準備
| GAMEOPS01 - ゲームのライブオペレーション (LiveOps) 戦略をどのようにして定義しますか? |
|---|
GAMEOPS_BP01: ゲームの目標とビジネスのパフォーマンスメトリクスを使用して、ライブオペレーション戦略を策定します。
ゲームの目的とパフォーマンスメトリクスを決定するには、ゲームプロデューサーやパブリッシングパートナーなどのビジネスステークホルダーに相談する必要があります。これにより、メンテナンスウィンドウ、ソフトウェアとインフラストラクチャの更新スケジュール、システムの信頼性と回復性の目標の定義など、ゲームの管理方法に関する計画を立てることができます。
例えば、プレイヤーの同時実行数 (CCU)、日次および月次のアクティブユーザーのターゲット数 (DAU/MAU)、インフラストラクチャ予算、財務目標のターゲットを定義したり、その他のパフォーマンスメトリクスとして、新しいコンテンツや機能のリリース頻度、ゲーム内イベントやプレイヤーエンゲージメントを高めるためのプロモーションの頻度などのターゲットを定義したりできます。これらの目標とメトリクスに基づいて、ゲーム設計、リリース管理、可観測性、効率的な運営に必要なサポートに関する意思決定を下すことができます。
ゲームに、少なくとも毎月 1 回は新しいコンテンツ更新をリリースし、リリース中にダウンタイムは発生させないという目標があるとします。この情報に基づいて、リリースのデプロイ戦略を定義し、ダウンタイムを必ず伴うメンテナンスを該当する月の他の時間帯にスケジュール調整して、可用性の SLA を達成できます。
これらのメトリクスは、ゲームのヘルスのモニタリング、直接的なゲームフィードバックの収集、合理化および自動化したリリースプロセスの構築を行うために、ゲームのライフサイクルのどの段階にライブオペレーションチーム (Live Ops) を関与させるかを判断するためにも役立ちます。例えば、新しいゲームの場合は、アクティブなプレイヤー数、収益、または別の一連のメトリクスに基づいて、ゲームが特定の規模に達したことを確認した後で、専任のライブオペレーションチームを編成する場合があります。体制が確立されているゲーム開発スタジオでは、以前のゲームでライブオペレーションを経験済みであるため、新しいゲームをオンボードするだけで済む場合があります。
GAMEOPS_BP02: 既存のゲームソフトウェアをゲームで再利用する前に検証およびテストします。
組織は、開発時間とコストを節約するために既存の (以前のゲームの) コンポーネントやソースコードを再利用する傾向があります。これらのレガシーコンポーネントやコードは、綿密なレビューや詳細な統合テストを受けていない可能性があり、代わりに過去のパフォーマンスに依存する場合があります。再利用は生産性の向上に役立ちますが、以前のパフォーマンスの問題や安定性の問題が新しいプロジェクトに引き継がれるリスクもあります。したがって、以前のゲームの既存のコンポーネントやソースコードを再利用する場合は、厳密なテストを実施する必要があります。
例えば、ゲーム A 向けに設計、作成、テストしたソースコードとコンポーネントをゲーム B で再利用すると、ゲーム B に要求される条件のすべては処理できない可能性があります。本番稼働環境でインシデントが発生した場合、デベロッパーにはそのコードやコンポーネントをデバッグして修正する十分な知識や作成し直す時間がないことがあり、オペレーションの問題を軽減できない場合があります。コードの原作者がいない場合、適切な修正を実装するのに時間がかかる可能性があります。以前に使用したコードやコンポーネントに問題があった場合は、再利用する前に優先事項として置換や修正を行います。オペレーションで再び問題が発生してから事後処理することは避けます。
| GAMEOPS02 - ゲーム環境をホストするためのアカウントはどのように構成しますか? |
|---|
GAMEOPS_BP03: マルチアカウント戦略を採用し、ゲームやアプリケーションごとに独自のアカウントに分離します。
