As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
MyDumper
MyDumper
-
MyDumper exporta um backup consistente dos bancos de dados MySQL. Ele suporta o backup do banco de dados usando vários threads paralelos, até um thread por núcleo de CPU disponível.
-
myloader lê os arquivos de backup criados por MyDumper, se conecta à instância do banco de dados de destino e, em seguida, restaura o banco de dados.
O diagrama a seguir mostra as etapas de alto nível envolvidas na migração de um banco de dados usando um arquivo de MyDumper backup. Esse diagrama de arquitetura inclui três opções para migrar o arquivo de backup do data center local para uma EC2 instância no. Nuvem AWS
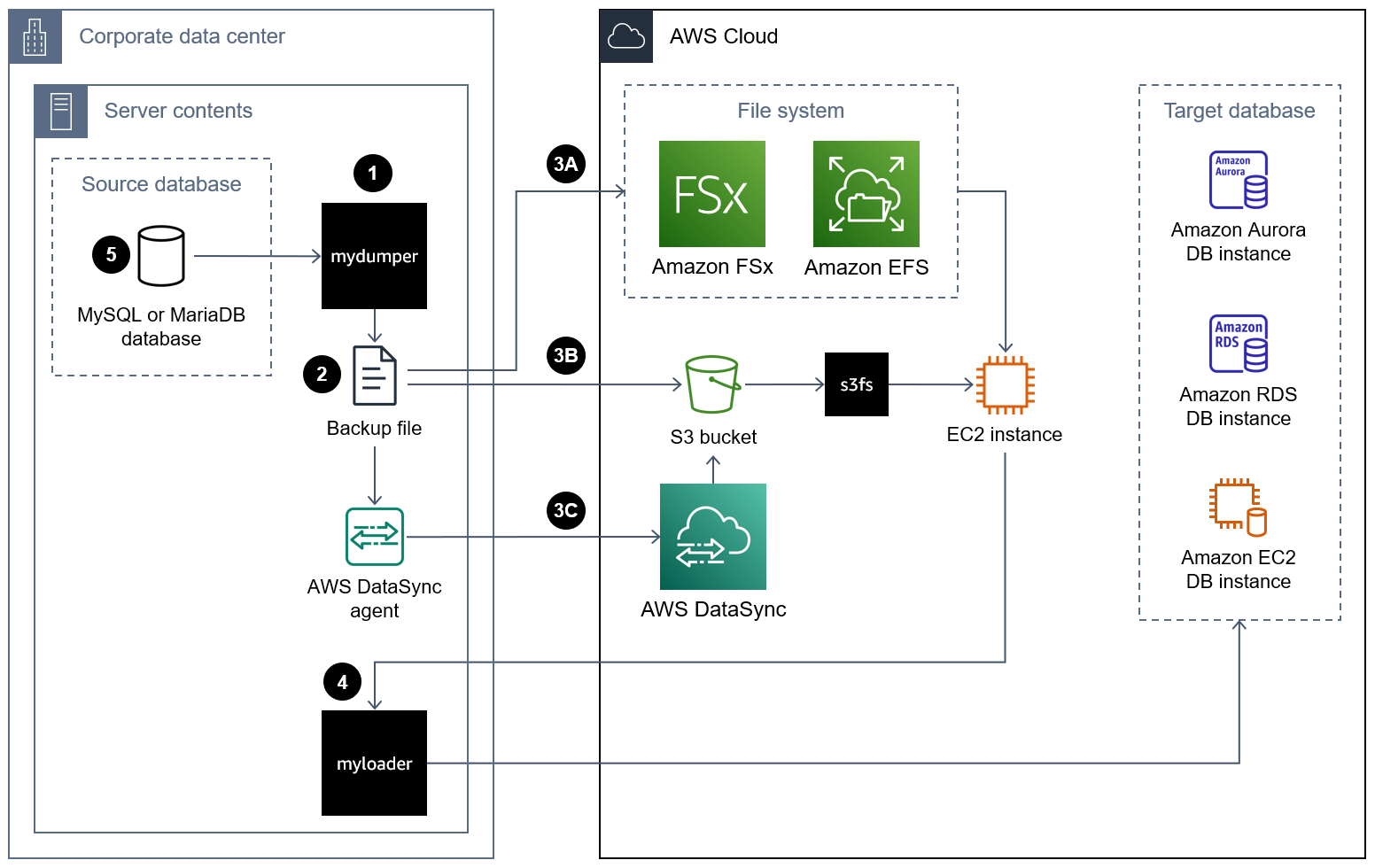
A seguir estão as etapas a serem usadas MyDumper para migrar um banco de dados para o Nuvem AWS:
-
Instale MyDumper e meu carregador. Para obter instruções, consulte Como instalar mydumper/myloader
(). GitHub -
Use MyDumper para criar um backup do banco de dados MySQL ou MariaDB de origem. Para obter instruções, consulte Como usar MyDumper
. -
Mova o arquivo de backup para uma EC2 instância no Nuvem AWS usando uma das seguintes abordagens:
Abordagem 3A — Monte um sistema de arquivos Amazon FSx ou Amazon Elastic File System (Amazon EFS) no servidor local que executa sua instância de banco de dados. Você pode usar AWS Direct Connect ou AWS VPN para estabelecer a conexão. Você pode fazer backup direto do banco de dados no compartilhamento de arquivos montado ou pode realizar o backup em duas etapas, fazendo backup do banco de dados em um sistema de arquivos local e, em seguida, carregando-o no volume montado ou FSx EFS. Em seguida, monte o sistema de arquivos Amazon FSx ou Amazon EFS, que também está montado no servidor local, em uma EC2 instância.
