기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
GraphQL 스키마 설계GraphQL 스키마는 모든 GraphQL 서버 구현의 기초입니다. 각 GraphQL API는 요청의 데이터가 채워지는 방식을 설명하는 유형과 필드를 포함하는 단일 스키마로 정의됩니다. API를 통한 데이터 흐름과 수행되는 작업은 스키마를 기준으로 검증되어야 합니다.
GraphQL 유형 시스템은 일반적으로 GraphQL 서버의 기능을 기술하고 쿼리가 유효한지 확인하는 데 사용됩니다. 서버의 유형 시스템은 종종 해당 서버의 스키마라고 하며 다양한 객체 유형, 스칼라 유형, 입력 유형 등으로 구성될 수 있습니다. GraphQL은 선언적이면서 강력한 유형입니다. 즉, 유형은 런타임에 잘 정의되고 지정된 값만 반환합니다.
AWS AppSync 를 사용하면 GraphQL 스키마를 정의하고 구성할 수 있습니다. 다음 섹션에서는 AWS AppSync의 서비스를 사용하여 GraphQL 스키마를 처음부터 생성하는 방법을 설명합니다.
GraphQL 스키마 구조화
계속하기 전에 스키마 섹션을 검토하는 것이 좋습니다.
GraphQL은 API 서비스를 구현하기 위한 강력한 도구입니다. GraphQL의 웹 사이트에서는 GraphQL을 다음과 같이 기술합니다.
“GraphQL은 API용 쿼리 언어이자 기존 데이터로 이러한 쿼리를 수행하기 위한 런타임입니다. GraphQL은 API의 데이터에 대한 완전하고 이해하기 쉬운 설명을 제공하고, 클라이언트가 필요한 사항과 더 이상 필요하지 않은 사항을 정확히 요청할 수 있는 기능을 제공하며, 시간이 지남에 따라 API를 더 쉽게 발전시킬 수 있게 하고, 강력한 개발자 도구를 사용할 수 있도록 합니다.”
이 섹션에서는 GraphQL 구현의 맨 첫 부분인 스키마를 다룹니다. 위의 인용문에 따르면 스키마는 'API의 데이터에 대한 완전하고 이해하기 쉬운 설명을 제공'하는 역할을 합니다. 즉, GraphQL 스키마는 서비스의 데이터, 작업 및 작업 간의 관계를 텍스트로 표현한 것입니다. 스키마는 GraphQL 서비스 구현을 위한 기본 진입점으로 간주됩니다. 당연하게도 스키마는 프로젝트에서 가장 먼저 만드는 항목 중 하나인 경우가 많습니다. 계속하기 전에 스키마 섹션을 검토하는 것이 좋습니다.
스키마 섹션을 인용하자면 GraphQL 스키마는 스키마 정의 언어(SDL)로 작성됩니다. SDL은 구조가 확립된 유형과 필드로 구성되어 있습니다.
-
유형: 유형은 GraphQL이 데이터의 형태와 동작을 정의하는 방식입니다. GraphQL은 이 섹션의 뒷부분에서 설명할 여러 유형을 지원합니다. 스키마에 정의된 각 유형에는 고유한 범위가 포함됩니다. 범위 내에는 GraphQL 서비스에서 사용할 값이나 로직을 포함할 수 있는 하나 이상의 필드가 있습니다. 유형은 다양한 역할을 수행하며, 가장 일반적으로는 객체 또는 스칼라(기본 값 유형) 역할을 합니다.
-
필드: 필드는 유형의 범위 내에 존재하며 GraphQL 서비스에서 요청한 값을 보유합니다. 이는 다른 프로그래밍 언어의 변수와 매우 유사합니다. 필드에 정의하는 데이터의 형태에 따라 요청/응답 작업에서 데이터가 구조화되는 방식이 결정됩니다. 이를 통해 개발자는 서비스의 백엔드가 구현되는 방식을 모르더라도 어떤 결과가 반환될지 예측할 수 있습니다.
가장 간단한 스키마에는 다음과 같은 세 가지 데이터 범주가 포함됩니다.
-
스키마 루트: 루트는 스키마의 진입점을 정의합니다. 또한 추가, 삭제, 수정과 같은 데이터에 대한 일부 작업을 수행할 필드를 가리킵니다.
