Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connexion aux sources de données
Dans Amazon SageMaker Canvas, vous pouvez importer des données depuis un emplacement extérieur à votre système de fichiers local via un AWS service, une plateforme SaaS ou d'autres bases de données à l'aide de connecteurs JDBC. Vous pouvez par exemple importer des tables à partir d'un entrepôt des données dans Amazon Redshift ou importer des données Google Analytics.
Lorsque vous suivez le flux de travail d'importation pour importer des données dans l'application Canvas, vous pouvez choisir votre source de données, puis sélectionner les données que vous souhaitez importer. Pour certaines sources de données, comme Snowflake et Amazon Redshift, vous devez spécifier vos informations d'identification et ajouter une connexion à la source de données.
La capture d'écran suivante illustre la barre d'outils des sources de données dans le flux de travail d'importation, avec toutes les sources de données disponibles mises en évidence. Vous ne pouvez importer des données qu'à partir des sources de données mises à votre disposition. Contactez votre administrateur si la source de données souhaitée n'est pas disponible.
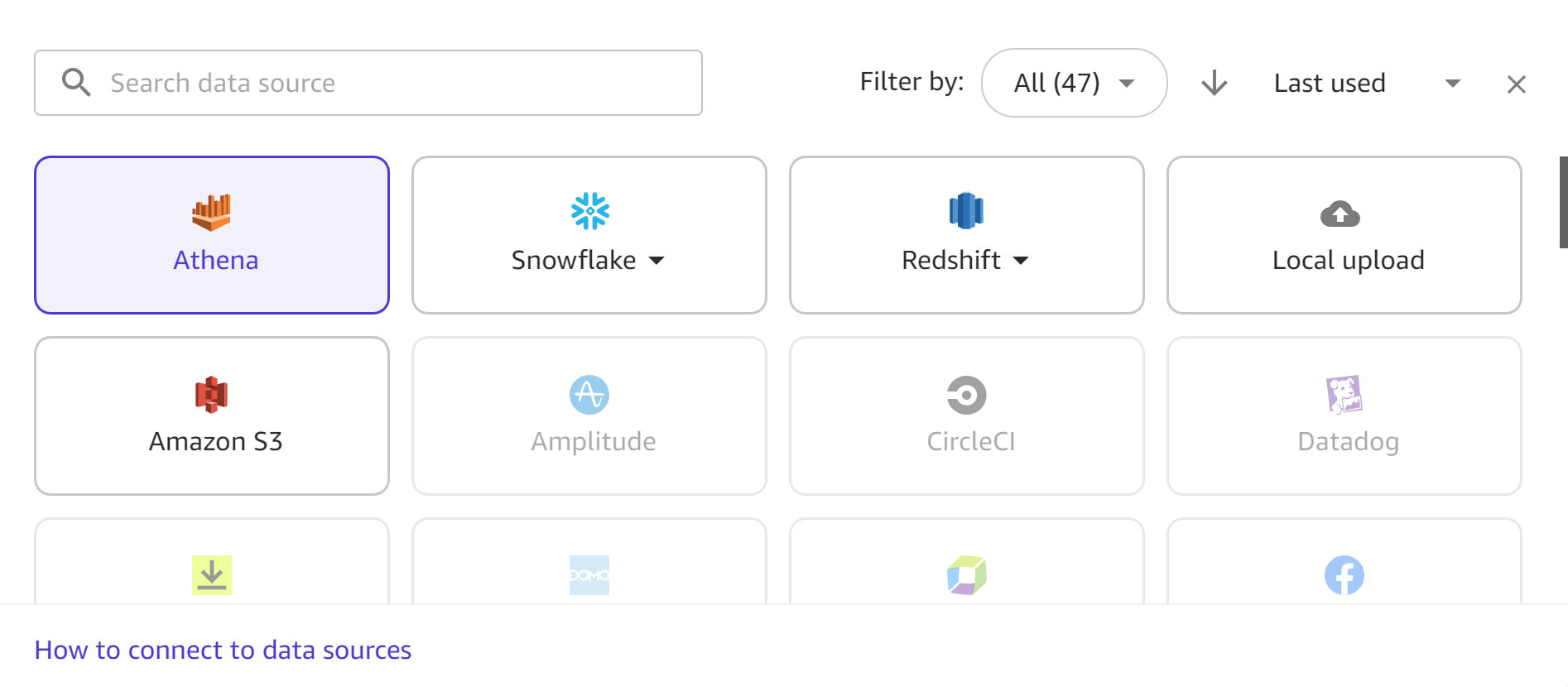
Les sections suivantes fournissent des informations sur l'établissement de connexions à des sources de données externes et sur l'importation de données à partir de celles-ci. Consultez d'abord la section suivante pour déterminer les autorisations nécessaires pour importer des données à partir de votre source de données.
Autorisations
Consultez les informations suivantes pour vous assurer que vous disposez des autorisations nécessaires pour importer des données à partir de votre source de données :
Amazon S3 : vous pouvez importer des données à partir de n'importe quel compartiment Amazon S3 tant que votre utilisateur est autorisé à accéder au compartiment. Pour plus d'informations sur l'utilisation d' AWS IAM pour contrôler l'accès aux compartiments Amazon S3, consultez la section Gestion des identités et des accès dans Amazon S3 dans le guide de l'utilisateur Amazon S3.
Amazon Athena : si la AmazonSageMakerFullAccesspolitique et la politique sont associées au rôle d'exécution de votre utilisateur, vous pouvez vous renseigner AWS Glue Data Catalog auprès d'Amazon Athena. AmazonSageMakerCanvasFullAccess Si vous faites partie d'un groupe de travail Athena, assurez-vous que l'utilisateur de Canvas est autorisé à exécuter des requêtes Athena sur les données. Pour plus d'informations, consultez Utilisation de groupes de travail pour exécuter des requêtes dans le Guide de l'utilisateur Amazon Athena.
Amazon DocumentDB : vous pouvez importer des données depuis n'importe quelle base de données Amazon DocumentDB à condition de disposer des informations d'identification (nom d'utilisateur et mot de passe) nécessaires pour vous connecter à la base de données et de disposer des autorisations Canvas de base minimales associées au rôle d'exécution de votre utilisateur. Pour plus d'informations sur les autorisations Canvas, consultez leConditions préalables à la configuration d'Amazon Canvas SageMaker .
Amazon Redshift : pour vous accorder les autorisations nécessaires pour importer des données à partir d'Amazon Redshift, consultez Octroi d'autorisations aux utilisateurs pour importer des données Amazon Redshift (langue française non garantie).
Amazon RDS : si la AmazonSageMakerCanvasFullAccesspolitique est attachée au rôle d'exécution de votre utilisateur, vous pourrez accéder à vos bases de données Amazon RDS depuis Canvas.