AWS でデプロイするゲームアーキテクチャでは、複数のアカウントを論理的に整理して適切に分離できるようにします。これにより、問題の影響範囲を限定し、ゲームインフラストラクチャがスケールした際のオペレーションを簡素化できます。ゲームインフラストラクチャをホストする AWS アカウントは、通常、以下の論理環境にグループ化されます。
-
ゲーム開発環境 (Dev): デベロッパーがゲームのソフトウェアやシステムを開発するために使用します。
-
テストまたは QA 環境: 統合テスト、手動の品質保証 (QA)、他の必須の自動テストを実行するために使用します。
-
ステージングまたは本番稼働前環境: 最終ビルドのソフトウェアをホストするために使用し、本番稼働環境に移行する前に負荷テストとスモークテストを実施できるようにします。
-
ライブまたは本番稼働環境: ライブソフトウェアおよびインフラストラクチャをホストし、プレイヤーからの本番トラフィックを処理するために使用します。
-
共有サービスまたはツール環境: さまざまなチームが使用する共通のプラットフォーム、ソフトウェア、ツールにアクセスできます。例えば、中央のセルフホスト型ソース管理リポジトリやゲームビルドファームは、共有サービスアカウントでホストしている場合があります。
-
セキュリティ環境: クラウドセキュリティを重視するチームが使用する、一元化されたログとセキュリティのテクノロジーを統合するために使用します。
AWS のゲームインフラストラクチャでは、ゲーム環境ごと (開発、テスト、ステージング、本番稼働) に個別のアカウントを作成するとともに、セキュリティ、ログ記録、中央の共有サービス用のアカウントを作成することをお勧めします。
通常、限られた数のインフラストラクチャリソース (通常は数百台以下のサーバー) を管理する小規模なゲーム開発スタジオでは、1 つの本番稼働用アカウント、1 つの開発アカウント、1 つのステージングアカウントなど、環境ごとに 1 つの AWS アカウントを作成できます。ただし、ゲームのインフラストラクチャやチームの規模が時間の経過とともに大きくなると、この単純なモデルは適切にスケールできなくなる可能性があります。これらの環境を設定する場合は、特定のリージョン内のアカウント全体において、AWS の多くのサービスがリソースや API レベルの Service Quotas を共有することを考慮することが重要です。この点を考慮して、アカウントを論理的に整理する方法を決定する必要があります。AWS アカウントでは、アカウント内にデプロイしたサービスを使用した分だけに料金が発生します。したがって、これにより、リソースの競合と Service Quotas を効果的に削減できます。特にゲームが成長して、より多くのデベロッパーがリソースを構築および管理するためのアクセスを要求するようになった場合に効果的です。
AWS は、大規模なゲーム開発スタジオ (一般的に、数千のサーバーを運用し、数百人のデベロッパーがリソースにアクセスする) と協働した経験に基づいて、よりきめ細かいアカウント構造を設計し、ゲームをサポートするアプリケーションごとに独自の開発、テスト、ステージング、および本番稼働用アカウントを設定することをお勧めします。大規模で成功したゲームをサポートしてきた経験から、ゲームをリリースした後で AWS マルチアカウント戦略を再設計することは困難で時間がかかることがわかっています。ライブシステムの計画と移行は複雑であるためです。将来のスケーリングニーズを考慮した上で、適切なマルチアカウント構造を決定してください。
AWS Organizations
AWS Control Tower
このような分離により、ゲーム環境ごとにカスタムまたは個別の許可とガードレールを設定できます。本番稼働用アカウントにはすべての必要なガードレール、アクセス制限、モニタリングとアラート、セキュリティツールが備わっている必要があり、本番稼働用アカウント以外のアカウントには同じレベルのガードレールや許可は必要ない場合があります。本番稼働以外の環境は、営業時間後にリソースをシャットダウンしてコストを削減するように自動化できます。このレベルのきめ細かさでアカウントを分離すると、ゲームをサポートする環境ごとにインフラストラクチャコストをモニタリングしやすくなります。
