기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 원본에 연결
Amazon SageMaker Canvas에서는 JDBC 커넥터를 사용하여 AWS 서비스, SaaS 플랫폼 또는 기타 데이터베이스를 통해 로컬 파일 시스템 외부의 위치에서 데이터를 가져올 수 있습니다. 예를 들어 Amazon Redshift의 데이터 웨어하우스에서 테이블을 가져오거나 Google Analytics 데이터를 가져오고 싶을 수 있습니다.
가져오기 워크플로를 통해 Canvas 애플리케이션에서 데이터를 가져오는 경우 데이터 원본을 선택한 다음 가져오려는 데이터를 선택할 수 있습니다. Snowflake 및 Amazon Redshift와 같은 특정 데이터 원본의 경우 자격 증명을 지정하고 데이터 원본에 대한 연결을 추가해야 합니다.
다음 스크린샷은 사용 가능한 모든 데이터 원본이 강조 표시된 가져오기 워크플로의 데이터 원본 도구 모음을 보여줍니다. 사용 가능한 데이터 원본에서만 데이터를 가져올 수 있습니다. 원하는 데이터 원본을 사용할 수 없는 경우 관리자에게 문의하세요.
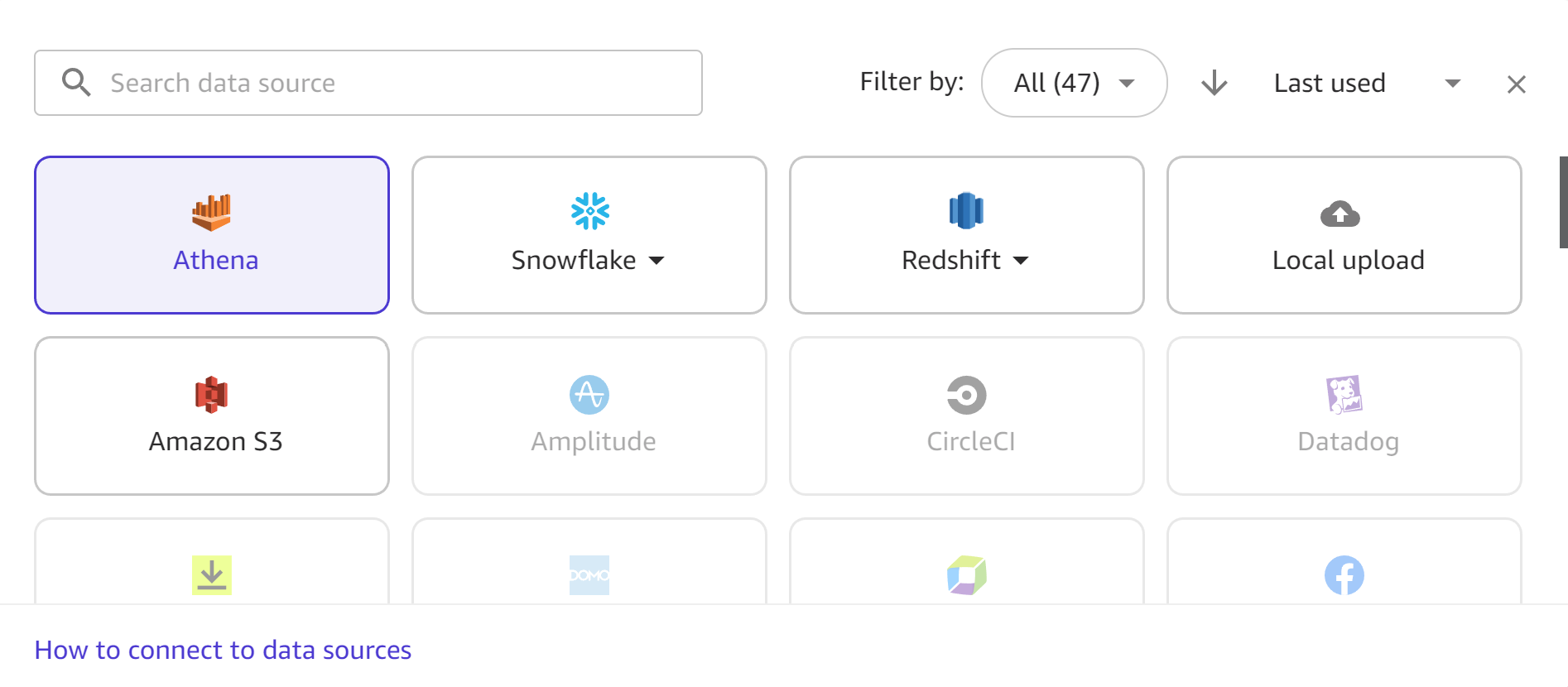
다음 섹션에서는 외부 데이터 원본에 대한 연결을 설정하고 외부 데이터 원본에서 데이터를 가져오는 방법에 대한 정보를 제공합니다. 먼저 다음 섹션을 검토하여 데이터 원본에서 데이터를 가져오는 데 필요한 권한을 결정하세요.