Plateformes SaaS : si la AmazonSageMakerFullAccesspolitique et la AmazonSageMakerCanvasFullAccesspolitique sont associées au rôle d'exécution de votre utilisateur, vous disposez des autorisations nécessaires pour importer des données depuis des plateformes SaaS. Pour plus d'informations sur la connexion à un connecteur SaaS spécifique, consultez Utilisation de connecteurs SaaS avec Canvas.
Connecteurs JDBC : pour les sources de base de données telles que Databricks, MySQL ou MariaDB, vous devez activer l'authentification par nom d'utilisateur et mot de passe sur la base de données source avant de tenter de vous connecter à partir de Canvas. Si vous vous connectez à une base de données Databricks, vous devez disposer de l'URL JDBC contenant les informations d'identification nécessaires.
Connectez-vous à une base de données stockée dans AWS
Vous souhaiterez peut-être importer les données que vous y avez stockées AWS. Vous pouvez importer des données depuis Amazon S3, utiliser Amazon Athena pour interroger une base de données dans le AWS Glue Data Catalog, importer des données depuis Amazon RDS ou établir une connexion à une base de données Amazon Redshift provisionnée (et non Redshift Serverless).
Vous pouvez créer plusieurs connexions à Amazon Redshift. Pour Amazon Athena, vous pouvez accéder à toutes les bases de données figurant dans votre AWS Glue Data Catalog. Pour Amazon S3, vous pouvez importer des données à partir d'un compartiment, à condition de disposer des autorisations nécessaires.
Pour plus d'informations, consultez les sections suivantes.
Connexion aux données dans Amazon S3, Amazon Athena ou Amazon RDS
Pour Amazon S3, vous pouvez importer des données à partir d'un compartiment Amazon S3 tant que vous disposez des autorisations pour accéder au compartiment.
Pour Amazon Athena, vous pouvez accéder aux bases de données de votre ordinateur AWS Glue Data Catalog tant que vous disposez des autorisations nécessaires par le biais de votre groupe de travail Amazon Athena.
Pour Amazon RDS, si la AmazonSageMakerCanvasFullAccesspolitique est associée au rôle de votre utilisateur, vous pourrez importer des données de vos bases de données Amazon RDS dans Canvas.
Pour importer des données à partir d'un compartiment Amazon S3 ou pour exécuter des requêtes et importer des tables de données avec Amazon Athena, consultez Création d'un jeu de données. Vous pouvez uniquement importer des données tabulaires à partir d'Amazon Athena et vous pouvez importer des données tabulaires et des données d'image à partir d'Amazon S3.
Connectez-vous à une base de données Amazon DocumentDB
Amazon DocumentDB est un service de base de données de documents entièrement géré et sans serveur. Vous pouvez importer des données documentaires non structurées stockées dans une base de données Amazon DocumentDB SageMaker dans Canvas sous forme de jeu de données tabulaire, puis vous pouvez créer des modèles d'apprentissage automatique à partir de ces données.
Important
Votre domaine SageMaker AI doit être configuré en mode VPC uniquement pour ajouter des connexions à Amazon DocumentDB. Vous ne pouvez accéder aux clusters Amazon DocumentDB que dans le même Amazon VPC que votre application Canvas. En outre, Canvas ne peut se connecter qu'aux clusters Amazon DocumentDB compatibles TLS. Pour plus d'informations sur la configuration de Canvas en mode VPC uniquement, consultez. Configuration d'Amazon SageMaker Canvas dans un VPC sans accès à Internet
Pour importer des données depuis des bases de données Amazon DocumentDB, vous devez disposer d'informations d'identification pour accéder à la base de données Amazon DocumentDB et spécifier le nom d'utilisateur et le mot de passe lors de la création d'une connexion à la base de données. Vous pouvez configurer des autorisations plus détaillées et restreindre l'accès en modifiant les autorisations utilisateur Amazon DocumentDB. Pour en savoir plus sur le contrôle d'accès dans Amazon DocumentDB, consultez la section Accès aux bases de données à l'aide du contrôle d'accès basé sur les rôles dans le manuel du développeur Amazon DocumentDB.
Lorsque vous importez depuis Amazon DocumentDB, Canvas convertit vos données non structurées en un jeu de données tabulaire en mappant les champs aux colonnes d'un tableau. Des tables supplémentaires sont créées pour chaque champ complexe (ou structure imbriquée) des données, les colonnes correspondant aux sous-champs du champ complexe. Pour obtenir des informations plus détaillées sur ce processus et des exemples de conversion de schéma, consultez la page Amazon DocumentDB Driver Schema Discovery.
Canvas ne peut établir une connexion qu'à une seule base de données dans Amazon DocumentDB. Pour importer des données depuis une autre base de données, vous devez créer une nouvelle connexion.
Vous pouvez importer des données depuis Amazon DocumentDB dans Canvas en utilisant les méthodes suivantes :
-
Création d'un jeu de données. Vous pouvez importer vos données Amazon DocumentDB et créer un jeu de données tabulaire dans Canvas. Si vous choisissez cette méthode, assurez-vous de suivre la procédure d'importation de données tabulaires.
-
Création d'un flux de données. Vous pouvez créer un pipeline de préparation des données dans Canvas et ajouter votre base de données Amazon DocumentDB en tant que source de données.
Pour procéder à l'importation de vos données, suivez la procédure correspondant à l'une des méthodes indiquées dans la liste précédente.
Lorsque vous atteignez l'étape de sélection d'une source de données dans l'un des flux de travail (étape 6 pour créer un jeu de données ou étape 8 pour créer un flux de données), procédez comme suit :
Pour Source de données, ouvrez le menu déroulant et choisissez DocumentDB.
Choisissez Add Connection (Ajouter une connexion).
-
Dans la boîte de dialogue, spécifiez vos informations d'identification Amazon DocumentDB :
Entrez le Nom de la connexion. Il s'agit d'un nom utilisé par Canvas pour identifier cette connexion.
Pour Cluster, sélectionnez le cluster dans Amazon DocumentDB qui stocke vos données. Canvas remplit automatiquement le menu déroulant avec les clusters Amazon DocumentDB situés dans le même VPC que votre application Canvas.
Entrez le nom d'utilisateur de votre cluster Amazon DocumentDB.
Entrez le mot de passe de votre cluster Amazon DocumentDB.
Entrez le nom de la base de données à laquelle vous souhaitez vous connecter.
-
L'option de préférence de lecture détermine les types d'instances de votre cluster dont Canvas lit les données. Sélectionnez l'un des éléments suivants :
Option secondaire préférée : Canvas lit par défaut à partir des instances secondaires du cluster, mais si aucune instance secondaire n'est disponible, Canvas lit à partir d'une instance principale.
Secondaire — Canvas ne lit que les instances secondaires du cluster, ce qui empêche les opérations de lecture d'interférer avec les opérations de lecture et d'écriture normales du cluster.
-
Choisissez Add Connection (Ajouter une connexion). L'image suivante montre la boîte de dialogue contenant les champs précédents pour une connexion Amazon DocumentDB.
