翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データのラベル付けの自動化
選択した場合、Amazon SageMaker Ground Truth は、アクティブラーニングを使用して、特定の組み込みタスクタイプの入力データのラベル付けを自動化できます。アクティブラーニングとは、ワーカーがラベル付けするデータを識別する機械学習の手法です。Ground Truth では、この機能を「自動データラベリング」と呼びます。自動データラベリングは、人間だけを使用する場合と比べて、データセットのラベル付けの所要コストと時間を削減するのに役立ちます。自動ラベル付けを使用すると、SageMaker トレーニングと推論の費用が発生します。
アクティブラーニングで使用されるニューラルネットワークは新しいデータセットごとに大量のデータを必要とするため、自動データラベリングは大規模なデータセットに対して使用することをお勧めします。通常、提供するデータが増えるほど、予測の精度が高くなります。自動ラベル付けモデルで使用されるニューラルネットワークで許容可能な高レベルの精度を達成できる場合にのみ、データが自動ラベル付けされます。したがって、データセットが大きいほど、ニューラルネットワークは自動ラベル付けに十分な高い精度を達成できるため、データが自動ラベル付けされる可能性が高くなります。自動データラベリングは、何千ものデータオブジェクトがある場合に最も適しています。自動データラベリングに許容される最小のオブジェクト数は 1,250 ですが、少なくとも 5,000 個のオブジェクトを指定することを強くお勧めします。
自動データラベリングは、次の Ground Truth 組み込みタスクタイプでのみ使用できます。
ストリーミングラベル付けジョブは、自動データラベリングをサポートしていません。
独自のモデルを使用してカスタムアクティブラーニングワークフローを作成する方法については、「独自のモデルを使用してアクティブラーニングワークフローをセットアップする」を参照してください。
自動データラベリングジョブには、入力データのクォータが適用されます。データセットのサイズ、入力データのサイズ、解像度の制限に関する情報は、「入力データのクォータ」を参照してください。
注記
本番環境で自動ラベル付けモデルを使用する前に、モデルの微調整またはテストを行うか、その両方を行う必要があります。ラベル付けジョブで生成されたデータセットでモデルを微調整する (または別の選択した監視対象モデルを作成して調整する) ことで、モデルのアーキテクチャとハイパーパラメータを最適化できます。モデルを微調整なしで推論に使用する場合は、Ground Truth でラベル付けしたデータセットの代表的なサブセット (ランダムに選択したサブセットなど) で精度を評価し、期待値を満たしていることを確認するよう強くお勧めします。
仕組み
自動データラベリングは、ラベル付けジョブの作成時に有効にします。この仕組みは以下のようになっています。
-
Ground Truth は、自動データラベリングジョブを開始するときに、入力データオブジェクトのランダムなサンプルを選択して人間のワーカーに送信します。これらのデータオブジェクトの 10% 以上が失敗すると、ラベル付けジョブは失敗します。ラベル付けジョブが失敗した場合は、Ground Truth が返すエラーメッセージを確認するだけでなく、入力データがワーカー UI に正しく表示されていること、指示が明確であること、ワーカーにタスクを完了するのに十分な時間を与えていることを確認します。
-
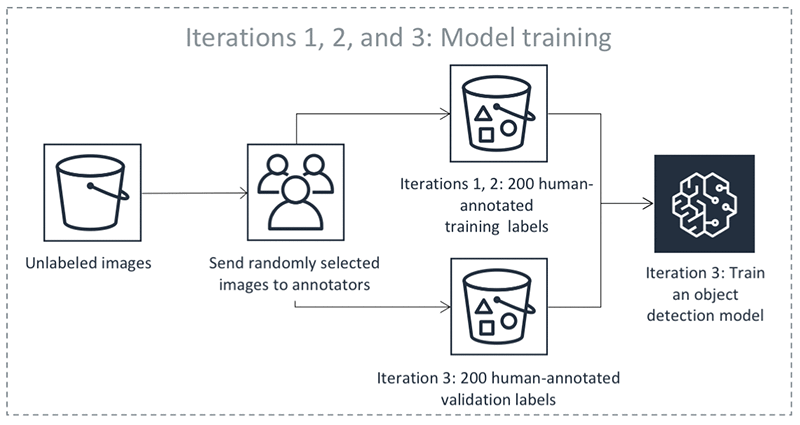
ラベル付きデータが返されると、トレーニングセットと検証セットの作成に使用されます。Ground Truth は、これらのデータセットを使用してデータの自動ラベル付けに使用されるモデルをトレーニングおよび検証します。
-