Abordagem 3B — Use o AWS CLI AWS SDK ou a API REST do Amazon S3 para mover diretamente o arquivo de backup do servidor local para um bucket do S3. Se o bucket do S3 de destino estiver em um Região da AWS local distante do data center, você poderá usar o Amazon S3 Transfer Acceleration para transferir o arquivo mais rapidamente. Use o sistema de arquivos s3fs-fuse
para montar o bucket S3 na instância. EC2 Abordagem 3C — Instale o AWS DataSync agente no data center local e, em seguida, use-o AWS DataSyncpara mover o arquivo de backup para um bucket do Amazon S3. Use o sistema de arquivos s3fs-fuse
para montar o bucket S3 na instância. EC2 nota
Você também pode usar o Amazon S3 File Gateway para transferir os grandes arquivos de backup do banco de dados para um bucket do S3 no. Nuvem AWS Para obter mais informações, consulte Usando o Amazon S3 File Gateway para transferir arquivos de backup neste guia.
-
Use myloader para restaurar o backup na instância do banco de dados de destino. Para obter instruções, consulte myloader usage
()GitHub. -
(Opcional) Você pode configurar a replicação entre o banco de dados de origem e a instância do banco de dados de destino. Você pode usar a replicação de log binário (binlog) para reduzir o tempo de inatividade. Para obter mais informações, consulte:
-
Definindo a configuração da fonte de replicação
na documentação do MySQL -
Para o Amazon Aurora, veja o seguinte:
-
Para o Amazon RDS, veja o seguinte:
-
Trabalhando com a replicação do MySQL na documentação do Amazon RDS
-
Trabalhando com a replicação do MariaDB na documentação do Amazon RDS
-
-
Para a Amazon EC2, veja o seguinte:
-
Configurando a replicação baseada na posição do arquivo de log binário
na documentação do MySQL -
Configurando réplicas
na documentação do MySQL -
Configurando a replicação na documentação
do MariaDB
-
-
Vantagens
-
MyDumper suporta paralelismo usando multiencadeamento, o que melhora a velocidade das operações de backup e restauração.
-
MyDumper evita rotinas caras de conversão de conjuntos de caracteres, o que ajuda a garantir que o código seja altamente eficiente.
-
MyDumper simplifica a visualização e a análise de dados usando o despejo de arquivos separados para tabelas e metadados.
-
MyDumper mantém instantâneos em todos os segmentos e fornece posições precisas dos registros primários e secundários.
-
Você pode usar expressões regulares compatíveis com Perl (PCRE) para especificar se deseja incluir ou excluir tabelas ou bancos de dados.
Limitações
-
Você pode escolher uma ferramenta diferente se seus processos de transformação de dados exigirem arquivos de despejo intermediários em formato simples em vez do formato SQL.
-
myloader não importa contas de usuário do banco de dados automaticamente. Se você estiver restaurando o backup no Amazon RDS ou no Aurora, recrie os usuários com as permissões necessárias. Para obter mais informações, consulte Privilégios da conta de usuário principal na documentação do Amazon RDS. Se você estiver restaurando o backup em uma instância de EC2 banco de dados da Amazon, poderá exportar manualmente as contas de usuário do banco de dados de origem e importá-las para a EC2 instância.
Práticas recomendadas
-
Configure MyDumper para dividir cada tabela em segmentos, como 10.000 linhas em cada segmento, e gravar cada segmento em um arquivo separado. Isso possibilita a importação dos dados em paralelo posteriormente.
-
Se você estiver usando o mecanismo InnoDB, use a
--trx-consistency-onlyopção para minimizar o bloqueio. -
O uso MyDumper para exportar o banco de dados pode exigir muita leitura, e o processo pode afetar o desempenho geral do banco de dados de produção. Se você tiver uma instância de banco de dados de réplica, execute o processo de exportação a partir da réplica. Antes de executar a exportação da réplica, interrompa o thread SQL de replicação. Isso ajuda o processo de exportação a ser executado mais rapidamente.
-
Não exporte o banco de dados durante o horário comercial de pico. Evitar os horários de pico pode estabilizar o desempenho do seu banco de dados de produção principal durante a exportação do banco de dados.
-
O Amazon RDS for MySQL não
keyring_awsé compatível com o plug-in. Para obter mais informações, consulte Problemas e limitações conhecidos. Para migrar as tabelas criptografadas locais para a instância do Amazon RDS, nos scripts de backup, você precisa removerENCRYPTIONouDEFAULT ENCRYPTIONremover a sintaxe.CREATE TABLEPara criptografia em repouso, você pode usar uma chave AWS Key Management Service (AWS KMS). Para ter mais informações, consulte Criptografar recursos do Amazon RDS.