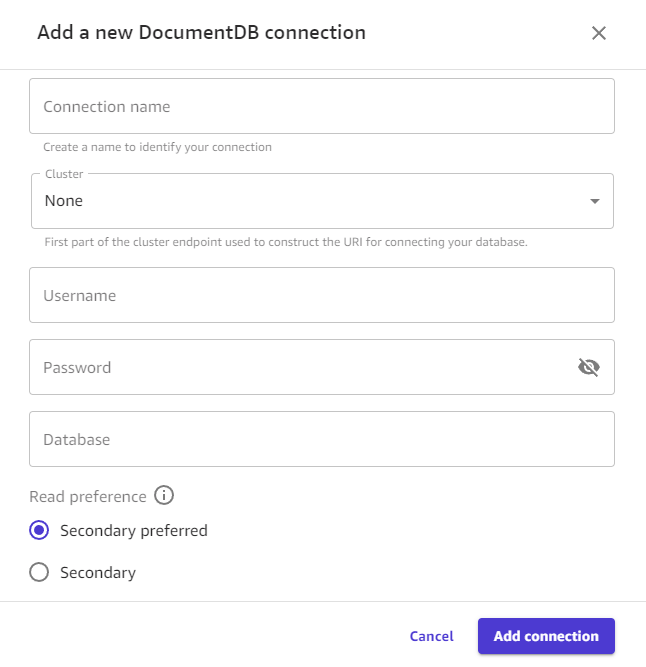
Vous devriez maintenant disposer d'une connexion Amazon DocumentDB, et vous pouvez utiliser vos données Amazon DocumentDB dans Canvas pour créer un ensemble de données ou un flux de données.
Connexion à une base de données Amazon Redshift
Vous pouvez importer des données depuis Amazon Redshift, un entrepôt de données dans lequel votre organisation conserve ses données. Avant de pouvoir importer des données depuis Amazon Redshift, le rôle AWS IAM que vous utilisez doit être associé à la politique AmazonRedshiftFullAccess gérée. Pour obtenir des instructions sur la façon d'attacher cette politique, consultez Autorisation des utilisateurs à importer des données Amazon Redshift.
Pour importer des données depuis Amazon Redshift, procédez comme suit :
-
Créez une connexion à une base de données Amazon Redshift.
-
Choisissez les données que vous importez.
-
Importez les données.
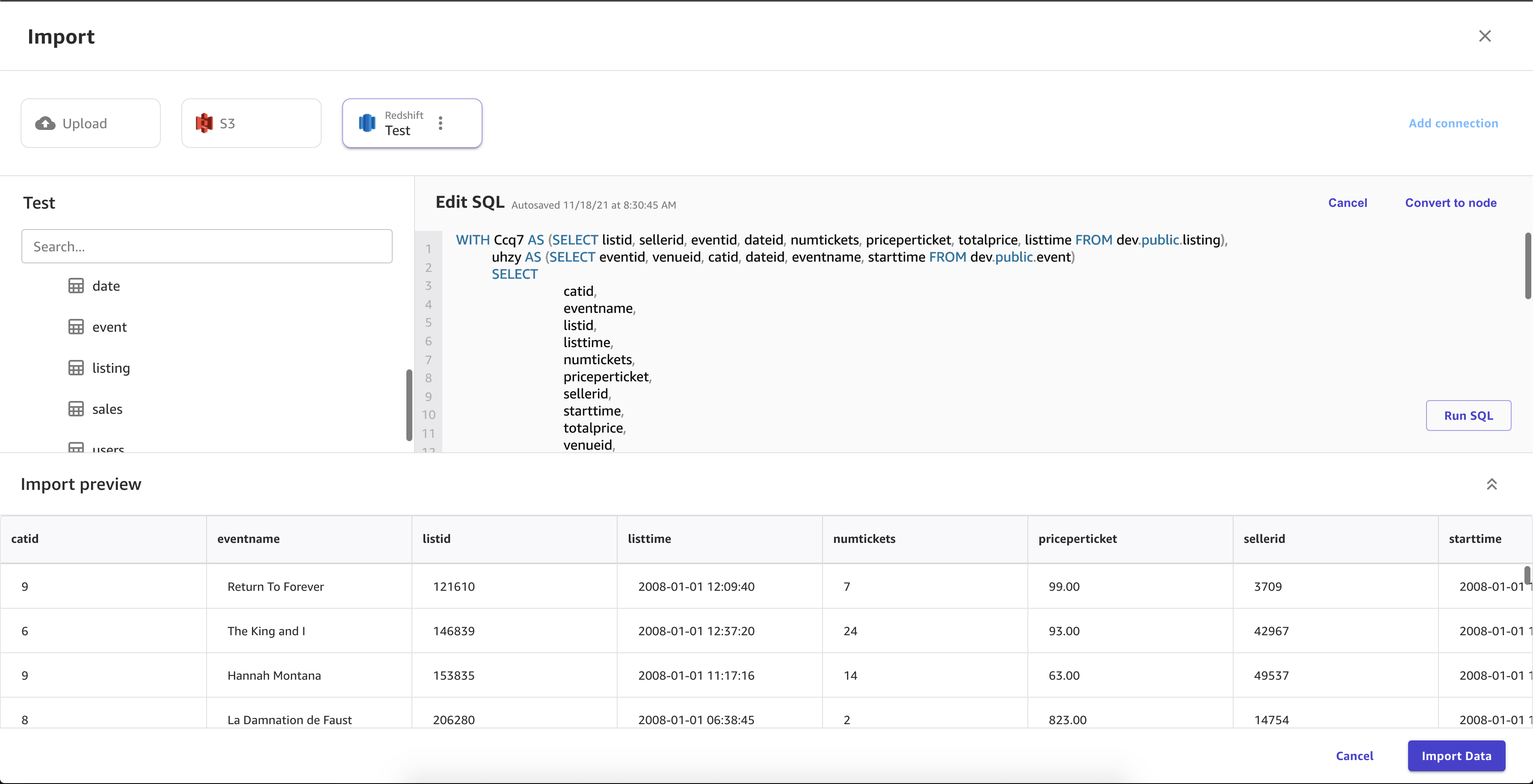
Vous pouvez utiliser l'éditeur Amazon Redshift pour faire glisser des ensembles de données vers le volet d'importation et les importer dans Canvas. SageMaker Pour plus de contrôle sur les valeurs renvoyées dans le jeu de données, vous pouvez utiliser les éléments suivants :
-
Requêtes SQL
-
Jointures
Les requêtes SQL vous permettent de personnaliser la façon dont vous importez les valeurs dans le jeu de données. Par exemple, vous pouvez spécifier les colonnes renvoyées dans le jeu de données ou la plage de valeurs d'une colonne.
Vous pouvez utiliser des jointures pour combiner plusieurs jeux de données d'Amazon Redshift dans un seul jeu de données. Vous pouvez déplacer vos jeux de données depuis Amazon Redshift vers le panneau qui vous permet de joindre les jeux de données.
