Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Progettazione dello schema GraphQLLo schema GraphQL è alla base di qualsiasi implementazione del server GraphQL. Ogni API GraphQL è definita da un unico schema che contiene tipi e campi che descrivono come verranno popolati i dati delle richieste. I dati che fluiscono attraverso l'API e le operazioni eseguite devono essere convalidati rispetto allo schema.
In generale, il sistema di tipo GraphQL descrive le funzionalità di un server GraphQL e viene utilizzato per determinare se una query è valida. Il sistema di tipi di server viene spesso definito schema del server e può essere costituito da diversi tipi di oggetti, tipi scalari, tipi di input e altro ancora. GraphQL è sia dichiarativo che fortemente tipizzato, il che significa che i tipi saranno ben definiti in fase di esecuzione e restituiranno solo ciò che è stato specificato.
AWS AppSync consente di definire e configurare schemi GraphQL. La sezione seguente descrive come creare schemi GraphQL da zero utilizzando AWS AppSync i servizi di GraphQL.
Strutturazione di uno schema GraphQL
Consigliamo di rivedere la sezione Schemas prima di continuare.
GraphQL è un potente strumento per l'implementazione di servizi API. Secondo il sito Web di GraphQL, GraphQL è il seguente:
«GraphQL è un linguaggio di query APIs e un runtime per soddisfare tali richieste con i dati esistenti. GraphQL fornisce una descrizione completa e comprensibile dei dati dell'API, offre ai clienti la possibilità di chiedere esattamente ciò di cui hanno bisogno e nient'altro, facilita l'evoluzione APIs nel tempo e abilita potenti strumenti di sviluppo. »
Questa sezione tratta la primissima parte dell'implementazione GraphQL, lo schema. Utilizzando la citazione precedente, uno schema svolge il ruolo di «fornire una descrizione completa e comprensibile dei dati nell'API». In altre parole, uno schema GraphQL è una rappresentazione testuale dei dati, delle operazioni e delle relazioni tra di essi del servizio. Lo schema è considerato il punto di ingresso principale per l'implementazione del servizio GraphQL. Non sorprende che sia spesso una delle prime cose che fai nel tuo progetto. Ti consigliamo di rivedere la sezione Schemi prima di continuare.
Per citare la sezione Schemas, gli schemi GraphQL sono scritti nello Schema Definition Language (SDL). SDL è composto da tipi e campi con una struttura consolidata:
-
Tipi: I tipi sono il modo in cui GraphQL definisce la forma e il comportamento dei dati. GraphQL supporta una moltitudine di tipi che verranno spiegati più avanti in questa sezione. Ogni tipo definito nello schema conterrà il proprio ambito. All'interno dell'ambito ci saranno uno o più campi che possono contenere un valore o una logica che verrà utilizzata nel servizio GraphQL. I tipi ricoprono molti ruoli diversi, i più comuni sono gli oggetti o gli scalari (tipi di valori primitivi).
-
Campi: i campi esistono nell'ambito di un tipo e contengono il valore richiesto dal servizio GraphQL. Sono molto simili alle variabili di altri linguaggi di programmazione. La forma dei dati definiti nei campi determinerà il modo in cui i dati sono strutturati in un'operazione di richiesta/risposta. Ciò consente agli sviluppatori di prevedere cosa verrà restituito senza sapere come viene implementato il backend del servizio.
Gli schemi più semplici conterranno tre diverse categorie di dati:
-
Radici dello schema: le radici definiscono i punti di ingresso dello schema. Indica i campi che eseguiranno alcune operazioni sui dati come aggiungere, eliminare o modificare qualcosa.
-
Tipi: si tratta di tipi di base utilizzati per rappresentare la forma dei dati. Puoi quasi pensarli come oggetti o rappresentazioni astratte di qualcosa con caratteristiche definite. Ad esempio, è possibile creare un Person oggetto che rappresenti una persona in un database. Le caratteristiche di ogni persona verranno definite all'interno dei campi Person as. Possono essere qualsiasi cosa, ad esempio il nome, l'età, il lavoro, l'indirizzo della persona, ecc.
