Amazon Forecast は新規顧客には利用できなくなりました。Amazon Forecast の既存のお客様は、通常どおりサービスを引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
予測精度の評価
Amazon Forecast は、予測子を評価し、予測の生成に使用する項目を選択するのに役立つ精度メトリクスを生成します。Amazon Forecast は、二乗平均平方根誤差 (RMSE)、重み付き分位損失 (wQL)、平均絶対パーセント誤差 (MAPE)、平均絶対スケーリング誤差 (MASE)、および重み付き絶対誤差率 (WAPE) メトリクスを提供します。
Amazon Forecast は、バックテストを使用してパラメータをチューニングし、精度メトリクスを生成します。バックテスト中、Forecast は、時系列データをトレーニングセットとテストセットといった 2 つのセットに自動的に分割します。トレーニングセットは、モデルをトレーニングし、テストセット内のデータポイントの予想を生成するために使用されます。Forecast は、予測値をテストセットの観測値と比較することにより、モデルの精度を評価します。
Forecast を使用すると、さまざまな予測タイプを使用して予測子を評価できます。これは、分位数予測と平均予測のセットである場合があります。平均予測は点推定を提供しますが、分位数予測は通常、考えられる結果の範囲を提供します。
Python ノートブック
予測子メトリクスの評価に関するステップバイステップガイドについては、「Computing Metrics Using Item-level Backtests
トピック
精度メトリクスの解釈
Amazon Forecast は、予測子を評価するために、二乗平均平方根誤差 (RMSE)、重み付き分位損失 (wQL)、平均重み付き分位損失 (平均 wQL)、平均絶対スケーリング誤差 (MASE)、平均絶対パーセント誤差 (MAPE)、および重み付き絶対誤差率 (WAPE) メトリクスを提供します。全体的な予測子のメトリクスとともに、Forecast は、各バックテストウィンドウのメトリクスを計算します。
Amazon Forecast のソフトウェア開発キット (SDK) および Amazon Forecast コンソールを使用して、予測子の精度メトリクスを表示できます。
注記
平均 wQL、wQL、RMSE、MASE、MAPE、および WAPE メトリクスの場合、値が小さいほど優れたモデルであることを示します。
トピック
重み付き分位損失 (wQL)
重み付き分位損失 (wQL) メトリクスは、指定された分位数でのモデルの精度を測定します。これは、過小予測と過大予測のコストが異なる場合に特に役立ちます。wQL 関数の重み (τ) を設定することにより、過小予測と過大予測に対して異なるペナルティを自動的に組み込むことができます。
損失関数は以下のように計算されます。

- コードの説明は以下のとおりです。
-
τ - セット {0.01, 0.02, ..., 0.99} 内の分位数
qi,t(τ) - モデルが予測する τ 分位数。
yi,t - ポイント (i,t) での観測値
wQL の分位数 (τ) は、0.01 (P1) から 0.99 (P99) の範囲です。wQL メトリクスは、平均予測を求めるために計算することはできません。
デフォルトでは、Forecast は、0.1 (P10)、0.5 (P50)、および 0.9 (P90) で wQL を計算します。
-
P10 (0.1) - true の値は 10% の確率で予測値より低くなることが予想されます。
-
P50 (0.5) - true の値は 50% の確率で予測値より低くなることが予想されます。これは、予測の中央値とも呼ばれます。
-
P90 (0.9) - true の値は 90% の確率で予測値より低くなることが予想されます。
小売業では、在庫不足のコストは在庫過剰のコストよりも高いことが多いため、P75 (τ = 0.75) での予測は、分位数の中央値 (P50) での予測よりも有益な場合があります。これらの場合、wQL[0.75] は、より大きなペナルティの重みを過小予測 (0.75) に割り当て、より小さなペナルティの重みを過大予測 (0.25) に割り当てます。

