翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
GraphQL スキーマの設計GraphQL スキーマは、あらゆる GraphQL サーバー実装の基盤です。各 GraphQL API は、リクエストからのデータがどのように入力されるかを記述するタイプとフィールドを含む単一のスキーマによって定義されます。API を経由するデータフローと実行される操作は、スキーマと照合して検証する必要があります。
GraphQL タイプシステムは、GraphQL サーバーの機能を記述し、クエリが有効であることを判別するために使用されます。サーバーのタイプシステムはしばしばそのサーバーのスキーマと呼ばれ、さまざまなオブジェクトタイプ、スカラー型、入力型などで構成されます。GraphQL は宣言型であると同時に厳密に型付けされています。つまり、型はランタイムに明確に定義され、指定されたものだけを返します。
AWS AppSync では、GraphQL スキーマを定義および設定できます。次のセクションでは、 AWS AppSyncのサービスを使用して GraphQL スキーマを最初から作成する方法について説明します。
GraphQL スキーマの構造化
続ける前に「スキーマ」セクションを確認することをおすすめします。
GraphQL は API サービスを実装するための強力なツールです。GraphQL のウェブサイトによると、GraphQL は以下の通りです。
「GraphQL は API 用のクエリ言語であり、既存のデータでそれらのクエリを実行するためのランタイムです。GraphQL は、API 内のデータを完全かつわかりやすく説明し、クライアントが必要としているものだけを尋ねることができるようにし、時間の経過とともに API を進化させやすくし、強力な開発者ツールを可能にします」
このセクションでは、GraphQL 実装の最初の部分であるスキーマについて説明します。上の引用を使用すると、スキーマは「API 内のデータを完全かつわかりやすく説明する」役割を果たします。言い換えると、GraphQL スキーマは、サービスのデータ、操作、およびそれらの間の関係をテキストで表現したものです。スキーマは、GraphQL サービス実装の主要なエントリポイントと見なされます。当然のことながら、多くの場合、プロジェクトで最初に作成するものの 1 つです。次に進む前に「スキーマ」セクションを確認することをおすすめします。
「スキーマ」セクションを引用すると、GraphQL スキーマはスキーマ定義言語 (SDL) で記述されています。SDL は、構造が確立された型とフィールドで構成されています。
-
タイプ: タイプとは、GraphQL がデータの形状と動作を定義する方法です。GraphQL は、このセクションの後半で説明する多数の型をサポートしています。スキーマで定義されている各タイプには、独自のスコープが含まれます。スコープ内には、GraphQL サービスで使用される値またはロジックを含むことができる 1 つ以上のフィールドがあります。型にはさまざまな役割がありますが、最も一般的なのはオブジェクトまたはスカラー (プリミティブ値型) です。
-
フィールド: フィールドはタイプのスコープ内に存在し、GraphQL サービスから要求された値を保持します。これらは他のプログラミング言語の変数とよく似ています。フィールドで定義するデータの形状によって、リクエスト/レスポンス操作におけるデータの構造が決まります。これにより、開発者はサービスのバックエンドがどのように実装されているかを知らなくても、何が返されるかを予測できます。
最も単純なスキーマには、次の 3 つの異なるデータカテゴリが含まれます。
-
スキーマルート: ルートはスキーマのエントリポイントを定義します。データの追加、削除、変更などの操作を行うフィールドを指します。
-
タイプ: これらはデータの形状を表すために使用される基本タイプです。これらは概して、定義された特性を持つ何かのオブジェクト、または抽象的な表現と考えることができます。例えば、データベース内の人を表す Person オブジェクトを作成できます。各個人の特性はフィールド Person として内部で定義されます。名前、年齢、職業、住所など何でも構いません。
-
特殊オブジェクトタイプ: スキーマ内の操作の動作を定義するタイプです。特殊オブジェクトタイプはそれぞれ、スキーマごとに 1 回定義されます。これらは最初にスキーマのルートに配置され、次にスキーマ本体で定義されます。特別なオブジェクトタイプの各フィールドは、リゾルバーによって実装される単一の操作を定義します。
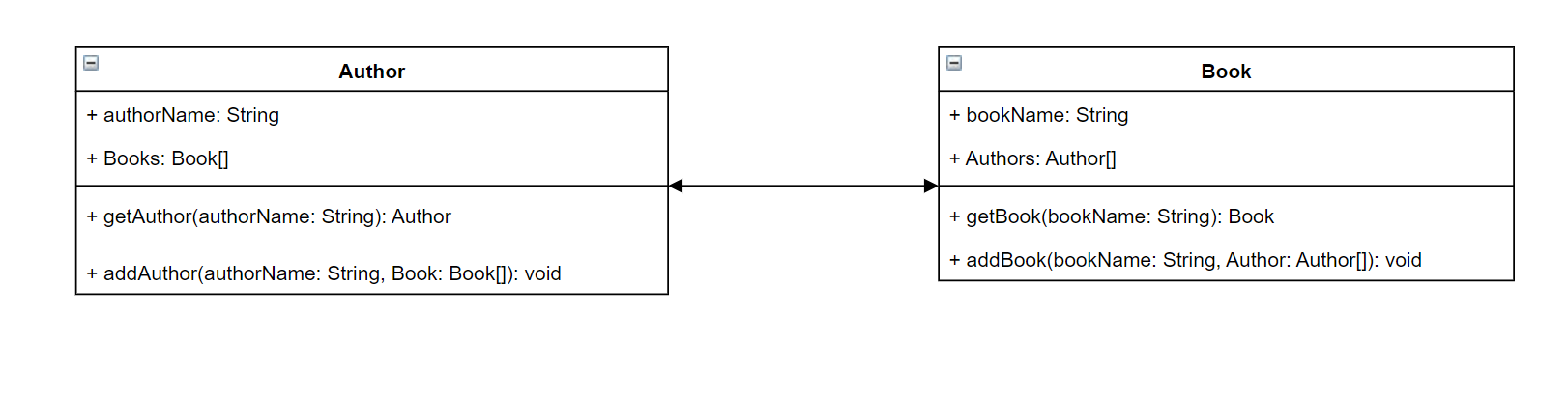
これを大局的に見ると、著者とその著者が書いた本を保存するサービスを作成していると想像してみてください。各著者には名前と執筆した本の配列があります。各本には名前と関連する著者のリストがあります。また、本や著者を追加したり、検索したりできる機能も必要です。この関係を単純な UML 表現で表現すると、次のようになります。
