Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esercitazione: nozioni di base su S3 Express One Zone
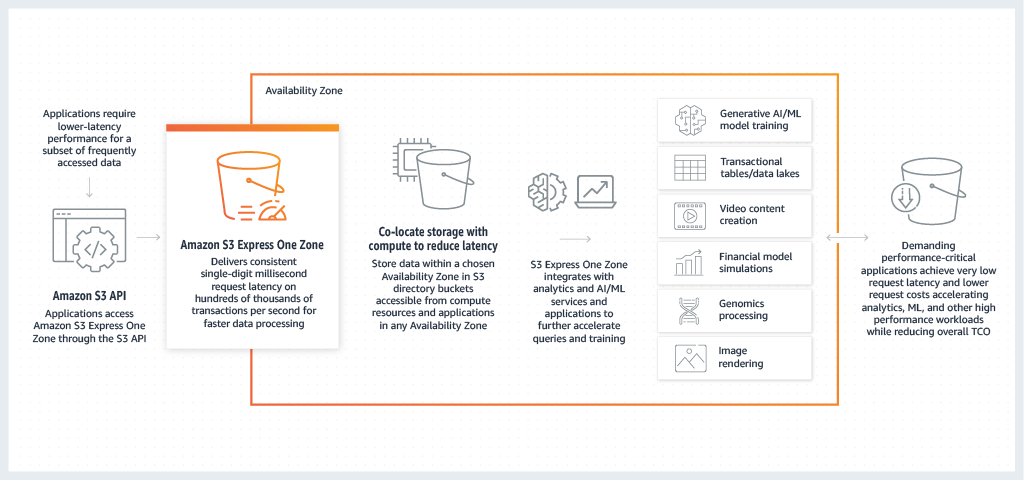
Amazon S3 Express One Zone è la prima classe di storage S3 in cui è possibile selezionare un'unica zona di disponibilità con la possibilità di co-localizzare lo storage di oggetti con le risorse di calcolo, per ottenere la massima velocità di accesso possibile. I dati in S3 Express One Zone sono archiviati in bucket di directory situati nelle zone di disponibilità. Per ulteriori informazioni sui bucket di directory, consulta Bucket di directory.
S3 Express One Zone è ideale per tutte le applicazioni in cui è fondamentale ridurre al minimo la latenza delle richieste. Tali applicazioni possono essere flussi di processo interattivi, come l'editing video, in cui i professionisti della creatività hanno bisogno di un accesso reattivo ai contenuti dalle loro interfacce utente. La soluzione S3 Express One Zone è vantaggiosa anche per i carichi di lavoro di analisi e machine learning che hanno requisiti simili di reattività dei dati, in particolare i carichi di lavoro con molti accessi minori o un gran numero di accessi casuali. S3 Express One Zone può essere utilizzato con altri AWS servizi come Amazon EMR, Amazon Athena, AWS Glue Data Catalog e SageMaker Amazon Model Training per supportare carichi di lavoro di analisi, intelligenza artificiale e apprendimento automatico (AI/ML),. Puoi lavorare con la classe di storage S3 Express One Zone e i bucket di directory utilizzando la console Amazon S3 AWS SDKs AWS , l'interfaccia a riga di comando (AWS CLI) e l'API REST di Amazon S3. Per ulteriori informazioni, consulta Che cos'è S3 Express One Zone? e In che modo S3 Express One Zone è diverso?
Obiettivo
In questa esercitazione si apprenderà come creare un endpoint gateway, creare e allegare una policy IAM, creare un bucket di directory e quindi utilizzare l'azione Importa per popolare il bucket di directory con gli oggetti attualmente memorizzati nel bucket per uso generico. In alternativa, è possibile caricare manualmente gli oggetti nel bucket della directory.
Argomenti
Passaggio 2: crea un bucket di directory S3 Express One Zone
Fase 3: Importazione di dati in un bucket di directory S3 Express One Zone
Passaggio 4: carica manualmente gli oggetti nel bucket di directory S3 Express One Zone
Passaggio 5: svuota il bucket di directory S3 Express One Zone
Passaggio 6: elimina il bucket di directory S3 Express One Zone
Prerequisiti
Prima di iniziare questo tutorial, devi disporre di un account a Account AWS cui puoi accedere come utente AWS Identity and Access Management (IAM) con le autorizzazioni corrette.
