Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pemeliharaan server Outposts
Di bawah model tanggung jawab bersama model
Awas
Data pada volume penyimpanan instance hilang jika drive disk yang mendasarinya gagal, atau jika instance berakhir. Untuk mencegah kehilangan data, sebaiknya Anda mencadangkan data jangka panjang pada volume penyimpanan instans ke penyimpanan persisten, seperti bucket Amazon S3 atau perangkat penyimpanan jaringan di jaringan lokal.
Daftar Isi
Perbarui detail kontak
Jika pemilik Outpost berubah, hubungi AWS Dukungan Pusat
Pemeliharaan perangkat keras
Jika AWS mendeteksi masalah perangkat keras yang tidak dapat diperbaiki selama proses penyediaan server atau saat menghosting instans Amazon yang EC2 berjalan di server Outposts Anda, kami akan memberi tahu pemilik Outpost dan pemilik instans bahwa instans yang terpengaruh dijadwalkan untuk pensiun. Untuk informasi selengkapnya, lihat Pensiun instans di Panduan EC2 Pengguna Amazon.
AWS mengakhiri instance yang terpengaruh pada tanggal pensiun instans. Data pada volume penyimpanan instance tidak bertahan setelah penghentian instance. Oleh karena itu, penting bagi Anda untuk mengambil tindakan sebelum tanggal pensiun contoh. Pertama, transfer data jangka panjang Anda dari volume penyimpanan instans untuk setiap instans yang terpengaruh ke penyimpanan persisten, seperti bucket Amazon S3 atau perangkat penyimpanan jaringan di jaringan Anda.
Server pengganti akan dikirim ke situs Outpost. Kemudian, lakukan hal berikut:
-
Lepaskan jaringan dan kabel daya dari server yang tidak dapat diperbaiki dan jika perlu lepaskan dari rak Anda.
-
Instal server pengganti di lokasi yang sama. Ikuti petunjuk penginstalan di Instalasi server Outposts.
-
Kemas server yang tidak dapat diperbaiki ke AWS dalam kemasan yang sama dengan server pengganti.
-
Gunakan label pengiriman pengembalian prabayar yang tersedia di konsol yang dilampirkan pada detail konfigurasi pesanan atau pesanan server pengganti.
-
Kembalikan server ke AWS. Untuk informasi selengkapnya, lihat Mengembalikan AWS Outposts server.
Pembaruan firmware
Memperbarui firmware Outpost biasanya tidak memengaruhi instance di Outpost Anda. Dalam kasus yang jarang terjadi bahwa kita perlu me-reboot peralatan Outpost untuk menginstal pembaruan, Anda akan menerima pemberitahuan pensiun instance untuk setiap instance yang berjalan pada kapasitas itu.
Praktik terbaik untuk acara listrik dan jaringan
Sebagaimana dinyatakan dalam Ketentuan AWS Layanan
Peristiwa kekuasaan
Dengan pemadaman listrik total, ada risiko yang melekat bahwa AWS Outposts sumber daya mungkin tidak kembali ke layanan secara otomatis. Selain menerapkan daya redundan dan solusi daya cadangan, kami menyarankan Anda melakukan hal berikut terlebih dahulu untuk mengurangi dampak dari beberapa skenario terburuk:
-
Pindahkan layanan dan aplikasi Anda dari peralatan Outposts dengan cara yang terkontrol, menggunakan perubahan load-balancing berbasis DNS atau off-rack.
-
Hentikan kontainer, instance, database secara bertahap dan gunakan urutan terbalik saat memulihkannya.
-
Uji rencana untuk pemindahan atau penghentian layanan yang terkontrol.
-
Buat cadangan data dan konfigurasi penting dan simpan di luar Outposts.
-
Pertahankan waktu henti daya seminimal mungkin.
-
Hindari pengalihan berulang dari umpan daya (off-on-off-on) selama pemeliharaan.
-
Berikan waktu ekstra dalam jendela pemeliharaan untuk menangani hal yang tidak terduga.
-
Kelola harapan pengguna dan pelanggan Anda dengan mengkomunikasikan kerangka waktu jendela pemeliharaan yang lebih luas daripada yang biasanya Anda butuhkan.
-
Setelah daya dipulihkan, buat case di AWS Dukungan Center
untuk meminta verifikasi bahwa AWS Outposts dan layanan terkait sedang berjalan.