GraphQL では、Author および Book エンティティとはスキーマ内の 2 つの異なるオブジェクトタイプを表します。
type Author {
}
type Book {
}
Author には authorName と Books が含まれ、Book には bookName とAuthors が含まれます。これらはタイプのスコープ内のフィールドとして表すことができます。
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
ご覧のとおり、型表現は図と非常に似ています。しかし、メソッドは少し難しいところです。これらは、いくつかの特殊なオブジェクトタイプのいずれかにフィールドとして配置されます。特殊なオブジェクト分類は、その動作によって異なります。GraphQL には、クエリ、ミューテーション、およびサブスクリプションの 3 つの基本的な特殊オブジェクトタイプがあります。特別なオブジェクトの詳細については、 を参照してください。
getAuthorとgetBookはどちらもデータを要求しているため、Query の特別なオブジェクトタイプに配置されます。
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
オペレーションはクエリにリンクされ、クエリ自体もスキーマにリンクされます。スキーマルートを追加すると、特別なオブジェクトタイプ (この場合は Query) がエントリポイントの 1 つとして定義されます。これは schema キーワードを使用して行うことがDけいます。
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
最後の 2 つの方法を見てみると、addAuthor と addBook はデータベースにデータを追加しているので、これらはMutation の特別なオブジェクトタイプで定義されます。ただし、タイプページを見ると、オブジェクトを直接参照する入力は厳密には出力タイプなので、許可されていないこともわかります。この場合、Author または Book は使用できないため、同じフィールドを持つ入力タイプを作成する必要があります。この例では、AuthorInput と BookInput を追加しましたが、どちらもそれぞれのタイプの同じフィールドを受け入れます。次に、入力をパラメータとして使用してミューテーションを作成します。
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
先ほど行ったことを振り返ってみましょう。
-
エンティティを表すための Book および Author タイプを含むスキーマを作成しました。
-
エンティティの特徴を含むフィールドを追加しました。
-
この情報をデータベースから取得するクエリを追加しました。
-
データベース内のデータを操作するミューテーションを追加しました。
-
GraphQL のルールに準拠するため、ミューテーション内のオブジェクトパラメータを置き換える入力タイプを追加しました。
-
GraphQL 実装がルートタイプの場所を理解できるように、クエリとミューテーションをルートスキーマに追加しました。
ご覧のとおり、スキーマを作成するプロセスには、一般的なデータモデリング (特にデータベースモデリング) から多くの概念が取り入れられています。スキーマはソースからのデータの形に合っていると考えることができます。リゾルバーが実装するモデルとしても機能します。以下のセクションでは、さまざまな AWSバックアップツールとサービスを使用してスキーマを作成する方法について説明します。
以下のセクションの例は、実際のアプリケーションで実行するためのものではありません。これらの説明は、ユーザーが独自のアプリケーションを構築できるようにコマンドを紹介することのみを目的としています。
スキーマの作成
スキーマは というファイルにありますschema.graphql。 AWS AppSync を使用すると、ユーザーはさまざまな方法を使用して GraphQL APIs の新しいスキーマを作成できます。この例では、空の API と空白のスキーマを作成します。
- Console
-
-
にサインイン AWS マネジメントコンソール し、AppSync コンソールを開きます。
-
ダッシュボードで、[API の作成] を選択します。
-
[API オプション] で、[GraphQL API]、[最初から設計]、[次へ] の順に選択します。
-
API 名では、あらかじめ入力されている名前をアプリケーションに必要な名前に変更します。
-
連絡先情報については、API のマネージャーを特定する連絡先を入力できます。これはオプションのフィールドです。
-
[Private API 設定] で、プライベート API 機能を有効にできます。プライベート API には、設定された VPC エンドポイント (VPCE) からのみアクセスできます。詳細については、「プライベート DNS」を参照してください。
この例では、この機能を有効にすることはお勧めしません。[次へ] 選択して入力を確認します。
-