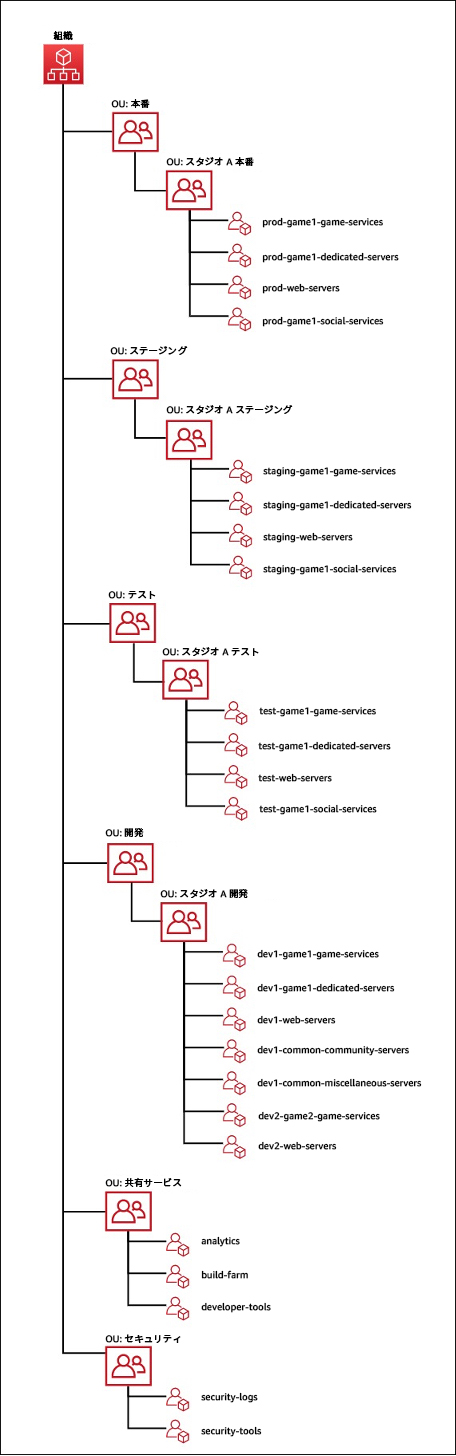
次の例は、AWS Organizations と組織単位 (OU) を使用して、AWS アカウントを個別の環境とスタジオに論理的にグループ化するゲーム会社のマルチアカウント構造を示しています。この例では、OU を使用して環境ごとにアカウントをグループ化し、次に環境を運用するスタジオごとにアカウントをグループ化しています。これは、ネスト階層を作成して、アプリケーションやゲームごとに独自のアカウントにデプロイできるようにする方法を示しています。この方法は、複数のゲームを開発して運用する場合に便利です。マルチアカウント戦略を整理するために検討できる追加の戦略については、この柱の「リソース」セクションに記載しているドキュメントとホワイトペーパーを参照してください。
GAMEOPS_BP04: リソースのタグ付けを使用してインフラストラクチャリソースを整理します。
効果的に インフラストラクチャリソース を AWS で管理および追跡するには、 リソースの適切なタグ付け と グループ化 を利用して各リソースの所有者、プロジェクト、アプリケーション、コストセンター、その他のデータを特定します。タグ付けしたリソースは、リソースグループを使用してグループ化すると、オペレーションのサポートに役立ちます。
ベストプラクティスとして、 タグ付けポリシーを定義する必要があります。一般的な戦略には、チーム名や個人名、ゲーム/アプリケーション/プロジェクトの名前、スタジオ名、環境 (開発、テスト、ステージング、本番稼働、共有など)、リソースのロール (データベースサーバー、ウェブサーバー、専用ゲームサーバー、アプリケーションサーバー、キャッシュサーバーなど) など、リソース所有者を特定するためのリソースタグがあります。任意のタグを追加して、ビジネスや IT のニーズに対応できます。AWS Config
| GAMEOPS03 - ゲームのデプロイはどのようにして管理しますか? |
|---|
GAMEOPS_BP05: プレイヤーへの影響を最小限に抑えるデプロイ戦略を採用します。
プレイヤーがゲームをプレイできないダウンタイムを最小限に抑えるような、ゲームのソフトウェアとインフラストラクチャのデプロイ戦略を組み込む必要があります。更新の種類によってはゲームクライアントに新しい更新をインストールする必要がありますが、ゲームバックエンドは、デプロイ中のダウンタイムを極力または完全になくすように設計する必要があります。
ゲームのデプロイ戦略を策定する際に考慮すべき最も重要なステップの 1 つは、ゲームインフラストラクチャの管理方法を決定することです。ゲームのインフラストラクチャを管理するベストプラクティスは、Infrastructure as Code (IaC) ツールを使用することです。例えば、 AWS CloudFormation
ゲームでは、以下のいくつかのデプロイ戦略を使用できます。
ローリング置換: デプロイのローリング置換の主な目的は、ゲームをシャットダウンしたり、プレイヤーに影響を与えたりすることなく、リソースを実行することです。実行するアップグレードや変更には下位互換性があること、およびシステムの以前のバージョンに隣接して動作することが重要です。
このデプロイでは、その名前が示すように、サーバーインスタンスが、更新バージョンを実行するインスタンスに段階的に入れ替わり (置換またはロールアウト) ます。このローリング置換は、いくつかの方法で実行できます。例えば、専用ゲームサーバーのフリートにローリング更新を実装するには、一般的な方法として、新しいゲームサーバービルドバージョンをデプロイしている EC2 インスタンスの新しい Auto Scaling グループを作成し、この新しいサーバーフリートでホストしているゲームセッションにプレイヤーを徐々にルーティングします。新しいゲームサーバービルドを使用する前提条件として、関連するゲームクライアント更新が必要である場合は、検証チェックを含めます。それにより、この新しいゲームクライアント更新をインストールしたプレイヤーのみを、これらのゲームセッションにルーティングできます。
