Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Visualizza i risultati AI/ML del modello utilizzando Flask e AWS Elastic Beanstalk
Chris Caudill e Durga Sury, Amazon Web Services
Riepilogo
La visualizzazione dei risultati dei servizi di intelligenza artificiale e machine learning (AI/ML) spesso richiede chiamate API complesse che devono essere personalizzate dai tuoi sviluppatori e ingegneri. Questo può essere uno svantaggio se gli analisti vogliono esplorare rapidamente un nuovo set di dati.
È possibile migliorare l'accessibilità dei servizi e fornire una forma più interattiva di analisi dei dati utilizzando un'interfaccia utente (UI) basata sul Web che consente agli utenti di caricare i propri dati e visualizzare i risultati del modello in una dashboard.
Questo modello utilizza Flask
Prerequisiti e limitazioni
Prerequisiti
Un account AWS attivo.
AWS Command Line Interface (AWS CLI), installata e configurata sul computer locale. Per ulteriori informazioni su questo argomento, consulta le nozioni di base sulla configurazione nella documentazione dell'interfaccia a riga di comando di AWS. Puoi anche utilizzare un ambiente di sviluppo integrato (IDE) AWS Cloud9; per ulteriori informazioni su questo argomento, consulta il tutorial di Python per AWS Cloud9 e l'anteprima delle applicazioni in esecuzione nell'IDE AWS Cloud9 nella documentazione di AWS Cloud9.
Avviso: non è più disponibile per i nuovi clienti. AWS Cloud9 I clienti esistenti di AWS Cloud9 possono continuare a utilizzare il servizio normalmente. Ulteriori informazioni
Comprensione del framework di applicazioni web di Flask. Per ulteriori informazioni su Flask, consulta il Quickstart
nella documentazione di Flask. Python versione 3.6 o successiva, installato e configurato. Puoi installare Python seguendo le istruzioni contenute in Configurazione dell'ambiente di sviluppo Python nella documentazione di AWS Elastic Beanstalk.
Elastic Beanstalk Command Line Interface (EB CLI), installata e configurata. Per ulteriori informazioni su questo argomento, consulta Installare l'EB CLI e Configurare l'EB CLI dalla documentazione di AWS Elastic Beanstalk.
Limitazioni
L'applicazione Flask di questo pattern è progettata per funzionare con file.csv che utilizzano una singola colonna di testo e sono limitati a 200 righe. Il codice dell'applicazione può essere adattato per gestire altri tipi di file e volumi di dati.
L'applicazione non considera la conservazione dei dati e continua ad aggregare i file utente caricati fino a quando non vengono eliminati manualmente. Puoi integrare l'applicazione con Amazon Simple Storage Service (Amazon S3) per lo storage persistente di oggetti o utilizzare un database come Amazon DynamoDB per lo storage di chiave-valore senza server.
L'applicazione prende in considerazione solo i documenti in lingua inglese. Tuttavia, puoi utilizzare Amazon Comprehend per rilevare la lingua principale di un documento. Per ulteriori informazioni sulle lingue supportate per ogni azione, consulta il riferimento all'API nella documentazione di Amazon Comprehend.
Un elenco di risoluzione dei problemi che contiene gli errori più comuni e le relative soluzioni è disponibile nella sezione Informazioni aggiuntive.
Architettura
Architettura dell'applicazione Flask
Flask è un framework leggero per lo sviluppo di applicazioni web in Python. È progettato per combinare la potente elaborazione dei dati di Python con una ricca interfaccia utente web. L'applicazione Flask del pattern mostra come creare un'applicazione Web che consenta agli utenti di caricare dati, inviarli ad Amazon Comprehend per l'inferenza e quindi visualizzare i risultati. L'applicazione ha la seguente struttura:
static— Contiene tutti i file statici che supportano l'interfaccia utente Web (ad esempio JavaScript, CSS e immagini)templates— Contiene tutte le pagine HTML dell'applicazioneuserData— Memorizza i dati utente caricatiapplication.py— Il file dell'applicazione Flaskcomprehend_helper.py— Funzioni per effettuare chiamate API verso Amazon Comprehendconfig.py— Il file di configurazione dell'applicazionerequirements.txt— Le dipendenze Python richieste dall'applicazione
Lo application.py script contiene le funzionalità principali dell'applicazione Web, che consiste in quattro percorsi Flask. Il diagramma seguente mostra questi percorsi Flask.

