Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connettore MSK di Amazon Athena
Il connettore Amazon Athena per Amazon MSK
Questo connettore non utilizza Glue Connections per centralizzare le proprietà di configurazione in Glue. La configurazione della connessione viene effettuata tramite Lambda.
Prerequisiti
Implementa il connettore sul tuo Account AWS utilizzando la console Athena o AWS Serverless Application Repository. Per ulteriori informazioni, consulta Crea una connessione a una fonte di dati o Usa il AWS Serverless Application Repository per distribuire un connettore di origine dati.
Limitazioni
-
Le operazioni di scrittura DDL non sono supportate.
-
Eventuali limiti Lambda pertinenti. Per ulteriori informazioni, consulta la sezione Quote Lambda nella Guida per gli sviluppatori di AWS Lambda .
-
Nelle condizioni di filtro, è necessario impostare i tipi di dati date e timestamp sul tipo di dati appropriato.
-
I tipi di dati data e ora non sono supportati per il tipo di file CSV e vengono trattati come valori varchar.
-
La mappatura in campi JSON annidati non è supportata. Il connettore mappa solo i campi di primo livello.
-
Il connettore non supporta tipi complessi. I tipi complessi vengono interpretati come stringhe.
-
Per estrarre o lavorare con valori JSON complessi, utilizza le funzioni relative a JSON disponibili in Athena. Per ulteriori informazioni, consulta Estrarre dati JSON dalle stringhe.
-
Il connettore non supporta l'accesso ai metadati dei messaggi Kafka.
Termini
-
Gestore dei metadati: un gestore Lambda che recupera i metadati dall'istanza del database.
-
Gestore dei record: un gestore Lambda che recupera i record di dati dall'istanza del database.
-
Gestore composito: un gestore Lambda che recupera sia i metadati sia i record di dati dall'istanza del database.
-
Endpoint Kafka: una stringa di testo che stabilisce una connessione a un'istanza Kafka.
Compatibilità dei cluster
Il connettore MSK può essere utilizzato con i seguenti tipi di cluster.
-
Cluster fornito da MSK: la capacità del cluster viene specificata, monitorata e dimensionata manualmente.
-
Cluster MSK serverless: fornisce capacità on demand che si adatta automaticamente al dimensionamento degli I/O delle applicazioni.
-
Kafka standalone: una connessione diretta a Kafka (autenticata o non autenticata).
Metodi di autenticazione di supportati
Il connettore supporta i seguenti metodi di autenticazione.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
Per ulteriori informazioni, consulta Configurazione dell'autenticazione per il connettore Athena MSK.
Formati di dati di input supportati
Il connettore supporta i seguenti formati di dati di input.
-
JSON
-
CSV
Parametri
Utilizzare i parametri in questa sezione per configurare il connettore Athena MSK.
-
auth_type: specifica il tipo di autenticazione del cluster. Il connettore supporta i seguenti tipi di autenticazione:
-
NO_AUTH — Connect direttamente a Kafka senza autenticazione (ad esempio, a un cluster Kafka distribuito su un' EC2 istanza che non utilizza l'autenticazione).
-
SASL_SSL_PLAIN — Questo metodo utilizza il protocollo di sicurezza e il meccanismo SASL.
SASL_SSLPLAIN -
SASL_PLAINTEXT_PLAIN — Questo metodo utilizza il protocollo di
SASL_PLAINTEXTsicurezza e ilPLAINmeccanismo SASL.Nota
I tipi di autenticazione
SASL_SSL_PLAINeSASL_PLAINTEXT_PLAINsono supportati da Apache Kafka ma non da Amazon MSK. -
SASL_SSL_ AWS_MSK _IAM — Il controllo degli accessi IAM per Amazon MSK consente di gestire sia l'autenticazione che l'autorizzazione per il cluster MSK. AWS Le credenziali dell'utente (chiave segreta e chiave di accesso) vengono utilizzate per connettersi al cluster. Per ulteriori informazioni, consulta la pagina IAM access control (Controllo degli accessi IAM) nella Guida per gli sviluppatori di Amazon Managed Streaming per Apache Kafka.
-
SASL_SSL_SCRAM_ SHA512 — Puoi utilizzare questo tipo di autenticazione per controllare l'accesso ai tuoi cluster Amazon MSK. Questo metodo memorizza il nome utente e la password su. AWS Secrets Manager Il segreto deve essere associato al cluster Amazon MSK. Per ulteriori informazioni, consulta la pagina Setting up SASL/SCRAM authentication for an Amazon MSK cluster (Configurazione dell'autenticazione SASL/SCRAM per un cluster Amazon MSK) nella Guida per gli sviluppatori di Amazon Managed Streaming per Apache Kafka.