[GraphQL タイプを作成] では、データソースとして使用する DynamoDB テーブルを作成するか、この作業をスキップして後で作成するかを選択できます。
この例では、[GraphQL リソースを後で作成] を選択します。リソースは別のセクションで作成します。
-
入力内容を確認し、[API を作成] を選択します。
-
特定の API のダッシュボードが表示されます。API の名前がダッシュボードの上部にあるのでわかります。そうでない場合は、サイドバーで [API] を選択し、API ダッシュボードで API を選択できます。
-
API 名の下のサイドバーで、[スキーマ] を選択します。
-
スキーマエディタでは、ファイルを設定できます。schema.graphqlファイルは空でも、モデルから生成されたタイプで埋め込まれていてもかまいません。右側には、リゾルバーをスキーマフィールドにアタッチするための [リゾルバー] セクションがあります。このセクションではリゾルバーについては説明しません。
- CLI
-
-
まだをインストールしてしていない場合は、 AWS
CLI をインストールして設定します。
-
create-graphql-apiコマンドを実行して GraphQL API オブジェクトを作成します。
この特定のコマンドには、次の 2 つのパラメータを入力する必要があります。
-
API の name です。
-
authentication-type、または API へのアクセスに使用される認証情報の種類 (IAM、OIDC など)。
Region など、その他のパラメータは設定する必要がありますが、通常はデフォルトで CLI 設定値になります。
コマンドの例は、次のようになります。
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
出力は CLI に返されます。例を示します。
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
これはオプションコマンドで、既存のスキーマを取得し、base-64 BLOB を使用して AWS AppSync サービスにアップロードします。この例では、このコマンドは使用しません。
start-schema-creation コマンドを実行します。
この特定のコマンドには、次の 2 つのパラメータを入力する必要があります。
-
api-id は前のステップからのものです。
-
スキーマ definitionは base-64 でエンコードされたバイナリブロブです。
コマンドの例は、次のようになります。
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
次のような出力が返されます。
{
"status": "PROCESSING"
}
このコマンドは処理後の最終出力を返しません。結果を確認するには別のコマンド get-schema-creation-status を使用する必要があります。この 2 つのコマンドは非同期なので、スキーマの作成中でも出力ステータスを確認できることに注意してください。
- CDK
-
-
CDK の開始点は少し異なります。理想的には、schema.graphql ファイルはすでに作成されているはずです。必要なのは、.graphql ファイル拡張子が付いた新しいファイルを作成することだけです。空のリストを指定できます。
-
一般的には、使用しているサービスにインポートディレクティブを追加しなければならない場合があります。たとえば、次の形式に従います。
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
GraphQL API を追加するには、スタックファイルで AWS AppSync サービスをインポートする必要があります。
import * as appsync from 'aws-cdk-lib/aws-appsync';
つまり、appsync キーワードでサービス全体をインポートすることになります。アプリでこれを使用するには、 AWS AppSync コンストラクトは の形式を使用しますappsync.construct_name。例えば、GraphQL API を作りたいなら、new appsync.GraphqlApi(args_go_here) と言うでしょう。次のステップはこれを描写しています。
-
最も基本的な GraphQL API には、API 用の name と schema パスが含まれます。
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
このスニペットが何をするのか見てみましょう。api の範囲内では、appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps) を呼び出して新しい GraphQL API を作成しています。スコープは this で、現在のオブジェクトを参照します。ID は API_ID で、作成 CloudFormation 時に の GraphQL API のリソース名になります。GraphqlApiProps には、GraphQL API の name と schema が含まれています。schema は、.graphql ファイル (schema_name.graphql) の絶対パス (__dirname) を検索してスキーマ (SchemaFile.fromAsset) を生成します。実際のシナリオでは、スキーマファイルはおそらく CDK アプリ内にあるでしょう。
