Como funciona o Aurora Serverless v1
Importante
A AWS anunciou a data de fim da vida útil do Aurora Serverless v1: 31 de março de 2025
A seguir, saiba como funciona o Aurora Serverless v1.
Aurora Serverless v1Arquitetura do
A imagem a seguir mostra uma visão geral da arquitetura do Aurora Serverless v1.
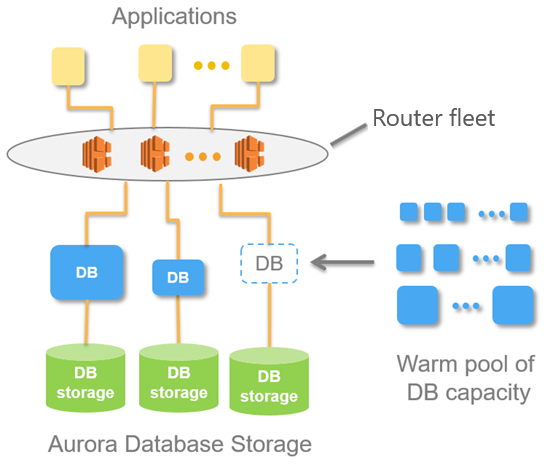
Em vez de provisionar e gerenciar servidores de banco de dados, você especifica capacity units (ACUs - unidades de capacidade) do Aurora. Cada ACU é uma combinação de aproximadamente 2 gigabytes (GB) de memória, CPU correspondente e rede. O armazenamento do banco de dados escala automaticamente de 10 gibibytes (GiB) para 128 tebibytes (TiB), o mesmo que o armazenamento em um cluster de banco de dados padrão do Aurora.
Você pode especificar as ACUs mínima e máxima. A unidade de capacidade mínima do Aurora é a ACU mais baixa para a qual o cluster de banco de dados pode ser reduzido. A unidade de capacidade máxima do Aurora é a ACU mais alta para a qual o cluster de banco de dados pode ser expandido. Com base em suas configurações, o Aurora Serverless v1 cria automaticamente as regras de escalabilidade para os limites de utilização de CPU, conexões e memória disponível.
O Aurora Serverless v1 gerencia o grupo quente de recursos em uma Região da AWS para minimizar o tempo de escalabilidade. Quando o Aurora Serverless v1 adiciona recursos ao cluster de bancos de dados Aurora, ele usa a frota de roteadores para alternar as conexões de clientes ativas para os novos recursos. Em algum momento específico, você será cobrado somente pelas ACUs que estão sendo usadas ativamente em seu cluster de banco de dados do Aurora.
Autoscaling for Aurora Serverless v1
A capacidade alocada para o cluster de banco de dados do Aurora Serverless v1 é expandida ou reduzida perfeitamente com base na carga gerada pela aplicação cliente. Aqui, a carga é a utilização da CPU e a quantidade de conexões. Quando a capacidade é limitada por qualquer um desses, o Aurora Serverless v1 se expande. O Aurora Serverless v1 também se expande quando detecta problemas de performance que podem ser resolvidos ao fazê-lo.
Você pode visualizar eventos de escalabilidade de seu cluster do Aurora Serverless v1 no AWS Management Console. Durante a escalabilidade automática, o Aurora Serverless v1 redefine a métrica EngineUptime. O valor da métrica de redefinição não significa que a escalabilidade contínua tenha problemas nem que o Aurora Serverless v1 descartou conexões. É simplesmente o ponto de partida para o tempo de atividade na nova capacidade. Para saber mais sobre as métricas, consulte Monitorar métricas em um cluster do Amazon Aurora.
Quando o seu cluster de banco de dados do Aurora Serverless v1 não tem conexões ativas, ele pode reduzir até a capacidade zero (0 ACUs). Para saber mais, consulte Pausa e retomada para o Aurora Serverless v1.