上の図は、wQL[0.50] と wQL[0.75] でのさまざまな需要予測を示しています。P75 の予測値は P50 の予測値よりも大幅に高くなります。これは、P75 の予測が 75% の確率で需要を満たすと予想されるのに対し、P50 の予測は 50% の確率で需要を満たすと予想されるためです。
指定のバックテスト期間では、すべての項目と時間ポイントの観察された値の合計がほぼゼロの場合、重み付き分位損失の式は未定義になります。これらの場合、Forecast は重み付けされていない分位損失を出力します。これは、wQL 式の分子です。
Forecast は、指定されたすべての分位数にわたる重み付き分位損失の平均値である平均 wQL も計算します。デフォルトでは、これは wQL[0.10]、wQL[0.50]、および wQL[0.90] の平均になります。
重み付き絶対誤差率 (WAPE)
重み付き絶対誤差率 (WAPE) は、観測値からの予測値の全体的な偏差を測定します。WAPE は、観測値の合計と予測値の合計を取り、これら 2 つの値の間の誤差を計算することによって計算されます。値が小さいほど、モデルの精度が高くなります。
指定のバックテスト期間では、すべての時間ポイントとすべての項目の観察された値の合計がほぼゼロの場合、重み付き絶対パーセント誤差の式は未定義になります。これらの場合、Forecast は重み付けされていない絶対誤差の合計を出力します。これは、WAPE 式の分子です。

- コードの説明は以下のとおりです。
-
yi,t - ポイント (i,t) での観測値
ŷi,t - ポイント (i,t) での予測値
Forecast は、平均予測を予測値 ŷi,t として使用します。
WAPE は、二乗誤差の代わりに絶対誤差を使用するため、二乗平均平方根誤差 (RMSE) よりも外れ値に対してロバストです。
Amazon Forecast は、これまで、WAPE メトリクスを平均絶対パーセント誤差 (MAPE) と呼び、予測の中央値 (P50) を予測値として使用していました。Forecast は、平均予測を使用して WAPE を計算するようになりました。以下に示すように、wQL[0.5] メトリクスは WAPE[median] メトリクスと同等です。
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
二乗平均平方根誤差 (RMSE)
二乗平均平方根誤差 (RMSE) は、二乗誤差の平均の平方根であるため、他の精度メトリクスよりも外れ値の影響を受けやすくなります。値が小さいほど、モデルの精度が高くなります。
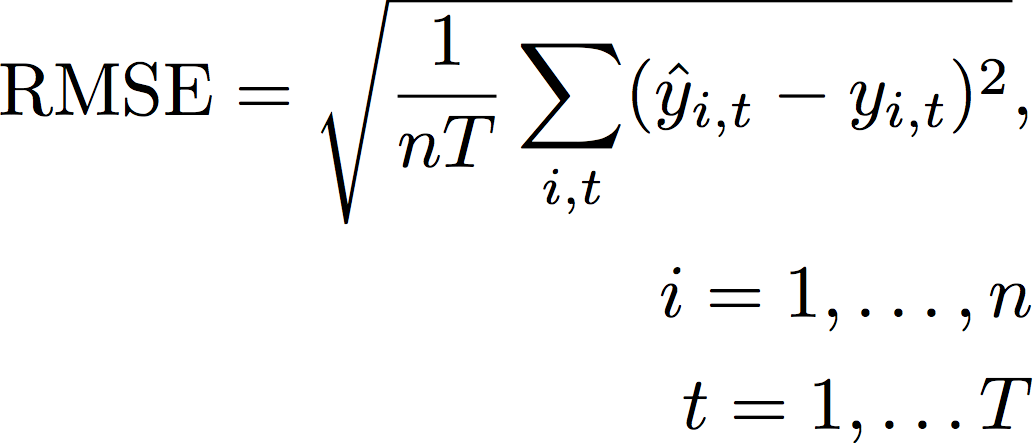
- コードの説明は以下のとおりです。
-
yi,t - ポイント (i,t) での観測値
ŷi,t - ポイント (i,t) での予測値
nT - テストセット内のデータポイントの数
Forecast は、平均予測を予測値 ŷi,t として使用します。予測子メトリクスを計算する場合、nT はバックテストウィンドウ内のデータポイントの数です。
RMSE は、外れ値の影響を増幅する残差の 2 乗値を使用します。非常に大きなコストを発生させる可能性があるのがいくつかの大きな誤予測だけであるユースケースでは、RMSE がより適切なメトリクスです。
2020 年 11 月 11 日より前に作成された予測子は、デフォルトで 0.5 分位数 (P50) を使用して RMSE を計算していました。Forecast は、平均予測を使用するようになりました。
平均絶対パーセント誤差 (MAPE)
平均絶対パーセント誤差 (MAPE) は、各時間単位の観測値と予測値の間のパーセント誤差の絶対値を取得し、それらの値を平均します。値が小さいほど、モデルの精度が高くなります。