-
유형: 데이터의 형태를 나타내는 데 사용되는 기본 유형입니다. 주로 정의된 특성을 가진 대상의 객체나 추상적 표현으로 생각할 수 있습니다. 예를 들어, 데이터베이스에 있는 사람을 나타내는 Person 객체를 만들 수 있습니다. 각 개인의 특성은 Person 내에 필드로 정의됩니다. 개인의 이름, 나이, 직업, 주소 등 무엇이든 될 수 있습니다.
-
특수 객체 유형: 스키마의 작업 동작을 정의하는 유형입니다. 각 특수 객체 유형은 스키마별로 한 번씩 정의됩니다. 먼저 스키마 루트에 배치된 다음 스키마 본문에 정의됩니다. 특수 객체 유형의 각 필드는 해석기가 구현할 단일 작업을 정의합니다.
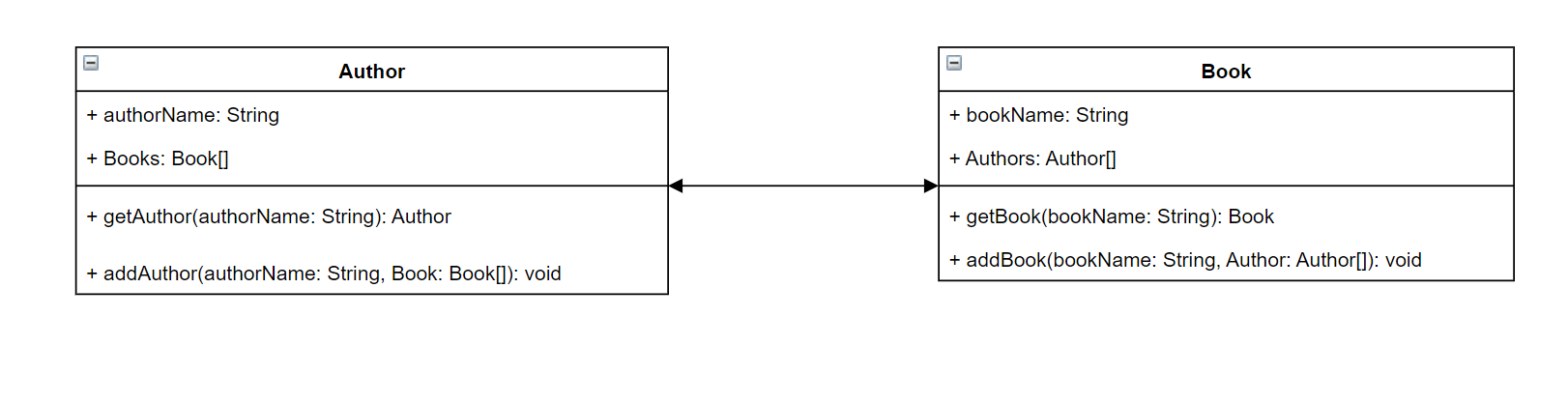
이 개념을 잘 이해하기 위해 저자와 저자가 쓴 책을 저장하는 서비스를 만든다고 가정해 보세요. 저자마다 이름이 있고 저술한 책도 여러 권 있습니다. 각 책에는 이름과 관련 저자 목록이 있습니다. 또한 책과 저자를 추가하거나 검색할 수 있는 기능도 필요합니다. 이 관계를 간단한 UML로 표현하면 다음과 같을 수 있습니다.
GraphQL에서 Author 및 Book 엔터티는 스키마의 서로 다른 두 가지 객체 유형을 나타냅니다.
type Author {
}
type Book {
}
Author는 authorName과 Books를 포함하는 반면, Book은 bookName과 Authors를 포함합니다. 이러한 유형은 유형 범위 내의 필드로 표시될 수 있습니다.
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
보는 것과 같이 유형 표현은 다이어그램과 매우 비슷합니다. 하지만 메서드의 경우 조금 더 까다로워집니다. 메서드는 몇 가지 특수 객체 유형 중 하나에 필드로 배치됩니다. 특수 객체 분류는 동작에 따라 결정됩니다. GraphQL에는 쿼리, 변형, 구독이라는 세 가지 기본 특수 객체 유형이 포함되어 있습니다. 자세한 내용은 특수 객체를 참조하세요.
getAuthor와 getBook 둘 다 데이터를 요청하므로 다음과 같은 Query 특수 객체 유형에 배치됩니다.
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
작업은 쿼리에 연결되며, 쿼리 자체는 스키마에 연결됩니다. 스키마 루트를 추가하면 특수 객체 유형(이 경우 Query)이 진입점 중 하나로 정의됩니다. 다음과 같은 schema 키워드를 사용하여 수행할 수 있습니다.