GraphQL API に加えた変更を使用するには、アプリを再デプロイする必要があります。
スキーマへのタイプの追加
スキーマを追加したので、入力タイプと出力タイプの両方を追加し始めることができます。ここで説明する型は実際のコードでは使用しないでください。これらはプロセスの理解に役立つ例に過ぎません。
まず、オブジェクトタイプを作成します。実際のコードでは、これらのタイプから始める必要はありません。GraphQL の規則と構文に従っていれば、いつでも好きなタイプを作ることができます。
次のいくつかのセクションではスキーマエディターを使用するので、これを開いたままにしておきます。
- Console
-
-
オブジェクトタイプは、type キーワードとタイプ名を使用して作成できます。
type Type_Name_Goes_Here {}
タイプのスコープ内には、オブジェクトの特性を表すフィールドを追加できます。
type Type_Name_Goes_Here {
# Add fields here
}
例を示します。
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
このステップでは、必須の id フィールドを ID として格納し、title フィールドを String として格納し、date フィールドを AWSDateTime として格納する汎用オブジェクトタイプを追加しました。タイプとフィールド、およびその機能の一覧については、「スキーマ」を参照してください。スカラーの一覧とその機能については、タイプのリファレンスを参照してください。
- CLI
-
まだの場合は、コンソール版最初に読むことをお勧めします。
-
オブジェクトタイプは create-type コマンドを実行して作成できます。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
このステップでは、必須の id フィールドを ID として格納し、title フィールドを String として格納し、date フィールドを AWSDateTime として格納する汎用オブジェクトタイプを追加しました。タイプとフィールド、およびその機能の一覧については、「スキーマ」を参照してください。スカラーの一覧とその機能については、タイプのリファレンスを参照してください。
さらにお気づきかもしれませんが、定義を直接入力しても、小さいタイプでは有効ですが、大きい型や複数のタイプを追加することはできません。.graphql ファイルにすべてを追加し、それを入力として渡すこともできます。
- CDK
-
タイプを追加するには、.graphql ファイルに追加する必要があります。例えば、コンソールの例は次のとおりです。
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
他のファイルと同様に、タイプをスキーマに直接追加できます。
GraphQL API に加えた変更を使用するには、アプリを再デプロイする必要があります。
オブジェクトタイプには、文字列や整数などのスカラー型であるフィールドがあります。 AWS AppSync では、基本 GraphQL スカラーAWSDateTimeに加えて、 などの拡張スカラー型を使用することもできます。また、名前が感嘆符で終わっているフィールドは必須フィールドです。
ID スカラー型は、String または Int のいずれかである一意の識別子です。これらはリゾルバーのマッピングテンプレートで自動割り当てを制御できます。
Query のような特別なオブジェクトタイプと上記の例のような「通常の」オブジェクトタイプでは、どちらもtype キーワードを使用し、オブジェクトと見なされるという点で類似点があります。ただし、特殊オブジェクトタイプ (Query、Mutation、およびSubscription) は API のエントリポイントとして公開されるため、動作が大きく異なります。また、データというよりは、オペレーションのシェーピングに関するものでもあります。詳細については、「The Query and Mutation types」を参照してください。
特殊なオブジェクトタイプについて言えば、次のステップは、1 つまたは複数のオブジェクトタイプを追加して、シェーピングされたデータに対して操作を実行することです。実際のシナリオでは、すべての GraphQL スキーマには、データをリクエストするためのルートクエリタイプが少なくとも必要です。クエリは、GraphQL サーバーのエントリポイント (またはエンドポイント) の 1 つと考えることができます。例としてクエリを追加してみましょう。
- Console
-
-
クエリを作成するには、他のタイプと同様にスキーマファイルに追加するだけです。クエリには、次のような Query タイプとルート内のエントリが必要です。