Vous pouvez utiliser l'éditeur SQL pour modifier le jeu de données que vous avez joint et convertir le jeu de données joint en un seul nœud. Vous pouvez joindre un autre jeu de données au nœud. Vous pouvez importer les données que vous avez sélectionnées dans SageMaker Canvas.
Utilisez la procédure suivante pour importer des données à partir d'Amazon Redshift.
Dans l'application SageMaker Canvas, accédez à la page Ensembles de données.
Choisissez Importer des données, puis dans le menu déroulant, choisissez Tabulaire.
-
Entrez un nom pour le jeu de données et choisissez Créer.
Pour Source de données, ouvrez le menu déroulant et choisissez Redshift.
-
Choisissez Add Connection (Ajouter une connexion).
-
Dans la boîte de dialogue, spécifiez vos informations d'identification Amazon Redshift :
-
Pour Méthode d'authentification, choisissez IAM.
-
Entrez l'Identifiant du cluster pour spécifier à quel cluster vous souhaitez vous connecter. Entrez uniquement l'identifiant de cluster et non le point de terminaison complet du cluster Amazon Redshift.
-
Entrez le Nom de la base de données à laquelle vous souhaitez vous connecter.
-
Entrez un Utilisateur de base de données pour identifier l'utilisateur que vous souhaitez utiliser pour vous connecter à la base de données.
-
Pour ARN, entrez l'ARN de rôle IAM du rôle que le cluster Amazon Redshift doit assumer pour déplacer et écrire des données dans Amazon S3. Pour plus d'informations sur ce rôle, consultez la section Autoriser Amazon Redshift à accéder à AWS d'autres services en votre nom dans le guide de gestion Amazon Redshift.
-
Entrez le Nom de la connexion. Il s'agit d'un nom utilisé par Canvas pour identifier cette connexion.
-
-
À partir de l'onglet qui porte le nom de votre connexion, faites glisser le fichier .csv que vous importez vers le panneau Drag and drop table to import (Glisser-déplacer la table à importer).
-
Vous pouvez déplacer d'autres tables dans le volet d'importation. Vous pouvez utiliser l'interface graphique pour joindre les tables. Pour plus de spécificité dans vos jointures, choisissez Edit in SQL (Éditer dans SQL).
-
Facultatif : si vous utilisez SQL pour interroger les données, vous pouvez choisir Context (Contexte) pour ajouter du contexte à la connexion en spécifiant les valeurs suivantes :
-
Warehouse (Entrepôt)
-
Database (Base de données)
-
Schema (Schéma)
-
-
Choisissez Import data (Importer les données).
L'image suivante présente un exemple de champs spécifiés pour une connexion Amazon Redshift.
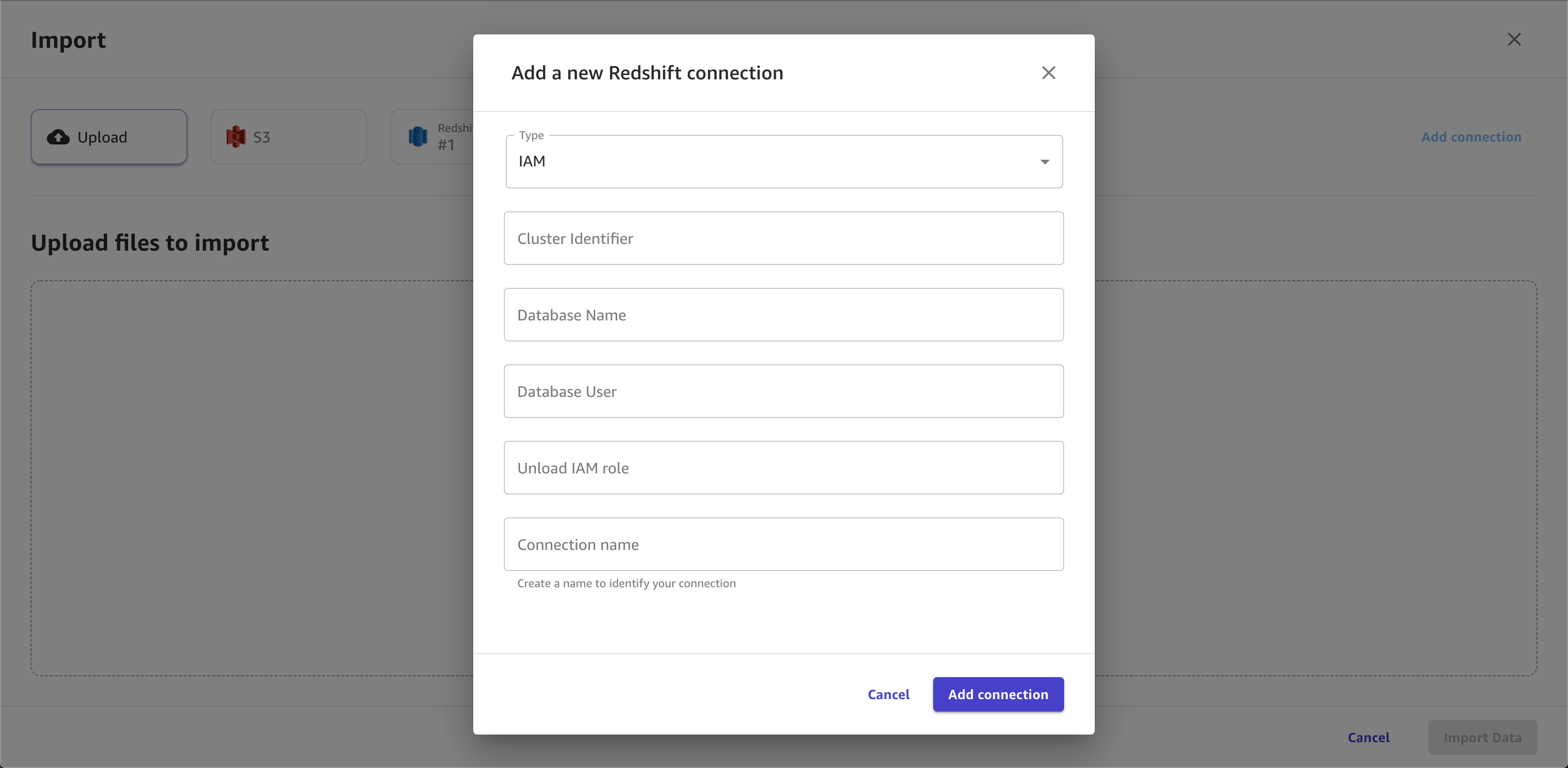
L'image suivante montre la page utilisée pour joindre des jeux de données dans Amazon Redshift.
