commande COPY avec plusieurs fichiers
-
Dans un atelier de test, la commande suivante a été exécutée pour utiliser COPY à partir d’un seul fichier. Cette commande affiche un compartiment fictif.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Les résultats ont été les suivants. Notez le délai d’exécution.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
La commande suivante a ensuite été exécutée pour utiliser COPY à partir de plusieurs fichiers.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Les résultats ont été les suivants. Notez le délai d’exécution.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
Comparez les temps d’exécution.
Dans notre expérience, le temps de chargement de 15 millions d’enregistrements est passé de 51,56 secondes à 17,7 secondes, soit une diminution de 65,7 %.
Ces résultats sont basés sur l’utilisation d’un cluster à quatre nœuds. Si votre cluster comporte plusieurs nœuds, les gains de temps sont multipliés. Pour des clusters Amazon Redshift classiques, avec des dizaines, voire des centaines de nœuds, la différence est encore plus spectaculaire. Si vous disposez d’un cluster à nœud unique, il y a peu de différence entre les temps d’exécution.
Étape 6 : Vider et analyser la base de données
Chaque fois que vous ajoutez, supprimez ou modifiez un grand nombre de lignes, vous devez exécuter une commande VACUUM, puis une commande ANALYZE. Une commande vacuum récupère l’espace des lignes supprimées et restaure l’ordre de tri. La commande ANALYZE met à jour les métadonnées des statistiques, ce qui permet à l’optimiseur de requête de générer des plans de requête plus précis. Pour plus d'informations, consultez Exécution de l’opération VACUUM sur les tables.
Si vous chargez les données dans l’ordre d’une clé de tri, le vidage est rapide. Dans ce didacticiel, vous avez ajouté un grand nombre de lignes, mais vous les avez ajoutées à des tables vides. Dans ce cas, il est inutile d’y recourir, et vous n’a pas besoin de supprimer toutes les lignes. La commande COPY met à jour automatiquement les statistiques après le chargement d’une table vide, vos statistiques doivent donc être à jour. Cependant, pour des raisons de bonne gestion, vous terminez ce didacticiel en effectuant un vidage et une analyse de votre base de données.
Pour vider et analyser la base de données, exécutez les commandes suivantes.
vacuum; analyze;
Étape 7 : Nettoyer vos ressources
Votre cluster continue d’accumuler les frais aussi longtemps qu’il est en cours d’exécution. Une fois ce didacticiel terminé, vous devez rétablir votre environnement à l’état précédent en suivant les étapes décrites à l’Étape 5 : Annuler les droits d’accès et supprimer votre exemple de cluster du Guide de démarrage d’Amazon Redshift.
Si vous souhaitez conserver le cluster, mais que vous voulez récupérer le stockage utilisé par les tables SSB, exécutez les commandes suivantes.
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
Suivant
Résumé
Dans ce didacticiel, vous avez téléchargé les fichiers de données dans Amazon S3, puis utilisé les commandes COPY pour charger les données des fichiers dans des tables Amazon Redshift.
Vous avez chargé des données à l’aide des formats suivants :
-
Character-delimited
-
CSV
-
Fixed-width
Vous avez utilisé la table système STL_LOAD_ERRORS pour résoudre les erreurs de chargement, puis utilisé les options REGION, MANIFEST, MAXERROR, ACCEPTINVCHARS, DATEFORMAT et NULL AS pour résoudre les erreurs.
Vous avez appliqué les bonnes pratiques suivantes au chargement des données :
Pour plus d’informations sur les bonnes pratiques Amazon Redshift, consultez les liens suivants :