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
プロダクション環境の Name_of_Query は、ほとんどの場合、単純に Query と呼ばれることに注意してください。この値のままにしておくことをお勧めします。クエリタイプ内にはフィールドを追加できます。各フィールドはリクエスト内でオペレーションを実行します。その結果、すべてではないにしても、ほとんどのフィールドがリゾルバーにアタッチされます。ただし、このセクションではその点については触れません。フィールドのオペレーションの形式については、次のようになります。
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
例を示します。
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
このステップでは、Query タイプを追加して schema ルートで定義しました。Query タイプは、Obj_Type_1 オブジェクトのリストを返す getObj フィールドを定義しました。Obj_Type_1 が前のステップのオブジェクトであることに注意してください。プロダクションコードでは、フィールド操作は通常、Obj_Type_1 のようなオブジェクトによって形成されたデータを処理します。さらに、getObj のようなフィールドには通常、ビジネスロジックを実行するリゾルバーがあります。これについては別のセクションで説明します。
追加の注意点として、 はエクスポート中にスキーマルート AWS AppSync を自動的に追加するため、技術的にはスキーマに直接追加する必要はありません。弊社のサービスは重複するスキーマを自動的に処理します。ベストプラクティスとしてここに追加しています。
- CLI
-
まだの場合は、コンソール版最初に読むことをお勧めします。
-
create-type コマンドを実行して query 定義付きの schema ルートを作成します。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
schema {
query: Query
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
create-type コマンドに正しく入力しなかった場合は、update-type コマンドを実行することでスキーマルート (またはスキーマ内の任意のタイプ) を更新できることに注意してください。この例では、subscription 定義を含むようにスキーマルートを一時的に変更します。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
タイプの type-name。コンソールの例では、これは schema でした。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
schema {
query: Query
}
subscription を追加した後のスキーマは次のようになります。
schema {
query: Query
subscription: Subscription
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
この例でも、フォーマット済みのファイルを追加しても問題ありません。
-
create-type コマンドを実行して Query タイプを作成します。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
type Query {
getObj: [Obj_Type_1]
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
このステップでは、Query タイプを追加して schema ルートで定義しました。Query タイプは、Obj_Type_1 オブジェクトのリストを返す getObj フィールドを定義しました。
schema ルートコードではquery: Query、query: 部分はクエリがスキーマで定義されたことを示し、Query 部分は実際の特別なオブジェクト名を示します。
- CDK
-
クエリとスキーマルートを .graphql ファイルに追加する必要があります。この例は以下の例のようになっていますが、実際のスキーマコードに置き換える必要があります。
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
他のファイルと同様に、タイプをスキーマに直接追加できます。
スキーマルートの更新は任意です。ベストプラクティスとして、この例に追加しました。
GraphQL API に加えた変更を使用するには、アプリを再デプロイする必要があります。