-
Tipi di oggetti speciali: questi sono i tipi che definiscono il comportamento delle operazioni nello schema. Ogni tipo di oggetto speciale viene definito una volta per schema. Vengono prima inseriti nella radice dello schema, quindi definiti nel corpo dello schema. Ogni campo di un tipo di oggetto speciale definisce una singola operazione che deve essere implementata dal resolver.
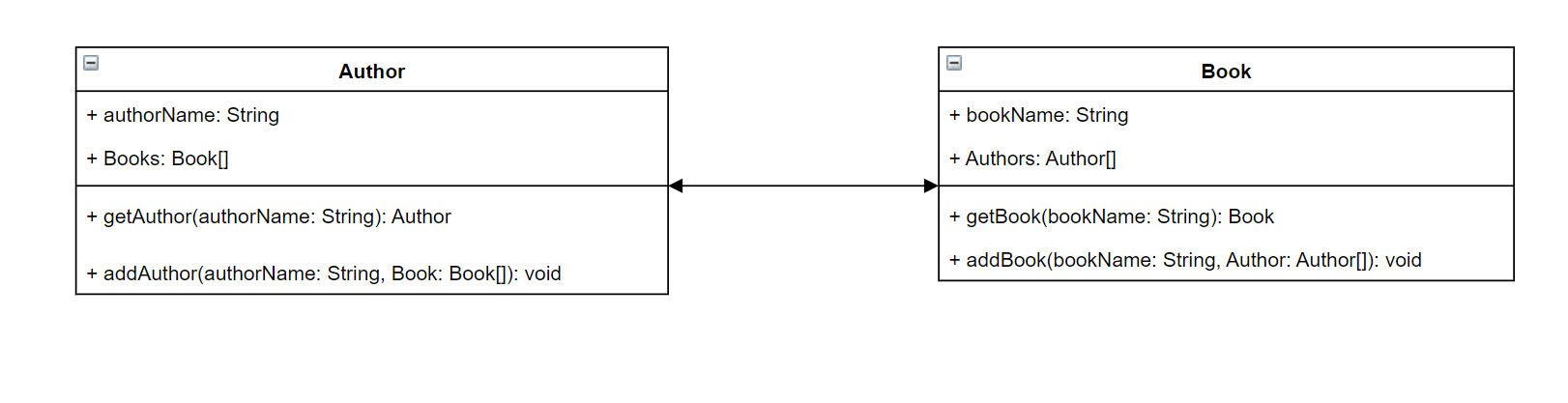
Per metterlo in prospettiva, immagina di creare un servizio che memorizza gli autori e i libri che hanno scritto. Ogni autore ha un nome e una serie di libri di cui è autore. Ogni libro ha un nome e un elenco di autori associati. Vogliamo anche avere la possibilità di aggiungere o recuperare libri e autori. Una semplice rappresentazione UML di questa relazione può avere il seguente aspetto:
In GraphQL, le entità Author e Book rappresentano due diversi tipi di oggetti nello schema:
type Author {
}
type Book {
}
Authorcontiene authorName eBooks, mentre Book contiene bookName eAuthors. Questi possono essere rappresentati come campi che rientrano nell'ambito dei tuoi tipi:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
Come potete vedere, le rappresentazioni dei tipi sono molto simili al diagramma. Tuttavia, i metodi sono quelli in cui la cosa diventa un po' più complicata. Questi verranno inseriti in uno dei pochi tipi di oggetti speciali come campo. La loro classificazione speciale degli oggetti dipende dal loro comportamento. GraphQL contiene tre tipi di oggetti speciali fondamentali: query, mutazioni e sottoscrizioni. Per ulteriori informazioni, vedete Oggetti speciali.
