O Amazon Redshift não permitirá mais a criação de funções definidas pelo usuário (UDFs) do Python a partir de 1.º de novembro de 2025. Se quiser usar UDFs do Python, você deve criá-las antes dessa data. As UDFs do Python existentes continuarão a funcionar normalmente. Para ter mais informações, consulte a publicação de blog
Tutorial: Carregar dados do Amazon S3
Neste tutorial, você percorre o processo de carregamento de dados nas tabelas de banco de dados do Amazon Redshift a partir de arquivos de dados em um bucket do Amazon S3 do início ao fim.
Neste tutorial, você faz o seguinte:
-
Baixa os arquivos de dados que usam formatos separados por vírgulas (CSV), delimitado por caracteres e de largura fixa.
-
Cria um bucket do Amazon S3 e carrega os arquivos de dados para o bucket.
-
Inicia um cluster do Amazon Redshift e cria tabelas de banco de dados.
-
Usa os comandos COPY para carregar as tabelas dos arquivos de dados no Amazon S3.
-
Soluciona erros de carga e modifica os comandos COPY para corrigir os erros.
Pré-requisitos
Você precisa dos seguintes pré-requisitos:
-
Uma conta da AWS para iniciar um cluster do Amazon Redshift e criar um bucket no Amazon S3.
-
Suas credenciais da AWS (função do IAM) para carregar dados de teste do Amazon S3. Se precisar de um novo perfil do IAM, acesse Criar perfis do IAM.
-
Um cliente SQL, como o editor de consulta do console do Amazon Redshift.
Este tutorial foi projetado de maneira que possa ser seguido sozinho. Além deste tutorial, recomendamos concluir os seguintes tutoriais para obter uma compreensão mais completa de como projetar e usar bancos de dados do Amazon Redshift:
-
O Guia de conceitos básicos do Amazon Redshift orienta você no processo de criação de um cluster do Amazon Redshift e de carregamento dos dados de exemplo.
Visão geral
Você pode adicionar dados às tabelas do Amazon Redshift usando um comando INSERT ou um comando COPY. Na escala e na velocidade de um data warehouse do Amazon Redshift, o comando COPY é muitas vezes mais rápido e eficiente do que os comandos INSERT.
O comando COPY usa a arquitetura de processamento massivamente paralelo (MPP) do Amazon Redshift para ler e carregar dados em paralelo de várias fontes de dados. Você pode carregar arquivos de dados no Amazon S3, Amazon EMR ou qualquer host remoto acessível por meio de uma conexão Secure Shell (SSH). Ou você pode carregar diretamente de uma tabela do Amazon DynamoDB.
Neste tutorial, você usa o comando COPY para carregar dados do Amazon S3. Muitos dos princípios apresentados aqui também se aplicam ao carregamento de outras fontes de dados.
Para saber mais sobre como usar o comando COPY, consulte estes recursos:
Etapa 1: criar um cluster
Se já tiver um cluster que quiser usar, você poderá ignorar esta etapa.
Para os exercícios deste tutorial, você usa um cluster de quatro nós.
Para criar um cluster
-
Faça login no AWS Management Console e abra o console do Amazon Redshift em https://console.aws.amazon.com/redshiftv2/
. Usando o menu de navegação, escolha Painel de clusters provisionados.
Importante
Verifique se o você tem as permissões necessárias para executar as operações de cluster. Para obter informações sobre como conceder as permissões necessárias, consulte Autorizar o Amazon Redshift a acessar serviços da AWS.
-
Na parte superior direita, escolha a região da AWS onde você deseja criar o cluster. Para este tutorial, escolha Oeste dos EUA (Oregon).
-
No menu de navegação, escolha Clusters e Create cluster (Criar cluster). A página Create cluster (Criar cluster) é exibida.
