Amazon Athena Vertica コネクタ
Vertica は、クラウドまたはオンプレミスでデプロイできる列指向データベースプラットフォームで、エクサバイト規模のデータウェアハウスをサポートします。Athena からの Vertica データソースのクエリには、フェデレーティッドクエリで Amazon Athena Vertica コネクタを使用できます。たとえば、Vertica 上のデータウェアハウスと Amazon S3 のデータレイクに対して分析クエリを実行できます。
このコネクタは、Glue 接続を使用して Glue の設定プロパティを一元化しません。接続設定は Lambda を介して行われます。
前提条件
Athena コンソールまたは AWS Serverless Application Repository を使用して AWS アカウント にコネクタをデプロイします。詳細については「データソース接続を作成する」または「AWS Serverless Application Repository を使用してデータソースコネクタをデプロイする」を参照してください。
このコネクタを使用する際は、先に VPC とセキュリティグループをセットアップしておきます。詳細については、「データソースコネクタまたは AWS Glue 接続用の VPC を作成する」を参照してください。
制限
-
Athena Vertica コネクタは、Amazon S3 からエクスポートされた Parquet ファイルを読み取るので、コネクタのパフォーマンスが低下する可能性があります。大きなテーブルに対してクエリを実行する場合は、CREATE TABLE AS (SELECT ...) クエリおよび SQL 述語を使用することをお勧めします。
-
現在、Athena フェデレーティッドクエリでの既知の問題のため、コネクタにより Vertica ではクエリされたテーブルのすべての列が Amazon S3 にエクスポートされますが、Athena コンソールの結果にはクエリされた列のみが表示されます。
-
DDL の書き込みオペレーションはサポートされていません。
-
関連性のある Lambda 上限値。詳細については、AWS Lambda デベロッパーガイドの Lambda のクォータを参照してください。
ワークフロー
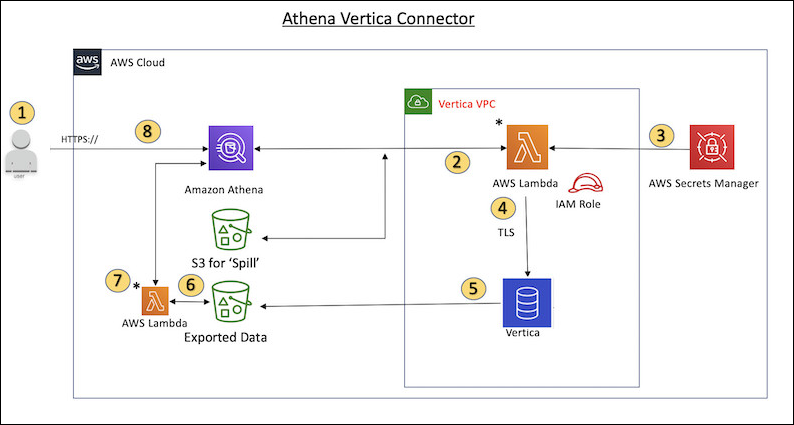
次の図は、Vertica コネクタを使用するクエリのワークフローを示しています。
-
SQL クエリは、Vertica の 1 つ以上のテーブルに対して発行されます。
-
コネクタは SQL クエリを解析し、関連する部分を JDBC 接続経由で Vertica に送信します。
-
Vertica にアクセスするため、接続文字列には AWS Secrets Manager に保存されているユーザー名とパスワードを使用します。
-
コネクタは、次の例のように SQL クエリを Vertica の
EXPORTコマンドでラップします。EXPORT TO PARQUET (directory = 's3://amzn-s3-demo-bucket/folder_name, Compression='Snappy', fileSizeMB=64) OVER() as SELECT PATH_ID, ... SOURCE_ITEMIZED, SOURCE_OVERRIDE FROM DELETED_OBJECT_SCHEMA.FORM_USAGE_DATA WHERE PATH_ID <= 5; -
Vertica が SQL クエリを処理し、結果セットを Amazon S3 バケットに送信します。スループットを向上させるため、Vertica は
EXPORTオプションを使用して、複数の Parquet ファイルの書き込みオペレーションを並列化します。 -
Athena は Amazon S3 バケットをスキャンして、結果セット用に読み込むファイルの数を決定します。
-
Athena は Lambda 関数を複数回呼び出し、Apache
ArrowReaderを使用して結果のデータセットから Parquet ファイルを読み取ります。複数回呼び出しを行うことで、Athena は Amazon S3 ファイルの読み取りを並列化し、1 秒あたり最大 100 GB のスループットを達成できます。 -
Athena は、Vertica から返されたデータをデータレイクからスキャンされたデータで処理し、その結果を返します。
用語
Vertica コネクタに関連する用語を次に示します。
-
データベースインスタンス — Amazon EC2 にデプロイされた Vertica データベースの任意のインスタンス。
-
ハンドラー – データベースインスタンスにアクセスする Lambda ハンドラー。ハンドラーには、メタデータ用とデータレコード用があります。