Acara konektivitas jaringan
Koneksi tautan layanan antara Outpost Anda dan AWS Wilayah atau Outposts home Region biasanya akan secara otomatis pulih dari gangguan jaringan atau masalah yang mungkin terjadi di perangkat jaringan perusahaan hulu Anda atau di jaringan penyedia konektivitas pihak ketiga mana pun setelah pemeliharaan jaringan selesai. Selama koneksi tautan layanan tidak aktif, operasi Outposts Anda terbatas pada aktivitas jaringan lokal.
EC2 Instans Amazon, jaringan LNI, dan volume penyimpanan instans di server Outposts akan terus beroperasi secara normal dan dapat diakses secara lokal melalui jaringan lokal dan LNI. Demikian pula, sumber daya AWS layanan seperti node pekerja Amazon ECS terus berjalan secara lokal. Namun, ketersediaan API akan terdegradasi. Misalnya, run, start, stop, dan terminate APIs mungkin tidak berfungsi. Metrik dan log instans akan terus di-cache secara lokal hingga 7 hari, dan akan didorong ke AWS Wilayah saat konektivitas kembali. Pemutusan lebih dari 7 hari dapat mengakibatkan hilangnya metrik dan log.
Jika tautan layanan tidak aktif karena masalah daya di tempat atau hilangnya konektivitas jaringan, maka akan AWS Health Dashboard mengirimkan pemberitahuan ke akun yang memiliki Outposts. Baik Anda maupun tidak AWS dapat menekan pemberitahuan gangguan tautan layanan, bahkan jika gangguan diharapkan. Untuk informasi selengkapnya, lihat Memulai dengan Anda AWS Health Dashboard di Panduan AWS Health Pengguna.
Dalam hal pemeliharaan layanan terencana yang akan memengaruhi konektivitas jaringan, ambil langkah-langkah proaktif berikut untuk membatasi dampak skenario bermasalah potensial:
-
Jika Anda mengendalikan pemeliharaan jaringan, batasi durasi downtime untuk tautan layanan. Sertakan langkah dalam proses pemeliharaan Anda yang memverifikasi bahwa jaringan telah pulih.
-
Jika Anda tidak mengendalikan pemeliharaan jaringan, pantau downtime tautan layanan sehubungan dengan jendela pemeliharaan yang diumumkan dan eskalasi lebih awal kepada pihak yang bertanggung jawab atas pemeliharaan jaringan yang direncanakan jika tautan layanan tidak dicadangkan pada akhir jendela pemeliharaan yang diumumkan.
Sumber daya
Berikut adalah beberapa sumber daya terkait pemantauan yang dapat memberikan jaminan bahwa Outposts beroperasi secara normal setelah peristiwa listrik atau jaringan yang direncanakan atau tidak direncanakan:
-
AWS Blog Pemantauan praktik terbaik untuk AWS Outposts
mencakup observabilitas dan praktik terbaik manajemen acara khusus untuk Outposts. -
Alat debugging AWS blog untuk konektivitas jaringan dari Amazon VPC
menjelaskan AWSSupport-SetupIPMonitoringFromVPCalat ini. Alat ini adalah AWS Systems Manager dokumen (dokumen SSM) yang membuat Instans EC2 Monitor Amazon di subnet yang ditentukan oleh Anda dan memantau alamat IP target. Dokumen menjalankan tes diagnostik ping, MTR, TCP trace-route dan trace-path dan menyimpan hasilnya di Amazon CloudWatch Logs yang dapat divisualisasikan di CloudWatch dasbor (misalnya latensi, kehilangan paket). Untuk pemantauan Outposts, Instans Monitor harus berada di satu subnet dari AWS Wilayah induk dan dikonfigurasi untuk memantau satu atau lebih instance Outpost Anda menggunakan IP pribadinya - ini akan memberikan grafik kehilangan paket dan latensi antara dan Wilayah induk. AWS Outposts AWS -
AWS Blog Menyebarkan CloudWatch dasbor Amazon otomatis untuk AWS Outposts digunakan AWS CDK
menjelaskan langkah-langkah yang terlibat dalam menerapkan dasbor otomatis. -
Jika Anda memiliki pertanyaan atau memerlukan informasi selengkapnya, lihat Membuat kasus AWS dukungan di Panduan Pengguna Support.