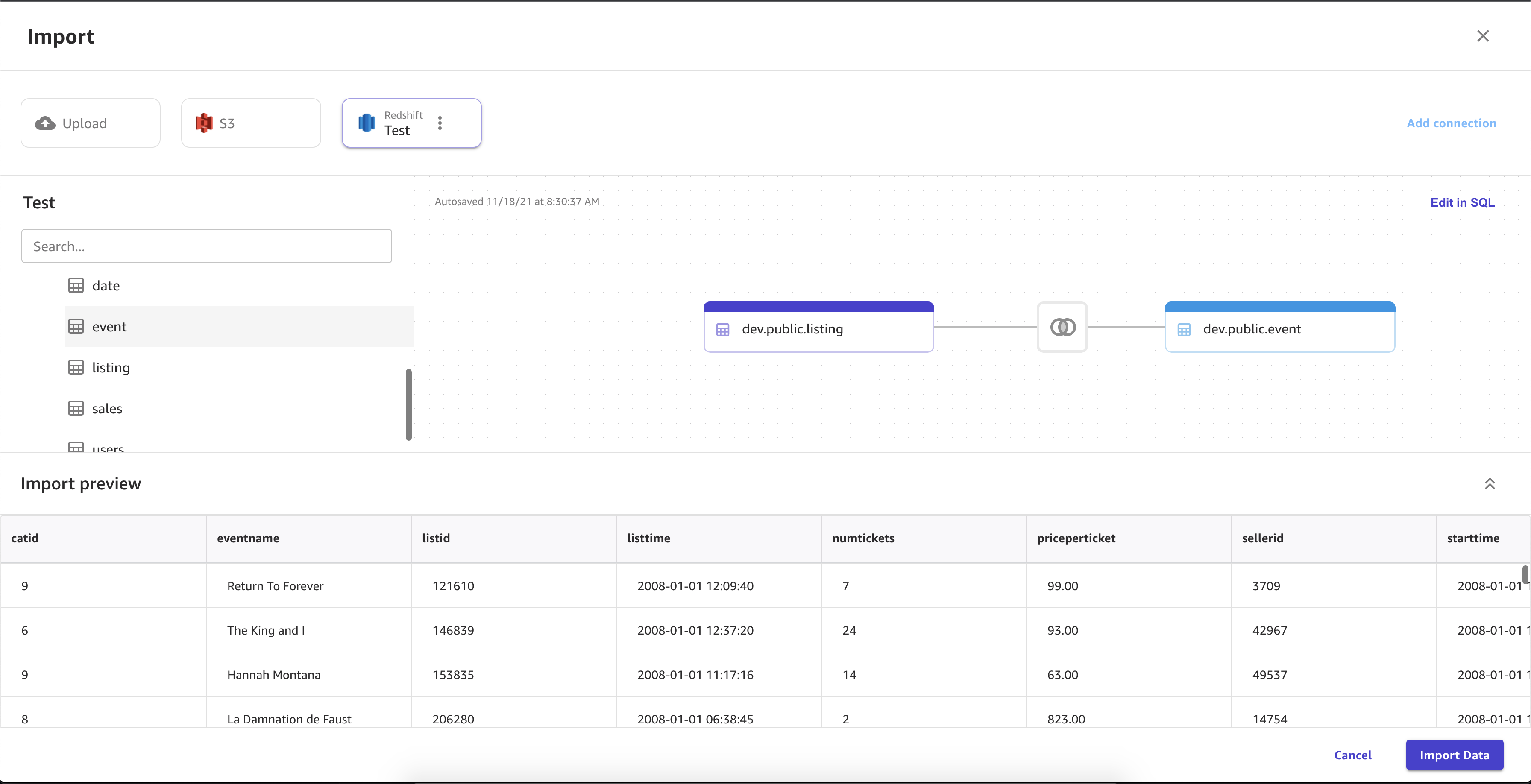
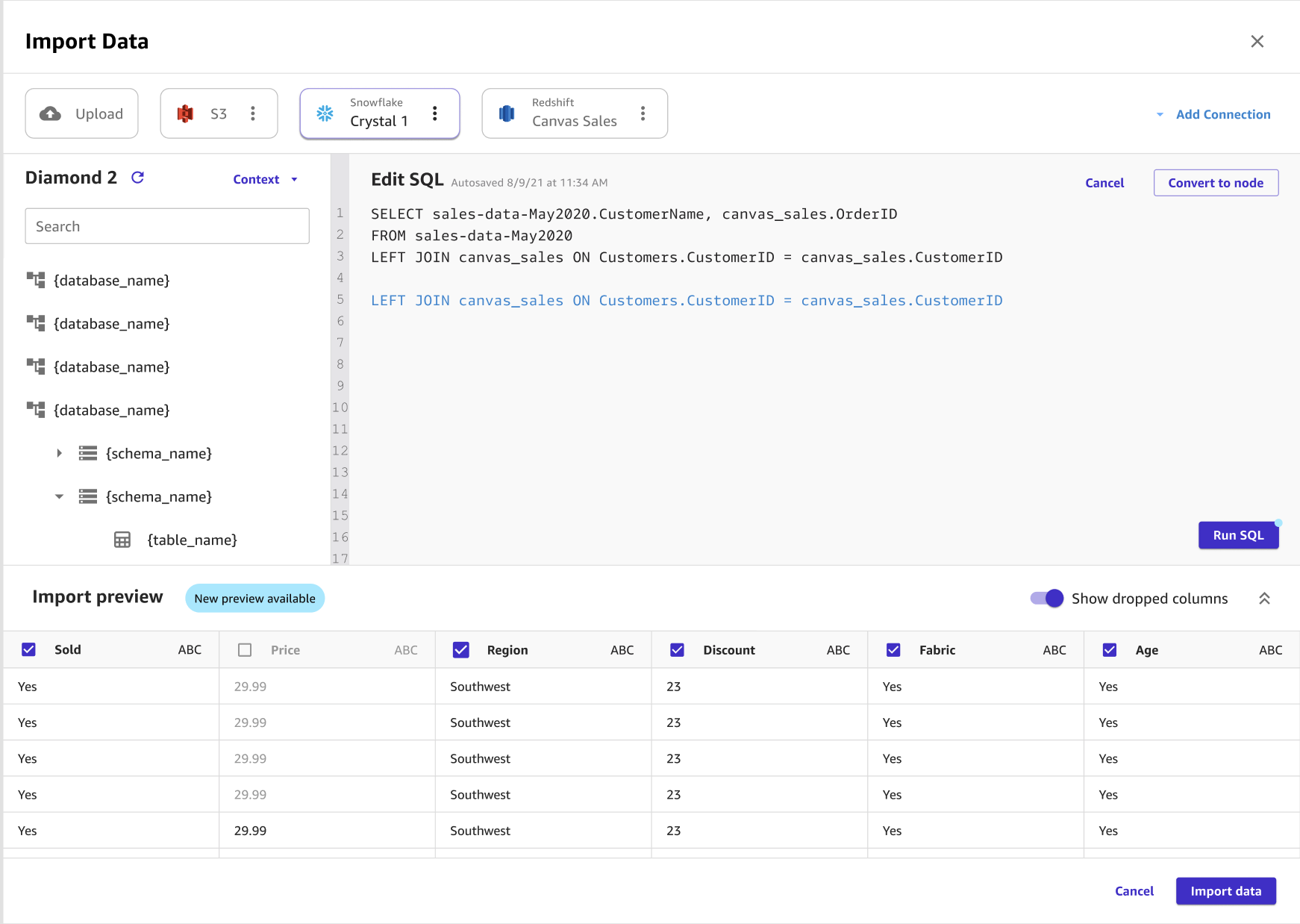
L'image suivante illustre une requête SQL utilisée pour modifier une jointure dans Amazon Redshift.
