Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea una pipeline di servizi ETL per caricare i dati in modo incrementale da Amazon S3 ad Amazon Redshift utilizzando AWS Glue
Rohan Jamadagni e Arunabha Datta, Amazon Web Services
Riepilogo
Questo modello fornisce indicazioni su come configurare Amazon Simple Storage Service (Amazon S3) per prestazioni ottimali del data lake e quindi caricare modifiche incrementali ai dati da Amazon S3 in Amazon Redshift utilizzando AWS Glue, eseguendo operazioni di estrazione, trasformazione e caricamento (ETL).
I file sorgente in Amazon S3 possono avere diversi formati, tra cui file con valori separati da virgole (CSV), XML e JSON. Questo modello descrive come utilizzare AWS Glue per convertire i file sorgente in un formato ottimizzato in termini di costi e prestazioni come Apache Parquet. Puoi interrogare i file Parquet direttamente da Amazon Athena e Amazon Redshift Spectrum. Puoi anche caricare file Parquet in Amazon Redshift, aggregarli e condividere i dati aggregati con i consumatori o visualizzare i dati utilizzando Amazon. QuickSight
Prerequisiti e limitazioni
Prerequisiti
Un account AWS attivo.
Un bucket sorgente S3 con i privilegi giusti e contenente file CSV, XML o JSON.
Ipotesi
I file sorgente CSV, XML o JSON sono già caricati in Amazon S3 e sono accessibili dall'account in cui sono configurati AWS Glue e Amazon Redshift.
Vengono seguite le best practice per il caricamento dei file, la suddivisione dei file, la compressione e l'utilizzo di un manifesto, come illustrato nella documentazione di Amazon Redshift.
La struttura del file di origine è inalterata.
Il sistema di origine è in grado di importare dati in Amazon S3 seguendo la struttura delle cartelle definita in Amazon S3.
Il cluster Amazon Redshift si estende su una singola zona di disponibilità. (Questa architettura è appropriata perché AWS Lambda, AWS Glue e Amazon Athena sono serverless.) Per un'elevata disponibilità, le istantanee del cluster vengono scattate con una frequenza regolare.
Limitazioni
I formati di file sono limitati a quelli attualmente supportati da AWS Glue.
Il reporting downstream in tempo reale non è supportato.
Architettura
Stack tecnologico di origine
Bucket S3 con file CSV, XML o JSON
Stack tecnologico Target
Data lake S3 (con archiviazione di file Parquet partizionata)
Amazon Redshift
Architettura Target

Flusso di dati
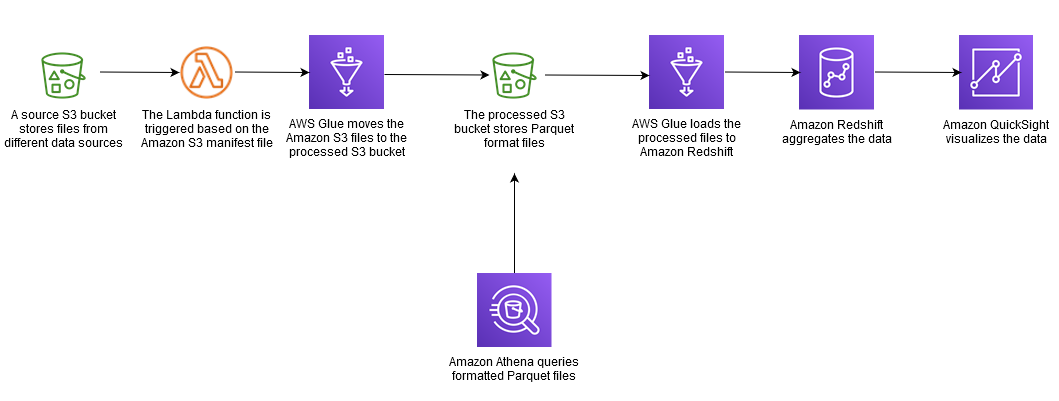
Strumenti
Amazon S3 — Amazon Simple
Storage Service (Amazon S3) è un servizio di storage di oggetti altamente scalabile. Amazon S3 può essere utilizzato per un'ampia gamma di soluzioni di storage, tra cui siti Web, applicazioni mobili, backup e data lake. AWS Lambda
: AWS Lambda consente di eseguire codice senza effettuare il provisioning o la gestione di server. AWS Lambda è un servizio basato sugli eventi; puoi configurare il codice per l'avvio automatico da altri servizi AWS. Amazon Redshift — Amazon Redshift
è un servizio di data warehouse completamente gestito su scala petabyte. Con Amazon Redshift, puoi interrogare petabyte di dati strutturati e semistrutturati nel tuo data warehouse e nel tuo data lake utilizzando SQL standard. AWS Glue
— AWS Glue è un servizio ETL completamente gestito che semplifica la preparazione e il caricamento dei dati per l'analisi. AWS Glue rileva i tuoi dati e archivia i metadati associati (ad esempio, definizioni di tabelle e schemi) nel catalogo dati di AWS Glue. I dati catalogati sono immediatamente ricercabili, possono essere interrogati e sono disponibili per ETL. AWS Secrets Manager
: AWS Secrets Manager facilita la protezione e la gestione centralizzata dei segreti necessari per l'accesso alle applicazioni o ai servizi. Il servizio archivia le credenziali del database, le chiavi API e altri segreti ed elimina la necessità di codificare le informazioni sensibili in formato testo semplice. Secrets Manager offre anche la rotazione delle chiavi per soddisfare le esigenze di sicurezza e conformità. Ha un'integrazione integrata per Amazon Redshift, Amazon Relational Database Service (Amazon RDS) e Amazon DocumentDB. È possibile archiviare e gestire centralmente i segreti utilizzando la console Secrets Manager, l'interfaccia a riga di comando (CLI) o l'API Secrets Manager e. SDKs Amazon Athena