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
마지막 두 메서드를 살펴보면 addAuthor 및 addBook은 데이터베이스에 데이터를 추가하고 있으므로 Mutation 특수 객체 유형에 정의됩니다. 그러나 유형 페이지를 보면 객체를 직접 참조하는 입력은 엄밀히는 출력 유형이기 때문에 허용되지 않는다는 사실도 알 수 있습니다. 이 경우에는 Author 또는 Book을 사용할 수 없으므로 동일한 필드로 입력 유형을 만들어야 합니다. 이 예제에서는 AuthorInput 및 BookInput을 추가했는데, 둘 다 해당 유형의 동일한 필드를 수락합니다. 그런 다음 입력값을 파라미터로 사용하여 변형을 생성합니다.
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
방금 수행한 단계를 다시 살펴보겠습니다.
-
엔터티를 나타내는 Book 및 Author 유형을 사용하여 스키마를 만들었습니다.
-
엔터티의 특성이 포함된 필드를 추가했습니다.
-
데이터베이스에서 이 정보를 검색하는 쿼리를 추가했습니다.
-
데이터베이스의 데이터를 조작하기 위해 변형을 추가했습니다.
-
GraphQL의 규칙을 준수하기 위해 변형의 객체 파라미터를 대체하는 입력 유형을 추가했습니다.
-
GraphQL 구현이 루트 유형 위치를 이해할 수 있도록 루트 스키마에 쿼리와 변형을 추가했습니다.
보는 것과 같이 스키마를 생성하는 프로세스는 일반적으로 데이터 모델링(특히 데이터베이스 모델링)으로부터 많은 개념을 가져옵니다. 스키마는 원본의 데이터 형태와 맞는 것으로 생각할 수 있습니다. 또한 해석기가 구현할 모델 역할도 합니다. 다음 단원에서는 다양한 AWS지원 도구 및 서비스를 사용하여 스키마를 만드는 방법을 알아봅니다.
다음 섹션의 예제는 실제 애플리케이션에서 실행하도록 설계된 것이 아닙니다. 직접 애플리케이션을 빌드할 수 있도록 명령을 보여 주기 위한 용도로만 제공됩니다.
스키마 생성
스키마는 라는 파일에 있습니다schema.graphql. AWS AppSync를 사용하면 다양한 방법을 사용하여 GraphQL APIs에 대한 새 스키마를 생성할 수 있습니다. 이 예에서는 빈 스키마와 함께 빈 API를 생성해 보겠습니다.
- Console
-
-
에 로그인 AWS Management Console 하고 AppSync 콘솔을 엽니다.
-
대시보드에서 API 생성을 선택합니다.
-
API 옵션에서 GraphQL API, 처음부터 설계, 다음을 차례로 선택합니다.
-
API 이름의 경우 미리 채워진 이름을 애플리케이션에 필요한 이름으로 변경합니다.
-
연락처 세부 정보에는 API 관리자를 식별할 연락처를 입력하면 됩니다. 이 필드는 선택 사항입니다.
-
프라이빗 API 구성에서 프라이빗 API 기능을 활성화할 수 있습니다. 프라이빗 API는 구성된 VPC 엔드포인트(VPCE)에서만 액세스할 수 있습니다. 자세한 내용은 프라이빗 API를 참조하세요.
이 예에서는 이 기능을 활성화하지 않는 것이 좋습니다. 입력 내용을 검토한 후 다음을 선택합니다.
-
GraphQL 유형 생성에서 데이터 소스로 사용할 DynamoDB 테이블을 생성할지, 아니면 이 단계를 건너뛰고 나중에 생성할지 선택할 수 있습니다.
이 예제에서는 나중에 GraphQL 리소스 생성을 선택합니다. 별도의 섹션에서 리소스를 생성할 것입니다.
-
입력 내용을 검토한 다음 API 생성을 선택합니다.
-
특정 API의 대시보드로 이동하게 됩니다. API 이름은 대시보드 상단에 표시되므로 알아볼 수 있습니다. 그렇지 않은 경우 사이드바에서 API를 선택한 다음 API 대시보드에서 API를 선택하면 됩니다.
-
API 이름 아래에 있는 사이드바에서 스키마를 선택합니다.
-
스키마 편집기에서 schema.graphql 파일을 구성할 수 있습니다. 파일이 비어 있거나 모델에서 생성된 유형으로 채워져 있을 수 있습니다. 오른쪽에는 스키마 필드에 해석기를 연결할 수 있는 해석기 섹션이 있습니다. 이 섹션에서는 해석기는 살펴보지 않겠습니다.