Connexion à vos données avec des connecteurs JDBC
Avec JDBC, vous pouvez vous connecter à vos bases de données à partir de sources telles que Databricks, SQLServer MySQL, PostgreSQL, MariaDB, Amazon RDS et Amazon Aurora.
Vous devez vous assurer que vous disposez des informations d'identification et des autorisations nécessaires pour créer la connexion à partir de Canvas.
Pour Databricks, vous devez fournir une URL JDBC. Le format de l'URL peut varier d'une instance Databricks à l'autre. Pour plus d'informations sur la recherche de l'URL et sur la spécification des paramètres qu'elle contient, consultez Paramètres de configuration et de connexion JDBC
(langue française non garantie) dans la documentation Databricks. Voici un exemple de format d'URL : jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-tokenPour les autres sources de base de données, vous devez configurer l'authentification par nom d'utilisateur et mot de passe, puis spécifier ces informations d'identification lors de la connexion à la base de données à partir de Canvas.
En outre, votre source de données doit être accessible via Internet public ou, si votre application Canvas s'exécute en mode VPC uniquement, la source de données doit s'exécuter dans le même VPC. Pour plus d'informations sur la configuration d'une base de données Amazon RDS dans un VPC, consultez Amazon VPC VPCs et Amazon RDS dans le guide de l'utilisateur Amazon RDS.
Après avoir configuré les informations d'identification de votre source de données, vous pouvez vous connecter à l'application Canvas et créer une connexion à la source de données. Spécifiez vos informations d'identification (ou l'URL pour Databricks) lors de la création de la connexion.
Connectez-vous aux sources de données avec OAuth
Canvas prend en charge l'utilisation OAuth comme méthode d'authentification pour la connexion à vos données dans Snowflake et Salesforce Data Cloud. OAuth
Note
Vous ne pouvez établir qu'une seule OAuth connexion pour chaque source de données.
Pour autoriser la connexion, vous devez suivre la configuration initiale décrite à la rubrique Configurez des connexions aux sources de données avec OAuth.
Après avoir configuré les OAuth informations d'identification, vous pouvez effectuer les opérations suivantes pour ajouter une connexion Snowflake ou Salesforce Data Cloud avec : OAuth
Connectez-vous à l'application Canvas.
Créez un jeu de données tabulaire. Lorsque vous êtes invité à charger des données, choisissez Snowflake ou Salesforce Data Cloud comme source de données.
Créez une connexion à votre source de données Snowflake ou Salesforce Data Cloud. Spécifiez OAuth comme méthode d'authentification et entrez vos informations de connexion.
Vous devriez désormais pouvoir importer des données à partir de vos bases de données dans Snowflake ou Salesforce Data Cloud.
Connexion à une plateforme SaaS