- コードの説明は以下のとおりです。
-
At - ポイント t での観測値
Ft - ポイント t での予測値
n - 時系列のデータポイントの数
Forecast は、平均予測を予測値 Ft として使用します。
MAPE は、値が時間ポイント間で大幅に異なり、外れ値が大きな影響を及ぼす場合に役立ちます。
平均絶対スケーリング誤差 (MASE)
平均絶対スケーリング誤差 (MASE) は、平均誤差をスケーリング係数で除することによって計算されます。このスケーリング係数は、予測頻度に基づいて選択された季節性の値 m に依拠します。値が小さいほど、モデルの精度が高くなります。

- コードの説明は以下のとおりです。
-
Yt - ポイント t での観測値
Yt-m - ポイント t-m での観測値
ej - 点 j での誤差 (観測値 - 予測値)
m - 季節性の値
Forecast は、平均予測を予測値として使用します。
MASE は、本質的に循環的であるか、季節的な特性を持つデータセットに最適です。例えば、夏季には需要が高く、冬季には需要が少ない商品の予測は、季節的な影響を考慮に入れることでより正確なものとなり得ます。
精度メトリクスのエクスポート
注記
エクスポートファイルは、[Dataset Import] (データセットのインポート) から直接情報を返すことができます。これにより、インポートされたデータに式またはコマンドが含まれている場合、ファイルは CSV インジェクションに対して脆弱になります。このため、エクスポートされたファイルはセキュリティ警告を表示する可能性があります。悪意のあるアクティビティを回避するには、エクスポートされたファイルを読み取るときにリンクとマクロを無効にします。
Forecast を使用すると、バックテスト中に生成された予測値と精度メトリクスをエクスポートできます。
これらのエクスポートを使用して、特定の時間ポイントおよび分位数で特定の項目を評価し、予測子をより良く理解できます。バックテストエクスポートは、指定された S3 の場所に送信され、2 つのフォルダを含みます。
-
forecasted-values: 各バックテストの各予想タイプでの予想値を含む CSV または Parquet ファイルが含まれています。
-
accuracy-metrics-values: すべてのバックテストの平均とともに、各バックテストのメトリクスを含む CSV または Parquet ファイルが含まれています。これらのメトリクスには、各分位数の wQL、平均 wQL、RMSE、MASE、MAPE、および WAPE が含まれます。
forecasted-values フォルダには、各バックテストウィンドウの各予測タイプの予測値が含まれています。また、項目 ID、ディメンション、タイムスタンプ、ターゲット値、およびバックテストウィンドウの開始時間と終了時間に関する情報も含まれています。
accuracy-metrics-values フォルダには、各バックテストウィンドウの精度メトリクスと、すべてのバックテストウィンドウの平均メトリクスが含まれています。これには、指定された各分位数の wQL メトリクスと、平均 wQL、RMSE、MASE、MAPE、および WAPE メトリクスが含まれます。
両方のフォルダ内のファイルは、命名規則に従います: <ExportJobName>_<ExportTimestamp>_<PartNumber>.csv。
Amazon Forecast のソフトウェア開発キット (SDK) および Amazon Forecast コンソールを使用して、精度メトリクスをエクスポートできます。