Poiché getAuthor getBook entrambi richiedono dati, verranno inseriti in un tipo di oggetto Query speciale:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Le operazioni sono collegate alla query, che a sua volta è collegata allo schema. L'aggiunta di una radice dello schema definirà il tipo di oggetto speciale (Queryin questo caso) come uno dei punti di ingresso. Questo può essere fatto usando la schema parola chiave:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Considerando gli ultimi due metodi, addAuthor addBook stiamo aggiungendo dati al database, quindi verranno definiti in un tipo di oggetto Mutation speciale. Tuttavia, dalla pagina Tipi, sappiamo anche che gli input che fanno riferimento direttamente agli oggetti non sono consentiti perché sono strettamente tipi di output. In questo caso, non possiamo usare Author orBook, quindi dobbiamo creare un tipo di input con gli stessi campi. In questo esempio, abbiamo aggiunto AuthorInput eBookInput, entrambi, accettano gli stessi campi dei rispettivi tipi. Quindi, creiamo la nostra mutazione usando gli input come parametri:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
Rivediamo cosa abbiamo appena fatto:
-
Abbiamo creato uno schema con i Author tipi Book e per rappresentare le nostre entità.
-
Abbiamo aggiunto i campi contenenti le caratteristiche delle nostre entità.
-
Abbiamo aggiunto una query per recuperare queste informazioni dal database.
-
Abbiamo aggiunto una mutazione per manipolare i dati nel database.
-
Abbiamo aggiunto tipi di input per sostituire i parametri dei nostri oggetti nella mutazione per rispettare le regole di GraphQL.
-
Abbiamo aggiunto la query e la mutazione al nostro schema principale in modo che l'implementazione GraphQL comprenda la posizione del tipo di radice.
Come puoi vedere, il processo di creazione di uno schema richiede molti concetti tratti dalla modellazione dei dati (in particolare dalla modellazione di database) in generale. Si può pensare che lo schema si adatti alla forma dei dati di origine. Serve anche come modello che il resolver implementerà. Nelle sezioni seguenti, imparerai come creare uno schema utilizzando vari strumenti e AWS servizi supportati.
Gli esempi nelle sezioni seguenti non sono pensati per essere eseguiti in un'applicazione reale. Servono solo a mostrare i comandi in modo da poter creare applicazioni personalizzate.
Creazione di schemi
Lo schema sarà contenuto in un file chiamatoschema.graphql. AWS AppSync consente agli utenti di creare nuovi schemi per il proprio APIs GraphQL utilizzando vari metodi. In questo esempio, creeremo un'API vuota insieme a uno schema vuoto.
- Console
-
-
Accedi a AWS Management Console e apri la AppSyncconsole.
-
Nel pannello di controllo, scegliere Create API (Crea API).
-
In Opzioni API, scegli GraphQL APIs, Progetta da zero, quindi Avanti.
-
Per il nome dell'API, modifica il nome precompilato in base alle esigenze dell'applicazione.
-
Per i dettagli di contatto, puoi inserire un punto di contatto per identificare un gestore dell'API. Questo campo è opzionale.
-
In Configurazione API privata, puoi abilitare le funzionalità dell'API privata. È possibile accedere a un'API privata solo da un endpoint VPC configurato (VPCE). Per ulteriori informazioni, consulta Privato. APIs
Non è consigliabile abilitare questa funzionalità per questo esempio. Scegli Avanti dopo aver esaminato i dati inseriti.
-
In Crea un tipo GraphQL, puoi scegliere di creare una tabella DynamoDB da utilizzare come origine dati o saltare questa operazione e farlo in un secondo momento.
Per questo esempio, scegli Create GraphQL resources in un secondo momento. Creeremo una risorsa in una sezione separata.
-
Controlla i tuoi input, quindi scegli Crea API.
-
Sarai nella dashboard della tua API specifica. Puoi capirlo perché il nome dell'API sarà nella parte superiore della dashboard. In caso contrario, puoi selezionarlo APIsnella barra laterale, quindi scegliere l'API nella APIs dashboard.
-
Nella barra laterale sotto il nome dell'API, scegli Schema.
-
Nell'editor dello schema, puoi configurare il tuo file. schema.graphql Può essere vuoto o pieno di tipi generati da un modello. Sulla destra, c'è la sezione Resolver per allegare i resolver ai campi dello schema. Non esamineremo i resolver in questa sezione.