Fasi secondarie
Crea un Account AWS
Per completare questo tutorial, hai bisogno di un Account AWS. Quando ti registri AWS, il tuo Account AWS viene automaticamente registrato per tutti i servizi in AWS, incluso Amazon S3. Ti vengono addebitati solo i servizi che utilizzi. Per ulteriori informazioni sui prezzi, consulta Prezzi di S3
Creazione di un utente IAM in Account AWS (console)
AWS Identity and Access Management (IAM) è un servizio Servizio AWS che aiuta gli amministratori a controllare in modo sicuro l'accesso alle risorse. AWS Gli amministratori IAM controllano chi può essere autenticato (signed in) e autorizzato (dispone di autorizzazioni) ad accedere agli oggetti e a utilizzare i bucket della directory in S3 Express One Zone. Puoi utilizzare IAM senza alcun costo aggiuntivo.
Per impostazione predefinita, gli utenti non hanno le autorizzazioni per accedere ai bucket della directory ed eseguire operazioni S3 Express One Zone. Per concedere le autorizzazioni di accesso per i bucket di directory e le operazioni S3 Express One Zone, puoi utilizzare IAM per creare utenti o ruoli e collegare autorizzazioni a tali identità. Per ulteriori informazioni su come creare un utente IAM, consulta Creazione di utenti IAM (console) nella Guida per l'utente di IAM. Per ulteriori informazioni su come creare un ruolo IAM, consulta Creazione di un ruolo per delegare le autorizzazioni a un utente IAM nella Guida all'utente IAM.
Per semplicità, questo tutorial crea e utilizza un utente IAM. Dopo aver completato il tutorial, ricordati di Eliminazione dell'utente IAM. Per l'uso in produzione, consigliamo di seguire le best practice di sicurezza in IAM disponibili nella Guida per l'utente di IAM. Come best practice, richiedi agli utenti di utilizzare la federazione con un gestore dell'identità digitale per accedere a AWS utilizzando credenziali temporanee. Un'ulteriore suggerimento derivante dalle best practice è richiedere ai carichi di lavoro di utilizzare credenziali temporanee con ruoli IAM per l'accesso ad AWS. Per ulteriori informazioni sull'utilizzo AWS IAM Identity Center per creare utenti con credenziali temporanee, consulta la Guida introduttiva nella Guida per l'AWS IAM Identity Center utente.
avvertimento
Gli utenti IAM dispongono di credenziali a lungo termine, il che rappresenta un rischio per la sicurezza. Per ridurre questo rischio, si consiglia di fornire a questi utenti solo le autorizzazioni necessarie per eseguire l'attività e di rimuoverli quando non sono più necessari.
Creazione di una policy IAM per collegarla a un utente o a un ruolo IAM (console)
Per impostazione predefinita, gli utenti non dispongono delle autorizzazioni per i bucket di directory e le operazioni S3 Express One Zone. Per concedere le autorizzazioni di accesso per i bucket di directory, puoi utilizzare IAM per creare utenti, gruppi o ruoli e collegare le autorizzazioni a tali identità. I bucket di directory sono l'unica risorsa che è possibile includere nelle policy di bucket o nelle policy di identità IAM per l'accesso a S3 Express One Zone.
Per utilizzare le operazioni API endpoint regionali (a livello di bucket o di piano di controllo (control-plane)) con S3 Express One Zone, si utilizza il modello di autorizzazione IAM, che non prevede la gestione delle sessioni. Le autorizzazioni sono concesse per le singole azioni. Per utilizzare le operazioni API endpoint di zona (operazioni a livello di oggetto o di piano dati), si usa CreateSession per creare e gestire sessioni ottimizzate per l'autorizzazione a bassa latenza delle richieste di dati. Per recuperare e utilizzare un token di sessione, è necessario consentire l'azione s3express:CreateSession per il bucket della directory in una basata sull'identità o in una policy di bucket. Se accedi a S3 Express One Zone nella console Amazon S3, tramite AWS l'interfaccia a riga di comando (AWS CLI) o utilizzando AWS SDKs la, S3 Express One Zone crea una sessione per tuo conto. Per ulteriori informazioni, consulta CreateSession autorizzazione e AWS Identity and Access Management (IAM) per S3 Express One Zone.
Per creare una policy IAM e associarla a un utente (o ruolo) IAM
Accedi alla console di AWS gestione e apri la console di gestione IAM.
Nel riquadro di navigazione, scegli Policy.
Scegliere Create Policy (Crea policy).
Seleziona JSON.