권한
다음 정보를 검토하여 데이터 원본에서 데이터를 가져오는 데 필요한 권한이 있는지 확인하세요.
Amazon S3: 사용자에게 버킷에 액세스할 권한이 있으면 Amazon S3 버킷에서 데이터를 가져올 수 있습니다. AWS IAM을 사용하여 Amazon S3 버킷에 대한 액세스를 제어하는 방법에 대한 자세한 내용은 Amazon S3 사용 설명서의 Amazon S3의 자격 증명 및 액세스 관리를 참조하세요.
Amazon Athena: 사용자의 실행 역할에 AmazonSageMakerFullAccess 정책 및 AmazonSageMakerCanvasFullAccess 정책이 연결되어 있는 경우 Amazon Athena AWS Glue Data Catalog 를 사용하여를 쿼리할 수 있습니다. Athena 작업 그룹에 속해 있는 경우 Canvas 사용자에게 데이터에 대한 Athena 쿼리를 실행할 수 있는 권한이 있는지 확인하세요. 자세한 내용은 Amazon Athena 사용 설명서의 작업 그룹을 사용하여 쿼리 실행을 참조하세요.
Amazon DocumentDB: 데이터베이스에 연결할 자격 증명(사용자 이름 및 암호)이 있고 사용자의 실행 역할에 연결된 최소 기본 Canvas 권한이 있는 한 모든 Amazon DocumentDB 데이터베이스에서 데이터를 가져올 수 있습니다. Canvas 권한에 대한 자세한 내용은 Amazon SageMaker Canvas를 설정하기 위한 사전 조건 섹션을 참조하세요.
Amazon Redshift: Amazon Redshift에서 데이터를 가져오는 데 필요한 권한을 자신에게 부여하려면 사용자에게 Amazon Redshift 데이터를 가져올 수 있는 권한 부여를 참조하세요.
Amazon RDS: 사용자의 실행 역할에 AmazonSageMakerCanvasFullAccess 정책이 연결되어 있으면 Canvas에서 Amazon RDS 데이터베이스에 액세스할 수 있습니다.
SaaS 플랫폼: AmazonSageMakerFullAccess 정책과 AmazonSageMakerCanvasFullAccess 정책이 사용자의 실행 역할에 연결되어 있는 경우 SaaS 플랫폼에서 데이터를 가져오는 데 필요한 권한을 갖게 됩니다. 특정 SaaS 커넥터 연결에 대한 자세한 내용은 Canvas와 함께 SaaS 커넥터 사용을 참조하세요.
JDBC 커넥터: Databricks, MySQL 또는 MariaDB와 같은 데이터베이스 원본의 경우 Canvas에서 연결을 시도하기 전에 원본 데이터베이스에서 사용자 이름 및 암호 인증을 활성화해야 합니다. Databricks 데이터베이스에 연결하는 경우 필요한 자격 증명이 포함된 JDBC URL이 있어야 합니다.
에 저장된 데이터베이스에 연결 AWS
저장한 데이터를 가져올 수 있습니다 AWS. Amazon S3에서 데이터를 가져오거나, Amazon Athena를 사용하여에서 데이터베이스를 쿼리하거나 AWS Glue Data Catalog, Amazon RDS에서 데이터를 가져오거나, 프로비저닝된 Amazon Redshift 데이터베이스(Redshift Serverless 아님)에 연결할 수 있습니다.
Amazon Redshift에 여러 개의 연결을 생성할 수 있습니다. Amazon Athena의 경우, AWS Glue Data Catalog에 보유하고 있는 모든 데이터베이스에 액세스할 수 있습니다. Amazon S3의 경우 필요한 권한이 있으면 버킷에서 데이터를 가져올 수 있습니다.
보다 자세한 내용은 다음 섹션을 검토하세요.
Amazon S3, Amazon Athena 또는 Amazon RDS의 데이터에 연결
Amazon S3의 경우 버킷에 액세스할 권한이 있으면 Amazon S3 버킷에서 데이터를 가져올 수 있습니다.
Amazon Athena의 경우 Amazon Athena 작업 그룹을 통해 권한이 있는 AWS Glue Data Catalog 한의 데이터베이스에 액세스할 수 있습니다.
Amazon RDS의 경우 Amazon SageMakerCanvasFullAccess 정책이 사용자 역할에 연결되어 있으면 Amazon RDS 데이터베이스의 데이터를 Canvas로 가져올 수 있습니다.