Forecast タイプの選択
Amazon Forecast は、予測タイプを使用して予測を作成し、予測子を評価します。Forecast のタイプには、次の 2 つの形式があります。
-
平均予測タイプ - 平均を期待値として使用する予測。通常、特定の時間ポイントのポイント予測として使用されます。
-
分位数の予測タイプ - 指定された分位数での予測。通常、予測間隔を提供するために使用されます。これは、予測の不確実性を説明するための可能な値の範囲です。例えば、
0.65分位数での予測では、65% の確率で観測値よりも低い値が推定されます。
デフォルトでは、Forecast は、予測子の予測タイプに、0.1 (P10)、0.5 (P50)、および 0.9 (P90) といった値を使用します。mean と、0.01 (P1) から 0.99 (P99) までの範囲の分位数を含む、最大 5 つのカスタム予測タイプを選択できます。
分位数は、予測の上限と下限を提供できます。例えば、予測タイプ 0.1 (P10) および 0.9 (P90) を使用すると、80% 信頼区間と呼ばれる値の範囲が提供されます。観測値は 10% の確率で P10 の値よりも低く、P90 の値は 90% の確率で観測値よりも高いことが予想されます。p10 と P90 で予測を生成することにより、true の値は、80% の確率でこれらの範囲内に収まることが想定されます。この値の範囲は、以下の図の P10 と P90 の間の影付きの領域で示されています。

過小予測のコストが過大予測のコストと異なる場合は、分位数予測をポイント予測として使用することもできます。例えば、小売業のいくつかのケースにおいては、在庫不足のコストは、過剰に在庫を抱えている場合のコストよりも高くなります。これらの場合、0.65 (P65) での予測は、中央値 (P50) または平均予測よりも有益です。
予測子をトレーニングする場合、Amazon Forecast のソフトウェア開発キット (SDK) と Amazon Forecast コンソールを使用してカスタム予測タイプを選択できます。

レガシー予測子の使用
バックテストパラメータの設定
Forecast は、バックテストを使用して精度メトリクスを計算します。複数のバックテストを実行する場合、Forecast は、すべてのバックテストウィンドウで各メトリクスを平均します。デフォルトでは、Forecast は、1 つのバックテストを計算し、バックテストウィンドウ (テストセット) のサイズは予測期間 (予測ウィンドウ) の長さに等しくなります。予測子をトレーニングするときに、バックテストウィンドウの長さとバックテストシナリオの数の両方を設定できます。
Forecast は、バックテストプロセスから入力された値を除外し、特定のバックテストウィンドウ内で値が入力された項目は、そのバックテストから除外されます。これは、Forecast がバックテスト中に予測値と観測値を比較するだけであり、入力された値は観測値ではないためです。
バックテストウィンドウは、少なくとも予測期間と同じ大きさであり、ターゲット時系列データセット全体の長さの半分よりも小さくなければなりません。1〜5 個のバックテストから選択できます。

一般に、バックテストの数を増やすと、テスト中に時系列の大部分が使用され、Forecast はすべてのバックテストのメトリクスの平均をとることができるため、より信頼性の高い精度メトリクスが生成されます。
Amazon Forecast のソフトウェア開発キット (SDK) および Amazon Forecast コンソールを使用して、バックテストパラメータを設定できます。

HPO および AutoML
デフォルトでは、Amazon Forecast は 0.1 (P10)、0.5 (P50)、および 0.9 (P90) 分位数を使用して、ハイパーパラメータ最適化 (HPO) 中のハイパーパラメータチューニングと AutoML 中のモデル選択を行います。予測子の作成時にカスタム予測タイプを指定すると、Forecast は、HPO および AutoML 中にそれらの予測タイプを使用します。
カスタム予測タイプが指定されている場合、Forecast は、HPO および AutoML 中に、それらの指定された予測タイプを使用して最適な結果を決定します。HPO 中、Forecast は、最初のバックテストウィンドウを使用して最適なハイパーパラメータ値を見つけます。AutoML 中、Forecast は、すべてのバックテストウィンドウの平均と HPO からの最適なハイパーパラメータ値を使用して、最適なアルゴリズムを見つけます。
AutoML と HPO の両方について、Forecast は、予測タイプ全体の平均損失を最小化するオプションを選択します。AutoML および HPO 中に、平均重み付き分位損失 (平均 wQL)、重み付き絶対誤差率 (WAPE)、二乗平均平方根誤差 (RMSE)、平均絶対パーセント誤差 (MAPE)、または平均絶対スケーリング誤差 (MASE) といった精度メトリクスのいずれかを使用して予測子を最適化することもできます。
Amazon Forecast の ソフトウェア開発キット (SDK) と Amazon Forecast コンソールを使用して、最適化メトリクスを選択できます。
