AWS IoT Greengrass Version 1 entered the extended life phase on June 30, 2023. For more information, see the AWS IoT Greengrass V1 maintenance policy. After this date, AWS IoT Greengrass V1 won't release updates that provide features, enhancements, bug fixes, or security patches. Devices that run on AWS IoT Greengrass V1 won't be disrupted and will continue to operate and to connect to the cloud. We strongly recommend that you migrate to AWS IoT Greengrass Version 2, which adds significant new features and support for additional platforms.
Perform machine learning inference
This feature is available for AWS IoT Greengrass Core v1.6 or later.
With AWS IoT Greengrass, you can perform machine learning (ML) inference at the edge on locally generated data using cloud-trained models. You benefit from the low latency and cost savings of running local inference, yet still take advantage of cloud computing power for training models and complex processing.
To get started performing local inference, see How to configure machine learning inference using the AWS Management Console.
How AWS IoT Greengrass ML inference works
You can train your inference models anywhere, deploy them locally as machine
learning resources in a Greengrass group, and then access them from Greengrass
Lambda functions. For example, you can build and train deep-learning models in SageMaker AI
The following diagram shows the AWS IoT Greengrass ML inference workflow.
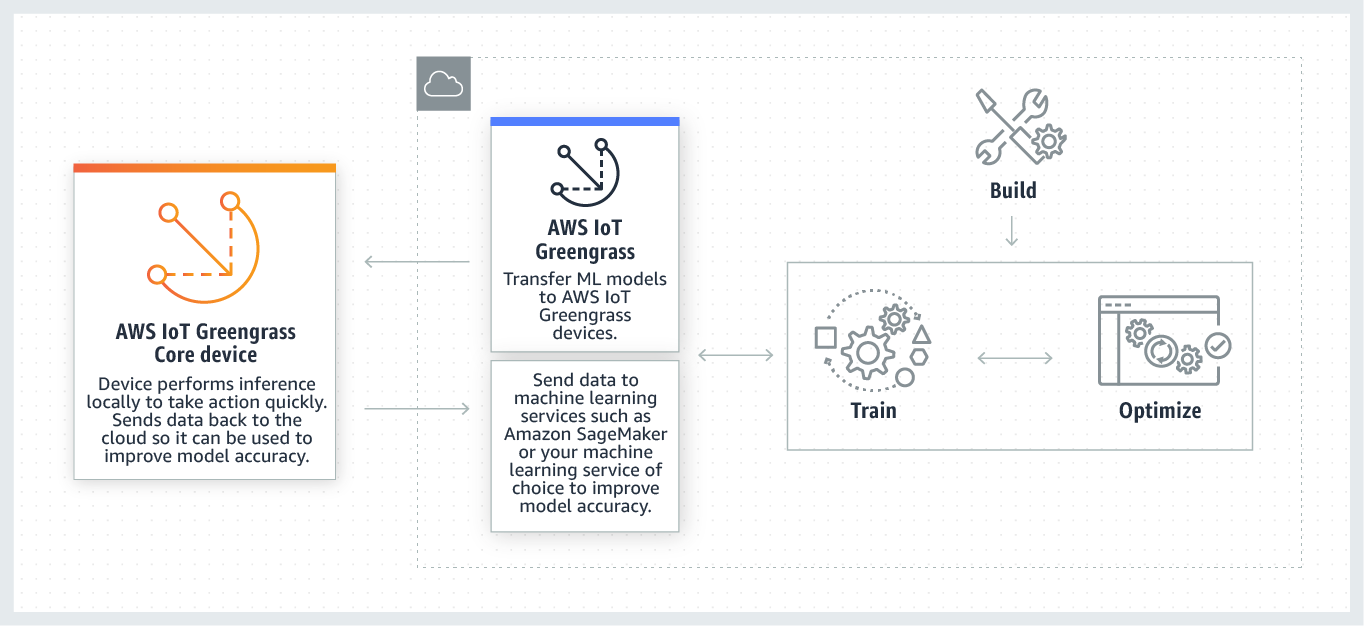
AWS IoT Greengrass ML inference simplifies each step of the ML workflow, including:
-
Building and deploying ML framework prototypes.
-
Accessing cloud-trained models and deploying them to Greengrass core devices.
-
Creating inference apps that can access hardware accelerators (such as GPUs and FPGAs) as local resources.
Machine learning resources
Machine learning resources represent cloud-trained inference models that are deployed to an AWS IoT Greengrass core. To deploy machine learning resources, first you add the resources to a Greengrass group, and then you define how Lambda functions in the group can access them. During group deployment, AWS IoT Greengrass retrieves the source model packages from the cloud and extracts them to directories inside the Lambda runtime namespace. Then, Greengrass Lambda functions use the locally deployed models to perform inference.
To update a locally deployed model, first update the source model (in the cloud) that corresponds to the machine learning resource, and then deploy the group. During deployment, AWS IoT Greengrass checks the source for changes. If changes are detected, then AWS IoT Greengrass updates the local model.
Supported model sources
AWS IoT Greengrass supports SageMaker AI and Amazon S3 model sources for machine learning resources.
The following requirements apply to model sources:
-
S3 buckets that store your SageMaker AI and Amazon S3 model sources must not be encrypted using SSE-C. For buckets that use server-side encryption, AWS IoT Greengrass ML inference currently supports the SSE-S3 or SSE-KMS encryption options only. For more information about server-side encryption options, see Protecting data using server-side encryption in the Amazon Simple Storage Service User Guide.