-
Na página Create cluster (Criar cluster), insira parâmetros do cluster. Escolha seus valores para os parâmetros, sem alterar os seguintes valores:
Escolha
dc2.largepara o tipo de nó.Escolha
4em Number of nodes (Número de nós).Na seção Cluster permissions (Permissões do cluster), escolha uma função do IAM em Available IAM roles (Funções do IAM disponíveis). Essa função deve ser uma que você criou anteriormente e que tem acesso ao Amazon S3. Depois, escolha Associate IAM role (Associar função do IAM) para adicioná-la à lista de Associated IAM roles (Funções do IAM associadas) do cluster.
-
Selecione Criar cluster.
Siga as etapas do Guia de conceitos básicos do Amazon Redshift para se conectar de um cliente SQL ao seu cluster e testar uma conexão. Você não precisa concluir as etapas de Conceitos básicos restantes para criar tabelas, fazer upload de dados e testar consultas de exemplo.
Etapa 2: Fazer download dos arquivos de dados
Nesta etapa, você baixará um conjunto de arquivos de dados de exemplo no computador. Na próxima etapa, você carrega os arquivos em um bucket do Amazon S3.
Para baixar os arquivos de dados
-
Baixe o arquivo compactado: LoadingDataSampleFiles.zip.
-
Extraia os arquivos para uma pasta no computador.
-
Verifique se a pasta contém os arquivos a seguir.
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Etapa 3: Carregar arquivos para um bucket do Amazon S3
Nesta etapa, você cria um bucket do Amazon S3 e carrega os arquivos de dados para o bucket.
Para carregar arquivos para um bucket do Amazon S3
-
Crie um bucket no Amazon S3.
Para obter mais informações sobre como criar um bucket, consulte Criar um bucket, no Guia do usuário do Amazon Simple Storage Service.
-
Faça login no AWS Management Console e abra o console do Amazon S3 em https://console.aws.amazon.com/s3/
. -
Escolha Criar bucket.
-
Escolha um Região da AWS.
Crie o bucket na mesma região do cluster. Se o cluster estiver na região Oeste dos EUA (Oregon), escolha US West (Oregon) Region (us-west-2).
-
Na caixa Nome do bucket da caixa de diálogo Criar um bucket, digite o nome de um bucket.
O nome de bucket que você escolher deve ser único entre todos os nomes de bucket existentes no Amazon S3. Uma forma de ajudar a garantir a exclusividade é prefixar seus nomes de bucket com o nome de sua organização. Os nomes de bucket devem estar em conformidade com determinadas regras. Para obter mais informações, acesse Restrições e limitações de bucket no Guia do usuário do Amazon Simple Storage Service.
-
Escolha os padrões recomendados para o restante das opções.
-
Escolha Criar bucket.
Quando o Amazon S3 cria seu bucket com sucesso, o console exibe seu bucket vazio no painel Buckets.
-
-
Crie uma pasta.
-
Escolha o nome do novo bucket.
-
Selecione o botão Criar pasta.
-
Nomeie a nova pasta como
load.nota
O bucket que você criou não está em um sandbox. Neste exercício, você adiciona objetos a um bucket real. Um valor nominal é cobrado pelo tempo em que você armazena os objetos no bucket. Para obter mais informações sobre preços do Amazon S3, consulte Preço do Amazon S3
.
-
-
Carregue arquivos de dados para o novo bucket do Amazon S3.
-
Escolha o nome da pasta de dados.
-
No assistente de upload, escolha Adicionar arquivos.
Siga as instruções do console do Amazon S3 para carregar todos os arquivos que você baixou e extraiu.
-
Escolha Carregar.