オブジェクトと特殊オブジェクト (クエリ) の両方を作成する例を見てきました。また、これらを相互に接続してデータや操作を記述する方法についても説明しました。データ記述と 1 つ以上のクエリのみを含むスキーマを作成できます。ただし、データソースにデータを追加する操作をもう 1 つ追加したいと考えています。データを変更する Mutation と呼ばれる特別なオブジェクトタイプを追加します。
- Console
-
-
ミューテーションはMutationと呼ばれます。Query と同様に、Mutation 内部のフィールド操作は操作を記述し、リゾルバーにアタッチされます。また、これは特殊なオブジェクトタイプなので、schema ルートで定義する必要があることにも注意してください。ミューテーションの例を示します。
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
一般的なミューテーションは、クエリのようにルートにリストされます。ミューテーションは type キーワードと名前を使って定義されます。通常は Name_of_Mutation がMutationと呼ばれるので、そのままにしておくことをおすすめします。各フィールドはオペレーションも実行します。フィールドのオペレーションの形式については、次のようになります。
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
例を示します。
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
このステップでは、addObj フィールドのある Mutation タイプを追加しました。このフィールドの機能をまとめてみましょう。
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObj では Obj_Type_1 オブジェクトを使用してオペレーションを実行しています。これはフィールドがあるから明らかですが、構文では : Obj_Type_1 戻り値のタイプでもそれが証明されています。addObj 内部では、Obj_Type_1 オブジェクトのid、title、date フィールドをパラメータとして受け付けています。ご覧のとおり、これはメソッド宣言によく似ています。ただし、メソッドの動作についてはまだ説明していません。前述のように、スキーマはデータとオペレーションの内容を定義するためだけのもので、オペレーションの方法を定義するものではありません。実際のビジネスロジックの実装は、後で最初のリゾルバーを作成するときに実装します。
スキーマが完成したら、それを schema.graphql ファイルとしてエクスポートするオプションがあります。スキーマエディターで [スキーマをエクスポート] を選択すると、サポートされている形式でファイルをダウンロードできます。
追加の注意点として、 はエクスポート中にスキーマルート AWS AppSync を自動的に追加するため、技術的にはスキーマに直接追加する必要はありません。弊社のサービスは重複するスキーマを自動的に処理します。ベストプラクティスとしてここに追加しています。
- CLI
-
まだの場合は、コンソール版最初に読むことをお勧めします。
-
update-type コマンドを実行してルートスキーマを更新します。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
タイプの type-name。コンソールの例では、これは schema でした。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
schema {
query: Query
mutation: Mutation
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
create-type コマンドを実行して Mutation タイプを作成します。
この特定のコマンドでは、いくつかのパラメータを入力する必要があります。
-
API の api-id です。
-
definition、またはタイプのコンテンツです。コンソールの例では、次のようになっていました。
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
入力の format です。この例では、SDL を使用します。
コマンドの例は、次のようになります。
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
出力は CLI に返されます。例を示します。
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
クエリとスキーマルートを .graphql ファイルに追加する必要があります。この例は以下の例のようになっていますが、実際のスキーマコードに置き換える必要があります。
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
スキーマルートの更新は任意です。ベストプラクティスとして、この例に追加しました。
GraphQL API に加えた変更を使用するには、アプリを再デプロイする必要があります。
その他の考慮事項 - 列挙型をステータスとして使用する