- CLI
-
CLI를 사용하는 경우 서비스에서 리소스에 액세스하고 리소스를 생성할 수 있는 올바른 권한이 있어야 합니다. 서비스에 액세스해야 하는 관리자가 아닌 사용자를 위해 최소 권한 정책을 설정할 수도 있습니다. AWS AppSync 정책에 대한 자세한 내용은 의 ID 및 액세스 관리를 참조하세요 AWS AppSync.
또한 아직 읽어보지 않은 경우 먼저 콘솔 버전을 읽어보시기 바랍니다.
-
아직 완료하지 않았다면 AWS
CLI를 설치한 다음 구성을 추가합니다.
-
create-graphql-api 명령을 실행하여 GraphQL API 객체를 생성합니다.
이 특정 명령에 대해 두 개의 파라미터를 입력해야 합니다.
-
API의 name.
-
authentication-type 또는 API에 액세스하는 데 사용되는 보안 인증 유형(IAM, OIDC 등)
필수로 구성해야 하지만 일반적으로 CLI 구성 값으로 기본 설정되는 Region과 같은 다른 파라미터도 있습니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
기존 스키마를 가져와 base-64 blob을 사용하여 AWS AppSync 서비스에 업로드하는 선택적 명령입니다. 이 예제에서는 이 명령을 사용하지 않을 것입니다.
start-schema-creation 명령을 실행합니다.
이 특정 명령에 대해 두 개의 파라미터를 입력해야 합니다.
-
이전 단계의 api-id입니다.
-
definition 스키마는 base-64로 인코딩된 바이너리 blob입니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
출력이 반환됩니다.
{
"status": "PROCESSING"
}
이 명령은 처리 후 최종 출력을 반환하지 않습니다. 결과를 보려면 별도의 명령인 get-schema-creation-status를 사용해야 합니다. 참고로 이 두 명령은 비동기식이므로 스키마를 생성하는 중에도 출력 상태를 확인할 수 있습니다.
- CDK
-
CDK를 사용하기 전에 CDK의 공식 설명서를 CDK 참조와 함께 검토 AWS AppSync하는 것이 좋습니다.
아래 나열된 단계는 특정 리소스를 추가하는 데 사용되는 스니펫의 일반적인 예시만 보여줍니다. 프로덕션 코드에서는 이 예시가 올바르게 작동하는 솔루션이 아닙니다. 또한 이미 작동하는 앱을 가지고 있는 것으로 가정합니다.
-
CDK의 시작점은 약간 다릅니다. 이상적으로는 schema.graphql 파일이 이미 생성되어 있어야 합니다. .graphql 파일 확장자가 있는 새 파일을 생성하기만 하면 됩니다. 빈 파일이어도 괜찮습니다.
-
대개는 사용 중인 서비스에 가져오기 지침을 추가해야 할 수 있습니다. 예를 들면 다음 형식을 따를 수 있습니다.
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
GraphQL API를 추가하려면 스택 파일이 AWS AppSync 서비스를 가져와야 합니다.
import * as appsync from 'aws-cdk-lib/aws-appsync';
즉, appsync 키워드로 전체 서비스를 가져오게 됩니다. 앱에서 이를 사용하기 위해 AWS AppSync 구문은 형식을 사용합니다appsync.construct_name. 예를 들어, GraphQL API를 만들고 싶다면 new appsync.GraphqlApi(args_go_here)를 사용할 수 있습니다. 다음 단계에서는 이 과정을 설명합니다.
-
가장 기본적인 GraphQL API에는 API의 name 및 schema 경로가 포함됩니다.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
이 스니펫이 어떤 역할을 하는지 살펴보겠습니다. api의 범위 내에서 appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps)를 호출하여 새로운 GraphQL API를 만들고 있습니다. 범위는 this이며, 현재 객체를 참조합니다. id는 API_ID이며, 생성 AWS CloudFormation 시에서 GraphQL API의 리소스 이름이 됩니다. GraphqlApiProps에는 GraphQL API의 name 및 schema가 포함되어 있습니다. schema는 .graphql 파일(schema_name.graphql)의 절대 경로(__dirname)를 검색하여 스키마(SchemaFile.fromAsset)를 생성합니다. 실제 시나리오에서는 스키마 파일이 CDK 앱 내에 있을 수 있습니다.
GraphQL API에서 변경한 내용을 사용하려면 앱을 재배포해야 합니다.