-
Credenciais do usuário
O comando COPY do Amazon Redshift deve ter acesso para ler os objetos de arquivo no bucket do Amazon S3. Se você usar as mesmas credenciais de usuário para criar o bucket do Amazon S3 e para executar o comando COPY do Amazon Redshift, o comando COPY tem todas as permissões necessárias. Se quiser usar credenciais de usuário diferentes, você pode conceder acesso usando os controles de acesso do Amazon S3. O comando COPY do Amazon Redshift requer pelo menos as permissões ListBucket e GetObject para acessar os objetos de arquivo no bucket do Amazon S3. Para obter mais informações sobre como controlar o acesso aos recursos do Amazon S3, consulte Gerenciar permissões de acesso aos recursos do Amazon S3.
Etapa 4: Criar as tabelas de exemplo
Neste tutorial, você usará um conjunto de tabelas baseadas no esquema Star Schema Benchmark (SSB). O diagrama a seguir mostra o modelo de dados SSB.
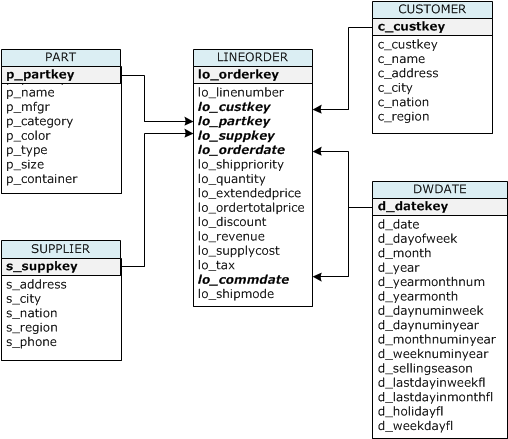
As tabelas SSB talvez já existam no banco de dados atual. Nesse caso, descarte as tabelas para removê-las do banco de dados antes de criá-las usando os comandos CREATE TABLE na próxima etapa. As tabelas usadas neste tutorial podem ter atributos diferentes das tabelas existentes.
Para criar as tabelas de exemplo
-
Para remover tabelas SSB, execute os comandos a seguir no cliente SQL.
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
Execute os comandos CREATE TABLE a seguir em seu cliente SQL.
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
Etapa 5: Executar os comandos COPY
Você executa os comandos COPY para carregar cada uma das tabelas no esquema SSB. Os exemplos de comando COPY demonstram como carregar de formatos de arquivo diferentes usando várias opções de comando COPY e solucionando erros de carga.
Sintaxe do comando COPY
A seguir, a sintaxe básica do comando COPY.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
Para executar um comando COPY, forneça os valores a seguir.
Nome da tabela
A tabela de destino do comando COPY. A tabela já deve existir no banco de dados. A tabela pode ser temporária ou persistente. O comando COPY acrescenta os novos dados de entrada a todas as linhas existentes na tabela.
Lista de colunas
Por padrão, COPY carrega campos dos dados de origem para as colunas da tabela na ordem. Você pode especificar uma lista de colunas, uma lista separada por vírgulas de nomes de coluna, a fim de mapear campos de dados para colunas específicas. Você não usa listas de colunas neste tutorial. Para obter mais informações, consulte Column List na referência do comando COPY.
Fonte de dados
Você pode usar o comando COPY para carregar dados de um bucket do Amazon S3, um cluster do Amazon EMR, um host remoto usando uma conexão SSH ou uma tabela do Amazon DynamoDB. Para este tutorial, você carrega de arquivos de dados em um bucket do Amazon S3. Ao carregar do Amazon S3, você deve fornecer o nome do bucket e a localização dos arquivos de dados. Para fazer isso, forneça o caminho de um objeto para os arquivos de dados ou a localização de um arquivo manifesto que lista explicitamente cada arquivo de dados e sua localização.