Amazon S3 버킷에서 데이터를 가져오거나 Amazon Athena를 사용하여 쿼리를 실행하고 데이터 테이블을 가져오려면 데이터세트 생성을 참조하세요. Amazon Athena에서는 테이블 형식 데이터만 가져올 수 있으며, Amazon S3에서는 테이블 형식 및 이미지 데이터를 가져올 수 있습니다.
Amazon DocumentDB 데이터베이스에 연결
Amazon DocumentDB는 완전관리형 서버리스 도큐먼트 데이터베이스 서비스입니다. Amazon DocumentDB 데이터베이스에 저장된 비정형 문서 데이터를 테이블 형식의 데이터세트로 SageMaker Canvas로 가져온 다음, 이 데이터를 사용하여 기계 학습 모델을 빌드할 수 있습니다.
중요
Amazon DocumentDB에 연결을 추가하려면 SageMaker AI 도메인을 VPC 전용 모드로 구성해야 합니다. Canvas 애플리케이션과 동일한 Amazon VPC에서만 Amazon DocumentDB 클러스터에 액세스할 수 있습니다. 또한 Canvas는 TLS 지원 Amazon DocumentDB 클러스터에만 연결할 수 있습니다. VPC 전용 모드로 Canvas를 설정하는 방법에 대한 자세한 내용은 인터넷 액세스 없이 VPC에서 Amazon SageMaker Canvas 구성 섹션을 참조하세요.
Amazon DocumentDB 데이터베이스에서 데이터를 가져오려면 Amazon DocumentDB 데이터베이스에 액세스하고 데이터베이스 연결을 만들 때 사용자 이름과 암호를 지정하는 자격 증명이 있어야 합니다. Amazon DocumentDB 사용자 권한을 수정하여 더 세분화된 권한을 구성하고 액세스를 제한할 수 있습니다. Amazon DocumentDB에서의 액세스 제어에 대한 자세한 내용은 Amazon DocumentDB 개발자 안내서의 Database Access Using Role-Based Access Control을 참조하세요.
Amazon DocumentDB에서 가져올 때 Canvas는 필드를 테이블의 열에 매핑하여 비정형 데이터를 테이블 형식의 데이터세트로 변환합니다. 데이터의 각 복합 필드(또는 중첩 구조)에 대해 추가 테이블이 만들어지며, 여기서 열은 복합 필드의 하위 필드에 상응합니다. 이 프로세스와 스키마 변환 예시에 대한 자세한 내용은 Amazon DocumentDB JDBC Driver Schema Discovery
Canvas는 Amazon DocumentDB 의 단일 데이터베이스에만 연결할 수 있습니다. 다른 데이터베이스에서 데이터를 가져오려면 새 연결을 만들어야 합니다.
다음 방법을 사용하여 Amazon DocumentDB에서 Canvas로 데이터를 가져올 수 있습니다.
-
데이터세트 생성. Canvas에서 Amazon DocumentDB 데이터를 가져오고 테이블 형식의 데이터세트를 만들 수 있습니다. 이 방법을 선택하는 경우 Import tabular data의 절차를 따라야 합니다.
-
데이터 흐름 만들기. Canvas에서 데이터 준비 파이프라인을 만들고 Amazon DocumentDB 데이터베이스를 데이터 소스로 추가할 수 있습니다.
데이터 가져오기를 계속하려면 이전 목록에 링크로 연결된 방법 중 하나에 대한 절차를 따르세요.
워크플로 중 하나에서 데이터 소스를 선택하는 단계에 도달하면(데이터세트 만들기의 경우 6단계, 데이터 흐름 만들기의 경우 8단계) 다음을 수행합니다.
데이터 소스에서 드롭다운 메뉴를 열고 DocumentDB를 선택합니다.
연결 추가를 선택합니다.
-
대화 상자에서 Amazon DocumentDB 자격 증명을 지정합니다.
연결 이름을 입력합니다. Canvas에서 이 연결을 식별하는 데 사용하는 이름입니다.
클러스터에서 데이터를 저장하는 Amazon DocumentDB의 클러스터를 선택합니다. Canvas는 Canvas 애플리케이션과 동일한 VPC에서 Amazon DocumentDB 클러스터로 드롭다운 메뉴를 자동으로 채웁니다.
Amazon DocumentDB 클러스터의 사용자 이름을 입력합니다.
Amazon DocumentDB 클러스터의 암호를 입력합니다.
연결할 데이터베이스의 이름을 입력합니다.
-
읽기 기본 설정 옵션은 클러스터 Canvas에서 데이터를 읽는 인스턴스 유형을 결정합니다. 다음 중 하나 선택:
보조 선호 - Canvas는 기본적으로 클러스터의 보조 인스턴스에서 읽지만 보조 인스턴스를 사용할 수 없는 경우 Canvas는 기본 인스턴스에서 읽습니다.