Quando é preciso executar uma operação de escalabilidade, o Aurora Serverless v1 primeiro tenta identificar um ponto de escalabilidade, um momento em que nenhuma consulta esteja em processamento. O Aurora Serverless v1 talvez não consiga encontrar um ponto de escalabilidade pelos seguintes motivos:
-
Consultas de longa duração
-
Transações em andamento
-
As tabelas temporárias ou bloqueios de tabela estão em uso
Para aumentar a taxa de sucesso em encontrar um ponto de escalabilidade de seu cluster de banco de dados Aurora Serverless v1, recomendamos evitar consultas e transações de longa duração. Para saber mais sobre operações que impedem a escalabilidade e como evitá-las, consulte Práticas recomendadas para trabalhar com o Aurora Serverless v1
Por padrão, o Aurora Serverless v1 tenta encontrar um ponto de escalabilidade por cinco minutos (300 segundos). É possível especificar um período de tempo limite diferente ao criar ou modificar o cluster. O tempo limite pode ter entre 60 segundos e 10 minutos (600 segundos). Se o Aurora Serverless v1 não conseguir encontrar um ponto de escalabilidade no período especificado, o tempo limite da operação de autoescalabilidade é excedido.
Por padrão, se a autoescalabilidade não encontrar um ponto de escalabilidade antes do tempo limite, o Aurora Serverless v1 manterá o cluster na capacidade atual. Você pode alterar esse comportamento padrão ao criar ou modificar o seu cluster de banco de dados do Aurora Serverless v1 selecionando a opção Force the capacity change (Forçar a alteração da capacidade). Para ter mais informações, consulte Ação de tempo limite para alterações na capacidade.
Ação de tempo limite para alterações na capacidade
Se a autoescalabilidade ultrapassar o tempo limite sem encontrar um ponto de escalabilidade, por padrão, o Aurora manterá a capacidade atual. Você pode optar por deixar o Aurora forçar a alteração selecionando a opção Force the capacity change (Forçar a alteração de capacidade). Essa opção está disponível na seção Autoscaling timeout and action (Tempo limite e ação de autoescalabilidade) da página Create database (Criar banco de dados), quando você cria o cluster.
Por padrão, a opção Force the capacity change (Forçar a alteração de capacidade) não é selecionada. Deixe essa opção desmarcada para que a capacidade do cluster de banco de dados do Aurora Serverless v1 permaneça inalterada, se a operação de escalabilidade ultrapassar o tempo limite sem encontrar um ponto de escalabilidade.
Selecionar essa opção faz com que o cluster de banco de dados do Aurora Serverless v1 imponha a alteração de capacidade, mesmo sem um ponto de escalabilidade. Antes de selecionar esta opção, lembre-se consequências dessa seleção:
-
Quaisquer transações em andamento são interrompidas e a seguinte mensagem de erro é exibida.
Aurora MySQL versão 2 –
ERRO 1105 (HY000): A última transação foi interrompida devido à escalabilidade simples. Tente novamente.Você pode reenviar as transações assim que seu cluster de banco de dados do Aurora Serverless v1 estiver disponível.
-
As conexões com tabelas temporárias e bloqueios são descartadas.
Recomendamos que você selecione a opção Force the capacity change (Forçar a alteração da capacidade) somente se sua aplicação puder se recuperar de conexões descartadas ou transações incompletas.
As escolhas que você faz no AWS Management Console ao criar um cluster de banco de dados do Aurora Serverless v1 são armazenadas no objeto ScalingConfigurationInfo, nas propriedades SecondsBeforeTimeout e TimeoutAction. O valor da propriedade TimeoutAction é definido como um dos seguintes valores quando você cria o cluster:
-
RollbackCapacityChange: este valor é definido quando você seleciona a opção Roll back the capacity change (Reverter a alteração na capacidade). Esse é o comportamento padrão. -
ForceApplyCapacityChange: este valor é definido quando você seleciona a opção Force the capacity change (Forcar a alteração da capacidade).
Você pode obter o valor dessa propriedade em um cluster de banco de dados do Aurora Serverless v1 existente usando o comando describe-db-clusters da AWS CLI, como mostrado a seguir.
Para Linux, macOS ou Unix:
aws rds describe-db-clusters --regionregion\ --db-cluster-identifieryour-cluster-name\ --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}'
Para Windows:
aws rds describe-db-clusters --regionregion^ --db-cluster-identifieryour-cluster-name^ --query "*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}"
O exemplo a seguir mostra a consulta e a resposta de um cluster de banco de dados do Aurora Serverless v1 chamado west-coast-sles na região Oeste dos EUA (Norte da Califórnia).