— Amazon Athena è un servizio di query interattivo che semplifica l'analisi dei dati archiviati in Amazon S3. Athena è serverless e integrata con AWS Glue, quindi può interrogare direttamente i dati catalogati utilizzando AWS Glue. Athena è scalabile in modo elastico per offrire prestazioni di query interattive.
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Analizza i sistemi di origine per la struttura e gli attributi dei dati. | Esegui questa attività per ogni fonte di dati che contribuisce al data lake Amazon S3. | Ingegnere dei dati |
Definisci la strategia di partizione e accesso. | Questa strategia dovrebbe basarsi sulla frequenza dell'acquisizione dei dati, sull'elaborazione delta e sulle esigenze di consumo. Assicurati che i bucket S3 non siano aperti al pubblico e che l'accesso sia controllato solo da politiche specifiche basate sui ruoli di servizio. Per ulteriori informazioni, consulta la Documentazione di Amazon S3. | Ingegnere dei dati |
Crea bucket S3 separati per ogni tipo di origine dati e un bucket S3 separato per origine per i dati elaborati (Parquet). | Crea un bucket separato per ogni fonte, quindi crea una struttura di cartelle basata sulla frequenza di inserimento dei dati del sistema di origine, ad esempio. | Ingegnere dei dati |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Avvia il cluster Amazon Redshift con i gruppi di parametri e la strategia di manutenzione e backup appropriati. | Usa il segreto del database Secrets Manager per le credenziali degli utenti amministratori durante la creazione del cluster Amazon Redshift. Per informazioni sulla creazione e il dimensionamento di un cluster Amazon Redshift, consulta la documentazione di Amazon Redshift e il white paper di Sizing Cloud Data Warehouses | Ingegnere dei dati |
Crea e collega il ruolo del servizio IAM al cluster Amazon Redshift. | Il ruolo del servizio AWS Identity and Access Management (IAM) garantisce l'accesso a Secrets Manager e ai bucket S3 di origine. Per ulteriori informazioni, consulta la documentazione AWS sull'autorizzazione e l'aggiunta di un ruolo. | Ingegnere dei dati |
Crea lo schema del database. | Segui le best practice di Amazon Redshift per la progettazione di tabelle. In base al caso d'uso, scegli le chiavi di ordinamento e distribuzione appropriate e la migliore codifica di compressione possibile. Per le best practice, consulta la documentazione di AWS. | Ingegnere dei dati |
Configura la gestione del carico di lavoro. | Configura le code di gestione del carico di lavoro (WLM), l'accelerazione delle query brevi (SQA) o la scalabilità simultanea, a seconda delle tue esigenze. Per ulteriori informazioni, consulta Implementazione della gestione del carico di lavoro nella documentazione di Amazon Redshift. | Ingegnere dei dati |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un nuovo segreto per archiviare le credenziali di accesso di Amazon Redshift in Secrets Manager. | Questo segreto memorizza le credenziali per l'utente amministratore e per i singoli utenti del servizio di database. Per istruzioni, consulta la documentazione di Secrets Manager. Scegli Amazon Redshift Cluster come tipo segreto. Inoltre, nella pagina di rotazione segreta, attiva la rotazione. Questo creerà l'utente appropriato nel cluster Amazon Redshift e ruoterà i segreti chiave a intervalli definiti. | Ingegnere dei dati |
Crea una policy IAM per limitare l'accesso a Secrets Manager. | Limita l'accesso a Secrets Manager solo agli amministratori di Amazon Redshift e AWS Glue. | Ingegnere dei dati |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Nel catalogo dati di AWS Glue, aggiungi una connessione per Amazon Redshift. | Per istruzioni, consulta la documentazione di AWS Glue. | Ingegnere dei dati |
Crea e associa un ruolo di servizio IAM per AWS Glue per accedere a Secrets Manager, Amazon Redshift e bucket S3. | Per ulteriori informazioni, consulta la documentazione di AWS Glue. | Ingegnere dei dati |