스키마에 유형 추가
이제 스키마를 추가했으니 입력 유형과 출력 유형을 모두 추가할 수 있습니다. 참고로 여기에 있는 유형은 실제 코드에서 사용해서는 안 됩니다. 프로세스 이해를 돕기 위한 예시일 뿐입니다.
먼저 객체 유형을 생성하겠습니다. 실제 코드에서는 이러한 유형으로 시작할 필요가 없습니다. GraphQL의 규칙과 구문만 따르면 언제든지 원하는 유형을 만들 수 있습니다.
다음 몇 개의 섹션에서 스키마 편집기를 사용할 예정이니 계속 열어 두세요.
- Console
-
-
유형 이름과 함께 type 키워드를 사용하여 객체 유형을 생성할 수 있습니다.
type Type_Name_Goes_Here {}
유형의 범위 내에 객체의 특성을 나타내는 필드를 추가할 수 있습니다.
type Type_Name_Goes_Here {
# Add fields here
}
다음은 그 예입니다.
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
이 단계에서는 필수 id 필드는 ID로, title 필드는 String으로, date 필드는 AWSDateTime으로 저장되는 일반 객체 유형을 추가했습니다. 유형 및 필드의 목록과 그 역할을 보려면 스키마를 참조하세요. 스칼라 목록과 그 역할을 보려면 유형 참조를 참조하세요.
- CLI
-
아직 읽어보지 않은 경우 먼저 콘솔 버전을 읽어보시기 바랍니다.
-
create-type 명령을 실행하여 객체 유형을 만들 수 있습니다.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
이 단계에서는 필수 id 필드는 ID로, title 필드는 String으로, date 필드는 AWSDateTime으로 저장되는 일반 객체 유형을 추가했습니다. 유형 및 필드의 목록과 그 역할을 보려면 스키마를 참조하세요. 스칼라 목록과 그 역할을 보려면 유형 참조를 참조하세요.
추가로 설명하자면, 정의를 직접 입력하는 것은 크기가 작은 유형에서는 효과적이지만, 크기가 크거나 여러 개인 유형에는 적합하지 않다는 사실을 확인하셨을 수 있습니다. .graphql 파일에 모든 유형을 추가한 다음 입력으로 전달하도록 선택할 수 있습니다.
- CDK
-
CDK를 사용하기 전에 CDK의 공식 설명서와 CDK 참조를 검토 AWS AppSync하는 것이 좋습니다.
아래 나열된 단계는 특정 리소스를 추가하는 데 사용되는 스니펫의 일반적인 예시만 보여줍니다. 프로덕션 코드에서는 이 예시가 올바르게 작동하는 솔루션이 아닙니다. 또한 이미 작동하는 앱을 가지고 있는 것으로 가정합니다.
유형을 추가하려면 .graphql 파일에 추가해야 합니다. 예를 들어 콘솔 예시에서는 다음과 같았습니다.
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
다른 파일처럼 스키마에 유형을 직접 추가할 수 있습니다.
GraphQL API에서 변경한 내용을 사용하려면 앱을 재배포해야 합니다.
객체 유형에는 문자열 및 정수와 같은 스칼라 유형인 필드가 있습니다. AWS AppSync를 사용하면 기본 GraphQL 스칼라 AWSDateTime 외에도와 같은 향상된 스칼라 유형을 사용할 수도 있습니다. 또한 느낌표로 끝나는 모든 필드는 필수 필드입니다.
특히 ID 스칼라 유형은 String 또는 Int인 고유한 식별자입니다. 자동 할당을 위해 해석기 코드에서 이러한 유형을 제어할 수 있습니다.
Query와 같은 특수 객체 유형과 위의 예와 같은 '일반' 객체 유형 간에는 모두 type 키워드를 사용하고 객체로 간주된다는 점에서 유사점이 있습니다. 하지만 특수 객체 유형(Query, Mutation, Subscription)의 경우 API의 진입점으로 노출되므로 동작은 크게 다릅니다. 또한 데이터보다는 작업의 형태를 잡는 데 더 중점을 둡니다. 자세한 내용은 쿼리 및 변형 유형을 참조하세요.
특수 객체 유형의 경우 다음 단계는 형상화된 데이터에 대한 작업을 수행하기 위해 하나 이상의 유형을 추가하는 것일 수 있습니다. 실제 시나리오에서 모든 GraphQL 스키마에는 데이터 요청을 위한 루트 쿼리 유형이 반드시 있어야 합니다. 쿼리는 GraphQL 서버의 진입점(또는 엔드포인트) 중 하나로 생각할 수 있습니다. 쿼리를 예로 추가해 보겠습니다.