サーバーフリート (EC2 Auto Scaling グループなど) に古いゲームサーバービルドバージョンが含まれている場合は、すべてのアクティブなプレイヤーセッションを適切な方法で終了した後でのみ、これらのフリートの稼働を停止できます。通常は、そのためにサーバーごとのメトリクスを設定し、ゲームオペレーションチームがこのプロセスを自動化できるようにします。また、ローリングデプロイを実行するためのインフラストラクチャと時間を削減するには、1 つの方法として、既存の本番インスタンスの稼働を停止し、新しいゲームサーバービルドで更新してから、本番フリートに戻します。この方法により、必要なインフラストラクチャの量は減りますが、サーバーを入れ替える際にプレイヤーが利用できるライブゲームサーバーの数が少なくなるため、リスクも増大します。
このモデルは、ゲームプレイをホストしないデータベース、キャッシュ、アプリケーションサーバーなどのバックエンドサービスに対してローリングデプロイを実行する際にも使用できます。クラスター化した複数のインスタンスを使用して可用性の高い方法でこれらのサービスをデプロイしている限り、これらのサービスへのデプロイは専用ゲームサーバーへのデプロイよりも複雑さが少ないはずです。
ブルー/グリーンデプロイ: ゲームでのブルー/グリーンデプロイの主な目的は、ダウンタイムを最小限に抑えながら、問題を特定した場合に、以前のデプロイに安全にロールバックできるようにすることです。このデプロイは、ゲームバックエンドの 2 つのバージョン間に互換性があり、同時にプレイヤーにサービスを提供できるようにする場合に適しています。ブルー/グリーンデプロイ戦略では、2 つの同じ環境 (ブルーとグリーン) を設定し、既存のゲームバージョンにはブルーというラベルを付け、デプロイ先である新しいゲームバージョンにはグリーンというラベルを付けます。グリーン環境で移行準備が整ったら、トラフィック先をグリーン環境に切り替えるようにルーティングレイヤーを設定できます。古い環境 (ブルー) は、フェイルバックが必要な場合に備えて、一定期間、使用可能な状態に保持します。このシナリオでは、ルーティングの更新に伴い、必要に応じてマッチメイキングサービスを更新してゲームセッションを新しいフリートに送信するように設定するか、ゲームバックエンドサービスの場合は、サービスの Route 53 の DNS レコードを更新するか、 Application Load Balancer の重み付けをシフト
ブルー/グリーンデプロイ戦略の欠点の 1 つは、デプロイの実行時にインフラストラクチャを追加する必要があるため、スタンバイ環境に必然的にコストが伴うことです。この追加のインフラストラクチャコストを軽減するには、ブルー/グリーンデプロイのバリエーションとして、本番稼働環境にデプロイ済みの同じサーバーに新しいゲームソフトウェアをデプロイすることを検討します。このシナリオでは、既存のブルーサーバープロセスと並行して新しいグリーンサーバープロセスで新しいソフトウェアを開始できます。カットオーバーは、完全に分離した物理インフラストラクチャ間ではなく、サーバープロセス間で発生します。また、このアプローチでは、クラウドで新しいサーバーが起動するまで待つ必要がないため、大量のインフラストラクチャ全体にわたってゲームのデプロイを高速化できます。このデプロイアプローチのベストプラクティスの詳細については、 AWS でのブルー/グリーンデプロイ のホワイトペーパーを参照してください。