- CLI
-
Quando utilizzi la CLI, assicurati di disporre delle autorizzazioni corrette per accedere e creare risorse nel servizio. Potresti voler impostare politiche con privilegi minimi per gli utenti non amministratori che devono accedere al servizio. Per ulteriori informazioni sulle AWS AppSync politiche, consulta Gestione delle identità e degli accessi per. AWS AppSync
Inoltre, ti consigliamo di leggere prima la versione per console se non l'hai già fatto.
-
Se non l'hai già fatto, installa la AWS
CLI, quindi aggiungi la tua configurazione.
-
Crea un oggetto API GraphQL eseguendo il create-graphql-apicomando.
Dovrai digitare due parametri per questo particolare comando:
-
La name della tua API.
-
Il o authentication-type il tipo di credenziali utilizzate per accedere all'API (IAM, OIDC, ecc.).
Altri parametri, ad esempio, Region devono essere configurati, ma di solito vengono utilizzati per impostazione predefinita i valori di configurazione CLI.
Un comando di esempio può avere il seguente aspetto:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
Un output verrà restituito nella CLI. Ecco un esempio:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
Si tratta di un comando opzionale che accetta uno schema esistente e lo carica sul AWS AppSync servizio utilizzando un blob base-64. Non utilizzeremo questo comando per questo esempio.
Esegui il comando start-schema-creation.
Dovrai digitare due parametri per questo particolare comando:
-
Provieni api-id dal passaggio precedente.
-
Lo schema definition è un blob binario codificato in base 64.
Un comando di esempio può avere il seguente aspetto:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
Verrà restituito un output:
{
"status": "PROCESSING"
}
Questo comando non restituirà l'output finale dopo l'elaborazione. È necessario utilizzare un comando separato per visualizzare il risultato. get-schema-creation-status Nota che questi due comandi sono asincroni, quindi puoi controllare lo stato dell'output anche mentre lo schema è ancora in fase di creazione.
- CDK
-
Prima di utilizzare il CDK, consigliamo di consultare la documentazione ufficiale del CDK insieme al riferimento CDK. AWS AppSync
I passaggi elencati di seguito mostreranno solo un esempio generale dello snippet utilizzato per aggiungere una particolare risorsa. Questa non è pensata per essere una soluzione funzionante nel codice di produzione. Supponiamo inoltre che tu abbia già un'app funzionante.
-
Il punto di partenza per il CDK è leggermente diverso. Idealmente, il schema.graphql file dovrebbe essere già stato creato. Devi solo creare un nuovo file con l'estensione del .graphql file. Questo può essere un file vuoto.
-
In generale, potrebbe essere necessario aggiungere la direttiva di importazione al servizio che si sta utilizzando. Ad esempio, può seguire i moduli:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
Per aggiungere un'API GraphQL, il file stack deve importare il servizio: AWS AppSync
import * as appsync from 'aws-cdk-lib/aws-appsync';
Ciò significa che stiamo importando l'intero servizio con la parola chiave. appsync Per utilizzarlo nella tua app, i tuoi AWS AppSync costrutti utilizzeranno il formato. appsync.construct_name Ad esempio, se volessimo creare un'API GraphQL, diremmo. new appsync.GraphqlApi(args_go_here) Il passaggio seguente illustra questo.
-
L'API GraphQL più semplice includerà una name per l'API e il schema percorso.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
Esaminiamo cosa fa questo frammento. Nell'ambito diapi, stiamo creando una nuova API GraphQL chiamando. appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps) L'ambito èthis, che si riferisce all'oggetto corrente. L'id èAPI_ID, che sarà il nome della risorsa dell'API GraphQL al AWS CloudFormation momento della creazione. GraphqlApiPropsContiene la name tua API GraphQL e il. schema schemaGenererà uno schema (SchemaFile.fromAsset) cercando il percorso assoluto (__dirname) per il .graphql file (schema_name.graphql). In uno scenario reale, il file di schema si troverà probabilmente all'interno dell'app CDK.