/è la radice dell'applicazione e indirizza gli utenti allaupload.htmlpagina (memorizzata nellatemplatesdirectory)./saveFileè una route che viene richiamata dopo che un utente carica un file. Questo percorso riceve unaPOSTrichiesta tramite un modulo HTML, che contiene il file caricato dall'utente. Il file viene salvato nellauserDatadirectory e il percorso reindirizza gli utenti al/dashboardpercorso./dashboardinvia gli utenti alla pagina.dashboard.htmlAll'interno del codice HTML di questa pagina, esegue il JavaScript codicestatic/js/core.jsche legge i dati dal/datapercorso e quindi crea visualizzazioni per la pagina./dataè un'API JSON che presenta i dati da visualizzare nella dashboard. Questo percorso legge i dati forniti dall'utente e utilizza le funzionicomprehend_helper.pyper inviare i dati utente ad Amazon Comprehend per l'analisi del sentiment e il riconoscimento delle entità nominate (NER). La risposta di Amazon Comprehend viene formattata e restituita come oggetto JSON.
Architettura di distribuzione
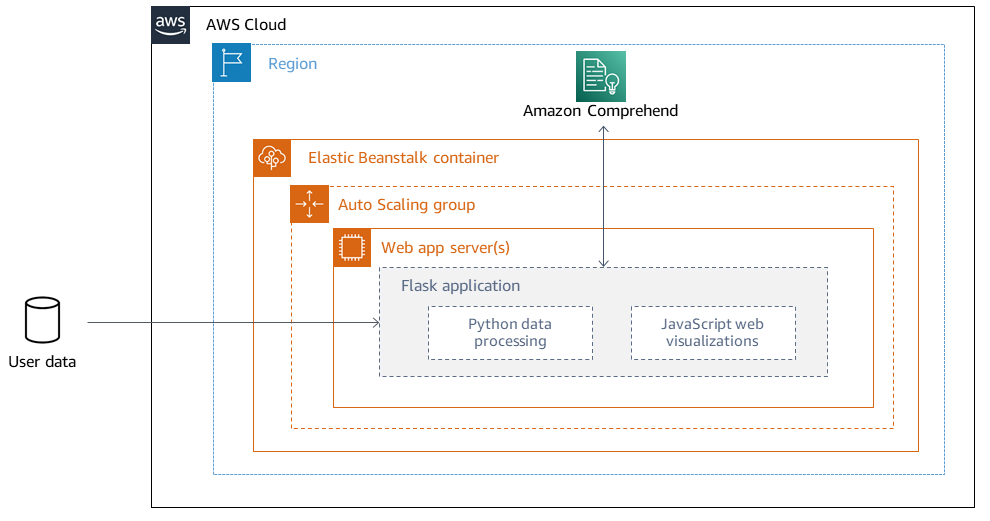
Considerazioni di progettazione
Per ulteriori informazioni sulle considerazioni di progettazione per le applicazioni distribuite utilizzando Elastic Beanstalk sul cloud AWS, consulta la documentazione di AWS Elastic Beanstalk.
Stack tecnologico
Amazon Comprehend
Elastic Beanstalk
Flask
Automazione e scalabilità
Le implementazioni di Elastic Beanstalk vengono configurate automaticamente con sistemi di bilanciamento del carico e gruppi di auto scaling. Per ulteriori opzioni di configurazione, consulta Configurazione degli ambienti Elastic Beanstalk nella documentazione di AWS Elastic Beanstalk.
Strumenti
AWS Command Line Interface (AWS CLI) è uno strumento unificato che fornisce un'interfaccia coerente per interagire con tutte le parti di AWS.
Amazon Comprehend utilizza l'elaborazione del linguaggio naturale (NLP) per estrarre informazioni dettagliate sul contenuto dei documenti senza richiedere una preelaborazione speciale.
AWS Elastic Beanstalk ti aiuta a distribuire e gestire rapidamente le applicazioni nel cloud AWS senza dover conoscere l'infrastruttura che esegue tali applicazioni.
Elastic Beanstalk CLI (EB CLI) è un'interfaccia a riga di comando per AWS Elastic Beanstalk che fornisce comandi interattivi per semplificare la creazione, l'aggiornamento e il monitoraggio di ambienti da un repository locale.
Il framework Flask
esegue l'elaborazione dei dati e le chiamate API utilizzando Python e offre una visualizzazione web interattiva con Plotly.