canary デプロイメント: canary デプロイメントは、ゲームの初期のアルファ/ベータビルドや、新しいゲームモード/マップ/チャレンジなどのゲーム機能を、本稼働環境内の特定または少数のプレイヤーにリリースするために適用できるという点で、ゲームデベロッパーに特に役立つ戦略です。このようなデプロイを canary と呼びます。リリースに追跡やレポートの機能を追加すると、実際のプレイヤーが該当するゲームや機能をプレイしたときに、ゲームプレイのテレメトリを収集し、異常や問題がないか分析できます。新機能の場合は、これを該当するプレイヤーに常に通知するわけではなく、プレイヤーに問題が発生しているかどうか、リリースをロールバックする必要があるかどうかを判断するには、ゲームテレメトリが主な情報源となります。同時に、重大な問題が特定されなければ、この機能をさらに多くのプレイヤーにロールアウトして追加のデータを収集できます。プレイヤーに通知する場合は、プレイヤーエクスペリエンスに関する定期的なフィードバックを提供するよう依頼できます。このようなテストアクティビティは、ライブオペレーションチームが調整するのが最適です。
戦略として、canary デプロイメントを標準リリースにも使用して、新しい機能を徐々にプレイヤーに利用してもらうこともできます。標準のブルー/グリーン環境に優る潜在的な利点は、フルスケールの第 2 環境を設定する必要がないことです。新しいスケールダウンした環境の容量によって、新機能にオンボードするプレイヤーの数が決まります。より多くのプレイヤーを追加する前に、容量を適切にスケールする必要があります。このカスタマイズしたブルー/グリーン手法が標準のブルー/グリーンよりもコスト安であるとしても、canary デプロイメントのローリング置換手法よりは多くのコストが発生すると推定されます。
本番稼働環境で canary を 1 つだけ実行し、その目的をデータとフィードバックに絞ることをお勧めします。複数の canary をデプロイすると、本番稼働環境でのトラブルシューティングと問題の切り分けが複雑になり、収集するデータセットとフィードバックの品質が損なわれます。
canary のバリエーションとして、1 つ以上の実験 (通常は UI テスト) をターゲットデプロイを介して実行します。その際、1 式のゲームバックエンドサーバーで 1 つのバージョンの機能を提供し、同様のサイズの別の 1 式で同じ機能の別のバージョンを提供します。この場合、追加のインフラストラクチャや特殊なインフラストラクチャのスピンアップはなく、選択したバックエンドサーバーだけがこれらの更新を受け取ります。実験の結果として、同じ機能の各バージョンに対するプレイヤーの反応と、全体的に好評か不評かという統一した見解が見られるかを観察したり、使いやすさや機能に問題がないかどうかなど、その他の想定していた結果を確認したりします。このような戦略的実験は A/B テストとも呼ばれます。このプロセス全体は A/B テスティングと呼ばれます。これらの実験が完了したら、必要なテストデータを収集した後で、テストに使用したサーバー上のゲームバックエンドシステムを現行バージョンに戻します。
従来のレガシーデプロイ: 従来のスタイルのデプロイでは、スケジュールしたメンテナンスウィンドウ中にゲームをシャットダウンし、接続しているすべてのプレイヤーをドロップまたはドレインした後で、ゲームバックエンド内のすべてのサーバーインスタンスを最新のコードビルドで更新します。このデプロイは、実行するたびにすべてのプレイヤーに影響するため、スケジュールに先立ってプレイヤーに通知する必要があります。結果として、このモデルはプレイヤーに最も大きな影響を与えるため、できる限り避けてください。ゲームの更新をデプロイした後で、ゲームの再開を待っているプレイヤーにゲームを開放する前に、ゲームのスモークテストを行うことができます。この場合、すべてのプレイヤーが短時間内にログインしてプレイしようとすると、トラフィックが急増する可能性があります。したがって、このようなトラフィックの急増を処理するようにゲームを設計していない場合は、プレイヤーをバッチに分けて徐々にゲームに戻すことができます。別の方法としては、開始時のトラフィックの急増に耐えられるようにインフラストラクチャをオーバープロビジョニングします。最終的にゲームのトラフィックが落ち着いたら、リソースをスケールダウンできます。このタイプのデプロイは、プレイヤー数が最も少ないオフピーク時に実施することをお勧めします。メンテナンスを頻繁にスケジュールしたり、時間を長くしたりすると、プレイヤー数や収益の減少につながるリスクがあります。また、プレイヤーは新しいリリース後に変更を期待するため、一定期間のダウンタイム後に戻ったときに変更がなければ、ゲームへの信頼を失うおそれがあります。