-
Prefixo de chaves
Um objeto armazenado no Amazon S3 é identificado exclusivamente por uma chave de objeto, que inclui o nome do bucket, os nomes das pastas, se houver, e o nome do objeto. Um prefixo de chaves se refere a um conjunto de objetos com o mesmo prefixo. O caminho do objeto é um prefixo de chaves usado pelo comando COPY para carregar todos os objetos que compartilham o prefixo de chaves. Por exemplo, o prefixo de chaves
custdata.txtpode referenciar um único arquivo ou um conjunto de arquivos, inclusivecustdata.txt.001custdata.txt.002e assim por diante. -
Arquivo manifesto
Em alguns casos, pode ser necessário carregar os arquivos com prefixos diferentes, por exemplo, de vários buckets ou pastas. Em outros, pode ser necessário excluir arquivos que compartilham um prefixo. Nesses casos, é possível usar um arquivo manifesto. Um arquivo manifesto lista cada arquivo de carga e a chave de objeto exclusiva. Você usa um arquivo manifesto para carregar a tabela PART posteriormente neste tutorial.
Credenciais
Para acessar os recursos da AWS que contêm os dados a serem carregados, você deve fornecer as credenciais de acesso da AWS a um usuário com privilégios suficientes. Essas credenciais incluem um nome do recurso da Amazon (ARN) da função do IAM. Para carregar dados do Amazon S3, as credenciais devem incluir as permissões ListBucket e GetObject. Serão necessárias outras credenciais, se os dados estiverem criptografados. Para obter mais informações, consulte Parâmetros de autorização na referência do comando COPY. Para obter mais informações sobre como gerenciar o acesso, consulte Gerenciar permissões de acesso aos seus recursos do Amazon S3.
Opções
Você pode especificar vários parâmetros com o comando COPY para especificar formatos de arquivo, gerenciar formatos de dados, gerenciar erros e controlar outros recursos. Neste tutorial, você usa as seguintes opções e os seguintes recursos do comando COPY:
-
Prefixo de chaves
Para obter informações sobre como carregar de vários arquivos especificando um prefixo de chave, consulte Carregar a tabela PART usando NULL AS.
-
Formato CSV
Para obter informações sobre como carregar dados que estão no formato CSV, consulte Carregar a tabela PART usando NULL AS.
-
NULL AS
Para obter informações sobre como carregar PART usando a opção NULL AS, consulte Carregar a tabela PART usando NULL AS.
-
Formato delimitado por caracteres
Para obter informações sobre como usar a opção DELIMITER, consulte As opções DELIMITER e REGION.
-
REGION
Para obter informações sobre como usar a opção REGION, consulte As opções DELIMITER e REGION.
-
Largura de formato fixo
Para obter informações sobre como carregar a tabela CUSTOMER de dados de largura fixa, consulte Carregar a tabela CUSTOMER usando MANIFEST.
-
MAXERROR
Para obter informações sobre como usar a opção MAXERROR, consulte Carregar a tabela CUSTOMER usando MANIFEST.
-
ACCEPTINVCHARS
Para obter informações sobre como usar a opção ACCEPTINVCHARS, consulte Carregar a tabela CUSTOMER usando MANIFEST.
-
MANIFEST
Para obter informações sobre como usar a opção MANIFEST, consulte Carregar a tabela CUSTOMER usando MANIFEST.
-
DATEFORMAT
Para obter informações sobre como usar a opção DATEFORMAT, consulte Carregar a tabela DWDATE usando DATEFORMAT.
-
GZIP, LZOP e BZIP2
Para obter informações sobre como compactar arquivos, consulte Carregar vários arquivos de dados.
-
COMPUPDATE
Para obter informações sobre como usar a opção COMPUPDATE, consulte Carregar vários arquivos de dados.
-
Vários arquivos
Para obter informações sobre como carregar vários arquivos, consulte Carregar vários arquivos de dados.
Carregar as tabelas SSB
Você usa os comandos COPY a seguir para carregar cada uma das tabelas no esquema SSB. O comando para cada tabela demonstra opções de COPY e técnicas para solução de problemas diferentes.
Para carregar as tabelas SSB, siga estas etapas:
Substituir o nome do bucket e as credenciais da AWS
Os comandos COPY neste tutorial são apresentados no formato a seguir.