Per utilizzare le modifiche apportate alla tua API GraphQL, dovrai ridistribuire l'app.
Aggiungere tipi agli schemi
Ora che hai aggiunto lo schema, puoi iniziare ad aggiungere sia i tipi di input che quelli di output. Nota che i tipi qui non devono essere usati nel codice reale; sono solo esempi per aiutarti a comprendere il processo.
Per prima cosa, creeremo un tipo di oggetto. Nel codice reale, non è necessario iniziare con questi tipi. Puoi creare qualsiasi tipo desideri in qualsiasi momento purché segua le regole e la sintassi di GraphQL.
Nelle prossime sezioni verrà utilizzato l'editor di schemi, quindi tienilo aperto.
- Console
-
-
È possibile creare un tipo di oggetto utilizzando la type parola chiave insieme al nome del tipo:
type Type_Name_Goes_Here {}
All'interno dell'ambito del tipo, puoi aggiungere campi che rappresentano le caratteristiche dell'oggetto:
type Type_Name_Goes_Here {
# Add fields here
}
Ecco un esempio:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
In questo passaggio, abbiamo aggiunto un tipo di oggetto generico con un id campo obbligatorio memorizzato comeID, un title campo archiviato come e un date campo archiviato comeAWSDateTime. String Per visualizzare un elenco di tipi e campi e le relative funzioni, consulta Schemi. Per visualizzare un elenco di scalari e cosa fanno, consulta il riferimento Type.
- CLI
-
Ti consigliamo di leggere prima la versione per console se non l'hai già fatto.
-
È possibile creare un tipo di oggetto eseguendo il create-typecomando.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
Il format tuo input. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
In questo passaggio, abbiamo aggiunto un tipo di oggetto generico con un id campo obbligatorio memorizzato comeID, un title campo archiviato come e un date campo archiviato come. String AWSDateTime Per visualizzare un elenco di tipi e campi e le relative funzioni, consulta Schemi. Per visualizzare un elenco di scalari e cosa fanno, vedi Type reference.
Inoltre, potresti aver capito che l'immissione diretta della definizione funziona per i tipi più piccoli, ma non è possibile aggiungere tipi più grandi o multipli. Puoi scegliere di aggiungere tutto in un .graphql file e poi passarlo come input.
- CDK
-
Prima di utilizzare il CDK, consigliamo di consultare la documentazione ufficiale del CDK insieme AWS AppSync al riferimento CDK.
I passaggi elencati di seguito mostreranno solo un esempio generale dello snippet utilizzato per aggiungere una particolare risorsa. Questa non è pensata per essere una soluzione funzionante nel codice di produzione. Supponiamo inoltre che tu abbia già un'app funzionante.
Per aggiungere un tipo, devi aggiungerlo al tuo .graphql file. Ad esempio, l'esempio della console era:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Puoi aggiungere i tuoi tipi direttamente allo schema come qualsiasi altro file.
Per utilizzare le modifiche apportate alla tua API GraphQL, dovrai ridistribuire l'app.
Il tipo di oggetto ha campi di tipo scalare come stringhe e numeri interi. AWS AppSync consente inoltre di utilizzare tipi scalari avanzati, ad esempio AWSDateTime in aggiunta agli scalari GraphQL di base. Inoltre, è obbligatorio qualsiasi campo che termina con un punto esclamativo.
Il tipo ID scalare, in particolare, è un identificatore univoco che può essere uno dei due. String Int È possibile controllarli nel codice del resolver per l'assegnazione automatica.
Esistono delle somiglianze tra tipi di oggetti speciali come quelli Query «normali», come nell'esempio precedente, in quanto entrambi usano la type parola chiave e sono considerati oggetti. Tuttavia, per i tipi di oggetti speciali (Query,Mutation, andSubscription), il loro comportamento è molto diverso perché sono esposti come punti di ingresso per l'API. Si occupano anche più di modellare le operazioni piuttosto che i dati. Per ulteriori informazioni, consulta I tipi di interrogazione e mutazione.