GAMEOPS_BP06: ピーク時の要件をサポートするために必要なインフラストラクチャを事前にスケールします。
大規模なゲームイベントに先立ってインフラストラクチャをスケールし、プレイヤーの需要の急増に対応できるようにする必要があります。
ライブゲームでは、新しいゲームのリリースに加えて、プレイヤーのエンゲージメントを維持し向上させる方法として、一般的にゲーム内イベント、プロモーション、新規コンテンツ、シーズンリリースなどを行います。このようなアクティビティでは、イベントやプロモーションの期間中に、プレイヤーのトラフィックが大量に発生します。ビジネスでは、イベントの意図した目標を達成するか上回ることを期待しており、ゲームインフラストラクチャは、イベント期間中の大量のトラフィックに耐えてサポートする必要があります。大規模なイベント中に予想されるプレイヤーロードをサポートできるように、事前にインフラストラクチャを準備することが重要です。準備として、ゲームオペレーションチームはセールスおよびマーケティングのステークホルダーと連携し、過去のプレイヤーの同時実行数、エンゲージメントメトリクス、セールスデータを調べて、予定のイベントで発生する予測需要を見積もる必要があります。新しいゲームのリリースを目的としたイベントの場合、ゲームオペレーションチームはこれらのステークホルダーと協力し、予測需要の規模を現実的に特定する必要があります。ゲームがどの程度の成功を達成するか予測するのは難しい場合がありますが、成功の期待値を全員が理解し、この期待値の目標をサポートできるようにインフラストラクチャをスケールおよびテストすることが重要です。
多くのゲームは、いくつかのステージを経てリリースします。ゲームを少数のプレイヤーに公開するソフトローンチから始まり、各ステージでプレイヤー数を有機的にスケールしながら、最終的に完全に一般公開します。ソフトローンチ期間中に問題をモニタリング、特定、追跡、解決するとともに、一般公開に向けて予測を調整することをお勧めします。
インフラストラクチャ要件を適切に見積もるには、ゲームをリリースする前に、本番稼働環境またはこれと似たステージング環境で実行しているゲームバックエンドに対してロードテストやパフォーマンステストを実行し、データを収集する必要があります。これらのテストは複数回実施し、ゲームのさまざまな状況をシミュレートして、バックエンドがあらゆる状況下でロードに耐えられることを検証します。デベロッパーは、これを実現するためにゲームプレイボットを記述して、ゲーム内のさまざまなワークフローを走査し、各種の状況をエミュレートできます。これらのテストでは、ゲームバックエンドのさまざまなシステムレイヤーをすべて検査し、各レイヤーやコンポーネントをテストして詳細を記録することが不可欠です。これらのテストから収集したデータは、ゲームのリリース時のプロビジョン計画に使用します。
アプリケーションの可用性と耐障害性を高めることで、単一障害点 (SPOF) をできる限り排除する必要があります。ロードテストを使用して、アップストリームとダウンストリームのさまざまなレイヤーで障害をエミュレートし、ゲームやその他のコンポーネントの動作を検証することで、SPOF を検出します。
ゲームのリリース、ゲーム内イベント、プロモーションの準備に必要と推定されたインフラストラクチャをプロビジョニングすることに加えて、オンデマンドで自動的にスケールするようにシステムを設定します。スケーリングイベントのしきい値を定義、設定、モニタリングし、ゲームバックエンドをスケールして大量のプレイヤートラフィックに耐えられるようにする必要があります。トラフィックが変動する場合は、スケールアウトする時間が十分にない場合があるため、事前プロビジョニングが最適です。ゲームの初回リリース時には、予想を超える需要が発生して、自動システムによるリソースのスケーリングでは間に合わない場合があり、手動スケーリングが必要になることがあります。