これで、基本的なスキーマの作り方がわかりました。しかし、スキーマの機能を高めるために追加できることはたくさんあります。アプリケーションによく見られることの 1 つは、列挙型をステータスとして使用することです。列挙型を使用すると、呼び出し時に値のセットから特定の値を強制的に選択させることができます。これは、長期間にわたって大幅に変化することはないとわかっている場合に便利です。仮説的に言えば、レスポンスにステータスコードまたは文字列を返す列挙型を追加できるかもしれません。
例として、ユーザーの投稿データをバックエンドに保存するソーシャルメディアアプリを作っているとしましょう。このスキーマには、個々の投稿のデータを表す Post タイプが含まれています。
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
私たちの Post には一意の id、投稿 title、投稿の date と、アプリによって処理された投稿の状態を表す PostStatus と呼ばれるという列挙型が含まれます。今回の操作では、すべての投稿データを返すクエリを用意します。
type Query {
getPosts: [Post]
}
また、データソースに投稿を追加するミューテーションもあります。
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
スキーマを見ると、PostStatus 列挙型には複数のステータスがある可能性があります。success (投稿は正常に処理されました)、pending (投稿は処理中)、error (投稿は処理できません) という 3 つの基本的な状態が必要な場合があります。列挙型を追加するには、次のようにします。
enum PostStatus {
success
pending
error
}
完全なスキーマは次のようになります。
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
ユーザーがアプリケーションに Post を追加すると、そのデータを処理する addPost オペレーションが呼び出されます。addPost にアタッチされたリゾルバーがデータを処理している間、poststatus はオペレーションの状態で継続的に更新されます。クエリを実行すると、Post にはデータの最終ステータスが含まれます。データをスキーマ内でどのように動作させたいかを説明しているだけだということを覚えておいてください。ここではリゾルバーの実装について多くのことを想定しています。リゾルバーは、リクエストを満たすためにデータを処理するための実際のビジネスロジックを実装します。
オプションとしての考慮事項 - サブスクリプション
AWS AppSync のサブスクリプションは、ミューテーションへの応答として呼び出されます。サブスクリプションは、Subscription 型と @aws_subscribe() ディレクティブを使用してスキーマで設定して、どのミューテーションが 1 つまたは複数のサブスクリプションを呼び出すかを示します。サブスクリプションの設定については、「リアルタイムデータ」を参照してください。
オプションとしての考慮事項 - リレーションとページ分割
DynamoDB テーブルに 100 万個の Posts が格納されていて、そのデータの一部を返したいとします。ただし、上記のクエリ例では、すべての投稿を返すだけです。リクエストするたびにこれらすべてを取得したいとは思わないでしょう。代わりに、それらをページ分割したいと思うかもしれません。スキーマを次のように変更します。
-
getPosts フィールドに、nextToken (イテレーター) と limit (イテレーション制限) の 2 つの入力引数を追加します。
-
Posts (Post オブジェクトのリストを取得) と nextToken (イテレーター) PostIterator フィールドを含む新しい タイプを追加します。
-
getPosts を変更すると、Post オブジェクトのリストではなく、PostIterator を返します。
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
PostIterator タイプにより、Post オブジェクトのリストと、次ののバッチを取得するための nextToken を返すことができます。PostIterator 内部には、ページ分割トークン (nextToken) とともに返される Post アイテム ([Post]) のリストがあります。 AWS AppSync では、これはリゾルバーを介して Amazon DynamoDB に接続され、暗号化されたトークンとして自動的に生成されます。マッピングテンプレートにより、limit 引数の値は maxResults パラメータに変換され、nextToken 引数の値は exclusiveStartKey パラメータに変換されます。 AWS AppSync コンソールでの例および組み込みテンプレートサンプルについては、「リゾルバーのリファレンス (JavaScript)」を参照してください。