- Console
-
-
쿼리를 만들려면 다른 유형과 마찬가지로 스키마 파일에 추가하기만 하면 됩니다. 쿼리에는 다음과 같이 루트에 Query 유형 및 항목이 필요합니다.
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
참고로 프로덕션 환경에서는 Name_of_Query를 대부분의 경우 단순히 Query라고 합니다. 이 값을 유지하는 것이 좋습니다. 쿼리 유형 내에서 필드를 추가할 수 있습니다. 각 필드는 요청에서 작업을 수행합니다. 따라서 전부는 아니더라도 대부분의 필드가 해석기에 연결됩니다. 하지만 이 섹션에서는 신경 쓰지 않습니다. 필드 작업의 형식과 관련해서는 다음과 같을 수 있습니다.
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
다음은 그 예입니다.
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
이 단계에서는 Query 유형을 추가하고 schema 루트에 정의했습니다. Query 유형은 Obj_Type_1 객체 목록을 반환하는 getObj 필드를 정의했습니다. 참고로 Obj_Type_1은 이전 단계의 객체입니다. 프로덕션 코드에서는 일반적으로 Obj_Type_1과 같은 객체로 형태가 지정된 데이터를 사용하여 필드 작업을 수행하게 됩니다. 또한 getObj와 같은 필드에는 일반적으로 비즈니스 로직을 수행하는 해석기가 있습니다. 이 내용은 다른 섹션에서 다룰 예정입니다.
참고로는 내보내기 중에 스키마 루트를 AWS AppSync 자동으로 추가하므로 기술적으로 스키마에 직접 추가할 필요가 없습니다. 본 서비스는 중복 스키마를 자동으로 처리합니다. 이 내용은 여기에 모범 사례로 추가하겠습니다.
- CLI
-
아직 읽어보지 않은 경우 먼저 콘솔 버전을 읽어보시기 바랍니다.
-
create-type 명령을 실행하여 query 정의가 있는 schema 루트를 생성합니다.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
schema {
query: Query
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
create-type 명령에 내용을 올바르게 입력하지 않은 경우 update-type 명령을 실행하여 스키마 루트(또는 스키마의 모든 유형)를 업데이트할 수 있습니다. 이 예에서는 subscription 정의를 포함하도록 스키마 루트를 일시적으로 변경해 보겠습니다.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
유형의 type-name. 콘솔 예제에서는 schema였습니다.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
schema {
query: Query
}
subscription을 추가한 후의 스키마는 다음과 같습니다.
schema {
query: Query
subscription: Subscription
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
이 예제에서는 미리 형식이 지정된 파일을 추가해도 여전히 작동합니다.
-
create-type 명령을 실행하여 Query 유형을 생성합니다.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
type Query {
getObj: [Obj_Type_1]
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
이 단계에서는 Query 유형을 추가하고 schema 루트에 정의했습니다. Query 유형은 Obj_Type_1 객체 목록을 반환한 getObj 필드를 정의했습니다.
schema 루트 코드 query: Query에서 query: 부분은 쿼리가 스키마에 정의되었음을 나타내고 Query 부분은 실제 특수 객체 이름을 나타냅니다.
- CDK
-
CDK를 사용하기 전에 CDK의 공식 설명서를 CDK 참조와 함께 검토 AWS AppSync하는 것이 좋습니다.
아래 나열된 단계는 특정 리소스를 추가하는 데 사용되는 스니펫의 일반적인 예시만 보여줍니다. 프로덕션 코드에서는 이 예시가 올바르게 작동하는 솔루션이 아닙니다. 또한 이미 작동하는 앱을 가지고 있는 것으로 가정합니다.
쿼리와 스키마 루트를 .graphql 파일에 추가해야 합니다. 예제에서는 아래와 비슷했지만, 실제 스키마 코드로 바꿔야 할 수 있습니다.
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
다른 파일처럼 스키마에 유형을 직접 추가할 수 있습니다.
스키마 루트 업데이트는 선택 사항입니다. 이 예제에 모범 사례로 추가했습니다.
GraphQL API에서 변경한 내용을 사용하려면 앱을 재배포해야 합니다.