보조 - Canvas는 클러스터의 보조 인스턴스에서만 읽기 때문에 읽기 작업이 클러스터의 일반 읽기 및 쓰기 작업을 방해하지 않습니다.
-
연결 추가를 선택합니다. 다음 이미지는 Amazon DocumentDB 연결에 대한 이전 필드가 있는 대화 상자를 보여줍니다.
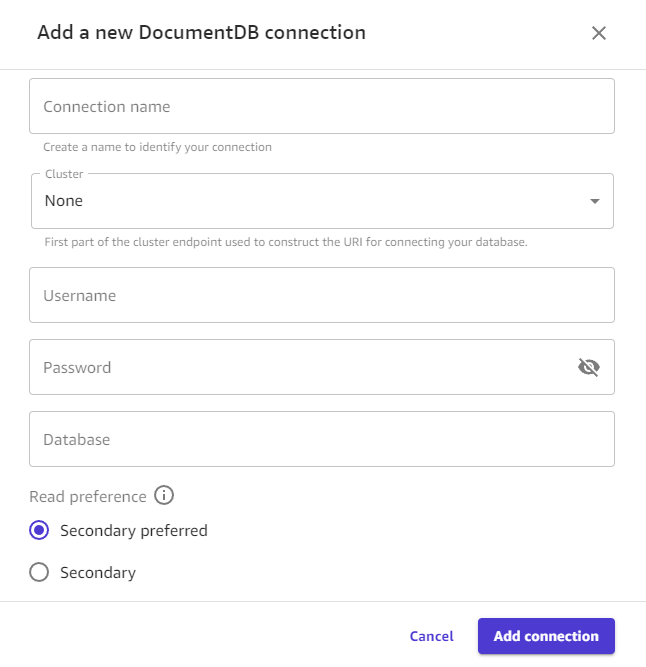
이제 Amazon DocumentDB에 연결되었을 것입니다. Canvas에서 Amazon DocumentDB 데이터를 사용하여 데이터세트 또는 데이터 흐름을 만들 수 있습니다.
Amazon Redshift 데이터베이스에 연결
조직이 데이터를 보관하는 데이터 웨어하우스인 Amazon Redshift에서 데이터를 가져올 수 있습니다. Amazon Redshift에서 데이터를 가져오려면 먼저 사용하는 AWS IAM 역할에 AmazonRedshiftFullAccess 관리형 정책이 연결되어 있어야 합니다. 정책을 연결하는 방법에 대한 지침은 사용자에게 Amazon Redshift 데이터를 가져올 수 있는 권한 부여을 참조하세요.
Amazon Redshift에서 데이터를 가져오려면 다음 작업을 수행합니다.
-
Amazon Redshift 데이터베이스에 대한 연결을 생성합니다.
-
가져오려는 데이터를 선택합니다.
-
데이터를 가져옵니다.
Amazon Redshift 편집기를 사용하여 데이터세트를 가져오기 창으로 드래그하여 SageMaker Canvas로 가져올 수 있습니다. 데이터 세트에 반환된 값을 더 자세히 제어하려면 다음을 사용할 수 있습니다.
-
SQL 쿼리
-
조인
SQL 쿼리를 사용하면 데이터세트의 값을 가져오는 방법을 사용자 지정할 수 있습니다. 예를 들어 데이터 세트에서 반환되는 열 또는 열의 값 범위를 지정할 수 있습니다.
조인을 사용하여 Amazon Redshift의 여러 데이터세트를 단일 데이터세트로 결합할 수 있습니다. Amazon Redshift에서 데이터세트를 조인할 수 있는 패널로 데이터세트를 드래그할 수 있습니다.
SQL 편집기를 사용하여 조인한 데이터세트를 편집하고 조인된 데이터세트를 단일 노드로 변환할 수 있습니다. 다른 데이터세트를 노드에 조인할 수 있습니다. 선택한 데이터를 SageMaker Canvas로 가져올 수 있습니다.
Amazon Redshift에서 데이터를 가져오려면 다음 절차를 따르세요.
SageMaker Canvas 애플리케이션에서 데이터 세트 페이지로 이동합니다.
데이터 가져오기를 선택하고 드롭다운 메뉴에서 테이블 형식을 선택합니다.
-
데이터 세트 이름을 입력한 후 생성을 선택합니다.
데이터 원본의 경우 드롭다운 메뉴를 열고 Redshift를 선택합니다.
-
연결 추가를 선택합니다.
-
대화 상자에서 Amazon Redshift 자격 증명을 지정합니다.
-
인증 방법으로는 IAM을 선택합니다.