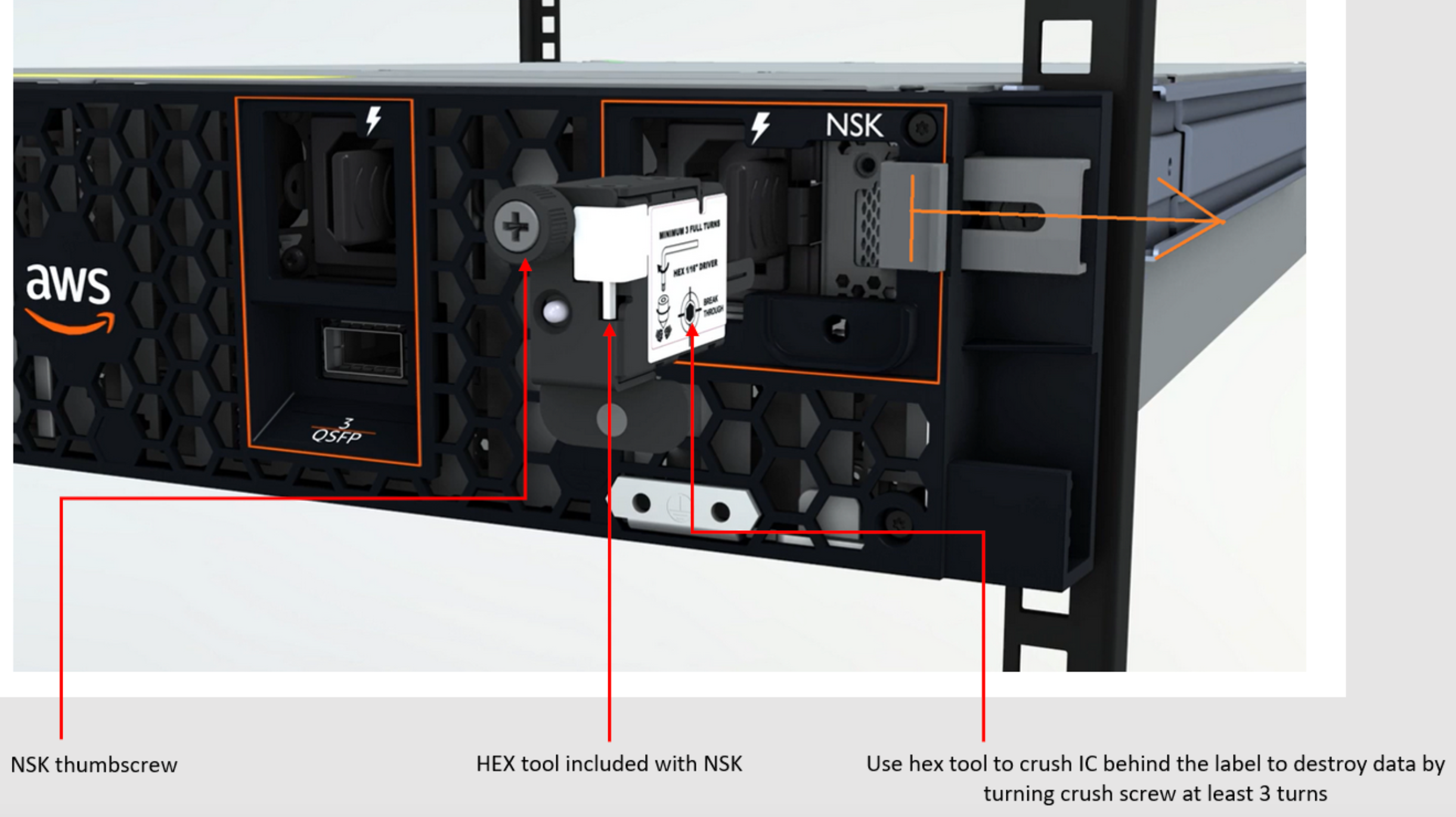
Data server rusak secara kriptografis
Kunci Keamanan Nitro (NSK) diperlukan untuk mendekripsi data di server. Ketika Anda mengembalikan server ke AWS, baik karena Anda mengganti server atau menghentikan layanan, Anda dapat menghancurkan NSK untuk secara kriptografis menghancurkan data di server.
Untuk menghancurkan data secara kriptografis di server
-
Hapus NSK dari server sebelum mengirim server kembali ke AWS.
-
Pastikan Anda memiliki NSK yang benar yang dikirimkan bersama server.
-
Lepaskan alat hex kecil/kunci pas Allen dari bawah stiker.
-
Gunakan alat hex untuk memutar sekrup kecil di bawah stiker tiga putaran penuh. Tindakan ini menghancurkan NSK dan secara kriptografis menghancurkan semua data di server.