-
メタデータハンドラー – データベースインスタンスからメタデータを取得する Lambda ハンドラー。
-
レコードハンドラー – データベースインスタンスからデータレコードを取得する Lambda ハンドラー。
-
複合ハンドラー — データベースインスタンスからメタデータとデータレコードの両方を取得する Lambda ハンドラー。
-
プロパティまたはパラメータ – ハンドラーがデータベース情報を抽出するために使用するデータベースプロパティ。これらのプロパティは Lambda の環境変数で設定します。
-
接続文字列 – データベースインスタンスへの接続を確立するために使用されるテキスト文字列。
-
カタログ – Athena に登録された AWS Glue ではないカタログ。これは、
connection_stringプロパティに必須のプレフィックスです。
パラメータ
Amazon Athena Vertica コネクタは Lambda 環境変数を使用して、設定オプションを公開します。次の Lambda 環境変数を使用して、コネクタを設定できます。
-
AthenaCatalogName — Lambda 関数名
-
ExportBucket — Vertica のクエリ結果がエクスポートされる Amazon S3 バケット。
-
SpillBucket — この関数がデータを提供できる Amazon S3 バケットの名前。
-
SpillPrefix — この関数がデータを提供できる
SpillBucketの場所のプレフィックス。 -
SecurityGroupIds — Lambda 関数に適用する必要があるセキュリティグループに対応する 1 つ以上の ID (例:
sg1、sg2、またはsg3)。 -
SubnetIds — Lambda 関数がデータソースへのアクセスに使用できるサブネットに対応する 1 つ以上のサブネット ID (例:
subnet1、またはsubnet2)。 -
SecretNameOrPrefix — この関数がアクセスできる Secrets Manager 内の名前セットの名前またはプレフィックス (例:
vertica-*)。 -
VerticaConnectionString — カタログ固有の接続が定義されていない場合にデフォルトで使用される Vertica 接続の詳細。オプションで、文字列は AWS Secrets Manager 構文を使用できます (例:
${secret_name})。 -
VPC ID — Lambda 関数にアタッチする VPC ID。
接続文字列
次の形式の JDBC 接続文字列を使用して、データベースインスタンスに接続します。
vertica://jdbc:vertica://host_name:port/database?user=vertica-username&password=vertica-password
単一接続ハンドラーの使用
次の単一接続のメタデータハンドラーとレコードハンドラーを使用して、単一の Vertica インスタンスに接続できます。
| ハンドラーのタイプ | Class |
|---|---|
| 複合ハンドラー | VerticaCompositeHandler |
| メタデータハンドラー | VerticaMetadataHandler |
| レコードハンドラー | VerticaRecordHandler |
単一接続ハンドラーのパラメータ
| パラメータ | 説明 |
|---|---|
default |
必須。デフォルトの接続文字列。 |
単一接続ハンドラーでは、1 つのデータベースインスタンスがサポートされます。また、default 接続文字列パラメータを指定する必要があります。他のすべての接続文字列は無視されます。
認証情報の提供
JDBC 接続文字列の中でデータベースのユーザー名とパスワードを指定するには、接続文字列のプロパティ、もしくは AWS Secrets Manager を使用します。
-
接続文字列 – ユーザー名とパスワードを、JDBC 接続文字列のプロパティとして指定できます。
重要
セキュリティのベストプラクティスとして、環境変数や接続文字列にハードコードされた認証情報を使用しないでください。ハードコードされたシークレットを AWS Secrets Manager に移動する方法については、「AWS Secrets Manager ユーザーガイド」の「ハードコードされたシークレットを AWS Secrets Manager に移動する」を参照してください。
-
AWS Secrets Manager – Athena フェデレーティッドクエリ機能を AWS Secrets Manager で使用するには、Secrets Manager に接続するためのインターネットアクセス