$aws rds describe-db-clusters --region us-west-1 --db-cluster-identifier west-coast-sles --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}' [ { "ScalingConfigurationInfo": { "MinCapacity": 1, "MaxCapacity": 64, "AutoPause": false, "SecondsBeforeTimeout": 300, "SecondsUntilAutoPause": 300, "TimeoutAction": "RollbackCapacityChange" } } ]
Como mostra a resposta, esse cluster de banco de dados do Aurora Serverless v1 usa a configuração padrão.
Para ter mais informações, consulte Criar um cluster de banco de dados do Aurora Serverless v1. Após criar seu Aurora Serverless v1, você também pode modificar a ação de tempo limite e outras configurações de capacidade a qualquer momento. Para saber como, consulte Modificar um cluster de banco de dados do Aurora Serverless v1.
Pausa e retomada para o Aurora Serverless v1
É possível escolher pausar o cluster de banco de dados do Aurora Serverless v1 depois de um certo tempo sem atividade. Você especifica o tempo sem atividade para que o cluster de banco seja pausado. Ao selecionar essa opção, o tempo de inatividade padrão é cinco minutos, mas é possível alterar esse valor. Esta definição é opcional.
Quando o cluster de banco é pausado, não ocorre nenhuma atividade de computação ou de memória, e você é cobrado somente pelo armazenamento. Se forem solicitadas conexões ao banco de dados quando um cluster de banco de dados do Aurora Serverless v1 estiver pausado, o cluster de banco de dados será retomado automaticamente e atenderá às solicitações de conexão.
Quando o cluster de banco de dados retoma a atividade, ele tem a mesma capacidade que tinha quando o Aurora pausou o cluster. O número de ACUs depende de quanto o Aurora expandiu ou reduziu o cluster antes de pausá-lo.
nota
Se um cluster de banco de dados for pausado por mais de sete dias, o backup do cluster de banco de dados poderá ser feito com um snapshot. Nesse caso, o Aurora restaura o cluster de banco de dados do snapshot quando há uma solicitação de conexão.
Determinar o número máximo de conexões de banco de dados do Aurora Serverless v1
Os exemplos a seguir são de um cluster de banco de dados do Aurora Serverless v1 compatível com o MySQL 5.7. Você pode usar um cliente do MySQL ou o editor de consultas, se tiver configurado o acesso a ele. Para ter mais informações, consulte Executar consultas no editor de consultas.
Como encontrar o número máximo de conexões de banco de dados
-
Encontre o intervalo de capacidade de seu cluster de banco de dados do Aurora Serverless v1 usando a AWS CLI.
aws rds describe-db-clusters \ --db-cluster-identifier my-serverless-57-cluster \ --query 'DBClusters[*].ScalingConfigurationInfo|[0]'O resultado mostra que seu intervalo de capacidade é de 1 a 4 ACUs.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Realize a seguinte consulta SQL para encontrar o número máximo de conexões.
select @@max_connections;O resultado mostrado é da capacidade mínima do cluster, 1 ACU.
@@max_connections 90 -
Dimensione o cluster para 8 a 32 ACUs.
Para ter mais informações sobre a escalabilidade, consulte Modificar um cluster de banco de dados do Aurora Serverless v1.
-
Confirme o intervalo de capacidade.
{ "MinCapacity": 8, "AutoPause": true, "MaxCapacity": 32, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Encontre o número máximo de conexões.
select @@max_connections;O resultado mostrado é da capacidade mínima do cluster, 8 ACUs.
@@max_connections 1000 -
Dimensione o cluster para o máximo possível, 256 a 256 ACUs.
-
Confirme o intervalo de capacidade.
{ "MinCapacity": 256, "AutoPause": true, "MaxCapacity": 256, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Encontre o número máximo de conexões.
select @@max_connections;O resultado mostrado é de 256 ACUs.
@@max_connections 6000nota
O valor
max_connectionsnão é dimensionado linearmente com o número de ACUs. -
Reduza a escala do cluster verticalmente para 1 a 4 ACUs.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 }Dessa vez, o valor
max_connectionsé de 4 ACUs.@@max_connections 270 -
Reduza a escala do cluster verticalmente para 2 ACUs.