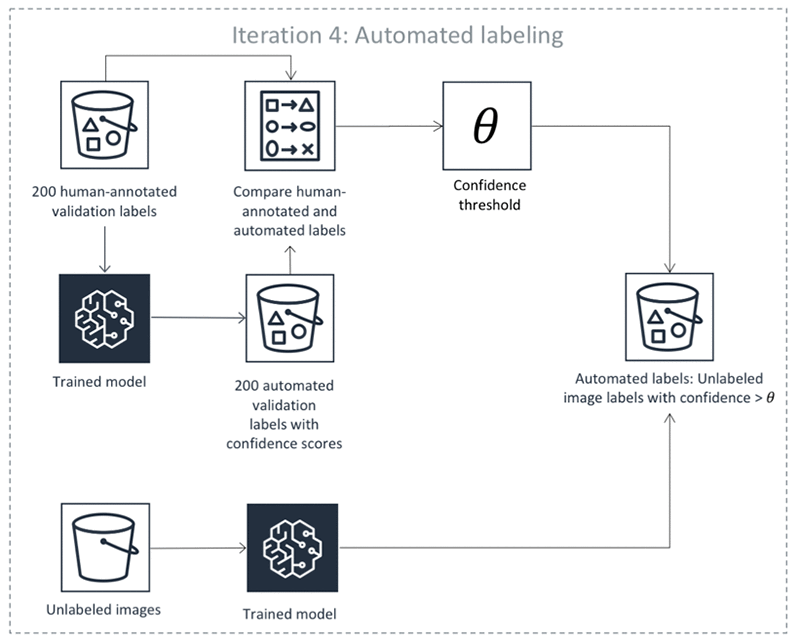
Ground Truth は、検証されたモデルを使用してバッチ変換ジョブを実行し、検証データに対する推論を行います。バッチ推論では、検証データ内のオブジェクトごとに信頼スコアと品質メトリクスが生成されます。
-
自動ラベル付けコンポーネントは、これらの品質メトリクスと信頼スコアを使用して、品質ラベルを保証する信頼スコアのしきい値を作成します。
-
Ground Truth は、推論用の同じ検証済みモデルを使用して、データセット内のラベル付けされていないデータに対してバッチ変換ジョブを実行します。これにより、オブジェクトごとの信頼スコアが生成されます。
-
Ground Truth の自動ラベル付けコンポーネントは、オブジェクトごとにステップ 5 で生成された信頼スコアが、ステップ 4 で決定された必要なしきい値を満たしているかどうかを判断します。信頼スコアがしきい値を満たしている場合は、自動ラベル付けに期待される品質が、要求される精度のレベルを超えているため、当該オブジェクトは自動ラベル付けされたものと見なされます。
-
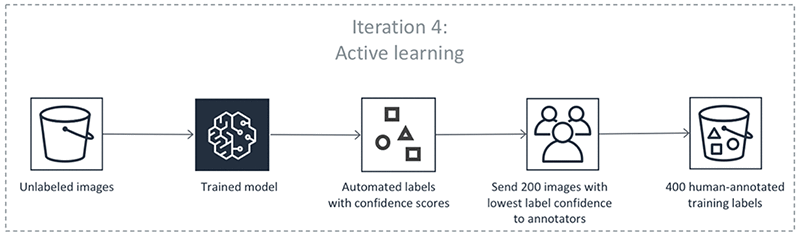
ステップ 6 では、信頼スコアを持つラベルなしデータのデータセットを生成します。Ground Truth は、このデータセットから信頼スコアの低いデータポイントを選択し、人間のワーカーに送信します。
-
Ground Truth は、人間によってラベル付けされた既存のデータと、人間のワーカーからの追加でラベル付けされたこのデータを使用して、新しいモデルを更新します。
-
このプロセスは、データセットが完全にラベル付けされるか、別の停止条件が満たされるまで繰り返されます。例えば、人間の注釈予算に達すると、自動ラベル付けは停止します。
上記のステップは、繰り返し行われます。次の表の各タブを選択すると、オブジェクト検出の自動ラベル付けジョブの各イテレーションで発生するプロセスの例が表示されます。これらのイメージの特定のステップで使用されるデータオブジェクトの数 (200 など) は、この例固有のものです。ラベルを付けるオブジェクトが 5,000 未満の場合、検証セットのサイズはデータセット全体の 20% になります。入力データセットに 5,000 を超えるオブジェクトがある場合、検証セットのサイズはデータセット全体の 10% になります。API オペレーション CreateLabelingJob を使用する場合、MaxConcurrentTaskCount の値を変更することでアクティブラーニングのイテレーションごとに収集される人間のラベルの数を制御できます。コンソールを使用してラベル付けジョブを作成する場合、この値は 1,000 に設定されます。[Active Learning] (アクティブラーニング) タブのアクティブラーニングフローでは、この値は 200 に設定されます。
自動ラベル付けの精度
精度の定義は、自動ラベル付けで使用する組み込みタスクタイプによって異なります。すべてのタスクタイプにおいて、これらの精度要件は Ground Truth によって事前に決定され、手動で構成することはできません。
-
イメージ分類とテキスト分類では、Ground Truth はロジックを使用して、少なくとも 95% のラベル精度に相当するラベル予測信頼レベルを見つけます。つまり、Ground Truth では、人間がその例でラベル付けした場合と比較すると、自動ラベルの精度は少なくとも 95% になると予想します。
-
境界ボックスの場合、自動ラベル付けされたイメージの期待平均 Intersection Over Union (IoU)
の値は 0.6 です。平均 IoU を求めるために、Ground Truth はすべてのクラスについて、イメージ上のすべての予測ボックスと欠落したボックスの平均 IoU を計算し、クラス間でこれらの値を平均化します。 -