Definisci il catalogo dati di AWS Glue per l'origine. | Questa fase prevede la creazione di un database e delle tabelle obbligatorie nel catalogo dati di AWS Glue. Puoi utilizzare un crawler per catalogare le tabelle nel database AWS Glue o definirle come tabelle esterne Amazon Athena. Puoi anche accedere alle tabelle esterne definite in Athena tramite AWS Glue Data Catalog. Consulta la documentazione di AWS per ulteriori informazioni sulla definizione del Data Catalog e sulla creazione di una tabella esterna in Athena. | Ingegnere dei dati |
Crea un job AWS Glue per elaborare i dati di origine. | Il job AWS Glue può essere usato come shell Python o PySpark per standardizzare, deduplicare e pulire i file dei dati di origine. Per ottimizzare le prestazioni ed evitare di dover interrogare l'intero bucket di origine S3, partiziona il bucket S3 per data, suddiviso per anno, mese, giorno e ora come predicato pushdown per il job AWS Glue. Per ulteriori informazioni, consulta la documentazione di AWS Glue. Carica i dati elaborati e trasformati nelle partizioni del bucket S3 elaborate in formato Parquet. È possibile interrogare i file Parquet da Athena. | Ingegnere dei dati |
Crea un job AWS Glue per caricare dati in Amazon Redshift. | Il job AWS Glue può essere una shell Python o PySpark caricare i dati invertendo i dati, seguito da un aggiornamento completo. Per i dettagli, consulta la documentazione di AWS Glue e la sezione Informazioni aggiuntive. | Ingegnere dei dati |
(Facoltativo) Pianifica i lavori AWS Glue utilizzando i trigger, se necessario. | Il carico di dati incrementale è principalmente guidato da un evento Amazon S3 che fa sì che una funzione AWS Lambda chiami il job AWS Glue. Utilizza la pianificazione basata su trigger di AWS Glue per tutti i carichi di dati che richiedono una pianificazione basata sul tempo anziché una pianificazione basata sugli eventi. | Ingegnere dei dati |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea e collega un ruolo collegato ai servizi IAM per AWS Lambda per accedere ai bucket S3 e al job AWS Glue. | Crea un ruolo collegato ai servizi IAM per AWS Lambda con una policy per leggere oggetti e bucket Amazon S3 e una policy per accedere all'API AWS Glue per avviare un job AWS Glue. Per ulteriori informazioni, consulta il Knowledge Center. | Ingegnere dei dati |
Crea una funzione Lambda per eseguire il job AWS Glue in base all'evento Amazon S3 definito. | La funzione Lambda deve essere avviata con la creazione del file manifest di Amazon S3. La funzione Lambda deve passare la posizione della cartella Amazon S3 (ad esempio, bucket/year/month/date/hour source_) al job AWS Glue come parametro. Il job AWS Glue utilizzerà questo parametro come predicato pushdown per ottimizzare l'accesso ai file e le prestazioni di elaborazione dei lavori. Per ulteriori informazioni, consulta la documentazione di AWS Glue. | Ingegnere dei dati |
Crea un evento oggetto Amazon S3 PUT per rilevare la creazione di oggetti e chiama la rispettiva funzione Lambda. | L'evento oggetto PUT di Amazon S3 deve essere avviato solo con la creazione del file manifest. Il file manifest controlla la funzione Lambda e la concorrenza dei job AWS Glue ed elabora il carico come batch invece di elaborare singoli file che arrivano in una partizione specifica del bucket di origine S3. Per ulteriori informazioni, consulta la documentazione di Lambda. | Ingegnere dei dati |
Risorse correlate
Informazioni aggiuntive
Approccio dettagliato per una modifica e un aggiornamento completo
Upsert: è destinato ai set di dati che richiedono l'aggregazione storica, a seconda del caso d'uso aziendale. Segui uno degli approcci descritti in Aggiornamento e inserimento di nuovi dati (documentazione di Amazon Redshift) in base alle tue esigenze aziendali.
Aggiornamento completo: questo è per piccoli set di dati che non necessitano di aggregazioni storiche. Segui uno di questi approcci:
Tronca la tabella Amazon Redshift.
Carica la partizione corrente dall'area di staging
oppure:
Crea una tabella temporanea con i dati della partizione corrente.
Elimina la tabella Amazon Redshift di destinazione.
Rinomina la tabella temporanea nella tabella di destinazione.