@@max_connections 180Se você configurou o cluster para pausar após determinado período de tempo ocioso, a escala será reduzida verticalmente para 0 ACUs. No entanto, o valor
max_connectionsnão fica abaixo de 1 ACU.@@max_connections 90
Grupos de parâmetros para Aurora Serverless v1
Quando você cria o seu cluster de banco de dados do Aurora Serverless v1, você escolhe um mecanismo de banco de dados do Aurora específico e um grupo de parâmetros de cluster de banco de dados associado. Ao contrário dos clusters de bancos de dados Aurora provisionado, um cluster de banco de dados do Aurora Serverless v1 tem uma única instância de banco de dados de leitura/gravação configurada apenas com um grupo de parâmetros de cluster de banco de dados. Ele não tem um grupo de parâmetros de banco de dados separado. Durante o autoscaling, o Aurora Serverless v1 precisa ser capaz de alterar os parâmetros para que o cluster funcione melhor com a capacidade aumentada ou reduzida. Assim, com um cluster de banco de dados do Aurora Serverless v1, algumas das alterações que você pode fazer nos parâmetros para um determinado tipo de mecanismo de banco de dados podem não se aplicar.
Por exemplo, um cluster de banco de dados do Aurora Serverless v1 baseado no Aurora PostgreSQL não pode usar apg_plan_mgmt.capture_plan_baselines e outros parâmetros para gerenciamento de planos de consulta que podem ser usados em clusters de bancos de dados Aurora PostgreSQL provisionados.
Você pode obter uma lista de valores padrão para os grupos de parâmetros padrão dos vários mecanismos de banco de dados do Aurora usando o comando da CLI describe-engine-default-cluster-parameters e consultando a Região da AWS. A seguir estão os valores que você pode usar para a opção --db-parameter-group-family.
|
Aurora MySQL versão 2 |
|
|
Aurora PostgreSQL versão 11 |
|
|
Aurora PostgreSQL versão 13 |
|
Recomendamos que você configure a AWS CLI com o seu ID de chave de acesso da AWS e a chave de acesso secreta da AWS, além de definir a sua Região da AWS antes de usar os comandos da AWS CLI. Fornecer a região a sua configuração de CLI torna desnecessário inserir o parâmetro --region ao executar comandos. Para saber mais sobre como configurar a AWS CLI, consulte Noções básicas de configuração no Guia do usuário da AWS Command Line Interface.
O exemplo a seguir obtém uma lista de parâmetros do grupo de clusters de banco de dados padrão para Aurora MySQL versão 2.
Para Linux, macOS ou Unix:
aws rds describe-engine-default-cluster-parameters \ --db-parameter-group-family aurora-mysql5.7 --query \ 'EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `serverless`) == `true`] | [*].{param:ParameterName}' \ --output text
Para Windows:
aws rds describe-engine-default-cluster-parameters ^ --db-parameter-group-family aurora-mysql5.7 --query ^ "EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, 'serverless') == `true`] | [*].{param:ParameterName}" ^ --output text
Modificação de valores de parâmetro para o Aurora Serverless v1
Como explicado em Grupos de parâmetros para Amazon Aurora, você não pode alterar diretamente os valores em um grupo de parâmetros padrão, independentemente do tipo (grupo de parâmetros de cluster de banco de dados, grupo de parâmetros de banco de dados). Em vez disso, você cria um grupo de parâmetros personalizado com base no grupo de parâmetros do cluster de banco de dados padrão para o seu mecanismo de banco de dados do Aurora e altera as configurações nesse grupo de parâmetros, conforme necessário. Por exemplo, você pode querer alterar algumas das configurações do cluster de banco de dados do Aurora Serverless v1 para consultas de log do ou para fazer upload de logs específicos do mecanismo de banco de dados para o Amazon CloudWatch.
Para criar um grupo de parâmetros de cluster de banco de dados personalizado
-
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Grupos de parâmetros.
-
Escolha Create parameter group (Criar grupo de parâmetros) para abrir o painel Parameter group details (Detalhes do grupo de parâmetros).
-
Escolha o grupo de cluster de banco de dados padrão apropriado para o mecanismo de banco de dados que você deseja usar para seu cluster de banco de dados do Aurora Serverless v1. Escolha as seguintes opções:
-
Para Parameter group family (Família de grupo de parâmetros), escolha a família apropriada para o mecanismo de banco de dados escolhido. Sua seleção deve ter o prefixo
aurora-no nome. -
Em Type (Tipo), escolha DB Cluster Parameter Group (Grupo de parâmetros do cluster de banco de dados).