-
SSL: l'autenticazione SSL utilizza i file di key store e trust store per connettersi al cluster Amazon MSK. Devi generare i file del trust store e del key store, caricarli in un bucket Amazon S3 e fornire il riferimento ad Amazon S3 quando implementi il connettore. Il key store, il trust store e la chiave SSL sono archiviati in AWS Secrets Manager. Il client deve fornire la chiave AWS segreta quando il connettore viene distribuito. Per ulteriori informazioni, consulta la pagina Mutual TLS authentication (Autenticazione TLS reciproca) nella Guida per gli sviluppatori di Amazon Managed Streaming per Apache Kafka.
Per ulteriori informazioni, consulta Configurazione dell'autenticazione per il connettore Athena MSK.
-
-
certificates_s3_reference: la posizione Amazon S3 che contiene i certificati (i file key store e trust store).
-
disable_spill_encryption: (facoltativo) se impostato su
True, disabilita la crittografia dello spill. L'impostazione predefinita èFalse: in questo modo, i dati riversati su S3 vengono crittografati utilizzando AES-GCM tramite una chiave generata casualmente o una chiave generata mediante KMS. La disabilitazione della crittografia dello spill può migliorare le prestazioni, soprattutto se la posizione dello spill utilizza la crittografia lato server. -
kafka_endpoint: i dettagli dell'endpoint da fornire a Kafka. Ad esempio, per un cluster Amazon MSK, fornisci un URL di bootstrap per il cluster.
-
secrets_manager_secret: il nome del segreto AWS in cui vengono salvate le credenziali. Questo parametro non è obbligatorio per l'autenticazione IAM.
-
Parametri di spill: le funzioni Lambda archiviano temporaneamente ("riversano") i dati che non rientrano nella memoria di Amazon S3. Tutte le istanze del database a cui accede la stessa funzione Lambda riversano i dati nella stessa posizione. Utilizza i parametri nella tabella seguente per specificare la posizione di spill.
Parametro Descrizione spill_bucketObbligatorio. Il nome del bucket Amazon S3 in cui la funzione Lambda può riversare i dati. spill_prefixObbligatorio. Il prefisso all'interno del bucket di spill in cui la funzione Lambda può riversare dati. spill_put_request_headers(Facoltativo) Una mappa codificata in JSON delle intestazioni e dei valori della richiesta per la richiesta putObjectdi Amazon S3 utilizzata per lo spill (ad esempio,{"x-amz-server-side-encryption" : "AES256"}). Per altre possibili intestazioni, consulta il riferimento PutObjectall'API di Amazon Simple Storage Service.
Supporto dei tipi di dati
Nella tabella seguente vengono illustrati i tipi di dati corrispondenti supportati per Kafka e Apache Arrow.
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATE | GIORNO |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
Partizioni e suddivisioni
Gli argomenti di Kafka sono suddivisi in partizioni. Ogni partizione è ordinata. Ogni messaggio in una partizione ha un ID incrementale chiamato offset. Ogni partizione Kafka è ulteriormente suddivisa in più suddivisioni per l'elaborazione in parallelo. I dati sono disponibili per il periodo di conservazione configurato nei cluster Kafka.
Best practice
Come procedura consigliata, utilizza il pushdown del predicato quando esegui query su Athena, come negli esempi seguenti.
SELECT * FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE integercol = 2147483647
SELECT * FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'
Configurazione del connettore MSK
Prima di poter utilizzare il connettore, è necessario configurare il cluster Amazon MSK, utilizzare il registro degli schemi di AWS Glue per definire lo schema e configurare l'autenticazione per il connettore.
Nota
Se si implementa il connettore in un VPC per accedere a risorse private e si desidera connettersi anche a un servizio accessibile al pubblico come Confluent, è necessario associare il connettore a una sottorete privata con un gateway NAT. Per ulteriori informazioni, consulta Gateway NAT nella Guida per l'utente di Amazon VPC.