-
클러스터 식별자를 입력하여 연결하려는 클러스터를 지정합니다. Amazon Redshift 클러스터의 전체 엔드포인트는 입력하지 않고 클러스터 식별자만 입력합니다.
-
연결할 데이터베이스의 데이터베이스 이름을 입력합니다.
-
데이터베이스 사용자를 입력하여 데이터베이스에 연결하는 데 사용할 사용자를 식별합니다.
-
ARN의 경우 Amazon Redshift 클러스터가 Amazon S3로 데이터를 이동하고 쓰기 위해 맡아야 하는 역할의 IAM 역할 ARN을 입력합니다. 이 역할에 대한 자세한 내용은 Amazon Redshift 관리 안내서의 Amazon Redshift가 사용자를 대신하여 다른 AWS 서비스에 액세스하도록 권한 부여를 참조하세요.
-
연결 이름을 입력합니다. Canvas에서 이 연결을 식별하는 데 사용하는 이름입니다.
-
-
연결 이름이 표시된 탭에서 가져오려는 .csv 파일을 가져올 테이블 드래그 앤 드롭 창으로 끌어다 놓습니다.
-
선택 사항: 추가 테이블을 가져오기 패널로 드래그합니다. GUI를 사용하여 테이블을 조인할 수 있습니다. 조인의 구체성을 높이려면 SQL에서 편집을 선택합니다.
-
선택 사항: SQL을 사용하여 데이터를 쿼리하는 경우 컨텍스트를 선택하여 다음 값을 지정하여 연결에 컨텍스트를 추가할 수 있습니다.
-
웨어하우스
-
데이터베이스
-
스키마
-
-
데이터 가져오기를 선택합니다.
다음 이미지는 Amazon Redshift 연결에 지정된 필드의 예를 보여줍니다.
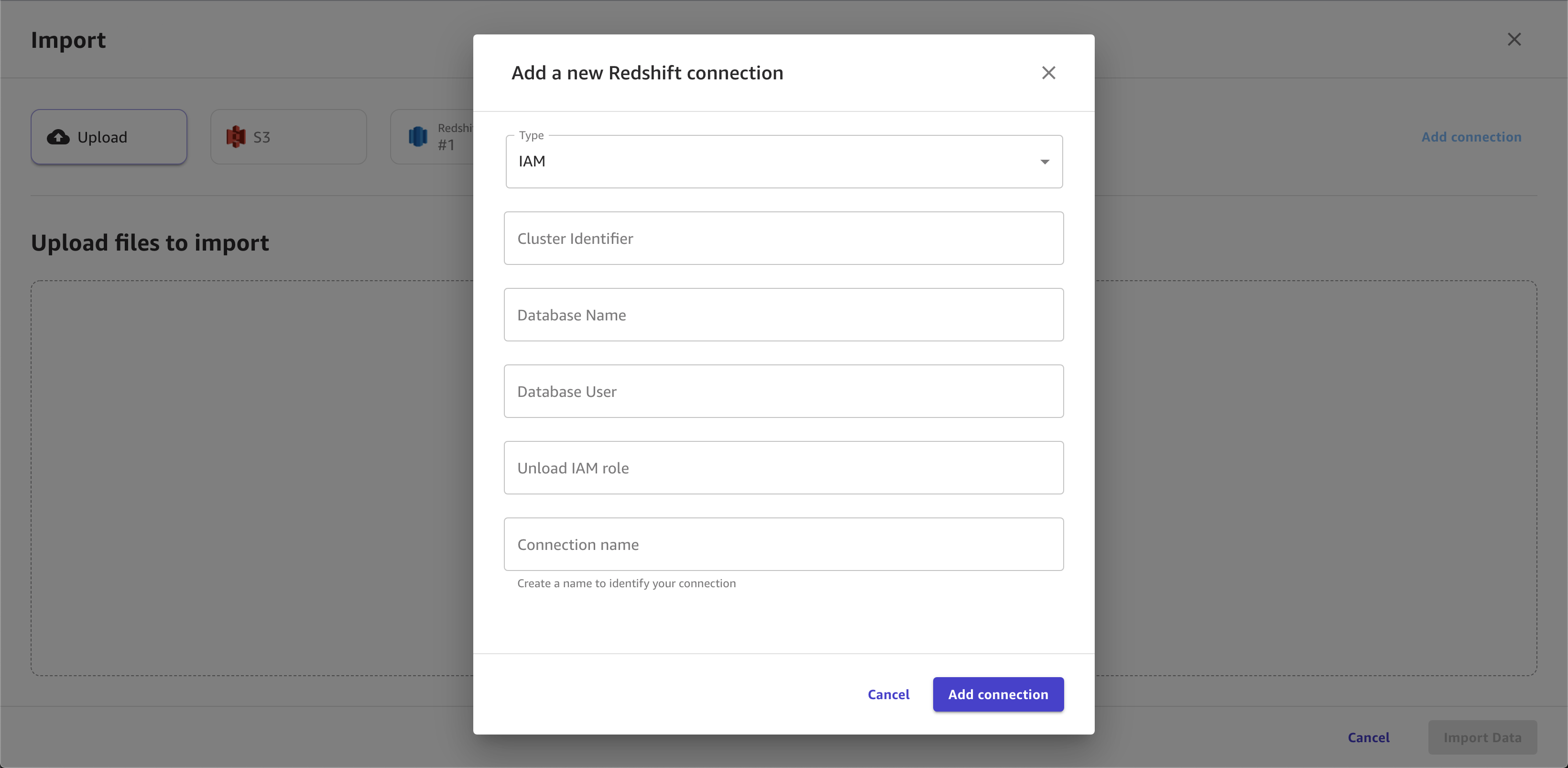
다음 이미지는 Amazon Redshift에서 데이터세트를 조인하는 데 사용되는 페이지를 보여줍니다.