-
Em Group name (Nome do grupo) e Description (Descrição), insira nomes significativos para você ou outras pessoas que possam precisar trabalhar com seu cluster de banco de dados do Aurora Serverless v1 e respectivos parâmetros.
-
Escolha Criar.
-
Seu grupo de parâmetros de cluster de banco de dados personalizado é adicionado à lista de grupos de parâmetros disponíveis em sua Região da AWS. Você pode usar seu grupo de parâmetros de cluster de banco de dados personalizado ao criar clusters de banco de dados do Aurora Serverless v1. Você também pode modificar seus clusters de banco de dados do Aurora Serverless v1 existentes para usar seu grupo de parâmetros de cluster de banco de dados personalizado. Depois que seu cluster de banco de dados do Aurora Serverless v1 começa a usar seu grupo de parâmetros do cluster de banco de dados personalizado, você pode alterar os valores de parâmetros dinâmicos usando o AWS Management Console ou a AWS CLI.
Você também pode usar o console para visualizar uma comparação lado a lado entre os valores no seu grupo de parâmetros do cluster de banco de dados personalizado e no cluster de banco de dados padrão, conforme mostrado no snapshot a seguir.
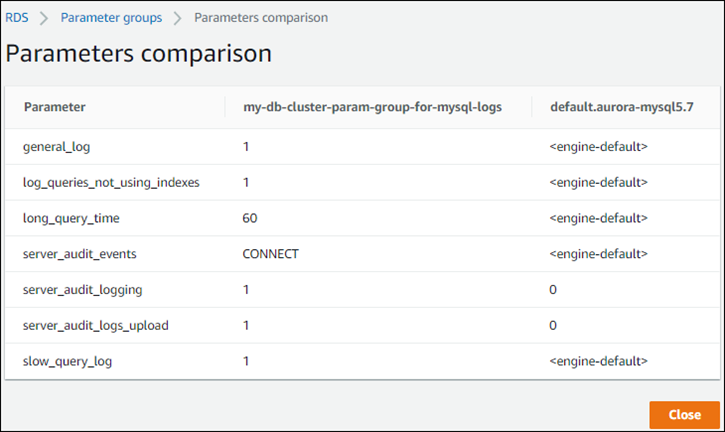
Quando você altera valores de parâmetros em um cluster de banco de dados ativo, o Aurora Serverless v1 inicia uma escalabilidade perfeita para aplicar as alterações de parâmetros. Se o seu cluster de banco de dados do Aurora Serverless v1 estiver em um estado pausado, ele retomará e começará a escalar para que possa fazer a alteração. A operação de escalabilidade para uma alteração de grupo de parâmetros sempre força a alteração de capacidade, portanto esteja ciente de que a modificação de parâmetros poderá ocasionar conexões descartadas se um ponto de escalabilidade não puder ser encontrado durante o período de escalabilidade.
Registro em log para o Aurora Serverless v1
Por padrão, logs de erros para o Aurora Serverless v1 são ativados e carregados automaticamente no Amazon CloudWatch. Você também pode fazer com que seu cluster de banco de dados do Aurora Serverless v1 carregue logs específicos do mecanismo de banco de dados do Aurora para o CloudWatch. Para fazer isso, habilite os parâmetros de configuração em seu grupo de parâmetros do seu cluster de banco de dados personalizado. Depois, seu cluster de banco de dados do Aurora Serverless v1 carrega todos os logs disponíveis para o Amazon CloudWatch. Nesse momento, é possível usar o CloudWatch para analisar os dados de log, criar alarmes e visualizar métricas.
No caso do Aurora MySQL, a tabela a seguir mostra os logs que você pode habilitar. Quando habilitados, é feito upload deles automaticamente do cluster de banco de dados do Aurora Serverless v1 para o Amazon CloudWatch.
| Log do Aurora MySQL | Descrição |
|---|---|
|
|
Cria o log geral. Defina como 1 para ativar. O padrão é desativado (0). |
|
|
Registra todas as consultas no log de consultas lentas que não usam um índice. O padrão é desativado (0). Defina como 1 para ativar esse log. |
|
|
Impede que consultas em execução rápida sejam registradas no log de consultas lentas. Pode ser definido como um float entre 0 e 3.1536.000. O padrão é 0 (não ativo). |
|
|
A lista de eventos a serem capturados nos logs. Os valores compatíveis são |
|
|
Defina como 1 para ativar o log de auditoria do servidor. Se você ativar isso, você poderá especificar os eventos de auditoria a serem enviados, CloudWatch listando-os no |
|
|
Cria um log de consulta lento. Defina como 1 para ativar o log de consulta lenta. O padrão é desativado (0). |
Para ter mais informações, consulte Como utilizar a auditoria avançada em um cluster de banco de dados do Amazon Aurora MySQL.