セマンティックセグメンテーションの場合、自動ラベルイメージの期待平均 IoU は 0.7 です。平均 IoU を求めるために、Ground Truth はイメージ内のすべてのクラス (背景を除く) の IoU 値の平均をとります。
アクティブラーニングのイテレーションごとに(上記のリストの手順 3~6)、自動ラベル付きオブジェクトの予想精度が事前定義された特定の精度要件を満たすように、人間による注釈付き検証セットを使用して信頼しきい値が検出されます。
自動データラベリングジョブの作成 (コンソール)
SageMaker AI コンソールで自動ラベル付けを使用するラベル付けジョブを作成するには、次の手順に従います。
自動データラベリングジョブを作成するには (コンソール)
-
SageMaker AI コンソールの Ground Truth ラベル付けジョブセクションを開きます: https://console.aws.amazon.com/sagemaker/groundtruth
。 -
ラベル付けジョブの作成 (コンソール) をガイドとして使用し、[Job overview] (ジョブ概要) セクションと [Task type] (タスクタイプ) セクションに入力します。自動ラベル付けは、カスタムタスクタイプではサポートされません。
-
[Workers] (ワーカー) で、ワークフォースタイプを選択します。
-
同じセクションで、[Enable automated data labeling] (自動データラベリングを有効化) を選択します。
-
境界ボックスツールの設定 をガイドとして、[
Task Typelabeling tool] (タスクタイプのレベル付けツール) セクションでワーカーの指示を作成します。例えば、ラベル付けジョブタイプとして [Semantic segmentation] を選択した場合、このセクションの名前は [Semantic segmentation labeling tool] になります。 -
ワーカーの指示とダッシュボードをプレビューするには、[Preview] (プレビュー) を選択します。
-
[Create] (作成) を選択します。これにより、ラベル付けジョブと自動ラベル付けプロセスが作成されて開始されます。
ラベル付けジョブは、SageMaker AI コンソールのラベル付けジョブセクションに表示されます。出力データは、ラベル付けジョブの作成時に指定した Amazon S3 バケットに表示されます。ラベル付けジョブの出力データの形式とファイル構造の詳細については、「ラベル付けジョブの出力データ」を参照してください。
自動データラベリングジョブの作成 (API)
SageMaker API を使用して自動データラベリングジョブを作成するには、CreateLabelingJob オペレーションの LabelingJobAlgorithmsConfig パラメータを使用します。CreateLabelingJob オペレーションを使用してラベル付けジョブを開始する方法については、「ラベル付けジョブを作成 (API)」を参照してください。
自動データラベリングに使用するアルゴリズムの Amazon リソースネーム (ARN) を LabelingJobAlgorithmSpecificationArn パラメータに指定します。自動ラベル付けでサポートされている Ground Truth の 4 つの組み込みアルゴリズムから 1 つを選択します。
自動データラベリングジョブが終了すると、Ground Truth は自動データレベリングジョブで使用したモデルの ARN を返します。このモデルを同様の自動ラベル付けジョブタイプの開始モデルとして使用するには、この ARN の文字列形式を InitialActiveLearningModelArn パラメータで指定します。モデルの ARN を取得するには、次のような AWS Command Line Interface (AWS CLI) コマンドを使用します。