Codice
Il codice per questo modello è disponibile nei risultati del AI/ML modello GitHub Visualize utilizzando Flask e il repository AWS Elastic Beanstalk
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Clona il GitHub repository. | Estrai il codice dell'applicazione dai risultati del AI/ML modello GitHub Visualize utilizzando Flask e il repository AWS Elastic Beanstalk eseguendo il seguente comando
NotaAssicurati di configurare le tue chiavi SSH con. GitHub | Developer |
Installa i moduli Python. | Dopo aver clonato il repository, viene creata una nuova
| Sviluppatore Python |
Prova l'applicazione localmente. | Avvia il server Flask eseguendo il seguente comando:
Ciò restituisce informazioni sul server in esecuzione. Dovresti essere in grado di accedere all'applicazione aprendo un browser e visitando http://localhost:5000 NotaSe esegui l'applicazione in un IDE AWS Cloud9, devi sostituire
È necessario annullare questa modifica prima della distribuzione. | Sviluppatore Python |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Avvia l'applicazione Elastic Beanstalk. | Per avviare il progetto come applicazione Elastic Beanstalk, esegui il seguente comando dalla directory principale dell'applicazione:
Importante
Esegui il | Architetto, sviluppatore |
Implementa l'ambiente Elastic Beanstalk. | Esegui il comando seguente dalla directory principale dell'applicazione:
Nota
| Architetto, sviluppatore |
Autorizza la tua distribuzione all'uso di Amazon Comprehend. | Sebbene la tua applicazione possa essere stata distribuita correttamente, dovresti anche fornire alla distribuzione l'accesso ad Amazon Comprehend. Allega la
Importante
| Sviluppatore, architetto della sicurezza |
Visita la tua applicazione distribuita. | Dopo che l'applicazione è stata distribuita correttamente, puoi visitarla eseguendo il Puoi anche eseguire il | Architetto, sviluppatore |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Autorizza Elastic Beanstalk ad accedere al nuovo modello. | Assicurati che Elastic Beanstalk disponga delle autorizzazioni di accesso necessarie per il tuo nuovo endpoint modello. Ad esempio, se utilizzi un SageMaker endpoint Amazon, la tua distribuzione deve disporre dell'autorizzazione per richiamare l'endpoint. Per ulteriori informazioni a riguardo, InvokeEndpointconsulta la SageMaker documentazione di Amazon. | Sviluppatore, architetto della sicurezza |
Invia i dati dell'utente a un nuovo modello. | Per modificare il modello ML sottostante in questa applicazione, è necessario modificare i seguenti file:
| Data scientist |
Aggiorna le visualizzazioni del pannello di controllo. | In genere, incorporare un nuovo modello ML significa che le visualizzazioni devono essere aggiornate per riflettere i nuovi risultati. Queste modifiche vengono apportate nei seguenti file:
| Sviluppatore web |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Aggiorna il file dei requisiti dell'applicazione. | Prima di inviare modifiche a Elastic Beanstalk,
| Sviluppatore Python |
Ridistribuisci l'ambiente Elastic Beanstalk. | Per assicurarti che le modifiche all'applicazione si riflettano nella distribuzione di Elastic Beanstalk, vai alla directory principale dell'applicazione ed esegui il comando seguente:
Questo invia la versione più recente del codice dell'applicazione alla distribuzione esistente di Elastic Beanstalk. | Amministratore di sistema, Architetto |
Risorse correlate
Informazioni aggiuntive
Elenco di risoluzione dei problemi
Di seguito sono riportati sei errori comuni e le relative soluzioni.
Errore 1
Unable to assume role "arn:aws:iam::xxxxxxxxxx:role/aws-elasticbeanstalk-ec2-role". Verify that the role exists and is configured correctly.
Soluzione: se questo errore si verifica durante l'esecuzioneeb create, crea un'applicazione di esempio sulla console Elastic Beanstalk per creare il profilo di istanza predefinito. Per ulteriori informazioni su questo argomento, consulta Creazione di un ambiente Elastic Beanstalk nella documentazione di AWS Elastic Beanstalk.
Errore 2
Your WSGIPath refers to a file that does not exist.
Soluzione: questo errore si verifica nei registri di distribuzione perché Elastic Beanstalk prevede che il codice Flask venga denominato. application.py Se hai scelto un nome diverso, eseguilo eb config e modificalo WSGIPath come mostrato nel seguente esempio di codice:
aws:elasticbeanstalk:container:python: NumProcesses: '1' NumThreads: '15' StaticFiles: /static/=static/ WSGIPath: application.py
Assicurati di sostituirlo application.py con il nome del file.
Puoi anche sfruttare Gunicorn e un Procfile. Per ulteriori informazioni su questo approccio, consulta Configurazione del server WSGI con un Procfile nella documentazione di AWS Elastic Beanstalk.