Vous pouvez importer des données à partir de Snowflake et plus de 40 autres plateformes SaaS externes. Pour obtenir la liste complète des connecteurs, consultez le tableau à la rubrique Importation de données.
Note
Vous ne pouvez importer que des données tabulaires, telles que des tables de données, à partir de plateformes SaaS.
Utilisation de Snowflake avec Canvas
Snowflake est un service de stockage et d'analyse de données, et vous pouvez importer vos données de Snowflake dans Canvas. SageMaker Pour plus d'informations sur Snowflake, consultez la documentation de Snowflake
Vous pouvez importer des données depuis votre compte Snowflake en procédant comme suit :
-
Créez une connexion à la base de données Snowflake.
-
Choisissez les données que vous importez en faisant glisser la table depuis le menu de navigation de gauche vers l'éditeur.
-
Importez les données.
Vous pouvez utiliser l'éditeur Snowflake pour faire glisser des ensembles de données vers le volet d'importation et les importer dans Canvas. SageMaker Pour plus de contrôle sur les valeurs renvoyées dans le jeu de données, vous pouvez utiliser les éléments suivants :
-
Requêtes SQL
-
Jointures
Les requêtes SQL vous permettent de personnaliser la façon dont vous importez les valeurs dans le jeu de données. Par exemple, vous pouvez spécifier les colonnes renvoyées dans le jeu de données ou la plage de valeurs d'une colonne.
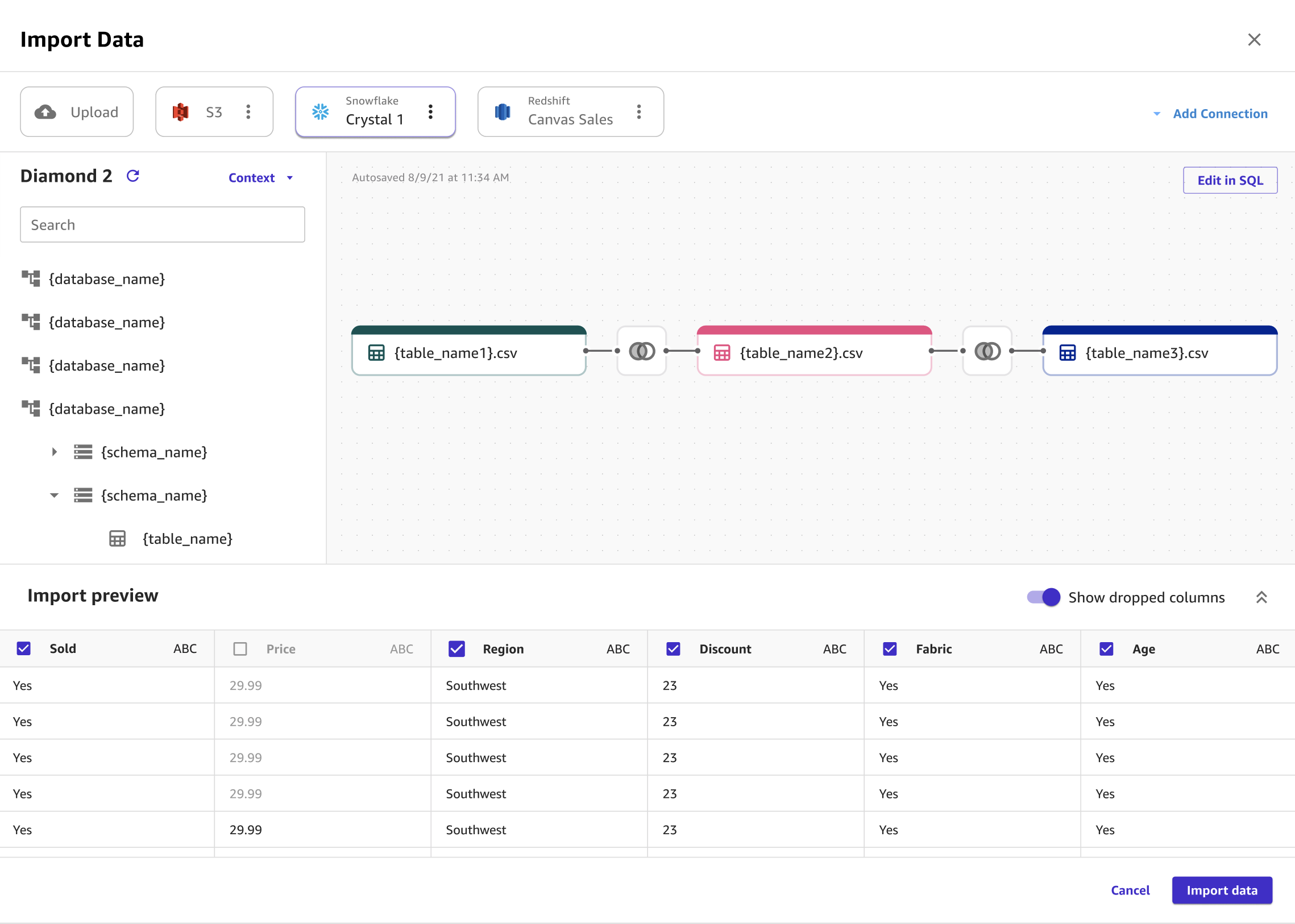
Vous pouvez joindre plusieurs jeux de données Snowflake en un seul jeu de données avant de l'importer dans Canvas à l'aide de SQL ou de l'interface de Canvas. Vous pouvez déplacer vos jeux de données depuis Snowflake vers le panneau qui vous permet de joindre les jeux de données, ou modifier les jointures dans SQL et convertir le code SQL en un nœud unique. Vous pouvez joindre d'autres nœuds au nœud que vous avez converti. Vous pouvez ensuite combiner les jeux de données que vous avez joints dans un seul nœud et joindre les nœuds à un autre jeu de données Snowflake. Pour finir, vous pouvez importer les données que vous avez sélectionnées dans Canvas.
Utilisez la procédure suivante pour importer des données de Snowflake vers Amazon SageMaker Canvas.
Dans l'application SageMaker Canvas, accédez à la page Ensembles de données.
Choisissez Importer des données, puis dans le menu déroulant, choisissez Tabulaire.
-
Entrez un nom pour le jeu de données et choisissez Créer.
Pour Source de données, ouvrez le menu déroulant et choisissez Snowflake.
-
Choisissez Add Connection (Ajouter une connexion).
-
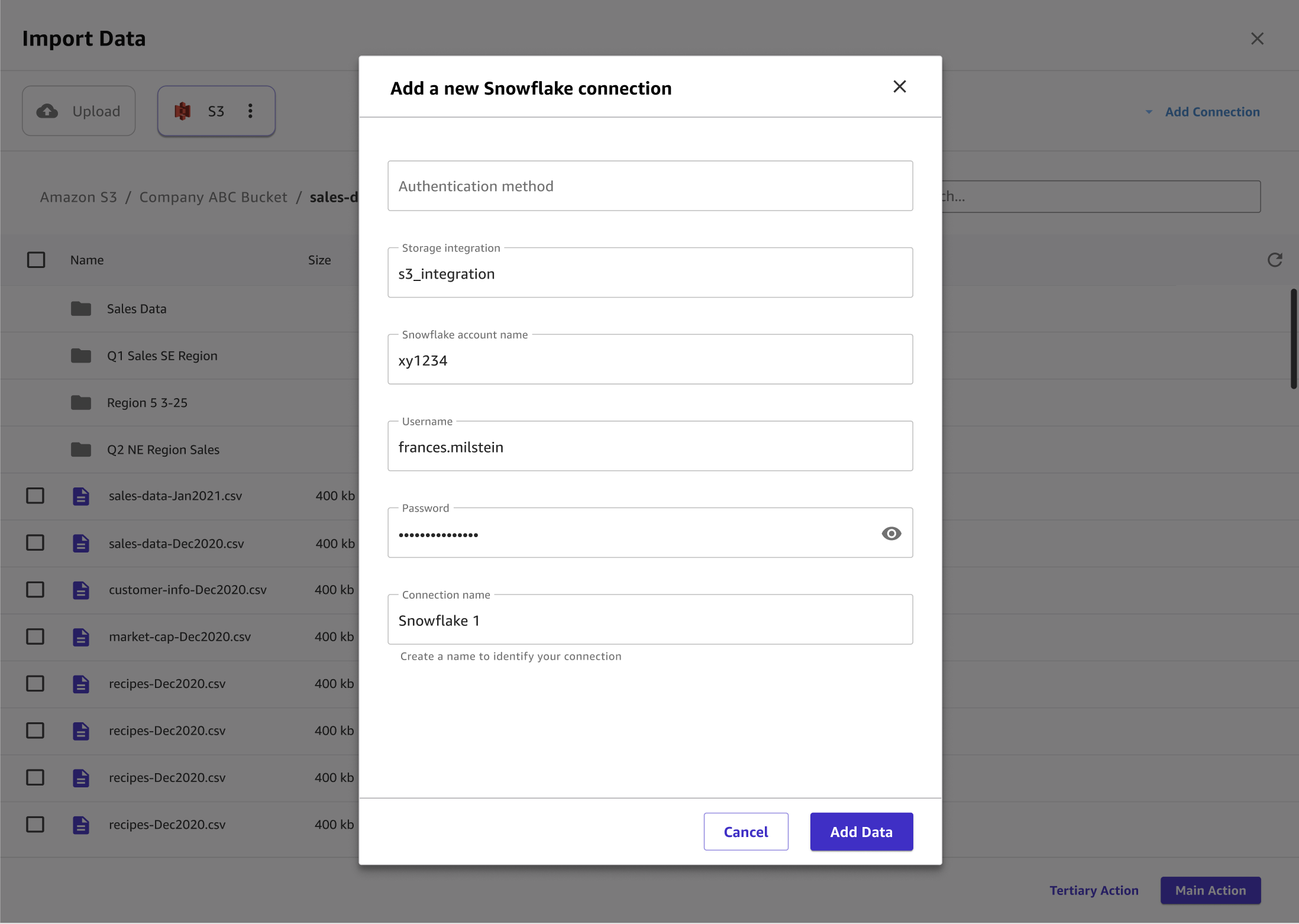
Dans la boîte de dialogue Ajouter une nouvelle connexion Snowflake, spécifiez vos informations d'identification Snowflake. Pour la méthode d'authentification, choisissez l'une des options suivantes :
Basic - nom d'utilisateur et mot de passe — Fournissez votre identifiant de compte Snowflake, votre nom d'utilisateur et votre mot de passe.