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
自動ラベル付けで使用される ML コンピューティングインスタンス (複数可) にアタッチされたストレージボリュームのデータを暗号化するには、 VolumeKmsKeyIdパラメータに AWS Key Management Service (AWS KMS) キーを含めます。KMS キーの詳細については、 AWS AWS 「 Key Management Service デベロッパーガイド」の「 Key Management Service とは」を参照してください。 AWS
CreateLabelingJob オペレーションを使用して自動データラベリングジョブを作成する例については、SageMaker AI ノートブックインスタンスの「SageMaker AI Examples, Ground Truth Labeling Jobs」セクションの object_detection_tutorial の例を参照してください。 SageMaker ノートブックインスタンスを作成して開く方法については、「Amazon SageMaker ノートブックインスタンスを作成する」を参照してください。SageMaker AI サンプルノートブックにアクセスする方法については、「」を参照してくださいサンプルノートブックにアクセスする。
自動データラベリングに必要な Amazon EC2 インスタンス
次の表は、トレーニングとバッチ推論ジョブのために自動データラベリングを実行するのに必要な Amazon Elastic Compute Cloud (Amazon EC2) インスタンスの一覧です。
| 自動データラベリングジョブタイプ | トレーニングインスタンスタイプ | 推論インスタンスタイプ |
|---|---|---|
|
イメージ分類 |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
オブジェクトの検出 (境界ボックス) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
テキスト分類 |
ml.c5.2xlarge |
ml.m4.xlarge |
|
セマンティックセグメンテーション |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* アジアパシフィック (Mumbai)リージョン (ap-south-1) では、代わりに ml.p2.8xlarge を使用します。
Ground Truth は、自動データラベリングジョブに使用するインスタンスを管理します。ジョブの実行に必要なインスタンスを作成、設定、および終了します。これらのインスタンスは、Amazon EC2 インスタンスダッシュボードには表示されません。
独自のモデルを使用してアクティブラーニングワークフローをセットアップする
独自のアルゴリズムを使用してアクティブラーニングワークフローを作成し、そのワークフローでトレーニングと推論を実行して、データを自動ラベル付けできます。ノートブック bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb は、SageMaker AI 組み込みアルゴリズム BlazingText を使用してこれを示しています。このノートブックには、このワークフローを実行するために使用できる AWS CloudFormation スタックが用意されています AWS Step Functions。ノートブックとサポートファイルは、GitHub リポジトリ
このノートブックは、SageMaker AI Examples リポジトリでも確認できます。Amazon SageMaker AI サンプルノートブックの検索方法については、「サンプルノートブックを使用する」を参照してください。