Copia la policy sottostante nella finestra di Editor di policy. Prima di poter creare bucket di directory o utilizzare S3 Express One Zone, devi concedere le autorizzazioni necessarie al tuo ruolo o ai tuoi utenti AWS Identity and Access Management (IAM). Questa policy di esempio consente l'accesso all'operazione API
CreateSession(da utilizzare con altre operazioni API a livello di zona o di oggetto) e a tutte le operazioni API a livello di endpoint regionale (bucket). Questa policy consente l'utilizzo dell'operazione APICreateSessioncon tutti i bucket di directory, ma le operazioni API dell'endpoint regionale sono consentite solo con il bucket di directory specificato. Per utilizzare questa policy di esempio, sostituisciuser input placeholdersScegli Next (Successivo).
Rinomina la policy.
Nota
I tag dei bucket non sono supportati per S3 Express One Zone.
-
Seleziona Crea policy.
-
Ora che è stata creata una policy IAM, è possibile associarla a un utente IAM. Nel riquadro di navigazione, scegli Policy.
Nella barra di ricerca, inserisci il nome della policy.
Dal menu Azioni, seleziona Allega.
In Filtro per tipo di entità, seleziona Utenti IAM o Ruoli.
Nel campo di ricerca, digita il nome dell'utente o del ruolo da utilizzare.
Scegli Attach Policy (Collega policy).
Argomenti
Passaggi successivi
In questa esercitazione si è appreso come creare un bucket di directory e come utilizzare la classe di storage S3 Express One Zone. Dopo aver completato questa esercitazione, è possibile esplorare i servizi AWS correlati da utilizzare con la classe di storage S3 Express One Zone.
Puoi utilizzare quanto segue Servizi AWS con la classe di storage S3 Express One Zone per supportare il tuo caso d'uso specifico a bassa latenza.
-
Amazon Elastic Compute Cloud (Amazon EC2): Amazon EC2 fornisce capacità di elaborazione sicura e scalabile in. Cloud AWS L'utilizzo di Amazon EC2 riduce la necessità di investire in hardware in anticipo, in modo da poter sviluppare e distribuire applicazioni più velocemente. Puoi usare Amazon EC2 per avviare tutti o pochi server virtuali di cui hai bisogno, configurare sicurezza e rete e gestire lo storage.
-
AWS Lambda: Lambda è un servizio di calcolo che consente di eseguire il codice senza provisioning o gestire server. Si configurano le impostazioni di notifica su un bucket e si concede ad Amazon S3 l'autorizzazione a invocare una funzione in base alle policy di autorizzazione basati sulle risorse della funzione.
-
Amazon Elastic Kubernetes Service (Amazon EKS) — Amazon EKS è un servizio gestito che elimina la necessità di installare, utilizzare e mantenere Kubernetes il proprio piano di controllo. AWSKubernetes
è un sistema open source che automatizza la gestione, la scalabilità e la distribuzione di applicazioni containerizzate. -
Amazon Elastic Container Service (Amazon ECS): Amazon ECS è un servizio di orchestrazione di container completamente gestito che facilita l'implementazione, la gestione e il dimensionamento di applicazioni distribuite in container.
-
Amazon EMR: Amazon EMR è una piattaforma di cluster gestita che semplifica l'esecuzione di framework di big data, ad esempio Apache Hadoop e Apache Spark su, AWS per elaborare e analizzare grandi quantità di dati.
-
Amazon Athena: Athena è un servizio di query interattivo che semplifica l'analisi dei dati direttamente in Amazon S3 utilizzando SQL standard. È inoltre possibile utilizzare Athena per eseguire in modo interattivo l'analisi dei dati utilizzando Apache Spark senza dover pianificare, configurare o gestire le risorse. Quando si eseguono applicazioni Apache Spark su Athena, si invia il codice Spark per l'elaborazione e si ricevono direttamente i risultati.
-
AWS Glue Data Catalog: AWS Glue è un servizio di integrazione dei dati senza server che consente agli utenti di analisi di scoprire, preparare, spostare e integrare facilmente i dati provenienti da più fonti. È possibile utilizzarlo AWS Glue per l'analisi, l'apprendimento automatico e lo sviluppo di applicazioni. AWS Glue Data Catalog è un repository centralizzato che archivia i metadati sui set di dati dell'organizzazione. Funge da indice per la posizione, lo schema e le metriche di esecuzione delle origini dati.
-
Amazon SageMaker Runtime Model Training — Amazon SageMaker Runtime è un servizio di machine learning completamente gestito. Con SageMaker Runtime, data scientist e sviluppatori possono creare e addestrare modelli di machine learning in modo rapido e semplice e poi distribuirli direttamente in un ambiente ospitato pronto per la produzione.
Per ulteriori informazioni su S3 Express One Zone, consulta Che cos'è S3 Express One Zone? e In che modo S3 Express One Zone è diverso?