Quando lavori con lo AWS Glue Schema Registry, tieni presente i seguenti punti:
-
Assicurati che il testo nel campo Description (Descrizione) del registro degli schemi di AWS Glue includa la stringa
{AthenaFederationMSK}. Questa stringa di marker è obbligatoria per i AWS Glue registri che usi con il connettore Amazon Athena MSK. -
Per prestazioni ottimali, utilizza solo lettere minuscole per i nomi dei database e delle tabelle. L'utilizzo di caratteri misti tra maiuscole e minuscole fa sì che il connettore esegua una ricerca senza distinzione tra maiuscole e minuscole, più impegnativa dal punto di vista computazionale.
Per configurare l'ambiente Amazon MSK e il registro AWS Glue degli schemi
-
Configura il tuo ambiente Amazon MSK. Per ulteriori informazioni e per conoscere la procedura, consulta le sezioni Setting up Amazon MSK (Configurazione di Amazon MSK) e Getting started using Amazon MSK (Nozioni di base sull'utilizzo di Amazon MSK) nella Guida per gli sviluppatori di Amazon Managed Streaming for Apache Kafka.
-
Carica il file di descrizione dell'argomento di Kafka (ovvero il relativo schema) in formato JSON nel registro degli schemi. AWS Glue Per ulteriori informazioni, consulta Integrating with AWS Glue Schema Registry nella Developer Guide. AWS Glue Per schemi di esempio, consulta la sezione seguente.
Utilizza il formato degli esempi in questa sezione quando carichi lo schema nel registro degli schemi di AWS Glue.
Esempio di schema di tipo JSON
Nell'esempio seguente, lo schema da creare nel registro degli AWS Glue schemi viene specificato json come valore dataFormat e da utilizzare datatypejson per. topicName
Nota
Il valore di topicName deve utilizzare le stesse maiuscole e minuscole del nome dell'argomento in Kafka.
{ "topicName": "datatypejson", "message": { "dataFormat": "json", "fields": [ { "name": "intcol", "mapping": "intcol", "type": "INTEGER" }, { "name": "varcharcol", "mapping": "varcharcol", "type": "VARCHAR" }, { "name": "booleancol", "mapping": "booleancol", "type": "BOOLEAN" }, { "name": "bigintcol", "mapping": "bigintcol", "type": "BIGINT" }, { "name": "doublecol", "mapping": "doublecol", "type": "DOUBLE" }, { "name": "smallintcol", "mapping": "smallintcol", "type": "SMALLINT" }, { "name": "tinyintcol", "mapping": "tinyintcol", "type": "TINYINT" }, { "name": "datecol", "mapping": "datecol", "type": "DATE", "formatHint": "yyyy-MM-dd" }, { "name": "timestampcol", "mapping": "timestampcol", "type": "TIMESTAMP", "formatHint": "yyyy-MM-dd HH:mm:ss.SSS" } ] } }
Esempio di schema di tipo CSV
Nell'esempio seguente, lo schema da creare nel registro degli AWS Glue schemi viene specificato csv come valore dataFormat e da utilizzare datatypecsvbulk per. topicName Il valore di topicName deve utilizzare le stesse maiuscole e minuscole del nome dell'argomento in Kafka.
{ "topicName": "datatypecsvbulk", "message": { "dataFormat": "csv", "fields": [ { "name": "intcol", "type": "INTEGER", "mapping": "0" }, { "name": "varcharcol", "type": "VARCHAR", "mapping": "1" }, { "name": "booleancol", "type": "BOOLEAN", "mapping": "2" }, { "name": "bigintcol", "type": "BIGINT", "mapping": "3" }, { "name": "doublecol", "type": "DOUBLE", "mapping": "4" }, { "name": "smallintcol", "type": "SMALLINT", "mapping": "5" }, { "name": "tinyintcol", "type": "TINYINT", "mapping": "6" }, { "name": "floatcol", "type": "DOUBLE", "mapping": "7" } ] } }
Configurazione dell'autenticazione per il connettore Athena MSK
Puoi utilizzare diversi metodi per l'autenticazione al cluster Amazon MSK, tra cui IAM, SSL, SCRAM e Kafka standalone.
La tabella seguente mostra i tipi di autenticazione per il connettore, il protocollo di sicurezza e il meccanismo SASL per ciascuno di questi metodi. Per ulteriori informazioni, consulta Autenticazione e autorizzazione per Apache Kafka APIs nella Amazon Managed Streaming for Apache Kafka Developer Guide.
| auth_type | security.protocol | sasl.mechanism |
|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
SASL_SSL_AWS_MSK_IAM |
SASL_SSL |
AWS_MSK_IAM |
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
SSL |
SSL |
N/D |
Nota
I tipi di autenticazione SASL_SSL_PLAIN e SASL_PLAINTEXT_PLAIN sono supportati da Apache Kafka ma non da Amazon MSK.