Per quanto riguarda i tipi di oggetti speciali, il passaggio successivo potrebbe essere quello di aggiungerne uno o più per eseguire operazioni sui dati sagomati. In uno scenario reale, ogni schema GraphQL deve avere almeno un tipo di query root per la richiesta dei dati. Puoi pensare alla query come a uno dei punti di ingresso (o endpoint) del tuo server GraphQL. Aggiungiamo una query come esempio.
- Console
-
-
Per creare una query, è sufficiente aggiungerla al file di schema come qualsiasi altro tipo. Una query richiederebbe un Query tipo e una voce nella radice come segue:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
Nota che Name_of_Query in un ambiente di produzione verrà semplicemente chiamato Query nella maggior parte dei casi. Si consiglia di mantenerlo a questo valore. All'interno del tipo di query, puoi aggiungere campi. Ogni campo eseguirà un'operazione nella richiesta. Di conseguenza, la maggior parte, se non tutti, questi campi verranno allegati a un resolver. Tuttavia, questo non ci interessa in questa sezione. Per quanto riguarda il formato dell'operazione sul campo, potrebbe essere simile a questo:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
Ecco un esempio:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
In questo passaggio, abbiamo aggiunto un Query tipo e lo abbiamo definito nella schema radice. Il nostro Query tipo ha definito un getObj campo che restituisce un elenco di Obj_Type_1 oggetti. Nota che Obj_Type_1 è l'oggetto del passaggio precedente. Nel codice di produzione, le operazioni sul campo normalmente funzioneranno con dati modellati da oggetti comeObj_Type_1. Inoltre, campi come quelli getObj normalmente dispongono di un resolver per eseguire la logica aziendale. Questo sarà trattato in una sezione diversa.
Come nota aggiuntiva, aggiunge AWS AppSync automaticamente una radice dello schema durante le esportazioni, quindi tecnicamente non è necessario aggiungerla direttamente allo schema. Il nostro servizio elaborerà automaticamente gli schemi duplicati. Lo stiamo aggiungendo qui come best practice.
- CLI
-
Ti consigliamo di leggere prima la versione per console se non l'hai già fatto.
-
Crea una schema radice con una query definizione eseguendo il create-typecomando.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era:
schema {
query: Query
}
-
Il format tuo input. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Nota che se non hai inserito qualcosa correttamente nel create-type comando, puoi aggiornare la radice dello schema (o qualsiasi tipo nello schema) eseguendo il update-typecomando. In questo esempio, cambieremo temporaneamente la radice dello schema per contenere una subscription definizione.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Il tuo type-name tipo. Nell'esempio della console, questo eraschema.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era:
schema {
query: Query
}
Lo schema dopo l'aggiunta di un subscription sarà simile al seguente:
schema {
query: Query
subscription: Subscription
}
-
Il format tuo contributo. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
L'aggiunta di file preformattati continuerà a funzionare in questo esempio.
-
Crea un Query tipo eseguendo il create-typecomando.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era:
type Query {
getObj: [Obj_Type_1]
}
-
Il format tuo input. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
In questo passaggio, abbiamo aggiunto un Query tipo e lo abbiamo definito nella schema radice. Il nostro Query tipo ha definito un getObj campo che ha restituito un elenco di Obj_Type_1 oggetti.
Nel codice schema principalequery: Query, la query: parte indica che una query è stata definita nello schema, mentre la Query parte indica il nome effettivo dell'oggetto speciale.
- CDK
-
Prima di utilizzare il CDK, consigliamo di consultare la documentazione ufficiale del CDK insieme AWS AppSync al riferimento CDK.
I passaggi elencati di seguito mostreranno solo un esempio generale dello snippet utilizzato per aggiungere una particolare risorsa. Questa non è pensata per essere una soluzione funzionante nel codice di produzione. Supponiamo inoltre che tu abbia già un'app funzionante.
Dovrai aggiungere la tua query e la radice dello schema al .graphql file. Il nostro esempio assomigliava all'esempio seguente, ma ti consigliamo di sostituirlo con il codice dello schema effettivo:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Puoi aggiungere i tuoi tipi direttamente allo schema come qualsiasi altro file.
