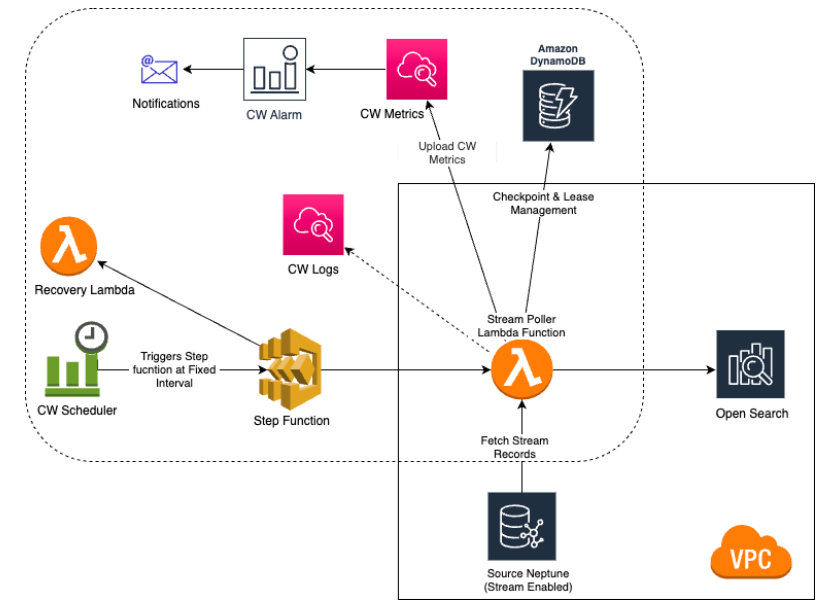
Full text search in Amazon Neptune using Amazon OpenSearch Service
Neptune integrates with Amazon OpenSearch Service (OpenSearch Service) to
support full-text search in both Gremlin and SPARQL queries. This feature is available
starting in Neptune engine release 1.0.2.1,
although we recommend using it with engine release 1.0.4.2 or higher to take
advantage of the latest fixes.
Starting with engine release 1.3.0.0, Amazon Neptune supports using Amazon OpenSearch Service Serverless for full-text search in Gremlin and SPARQL queries.
Note
When integrating with Amazon OpenSearch Service, Neptune requires Elasticsearch version 7.1 or higher, and works with OpenSearch 2.3, 2.5 and above. Neptune also works with OpenSearch Serverless.
You can use Neptune with an existing OpenSearch Service cluster that has been populated according to the Neptune data model for OpenSearch data. Or, you can create an OpenSearch Service domain linked with Neptune using an AWS CloudFormation stack.
Important
The Neptune to OpenSearch replication process described here does not replicate blank nodes. This is an important limitation to note.
Also, if you enable fine-grained access control on your OpenSearch cluster, you need to enable IAM authentication in your Neptune database as well.
Topics