다음 이미지는 Amazon Redshift에서 조인을 편집하는 데 사용되는 SQL 쿼리를 보여줍니다.

JDBC 커넥터로 데이터에 연결
JDBC를 사용하면 Databricks, SQLServer, MySQL, PostgreSQL, MariaDB, Amazon RDS 및 Amazon Aurora와 같은 소스에서 데이터베이스에 연결할 수 있습니다.
Canvas에서 연결을 생성하는 데 필요한 자격 증명과 권한이 있는지 확인해야 합니다.
Databricks의 경우 JDBC URL을 제공해야 합니다. URL 형식은 Databricks 인스턴스마다 다를 수 있습니다. URL을 찾고 그 내부에서 파라미터를 지정하는 방법은 Databricks 설명서의 JDBC 구성 및 연결 파라미터
에서 확인하세요. jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-token은 URL 형식을 지정하는 방법의 예입니다.다른 데이터베이스 소스의 경우 사용자 이름 및 암호 인증을 설정한 다음 Canvas에서 데이터베이스에 연결할 때 해당 자격 증명을 지정해야 합니다.
또한 퍼블릭 인터넷을 통해 데이터 소스에 액세스할 수 있어야 합니다.또는 Canvas 애플리케이션이 VPC 전용 모드에서 실행되는 경우 데이터 소스가 동일한 VPC에서 실행되어야 합니다. VPC에서 Amazon RDS 데이터베이스를 구성하는 방법에 대한 자세한 내용은 Amazon RDS 사용 설명서의 Amazon VPC 및 Amazon RDS를 참조하세요.
데이터 원본 자격 증명을 구성한 후 Canvas 애플리케이션에 로그인하여 데이터 원본에 대한 연결을 생성할 수 있습니다. 연결을 만들 때 자격 증명(또는 Databricks의 경우 URL)을 지정하세요.
OAuth를 사용하여 데이터 원본에 연결
Canvas는 Snowflake 및 Salesforce Data Cloud의 데이터에 연결하기 위한 인증 방법으로 OAuth 사용을 지원합니다. OAuth
참고
각 데이터 원본에 대해 하나의 OAuth 연결만 설정할 수 있습니다.
연결을 승인하려면 OAuth를 사용하여 데이터 원본에 대한 연결 설정에 설명된 초기 설정을 따라야 합니다.
OAuth 자격 증명을 설정한 후 다음을 수행하여 OAuth를 통한 Snowflake 또는 Salesforce Data Cloud 연결을 추가할 수 있습니다.
Canvas 애플리케이션에 로그인합니다.
테이블 형식의 데이터세트를 생성합니다. 데이터를 업로드하라는 메시지가 표시되면 Snowflake 또는 Salesforce Data Cloud를 데이터 원본으로 선택합니다.
Snowflake 또는 Salesforce Data Cloud 데이터 원본에 대한 새 연결을 생성합니다. OAuth를 인증 방법으로 지정하고 연결 세부 정보를 입력합니다.
이제 Snowflake 또는 Salesforce Data Cloud의 데이터베이스에서 데이터를 가져올 수 있을 것입니다.
SaaS 플랫폼에 연결
Snowflake 및 40개 이상의 기타 외부 SaaS 플랫폼에서 데이터를 가져올 수 있습니다. 커넥터의 전체 목록은 데이터 가져오기의 테이블을 참조하세요.
참고
SaaS 플랫폼에서는 데이터 테이블과 같은 테이블 형식 데이터만 가져올 수 있습니다.
Snowflake를 Canvas와 함께 사용
Snowflake는 데이터 저장 및 분석 서비스이며, Snowflake에서 SageMaker Canvas로 데이터를 가져올 수 있습니다. Snowflake에 대한 자세한 내용은 Snowflake 설명서
다음을 수행하여 Snowflake 계정에서 데이터를 가져올 수 있습니다.