-
The names of S3 buckets that store your SageMaker AI and Amazon S3 model sources must not include periods (
.). For more information, see the rule about using virtual hosted-style buckets with SSL in Rules for bucket naming in the Amazon Simple Storage Service User Guide. -
Service-level AWS Region support must be available for both AWS IoT Greengrass and SageMaker AI. Currently, AWS IoT Greengrass supports SageMaker AI models in the following Regions:
-
US East (Ohio)
-
US East (N. Virginia)
-
US West (Oregon)
-
Asia Pacific (Mumbai)
-
Asia Pacific (Seoul)
-
Asia Pacific (Singapore)
-
Asia Pacific (Sydney)
-
Asia Pacific (Tokyo)
-
Europe (Frankfurt)
-
Europe (Ireland)
-
Europe (London)
-
-
AWS IoT Greengrass must have
readpermission to the model source, as described in the following sections.
- SageMaker AI
-
AWS IoT Greengrass supports models that are saved as SageMaker AI training jobs. SageMaker AI is a fully managed ML service that you can use to build and train models using built-in or custom algorithms. For more information, see What is SageMaker AI? in the SageMaker AI Developer Guide.
If you configured your SageMaker AI environment by creating a bucket whose name contains
sagemaker, then AWS IoT Greengrass has sufficient permission to access your SageMaker AI training jobs. TheAWSGreengrassResourceAccessRolePolicymanaged policy allows access to buckets whose name contains the stringsagemaker. This policy is attached to the Greengrass service role.Otherwise, you must grant AWS IoT Greengrass
readpermission to the bucket where your training job is stored. To do this, embed the following inline policy in the service role. You can list multiple bucket ARNs.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket" ] } ] } - Amazon S3
-
AWS IoT Greengrass supports models that are stored in Amazon S3 as
tar.gzor.zipfiles.To enable AWS IoT Greengrass to access models that are stored in Amazon S3 buckets, you must grant AWS IoT Greengrass
readpermission to access the buckets by doing one of the following:-
Store your model in a bucket whose name contains
greengrass.The
AWSGreengrassResourceAccessRolePolicymanaged policy allows access to buckets whose name contains the stringgreengrass. This policy is attached to the Greengrass service role. -
Embed an inline policy in the Greengrass service role.
If your bucket name doesn't contain
greengrass, add the following inline policy to the service role. You can list multiple bucket ARNs.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket" ] } ] }For more information, see Embedding inline policies in the IAM User Guide.
-
Requirements
The following requirements apply for creating and using machine learning resources:
-
You must be using AWS IoT Greengrass Core v1.6 or later.
-
User-defined Lambda functions can perform
readorread and writeoperations on the resource. Permissions for other operations are not available. The containerization mode of affiliated Lambda functions determines how you set access permissions. For more information, see Access machine learning resources from Lambda functions. -
You must provide the full path of the resource on the operating system of the core device.
-
A resource name or ID has a maximum length of 128 characters and must use the pattern
[a-zA-Z0-9:_-]+.
Runtimes and libraries for ML inference
You can use the following ML runtimes and libraries with AWS IoT Greengrass.
-
Apache MXNet
-
TensorFlow
These runtimes and libraries can be installed on NVIDIA Jetson TX2, Intel Atom, and Raspberry Pi platforms. For download information, see Supported machine learning runtimes and libraries. You can install them directly on your core device.
Be sure to read the following information about compatibility and limitations.
SageMaker AI Neo deep learning runtime
You can use the SageMaker AI Neo deep learning runtime to perform inference with optimized machine learning models on your AWS IoT Greengrass devices. These models are optimized using the SageMaker AI Neo deep learning compiler to improve machine learning inference prediction speeds. For more information about model optimization in SageMaker AI, see the SageMaker AI Neo documentation.
Note
Currently, you can optimize machine learning models using the Neo deep learning compiler in specific Amazon Web Services Regions only. However, you can use the Neo deep learning runtime with optimized models in each AWS Region where AWS IoT Greengrass core is supported. For information, see How to Configure Optimized Machine Learning Inference.
MXNet versioning
Apache MXNet doesn't currently ensure forward compatibility, so models that you train using later versions of the framework might not work properly in earlier versions of the framework. To avoid conflicts between the model-training and model-serving stages, and to provide a consistent end-to-end experience, use the same MXNet framework version in both stages.
MXNet on Raspberry Pi
Greengrass Lambda functions that access local MXNet models must set the following environment variable:
MXNET_ENGINE_TYPE=NativeEngine
You can set the environment variable in the function code or add it to the function's group-specific configuration. For an example that adds it as a configuration setting, see this step.
Note
For general use of the MXNet framework, such as running a third-party code example, the environment variable must be configured on the Raspberry Pi.
TensorFlow model-serving limitations on Raspberry Pi
The following recommendations for improving inference results are based on our tests with the TensorFlow 32-bit Arm libraries on the Raspberry Pi platform. These recommendations are intended for advanced users for reference only, without guarantees of any kind.
-
Models that are trained using the Checkpoint
format should be "frozen" to the protocol buffer format before serving. For an example, see the TensorFlow-Slim image classification model library . -
Don't use the TF-Estimator and TF-Slim libraries in either training or inference code. Instead, use the
.pbfile model-loading pattern that's shown in the following example.graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
Note
For more information about supported platforms for TensorFlow, see Installing
TensorFlow