No caso do Aurora PostgreSQL, a tabela a seguir mostra os logs que você pode habilitar. Quando habilitados, é feito upload deles automaticamente do cluster de banco de dados do Aurora Serverless v1 para o Amazon CloudWatch com os logs de erro regulares.
| Log do Aurora PostgreSQL | Descrição |
|---|---|
|
|
Ativado por padrão e não pode ser alterado. Ele registra detalhes para todas as novas conexões de clientes. |
|
|
Ativado por padrão e não pode ser alterado. Registra todas as desconexões de clientes. |
|
|
Desativado por padrão e não pode ser alterado. Nomes de host não são registrados no log. |
|
|
O padrão é 0 (desativado). Defina como 1 para registrar esperas por bloqueio. |
|
|
A duração mínima (em milissegundos) para que uma instrução seja executada antes de ser registrada. |
|
|
Define os níveis de mensagem registrados. Os valores compatíveis são Para registrar dados de performance no log do |
|
|
Registra o uso de arquivos temporários que estão acima dos kilobytes (kB) especificados. |
|
|
Controla as instruções SQL específicas que são registradas. Os valores compatíveis são |
Depois de ativar os logs para Aurora MySQL ou Aurora PostgreSQL para o cluster de banco de dados do Aurora Serverless v1, você pode visualizá-los no CloudWatch.
Visualizar logs do Aurora Serverless v1 com o Amazon CloudWatch
O Aurora Serverless v1 carrega automaticamente (“publica”) no Amazon CloudWatch todos os logs que estão ativados em seu grupo de parâmetros de cluster de banco de dados personalizado. Você não precisa escolher ou especificar os tipos de log. O upload de logs começa assim que você habilita o parâmetro de configuração de log. Se, mais tarde, você desabilitar o parâmetro de log, os uploads serão interrompidos. No entanto, todos os logs que já foram publicados no CloudWatch permanecem até que você os exclua.
Para mais informações sobre como usar o CloudWatch com os logs do Aurora MySQL, consulte Monitorar eventos de log no Amazon CloudWatch.
Para ter mais informações sobre CloudWatch e Aurora PostgreSQL, consulte Publicar logs do Aurora PostgreSQL no Amazon CloudWatch Logs.
Para visualizar logs do cluster de banco de dados do Aurora Serverless v1
Abra o console do CloudWatch, em https://console.aws.amazon.com/cloudwatch/
. -
Escolha a Região da AWS.
-
Escolha Grupos de logs.
-
Escolha o log do cluster de banco de dados do Aurora Serverless v1 na lista. Para logs de erros, o padrão de nomenclatura é o seguinte.
/aws/rds/cluster/cluster-name/error
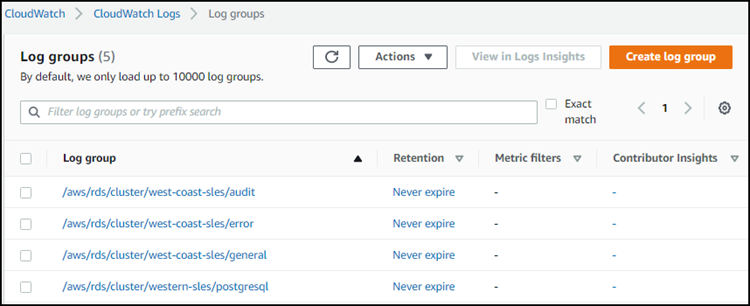
Por exemplo, no snapshot a seguir, você pode encontrar listagens para logs publicados para um cluster de banco de dados do Aurora Serverless v1 para Aurora PostgreSQL denominado western-sles. Você também pode encontrar várias listas para cluster de banco de dados do Aurora Serverless v1 para Aurora MySQL, west-coast-sles. Escolha o log de interesse para começar a explorar seu conteúdo.