L'aggiornamento della radice dello schema è facoltativo. L'abbiamo aggiunta a questo esempio come procedura consigliata.
Per utilizzare le modifiche apportate alla tua API GraphQL, dovrai ridistribuire l'app.
Ora hai visto un esempio di creazione sia di oggetti che di oggetti speciali (query). Hai anche visto come questi possono essere interconnessi per descrivere dati e operazioni. Puoi avere schemi con solo la descrizione dei dati e una o più interrogazioni. Tuttavia, vorremmo aggiungere un'altra operazione per aggiungere dati all'origine dati. Aggiungeremo un altro tipo di oggetto speciale chiamato Mutation che modifica i dati.
- Console
-
-
Verrà chiamata una mutazione. Mutation Ad esempioQuery, le operazioni sul campo interne Mutation descriveranno un'operazione e saranno collegate a un resolver. Inoltre, nota che dobbiamo definirlo nella schema radice perché è un tipo di oggetto speciale. Ecco un esempio di mutazione:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
Una mutazione tipica verrà elencata nella radice come una query. La mutazione viene definita utilizzando la type parola chiave insieme al nome. Name_of_Mutationdi solito viene chiamatoMutation, quindi consigliamo di mantenerlo in questo modo. Ogni campo eseguirà anche un'operazione. Per quanto riguarda il formato dell'operazione sul campo, potrebbe essere simile a questo:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
Ecco un esempio:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
In questo passaggio, abbiamo aggiunto un Mutation tipo con un addObj campo. Riassumiamo cosa fa questo campo:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObjsta usando l'Obj_Type_1oggetto per eseguire un'operazione. Ciò è evidente a causa dei campi, ma la sintassi lo dimostra nel tipo : Obj_Type_1 restituito. All'internoaddObj, accetta i id date campi e e dell'Obj_Type_1oggetto come parametri. title Come puoi vedere, assomiglia molto a una dichiarazione di metodo. Tuttavia, non abbiamo ancora descritto il comportamento del nostro metodo. Come affermato in precedenza, lo schema serve solo a definire quali saranno i dati e le operazioni e non come funzioneranno. L'implementazione dell'effettiva logica aziendale avverrà più avanti, quando creeremo i nostri primi resolver.
Una volta che hai finito con lo schema, c'è un'opzione per esportarlo come file. schema.graphql Nell'editor dello schema, puoi scegliere Esporta schema per scaricare il file in un formato supportato.
Come nota aggiuntiva, aggiunge AWS AppSync automaticamente una radice dello schema durante le esportazioni, quindi tecnicamente non è necessario aggiungerla direttamente allo schema. Il nostro servizio elaborerà automaticamente gli schemi duplicati. Lo stiamo aggiungendo qui come best practice.
- CLI
-
Ti consigliamo di leggere prima la versione per console se non l'hai già fatto.
-
Aggiorna lo schema root eseguendo il update-typecomando.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Il tuo type-name tipo. Nell'esempio della console, questo eraschema.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era:
schema {
query: Query
mutation: Mutation
}
-
Il format tuo input. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
Crea un Mutation tipo eseguendo il create-typecomando.
Dovrai inserire alcuni parametri per questo particolare comando:
-
La api-id della tua API.
-
Ildefinition, o il contenuto del tuo tipo. Nell'esempio della console, questo era
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
Il format tuo input. In questo esempio, stiamo usandoSDL.
Un comando di esempio può essere simile al seguente:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
Un output verrà restituito nella CLI. Ecco un esempio:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
Dovrai aggiungere la tua query e la radice dello schema al .graphql file. Il nostro esempio assomigliava all'esempio seguente, ma ti consigliamo di sostituirlo con il codice dello schema effettivo:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
L'aggiornamento della radice dello schema è facoltativo. L'abbiamo aggiunta a questo esempio come procedura consigliata.