Errore 3
Target WSGI script '/opt/python/current/app/application.py' does not contain WSGI application 'application'.
Soluzione: Elastic Beanstalk si aspetta che la variabile che rappresenta l'applicazione Flask venga denominata. application Assicurati che il application.py file utilizzi application come nome della variabile:
application = Flask(__name__)
Errore 4
The EB CLI cannot find your SSH key file for keyname
Soluzione: utilizza l'EB CLI per specificare quale coppia di chiavi utilizzare o per creare una coppia di chiavi per le istanze della EC2 distribuzione. Per risolvere l'errore, esegui eb init -i e una delle opzioni chiederà:
Do you want to set up SSH for your instances?
YRispondi con per creare una coppia di chiavi o specificare una coppia di chiavi esistente.
Errore 5
Ho aggiornato il codice e l'ho ridistribuito, ma la mia distribuzione non riflette le mie modifiche.
Soluzione: se utilizzi un repository Git con la tua distribuzione, assicurati di aggiungere e confermare le modifiche prima di ridistribuirle.
Errore 6
Stai visualizzando l'anteprima dell'applicazione Flask da un IDE AWS Cloud9 e riscontri degli errori.
Soluzione: per ulteriori informazioni su questo argomento, consulta Anteprima delle applicazioni in esecuzione nell'IDE AWS Cloud9 nella documentazione di AWS Cloud9.
Elaborazione del linguaggio naturale con Amazon Comprehend
Scegliendo di utilizzare Amazon Comprehend, puoi rilevare entità personalizzate in singoli documenti di testo eseguendo analisi in tempo reale o processi batch asincroni. Amazon Comprehend consente inoltre di addestrare modelli personalizzati di riconoscimento delle entità e classificazione del testo che possono essere utilizzati in tempo reale creando un endpoint.
Questo modello utilizza processi batch asincroni per rilevare sentimenti ed entità da un file di input che contiene più documenti. L'applicazione di esempio fornita da questo modello è progettata per consentire agli utenti di caricare un file.csv contenente una singola colonna con un documento di testo per riga. Il comprehend_helper.py file nei risultati del AI/ML modello GitHub Visualize utilizzando Flask e il repository AWS Elastic Beanstalk legge il file di input e invia l'input ad Amazon
BatchDetectEntities
Amazon Comprehend esamina il testo di un batch di documenti alla ricerca di entità denominate e restituisce l'entità, l'ubicazione, il tipo di entità rilevati e un punteggio che indica il livello di fiducia di Amazon Comprehend. È possibile inviare un massimo di 25 documenti in una chiamata API, con ogni documento di dimensioni inferiori a 5.000 byte. Puoi filtrare i risultati per mostrare solo determinate entità in base al caso d'uso. Ad esempio, è possibile ignorare il tipo di ‘quantity’ entità e impostare un punteggio di soglia per l'entità rilevata (ad esempio, 0,75). Ti consigliamo di esaminare i risultati per il tuo caso d'uso specifico prima di scegliere un valore di soglia. Per ulteriori informazioni su questo argomento, consulta la BatchDetectEntitiesdocumentazione di Amazon Comprehend.
BatchDetectSentiment
Amazon Comprehend ispeziona un batch di documenti in entrata e restituisce il sentimento prevalente per ogni documento (,, o). POSITIVE NEUTRAL MIXED NEGATIVE È possibile inviare un massimo di 25 documenti in una chiamata API, con ogni documento di dimensioni inferiori a 5.000 byte. L'analisi del sentimento è semplice e puoi scegliere il sentimento con il punteggio più alto da visualizzare nei risultati finali. Per ulteriori informazioni su questo argomento, consulta la BatchDetectSentimentdocumentazione di Amazon Comprehend.
Gestione della configurazione di Flask
I server Flask utilizzano una serie di variabili di configurazione
In questo modello, la configurazione è definita config.py ed ereditata all'internoapplication.py.
Nota
config.pycontiene le variabili di configurazione impostate all'avvio dell'applicazione. In questa applicazione, viene definita unaDEBUGvariabile per indicare all'applicazione di eseguire il server in modalità di debug. : la modalità di debug non deve essere utilizzata quando si esegue un'applicazione in un ambiente di produzione. UPLOAD_FOLDERè una variabile personalizzata definita per essere referenziata più avanti nell'applicazione e che indica dove devono essere archiviati i dati utente caricati.application.pyavvia l'applicazione Flask ed eredita le impostazioni di configurazione definite in.config.pyCiò viene eseguito dal seguente codice:
application = Flask(__name__) application.config.from_pyfile('config.py')