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
Para cada comando COPY, faça o seguinte:
-
Substitua
<your-bucket-name>pelo nome de um bucket na mesma região do cluster.Essa etapa pressupõe que o bucket e o cluster estejam na mesma região. Você também pode especificar a região usando a opção REGION com o comando COPY.
-
Substitua
<aws-account-id>e<role-name>por sua Conta da AWS e função do IAM. O segmento da string de credenciais entre aspas não deve conter espaços ou quebras de linha. O formato do ARN pode ser levemente diferente do formato da amostra. Ao executar os comandos COPY, é melhor copiar o ARN do perfil pelo console do IAM, para garantir que ele seja preciso.
Carregar a tabela PART usando NULL AS
Nesta etapa, você usa as opções CSV e NULL AS para carregar a tabela PART.
O comando COPY pode carregar dados de vários arquivos em paralelo, o que é muito mais rápido do que carregar de um único arquivo. Para demonstrar esse princípio, os dados de cada tabela neste tutorial estão divididos em oito arquivos, mesmo que os arquivos sejam muito pequenos. Em uma etapa posterior, você compara a diferença de tempo entre o carregamento de um único arquivo e carregar de vários arquivos. Para obter mais informações, consulte Carregar arquivos de dados.
Prefixo de chaves
Você pode carregar de vários arquivos especificando um prefixo de chaves para o conjunto de arquivos ou listando explicitamente os arquivos em um arquivo manifesto. Nesta etapa, você usa um prefixo de chaves. Em uma etapa posterior, você usa um arquivo manifesto. O prefixo de chaves 's3://amzn-s3-demo-bucket/load/part-csv.tbl' carrega o conjunto de arquivos a seguir na pasta load.
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Formato CSV
CSV, que significa comma separated values, ou valores separados por vírgulas, é um formato comum usado para importar e exportar dados da planilha. CSV é mais flexível do que o formato delimitado por vírgulas porque permite incluir strings de aspas dentro dos campos. O caractere de aspa padrão para o formato COPY from CSV é uma aspa dupla ("), mas você pode especificar outro caractere de aspa usando a opção QUOTE AS. Ao usar aspas dentro do campo, escape o caractere com aspas adicionais.
O seguinte trecho de um arquivo de dados formatado em CSV para a tabela PART mostra strings entre aspas duplas ("LARGE ANODIZED
BRASS"). Ele também mostra uma string entre aspas duplas dentro da string entre aspas ("MEDIUM ""BURNISHED"" TIN").
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
Os dados da tabela PART contêm caracteres que causam uma falha no comando COPY. Neste exercício, você soluciona problemas e corrige-os.
Para carregar dados que estejam em formato CSV, adicione csv ao comando COPY. Execute o comando a seguir para carregar a tabela PART.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
Você poderá receber uma mensagem de erro semelhante à mensagem a seguir.
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
Para obter mais informações sobre o erro, consulte a tabela STL_LOAD_ERRORS. A consulta a seguir usar a função SUBSTRING para encurtar colunas para fins de legibilidade e usa LIMIT 10 para reduzir o número de linhas retornadas. Você pode ajustar os valores em substring(filename,22,25) para permitir o comprimento do nome do bucket.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL AS
Os arquivos de dados part-csv.tbl usam o caractere terminador NUL (\x000 ou \x0) para indicar valores NULL.
nota
Apesar da ortografia muito semelhante, NUL e NULL não são iguais. NUL é um caractere UTF-8 com codepoint x000 normalmente usado para indicar End Of Record (EOR – Fim do registro). NULL é um valor SQL que representa uma ausência de dados.