Per utilizzare le modifiche apportate alla tua API GraphQL, dovrai ridistribuire l'app.
Considerazioni facoltative: utilizzo delle enumerazioni come stati
A questo punto, sapete come creare uno schema di base. Tuttavia, ci sono molte cose che è possibile aggiungere per aumentare la funzionalità dello schema. Una caratteristica comune nelle applicazioni è l'uso di enumerazioni come stati. È possibile utilizzare un enum per forzare un valore specifico da un insieme di valori da scegliere quando viene chiamato. Questo è utile per cose che sai non cambieranno drasticamente per lunghi periodi di tempo. Ipoteticamente parlando, potremmo aggiungere un enum che restituisca il codice di stato o la stringa nella risposta.
Ad esempio, supponiamo di creare un'app per social media che memorizza i dati dei post di un utente nel backend. Il nostro schema contiene un Post tipo che rappresenta i dati di un singolo post:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Il nostro Post conterrà un unico id post title date di pubblicazione e un enum chiamato PostStatus che rappresenta lo stato del post così come viene elaborato dall'app. Per le nostre operazioni, avremo una query che restituisce tutti i dati dei post:
type Query {
getPosts: [Post]
}
Avremo anche una mutazione che aggiunge post alla fonte di dati:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
Guardando il nostro schema, l'PostStatusenum potrebbe avere diversi stati. Potremmo volere che i tre stati di base si chiamino success (post elaborato con successo), pending (post in fase di elaborazione) e error (post non in grado di essere elaborato). Per aggiungere l'enum, potremmo fare questo:
enum PostStatus {
success
pending
error
}
Lo schema completo potrebbe essere simile a questo:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
Se un utente aggiunge un Post nell'applicazione, l'addPostoperazione verrà chiamata per elaborare quei dati. Man mano che il resolver collegato addPost elabora i dati, li aggiornerà continuamente poststatus con lo stato dell'operazione. Quando richiesto, Post conterrà lo stato finale dei dati. Tieni presente che stiamo solo descrivendo come vogliamo che i dati funzionino nello schema. Stiamo dando molte supposizioni sull'implementazione dei nostri resolver, che implementeranno l'effettiva logica aziendale per la gestione dei dati per soddisfare la richiesta.
Considerazioni opzionali - Abbonamenti
Le sottoscrizioni in AWS AppSync vengono richiamate come risposta a una mutazione. È possibile configurare ciò con un tipo Subscription e una direttiva @aws_subscribe() nello schema, per indicare quali mutazioni richiamano una o più sottoscrizioni. Per ulteriori informazioni sulla configurazione degli abbonamenti, consulta Dati in tempo reale.
Considerazioni facoltative: relazioni e impaginazione
Supponiamo di avere un milione Posts archiviato in una tabella DynamoDB e di voler restituire alcuni di quei dati. Tuttavia, la query di esempio riportata sopra restituisce solo tutti i post. Non vorrai recuperarli tutti ogni volta che fai una richiesta. Invece, dovresti sfogliarli per pagina. Apporta le modifiche seguenti allo schema:
-
Nel getPosts campo, aggiungi due argomenti di input: nextToken (iteratore) e limit (limite di iterazione).
-
Aggiungi un nuovo PostIterator tipo contenente Posts (recupera l'elenco degli Post oggetti) e nextToken (iteratore) i campi.
-
Modifica getPosts in modo che restituisca PostIterator e non un elenco di Post oggetti.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
Il PostIterator tipo consente di restituire una parte dell'elenco di Post oggetti e nextToken di ottenere la parte successiva. All'internoPostIterator, c'è un elenco di Post elementi ([Post]) che viene restituito con un token di paginazione (nextToken). Nel AWS AppSync, questo verrebbe collegato ad Amazon DynamoDB tramite un resolver e generato automaticamente come token crittografato. Il modello converte il valore dell'argomento limit nel parametro maxResults e dell'argomento nextToken nel parametro exclusiveStartKey. Per alcuni esempi e gli esempi di modelli incorporati nella AWS AppSync console, consulta Resolver reference (). JavaScript