AWS では、組織はゲームバックエンドで使用するサービスに対して、より高い Service Quotas をリクエストする必要があります。Service Quotas は、すべてのアカウントに対して設定し、意図した以上のインフラストラクチャをお客様が不注意で起動したり、スケールしたりするのを防ぎます。クォータを引き上げても、追加のリソースを消費するまではコストが発生しません。アカウントで実行しているゲームが、そのリージョンに設定されているサービスクォータの上限に達すると、プロビジョニングしたクォータを超えるすべてのリクエストおよびバーストしたプロビジョンは、サービスによってスロットリングされます。スロットリングは、意図しないエラーや予期しないエラーを引き起こし、プレイヤーエクスペリエンスを損なう可能性があります。スロットリングを回避するには、本番稼働中のゲームで使用するすべてのサービスについてサービスクォータのしきい値をモニタリングおよび追跡し、定期的に確認することが重要です。使用量が許容可能なサービスクォータのしきい値を超えた場合は、コンソールサポートセンターから サポートケース を作成することで、クォータの引き上げをリクエストできます。最初に該当するアカウントにログインするか、 Support API を使用する必要があります。
ゲームを Amazon GameLift Servers でホストして立ち上げる場合は、 リリース前のチェックリスト を確認して準備してください。
GAMEOPS_BP07: プレイヤーの行動をシミュレートして、リリース前にパフォーマンスエンジニアリングおよびロードテストを実施します。
リリースに向けて準備するには、インフラストラクチャに対して大規模にテストできるゲームプレイシミュレーションを開発し、ピーク時の使用量要件を満たすようにスケールできることを確認します。
パフォーマンスエンジニアリングとは、アプリケーションの複数の重要な運用メトリクスをモニタリングして、アプリケーションのパフォーマンスをさらに改善できる最適化の機会を発見するプロセスです。これは、コード、その依存関係、関連プロセス、ホストオペレーティングシステム、基盤となるインフラストラクチャを最初にテストし、次にこれらを最適化する反復プロセスです。
アプリケーションのパフォーマンスをより詳細に分析するには、アプリケーションパフォーマンスモニタリング (APM) またはデバッグツールをアプリケーションコードに統合することをお勧めします。これにより、アプリケーションのすべてのフローにわたってアプリケーションの動作に関して異常を追跡し、問題を切り分け、トラブルシューティング時間を短縮できます。APM ツールでパフォーマンスの遅いメソッドや外部操作を特定することもできます。
AWS X-Ray
人為的なプレイヤートラフィックをシミュレートするには、ボットが必要です。このポットを使用して、ゲームクライアントのフローをエミュレートし、ゲームバックエンドとやり取りして実際のプレイヤーの行動をシミュレートします。通常、このデータは、ゲームプレイのログと人間が実施した QA テストで生成したデータから取得します。または、現実世界の小規模なアルファテストやベータテストに実際のプレイヤーを招待してゲームをプレイしてもらうことで生成したデータから取得します。
また、ロードテストを実行し、これら各種のロードテスト中にさまざまな種類の障害をゲームバックエンドに挿入して、各障害に対してシステムがどのように動作するかを確認することをお勧めします。将来発生する可能性がある障害のトラブルシューティングに役立てるために、システムの動作をオペレーションランブックに記録することが重要です。ロードテスト中に人間のテスターにゲームをテストしてもらう環境は、ロードテストを行っているのと同じ環境である必要があります。人間は、ロードテスト中にボットや他のメトリクスでは検出できないものを発見できます。
ゲームのリリース、主要なゲーム内イベントやプロモーションなど、重要なイベントには、
AWS インフラストラクチャイベント管理 (IEM)
AWS Fault Injection Simulator