SASL/IAM
Se il cluster utilizza l'autenticazione IAM, è necessario configurare la policy IAM per l'utente al momento della configurazione del cluster. Per ulteriori informazioni, consulta la pagina IAM access control (Controllo degli accessi IAM) nella Guida per gli sviluppatori di Amazon Managed Streaming per Apache Kafka.
Per utilizzare questo tipo di autenticazione, imposta la variabile di ambiente Lambda auth_type per il connettore su SASL_SSL_AWS_MSK_IAM.
SSL
Se il cluster è autenticato tramite SSL, devi generare i file del trust store e del key store e caricarli nel bucket Amazon S3. È necessario fornire questo riferimento Amazon S3 quando implementi il connettore. Il key store, il trust store e la chiave SSL sono archiviati in AWS Secrets Manager. Fornisci la chiave AWS segreta quando distribuisci il connettore.
Per informazioni sulla creazione di un segreto in Secrets Manager, consulta la pagina Crea un segreto AWS Secrets Manager.
Per utilizzare questo tipo di autenticazione, è necessario impostare le variabili di ambiente come illustrato nella tabella seguente.
| Parametro | Valore |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
La posizione di Amazon S3 contenente i certificati. |
secrets_manager_secret |
Il nome della tua chiave AWS segreta. |
Dopo avere creato un segreto in Gestione dei segreti, puoi visualizzarlo nella console Gestione dei segreti.
Visualizzazione del segreto in Gestione dei segreti
Apri la console Secrets Manager all'indirizzo https://console.aws.amazon.com/secretsmanager/
. -
Nel riquadro di navigazione, scegli Secrets (Segreti).
-
Nella pagina Secrets (Segreti), scegli il collegamento al tuo segreto.
-
Nella pagina dei dettagli del segreto, scegli Retrieve secret value (Recupera il valore di un segreto).
L'immagine seguente mostra un esempio di segreto con tre coppie chiave/valore:
keystore_password,truststore_passwordessl_key_password.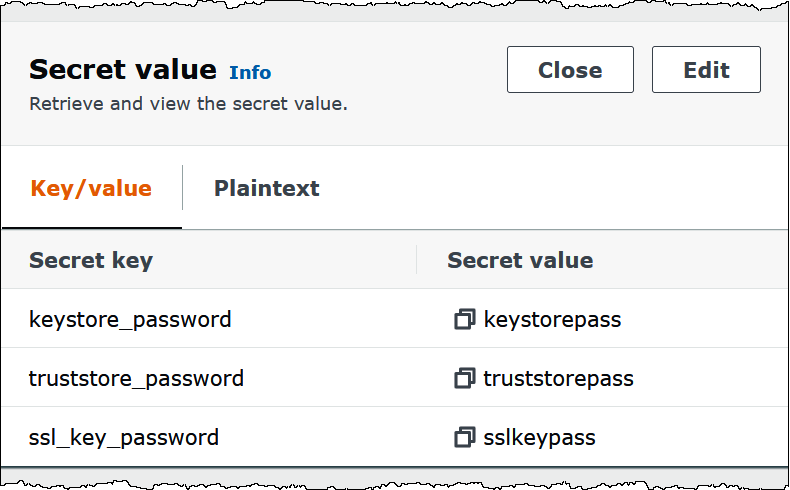
SASL/SCRAM
Se il cluster utilizza l'autenticazione SCRAM, fornisci la chiave Gestione dei segreti associata al cluster quando implementi il connettore. Le credenziali AWS dell'utente (chiave segreta e chiave di accesso) vengono utilizzate per autenticarsi al cluster.
Imposta le variabili di ambiente come illustrato nella tabella seguente.
| Parametro | Valore |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
Il nome della tua chiave AWS segreta. |
L'immagine seguente mostra un esempio di segreto nella console Gestione dei segreti con due coppie chiave/valore: una per username e una per password.

Informazioni sulla licenza
Utilizzando questo connettore, l'utente riconosce l'inclusione di componenti di terze parti, un elenco dei quali è disponibile nel file pom.xml
Risorse aggiuntive
Per ulteriori informazioni su questo connettore, visita il sito corrispondente