Aurora Serverless v1 e manutenção
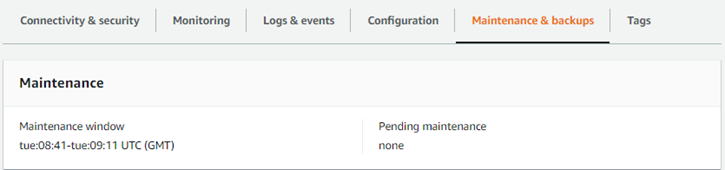
A manutenção do cluster de banco de dados do Aurora Serverless v1, como a aplicação dos recursos, das correções e das atualizações de segurança mais recentes, é realizada automaticamente para você. O Aurora Serverless v1 tem uma janela de manutenção que você pode visualizar no AWS Management Console em Manutenção e backups para seu cluster de banco de dados do Aurora Serverless v1. É possível encontrar a data e a hora em que a manutenção pode ser realizada e se alguma manutenção está pendente para o cluster de banco de dados do Aurora Serverless v1, conforme mostrado na figura a seguir.
Você pode definir a janela de manutenção ao criar o cluster de banco de dados do Aurora Serverless v1 e pode modificá-la posteriormente. Para ter mais informações, consulte Ajustar a janela de manutenção do cluster de banco de dados preferencial.
As janelas de manutenção são usadas para atualizações programadas de versões principais. Atualizações de versões secundárias e patches são aplicados imediatamente durante o ajuste de escala. O ajuste de escala ocorre de acordo com a configuração de TimeoutAction:
-
ForceApplyCapacityChange: a alteração é aplicada imediatamente. -
RollbackCapacityChange: o Aurora atualizará o cluster à força após três dias a partir da primeira tentativa.
Tal como acontece com qualquer alteração que seja forçada sem um ponto de escala apropriado, isso pode interromper sua workload.
Sempre que possível, o Aurora Serverless v1 realiza a manutenção sem causar disrupções. Quando a manutenção é necessária, o cluster de banco de dados do Aurora Serverless v1 dimensiona sua capacidade para lidar com as operações necessárias. Antes de escalar, o Aurora Serverless v1 procura um ponto de escalabilidade. Se necessário, isso será realizado por até três dias.
No fim de cada dia em que o Aurora Serverless v1 não consegue encontrar um ponto de escalabilidade, ele cria um evento de cluster. Esse evento notifica você sobre a manutenção pendente e a necessidade de dimensionar para executar a manutenção. A notificação inclui a data em que o Aurora Serverless v1 pode forçar o cluster de banco de dados a escalar.
Para ter mais informações, consulte Ação de tempo limite para alterações na capacidade.
Aurora Serverless v1 e failover
Se a instância de banco de dados de um cluster de banco de dados do Aurora Serverless v1 ficar indisponível ou a zona de disponibilidade (AZ) em que ela está estiver com falha, o Aurora recriará a instância de banco de dados em uma AZ diferente. No entanto, o cluster do Aurora Serverless v1 não é um cluster multi-AZ. O motivo disso é que ele consiste em uma única instância de banco de dados em uma única AZ. Dessa forma, esse mecanismo de failover leva mais tempo do que um cluster do Aurora com instâncias do Aurora Serverless v2 ou provisionadas. O tempo de failover do Aurora Serverless v1 é indefinido no momento, porque depende da demanda e da disponibilidade da capacidade em outras AZs na Região da AWS indicada.
Como o Aurora separa a capacidade computacional e o armazenamento, o volume de armazenamento do cluster é distribuído em várias AZs. Seus dados permanecem disponíveis mesmo que as interrupções afetem a instância de banco de dados ou a AZ associada.
Aurora Serverless v1 e snapshots
O volume do cluster de um cluster do Aurora Serverless v1 é sempre criptografado. É possível escolher a chave de criptografia, mas não é possível desabilitar a criptografia. Para copiar ou compartilhar um snapshot de um cluster do Aurora Serverless v1, criptografe o snapshot usando a sua própria AWS KMS key. Para ter mais informações, consulte Cópia de snapshot de cluster de banco de dados. Para saber mais sobre criptografia e o Amazon Aurora, consulte Criptografar um cluster de banco de dados do Amazon Aurora