-
ARN — Pour une meilleure protection de vos informations d'identification Snowflake, fournissez l'ARN d'un AWS Secrets Manager secret contenant vos informations d'identification. Pour plus d'informations, voir Création d'un AWS Secrets Manager secret dans le guide de AWS Secrets Manager l'utilisateur.
Votre secret doit contenir vos informations d'identification Snowflake stockées au format JSON suivant :
{"accountid": "ID", "username": "username", "password": "password"} OAuth— vous OAuth permet de vous authentifier sans fournir de mot de passe, mais nécessite une configuration supplémentaire. Pour plus d'informations sur la configuration des OAuth informations d'identification pour Snowflake, consultez. Configurez des connexions aux sources de données avec OAuth
-
Choisissez Add Connection (Ajouter une connexion).
-
À partir de l'onglet qui porte le nom de votre connexion, faites glisser le fichier .csv que vous importez vers le panneau Drag and drop table to import (Glisser-déplacer la table à importer).
-
Facultatif : déplacez d'autres tables dans le volet d'importation. Vous pouvez utiliser l'interface utilisateur pour joindre les tables. Pour plus de spécificité dans vos jointures, choisissez Edit in SQL (Éditer dans SQL).
-
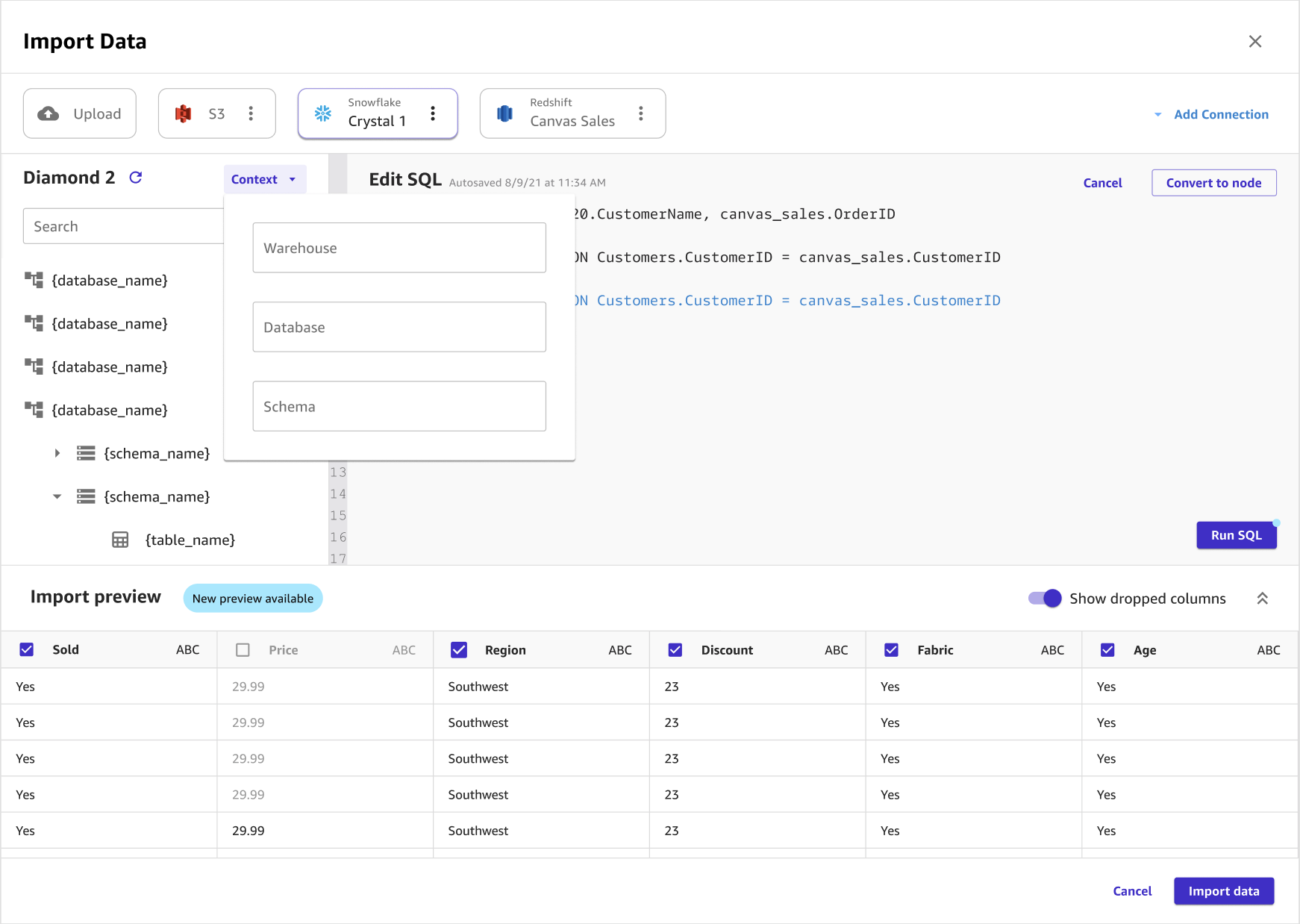
Facultatif : si vous utilisez SQL pour interroger les données, vous pouvez choisir Context (Contexte) pour ajouter du contexte à la connexion en spécifiant les valeurs suivantes :
-
Warehouse (Entrepôt)
-
Database (Base de données)
-
Schema (Schéma)
L'ajout de contexte à une connexion permet de spécifier plus facilement les futures requêtes.
-
-
Choisissez Import data (Importer les données).
L'image suivante présente un exemple de champs spécifiés pour une connexion Snowflake.
L'image suivante montre la page utilisée pour ajouter du contexte à une connexion.
L'image suivante montre la page utilisée pour joindre les jeux de données dans Snowflake.
L'image suivante montre une requête SQL utilisée pour modifier une jointure dans Snowflake.
Utilisation de connecteurs SaaS avec Canvas
Note
Pour les plateformes SaaS autres que Snowflake, vous ne pouvez avoir qu'une seule connexion par source de données.
Avant de pouvoir importer des données à partir d'une plateforme SaaS, votre administrateur doit s'authentifier et créer une connexion à la source de données. Pour plus d'informations sur la manière dont les administrateurs peuvent créer une connexion avec une plateforme SaaS, consultez la section Gestion des AppFlow connexions Amazon dans le guide de AppFlow l'utilisateur Amazon.
Si vous êtes administrateur et que vous commencez à utiliser Amazon AppFlow pour la première fois, consultez Getting started dans le guide de AppFlow l'utilisateur Amazon.
Pour importer des données à partir d'une plateforme SaaS, vous pouvez suivre la procédure standard d(Importation de données tabulaires) qui explique comment importer des jeux de données tabulaires dans Canvas.