이제 객체와 특수 객체(쿼리)를 모두 생성하는 예제를 살펴보았습니다. 또한 이러한 객체를 상호 연결하여 데이터와 작업을 설명하는 방법도 살펴보았습니다. 데이터 설명과 하나 이상의 쿼리만 포함된 스키마를 사용할 수 있습니다. 하지만 데이터 원본에 데이터를 추가하는 또 다른 작업을 추가하려고 합니다. 데이터를 수정하는 Mutation이라는 또 하나의 특수 객체 유형을 추가할 것입니다.
- Console
-
-
변형은 Mutation이라고 부르겠습니다. Query와 마찬가지로, Mutation 내부의 필드 작업은 작업을 설명하고 해석기에 연결됩니다. 또한 특수 객체 유형이기 때문에 schema 루트에 정의해야 합니다. 다음은 변형의 예입니다.
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
일반적인 변형은 쿼리처럼 루트에 나열됩니다. 변형은 이름과 함께 type 키워드를 사용하여 정의됩니다. Name_of_Mutation은 일반적으로 Mutation으로 불리므로 그대로 유지하는 것이 좋습니다. 또한 각 필드는 작업을 수행합니다. 필드 작업의 형식과 관련해서는 다음과 같을 수 있습니다.
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
다음은 그 예입니다.
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
이 단계에서는 addObj 필드가 있는 Mutation 유형을 추가했습니다. 이 필드의 기능을 요약해 보겠습니다.
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObj는 Obj_Type_1 객체를 사용하여 작업을 수행합니다. 필드로 인해 분명히 알 수도 있지만, : Obj_Type_1 반환 유형에서도 구문을 통해 이를 증명할 수 있습니다. addObj 내부에서는 Obj_Type_1 객체의 id, title, date 필드를 파라미터로 수용합니다. 보는 것과 같이 메서드 선언과 매우 흡사합니다. 하지만 메서드의 동작에 대해서는 아직 설명하지 않았습니다. 앞서 설명했듯이 스키마는 데이터와 작업의 내용을 정의하는 용도로만 사용되며 작동 방식을 정의하는 용도로는 사용할 수 없습니다. 실제 비즈니스 로직을 구현하는 방법은 나중에 첫 번째 해석기를 만들 때 다루게 될 것입니다.
스키마 작업을 완료하면 schema.graphql 파일로 내보낼 수 있는 옵션이 있습니다. 스키마 편집기에서 스키마 내보내기를 선택하여 지원되는 형식으로 파일을 다운로드할 수 있습니다.
참고로는 내보내기 중에 스키마 루트를 AWS AppSync 자동으로 추가하므로 기술적으로 스키마에 직접 추가할 필요가 없습니다. 본 서비스는 중복 스키마를 자동으로 처리합니다. 이 내용은 여기에 모범 사례로 추가하겠습니다.
- CLI
-
아직 읽어보지 않은 경우 먼저 콘솔 버전을 읽어보시기 바랍니다.
-
update-type 명령을 실행하여 루트 스키마를 업데이트하세요.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
유형의 type-name. 콘솔 예제에서는 schema였습니다.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
schema {
query: Query
mutation: Mutation
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
create-type 명령을 실행하여 Mutation 유형을 생성합니다.
이 특정 명령에 대해 몇 가지 파라미터를 입력해야 합니다.
-
API의 api-id.
-
definition 또는 유형의 내용. 콘솔 예제에서는 다음과 같았습니다.
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
입력의 format. 이 예제에서는 SDL을 사용합니다.
예를 들어 명령은 다음과 같을 수 있습니다.
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
CLI에서 출력이 반환됩니다. 다음은 그 예입니다.
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
CDK를 사용하기 전에 CDK의 공식 설명서를 CDK 참조와 함께 검토 AWS AppSync하는 것이 좋습니다.
아래 나열된 단계는 특정 리소스를 추가하는 데 사용되는 스니펫의 일반적인 예시만 보여줍니다. 프로덕션 코드에서는 이 예시가 올바르게 작동하는 솔루션이 아닙니다. 또한 이미 작동하는 앱을 가지고 있는 것으로 가정합니다.
쿼리와 스키마 루트를 .graphql 파일에 추가해야 합니다. 예제에서는 아래와 비슷했지만, 실제 스키마 코드로 바꿔야 할 수 있습니다.
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
스키마 루트 업데이트는 선택 사항입니다. 이 예제에 모범 사례로 추가했습니다.
GraphQL API에서 변경한 내용을 사용하려면 앱을 재배포해야 합니다.