-
Snowflake 데이터베이스에 대한 연결을 생성합니다.
-
왼쪽 탐색 메뉴에서 테이블을 편집기로 드래그 앤 드롭하여 가져오려는 데이터를 선택합니다.
-
데이터를 가져옵니다.
Snowflake 편집기를 사용하여 데이터세트를 가져오기 패널로 드래그하고 SageMaker Canvas로 가져올 수 있습니다. 데이터 세트에 반환된 값을 더 자세히 제어하려면 다음을 사용할 수 있습니다.
-
SQL 쿼리
-
조인
SQL 쿼리를 사용하면 데이터세트의 값을 가져오는 방법을 사용자 지정할 수 있습니다. 예를 들어 데이터 세트에서 반환되는 열 또는 열의 값 범위를 지정할 수 있습니다.
SQL 또는 Canvas 인터페이스를 사용하여 Canvas로 가져오기 전에 여러 Snowflake 데이터세트를 단일 데이터세트로 조인할 수 있습니다. 데이터세트를 조인할 수 있는 패널로 Snowflake의 데이터세트를 드래그하거나, SQL에서 조인을 편집하고 SQL을 단일 노드로 변환할 수 있습니다. 변환한 노드에 다른 노드를 조인할 수 있습니다. 그런 다음 조안한 데이터세트를 단일 노드로 결합하고 노드를 다른 Snowflake 데이터세트에 조인할 수 있습니다. 마지막으로, 선택한 데이터를 Canvas로 가져올 수 있습니다.
다음 절차를 사용하여 Snowflake에서 Amazon SageMaker Canvas로 데이터를 가져올 수 있습니다.
SageMaker Canvas 애플리케이션에서 데이터 세트 페이지로 이동합니다.
데이터 가져오기를 선택하고 드롭다운 메뉴에서 테이블 형식을 선택합니다.
-
데이터 세트 이름을 입력한 후 생성을 선택합니다.
데이터 원본의 경우 드롭다운 메뉴를 열고 Snowflake를 선택합니다.
-
연결 추가를 선택합니다.
-
새 Snowflake 연결 추가 대화 상자에서 Snowflake 자격 증명을 지정합니다. 인증 방법에서 다음 중 하나를 선택합니다.
기본 - 사용자 이름 암호 - Snowflake 계정 ID, 사용자 이름 및 암호를 입력합니다.
-
ARN - Snowflake 자격 증명의 보호를 개선하려면 자격 증명이 포함된 AWS Secrets Manager 보안 암호의 ARN을 제공합니다. 자세한 내용은 AWS Secrets Manager 사용 설명서의 AWS Secrets Manager 보안 암호 생성을 참조하세요.
보안 암호에는 Snowflake 자격 증명이 다음 JSON 형식으로 저장되어 있어야 합니다.
{"accountid": "ID", "username": "username", "password": "password"} OAuth - OAuth를 사용하면 암호를 제공하지 않고도 인증할 수 있지만 추가 설정이 필요합니다. Snowflake용 OAuth 자격 증명 설정에 대한 자세한 내용은 OAuth를 사용하여 데이터 원본에 대한 연결 설정을 참조하세요.
-
연결 추가를 선택합니다.
-
연결 이름이 표시된 탭에서 가져오려는 .csv 파일을 가져올 테이블 드래그 앤 드롭 창으로 끌어다 놓습니다.
-
선택 사항: 추가 테이블을 가져오기 패널로 드래그합니다. 사용자 인터페이스를 사용하여 테이블을 조인할 수 있습니다. 조인을 좀 더 구체적으로 지정하려면 SQL에서 편집을 선택합니다.
-
선택 사항: SQL을 사용하여 데이터를 쿼리하는 경우 컨텍스트를 선택하여 다음 값을 지정하여 연결에 컨텍스트를 추가할 수 있습니다.
-
웨어하우스
-
데이터베이스
-
스키마
연결에 컨텍스트를 추가하면 향후 쿼리를 더 쉽게 지정할 수 있습니다.
-
-
데이터 가져오기를 선택합니다.
다음 이미지는 Snowflake 연결에 지정된 필드의 예를 보여 줍니다.