または VPC エンドポイントが、Lambda 関数に接続されている VPC に必要です。 JDBC 接続文字列には、AWS Secrets Manager のシークレットの名前を含めることができます。コネクタは、このシークレット名を Secrets Manager の
usernameおよびpasswordの値に置き換えます。Amazon RDS データベースインスタンスには、このサポートが緊密に統合されています。Amazon RDS を使用している場合は、AWS Secrets Manager と認証情報ローテーションの使用を強くお勧めします。データベースで Amazon RDS を使用していない場合は、認証情報を次の形式で JSON として保存します。
{"username": "${username}", "password": "${password}"}
シークレット名を含む接続文字列の例
次の文字列には、シークレット名 ${vertica-username} および ${vertica-password} が含まれています。
vertica://jdbc:vertica://host_name:port/database?user=${vertica-username}&password=${vertica-password}
次の例のように、コネクタはシークレット名を使用し、シークレットを取得してユーザー名とパスワードを提供します。
vertica://jdbc:vertica://host_name:port/database?user=sample-user&password=sample-password
現在、Vertica コネクタは vertica-username と vertica-password の JDBC プロパティを認識します。
スピルパラメータ
Lambda SDK は Amazon S3 にデータをスピルする可能性があります。同一の Lambda 関数によってアクセスされるすべてのデータベースインスタンスは、同じ場所にスピルします。
| パラメータ | 説明 |
|---|---|
spill_bucket |
必須。スピルバケット名。 |
spill_prefix |
必須。スピルバケットのキープレフィックス |
spill_put_request_headers |
(オプション) スピルに使用される Amazon S3 の putObject リクエスト (例:{"x-amz-server-side-encryption" :
"AES256"}) における、リクエストヘッダーと値に関する JSON でエンコードされたマッピング。利用可能な他のヘッダーについては、「Amazon Simple Storage Service API リファレンス」の「PutObject」を参照してください。 |
サポートされるデータ型
次の表は、Vertica コネクタ用にサポートされているデータ型です。
| ブール値 |
|---|
| BigInt |
| ショート |
| 整数 |
| Long |
| 浮動小数点数 |
| 倍精度 |
| 日付 |
| Varchar |
| バイト |
| BigDecimal |
| Varchar としての TimeStamp |
パフォーマンス
Lambda 関数は射影プッシュダウンを実行して、クエリがスキャンするデータを減少させます。LIMIT 句はスキャンされるデータ量を削減しますが、述語を提供しない場合、LIMIT 句を含む SELECT クエリは少なくとも 16 MB のデータをスキャンすることを想定する必要があります。Vertica コネクタは、同時実行によるスロットリングに強いです。
パススルークエリ
Vertica コネクタは、パススルークエリをサポートします。パススルークエリは、テーブル関数を使用して、実行のためにクエリ全体をデータソースにプッシュダウンします。
Vertica でパススルークエリを使用するには、以下の構文を使用できます。
SELECT * FROM TABLE( system.query( query => 'query string' ))
以下のクエリ例は、Vertica 内のデータソースにクエリをプッシュダウンします。クエリは customer テーブル内のすべての列を選択し、結果を 10 個に制限します。
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
ライセンス情報
このコネクタを使用することにより、pom.xml
追加リソース
最新の JDBC ドライバーのバージョン情報については、GitHub.com で Vertica コネクタ用の pom.xml
このコネクタの追加情報については、GitHub.com の対応するサイト