선택적 고려 사항 - 열거형을 상태로 사용
이제 기본 스키마를 만드는 방법을 알게 되었습니다. 그러나 스키마의 기능을 향상하기 위해 추가할 수 있는 많은 항목이 있습니다. 애플리케이션에서 흔히 볼 수 있는 방법 중 하나는 열거형을 상태로 사용하는 방법입니다. 열거형을 사용하여 호출 시 값 집합에서 특정 값을 선택하도록 할 수 있습니다. 이 옵션은 시간이 오래 지나도 크게 변하지 않을 것임을 알고 있는 경우에 유용합니다. 가정해 보자면, 응답에 상태 코드나 문자열을 반환하는 열거형을 추가할 수도 있습니다.
예를 들어 백엔드에 사용자의 게시물 데이터를 저장하는 소셜 미디어 앱을 만들고 있다고 가정해 보겠습니다. 스키마에는 개별 게시물의 데이터를 나타내는 Post 유형이 포함되어 있습니다.
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Post에는 고유한 id, 게시물 title, 게시한 date 및 앱에서 처리되는 게시물 상태를 나타내는 PostStatus라는 열거형이 포함됩니다. 작업을 위해 모든 게시물 데이터를 반환하는 쿼리를 만들겠습니다.
type Query {
getPosts: [Post]
}
또한 데이터 원본에 게시물을 추가하는 변형도 생성할 것입니다.
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
스키마를 보면 PostStatus 열거형에 여러 상태가 있는 것을 볼 수 있습니다. success(게시물 처리 완료), pending(게시물 처리 중), error(게시물을 처리할 수 없음)의 세 가지 기본 상태가 필요할 수 있습니다. 다음과 같이 열거형을 추가할 수 있습니다.
enum PostStatus {
success
pending
error
}
전체 스키마는 다음과 같을 수 있습니다.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
사용자가 애플리케이션에 Post를 추가하면 해당 데이터를 처리하기 위해 addPost 작업이 호출됩니다. addPost에 연결된 해석기가 데이터를 처리하는 동안 poststatus를 작업의 상태로 계속 업데이트합니다. 쿼리 시 Post에는 데이터의 최종 상태가 포함됩니다. 여기서는 스키마에서 데이터가 작동하는 방식에 대해서만 설명하고 있다는 점을 기억하세요. 요청을 이행하기 위해 데이터를 처리하는 실제 비즈니스 로직을 구현하는 해석기의 구현에 대해서는 많은 사항을 가정합니다.
선택적 고려 사항 - 구독
AWS AppSync의 구독은 변형에 대한 응답으로 호출됩니다. 스키마의 Subscription 지시문과 @aws_subscribe() 유형을 사용하여 이 호출을 구성하면 하나 이상의 구독을 호출하는 변형을 지정할 수 있습니다. 구독 구성에 대한 자세한 내용은 실시간 데이터를 참조하세요.
선택적 고려 사항 - 관계 및 페이지 매김
DynamoDB 테이블에 백만 개의 Posts가 저장되어 있고 그 데이터 중 일부를 반환하려고 한다고 가정해 보겠습니다. 그러나 위에 제공된 예제 쿼리는 모든 게시물만 반환합니다. 요청을 할 때마다 모든 게시물을 가져오고 싶지는 않을 수 있습니다. 대신 데이터에 페이지를 지정할 수 있습니다. 스키마를 다음과 같이 변경합니다.
-
getPosts 필드에 nextToken(반복자) 및 limit(반복 제한)이라는 두 개의 입력 인수를 추가합니다.
-
Posts(Post 객체 목록 검색) 및 nextToken(반복자) 필드를 포함하는 새 PostIterator 유형을 추가합니다.
-
Post 객체 목록이 아닌 PostIterator를 반환하도록 getPosts를 변경합니다.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
PostIterator 유형을 사용하면 Post 객체 목록의 일부와 다음 부분을 가져오기 위해 nextToken을 반환할 수 있습니다. PostIterator 내부에는 페이지 매김 토큰(nextToken)과 함께 반환되는 Post 항목([Post])의 목록이 있습니다. In AWS AppSync에서는 해석기를 통해 Amazon DynamoDB에 연결되고 암호화된 토큰으로 자동으로 생성됩니다. 이 매핑 템플릿은 limit 인수의 값을 maxResults 파라미터로 변환하고 nextToken 인수의 값을 exclusiveStartKey 파라미터로 변환합니다. AWS AppSync 콘솔의 예제 또는 기본 제공 템플릿 샘플은 해석기 참조(JavaScript)를 참조하세요.