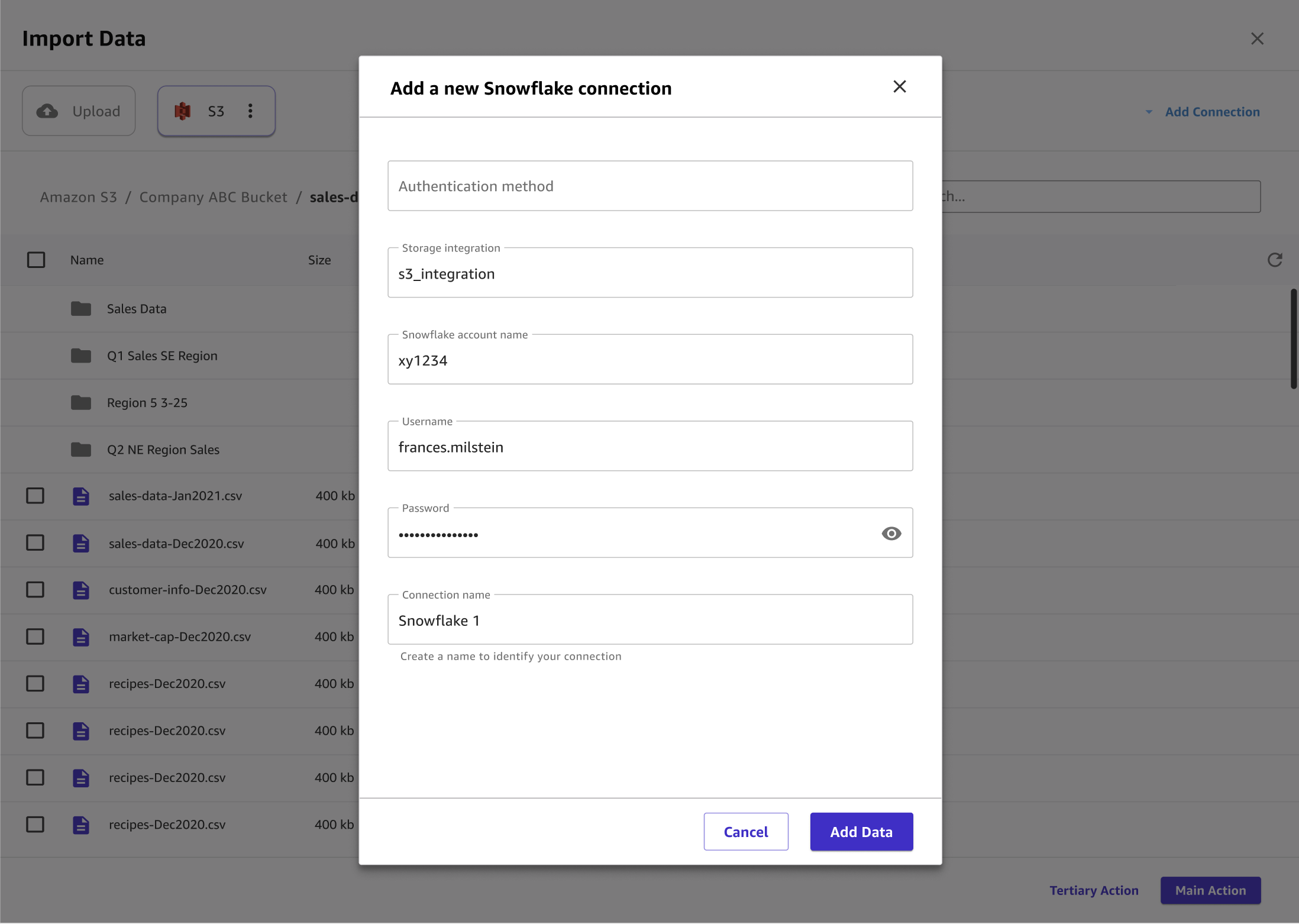
다음 이미지는 연결에 컨텍스트를 추가하는 데 사용되는 페이지를 보여줍니다.
다음 이미지는 Snowflake에서 데이터세트를 조인하는 데 사용되는 페이지를 보여줍니다.
다음 이미지는 Snowflake에서 조인을 편집하는 데 사용되는 SQL 쿼리를 보여줍니다.
Canvas와 함께 SaaS 커넥터 사용
참고
Snowflake를 제외한 SaaS 플랫폼의 경우 데이터 원본당 하나의 연결만 사용할 수 있습니다.
SaaS 플랫폼에서 데이터를 가져오려면 먼저 관리자가 인증하고 데이터 원본에 대한 연결을 생성해야 합니다. 관리자가 SaaS 플랫폼과의 연결을 생성하는 방법에 대한 자세한 내용은 Amazon AppFlow 사용 설명서의 Amazon AppFlow 연결 관리를 참조하세요.
Amazon AppFlow를 처음 시작하는 관리자인 경우 Amazon AppFlow 사용 설명서의 시작하기를 참조하세요.
SaaS 플랫폼에서 데이터를 가져오려면 테이블 형식 데이터세트를 Canvas로 가져오는 방법을 보여주는 표준 테이블 형식 데이터 가져오기절차를 따를 수 있습니다.