Por padrão, COPY trata um caractere terminador NUL como um caractere EOR e encerra o registro, o que normalmente acarreta em resultados inesperados ou em um erro. Não existe um único método padrão para indicar NULL em dados de texto. Assim, a opção do comando NULL AS COPY permite especificar qual caractere substituir por NULL ao carregar a tabela. Neste exemplo, você deseja que COPY trate o caractere terminador NUL como um valor NULL.
nota
A coluna da tabela que recebe o valor NULL deve ser configurada como anulável. Ou seja, ela não deve incluir a restrição NOT NULL na especificação CREATE TABLE.
Para carregar PART usando a opção NULL AS, execute o comando COPY a seguir.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
Para verificar se o COPY carregou valores NULL, execute o comando a seguir para selecionar somente as linhas que contenham NULL.
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
As opções DELIMITER e REGION
As opções DELIMITER e REGION são importantes para entender como carregar os dados.
Formato delimitado por caracteres
Os campos em um arquivo delimitado por caracteres são separados por um caractere específico, como uma barra ( | ), uma vírgula ( , ) ou uma tabulação ( \t ). Os arquivos delimitados por caractere podem usar qualquer caractere ASCII único, inclusive um dos caracteres ASCII não imprimíveis, como o delimitador. Você especifica o caractere delimitador usando a opção DELIMITER. O delimitador padrão é um caractere de barra ( | ).
O trecho a seguir dos dados da tabela SUPPLIER usa o formato delimitado por barras.
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
REGION
Sempre que possível, você deve localizar seus dados de carga na mesma região da AWS do cluster do Amazon Redshift. Se seus dados e cluster estiverem na mesma região, você reduz a latência e evita custos de transferência de dados entre regiões. Para obter mais informações, consulte Práticas recomendadas do Amazon Redshift para carregamento de dados.
Se você precisar carregar dados de uma região da AWS diferente, use a opção REGION para especificar a região da AWS na qual os dados de carga estão localizados. Se você especificar uma região, todos os dados da carga, inclusive arquivos manifestos, deverão estar na região nomeada. Para obter mais informações, consulte REGION.
Por exemplo, se o cluster estiver na região Leste dos EUA (Norte da Virgínia) e o bucket do Amazon S3 estiver na região Oeste dos EUA (Oregon), o comando COPY a seguir mostrará como carregar a tabela SUPPLIER usando dados delimitados por pipe.
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
Carregar a tabela CUSTOMER usando MANIFEST
Nesta etapa, você usa as opções FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS e MANIFEST para carregar a tabela CUSTOMER.
Os dados de exemplo deste exercício contêm caracteres que causam erros quando COPY tenta carregá-los. Você usa a opção MAXERRORS e a tabela do sistema STL_LOAD_ERRORS para solucionar erros de carga e usa as opções ACCEPTINVCHARS e MANIFEST para eliminar os erros.
Formato de largura fixa
O formato de largura fixa define cada campo como um número de caracteres fixo, em vez de separar campos com um delimitador. O trecho a seguir dos dados da tabela CUSTOMER usa o formato de largura fixa.
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
A ordem dos pares de rótulo/largura deve corresponder exatamente à ordem das colunas da tabela. Para obter mais informações, consulte FIXEDWIDTH.
A seguir, a string de especificação de largura fixa dos dados da tabela CUSTOMER.
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
Para carregar a tabela CUSTOMER de dados de largura fixa, execute o comando a seguir.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
Você deve receber uma mensagem de erro, semelhante à mensagem a seguir.
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
Por padrão, a primeira vez em que COPY encontra um erro, o comando falha e retorna uma mensagem de erro. Para economizar tempo durante testes, você pode usar a opção MAXERROR para instruir COPY a ignorar um número especificado de erros antes de falhar. Como esperamos erros na primeira vez em que testamos o carregamento dos dados da tabela CUSTOMER, adicionamos maxerror 10 ao comando COPY.
Para testar usando as opções FIXEDWIDTH e MAXERROR, execute o comando a seguir.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
Desta vez, em vez de uma mensagem de erro, você recebe uma mensagem de aviso semelhante à que se segue.
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
O aviso indica que COPY encontrou sete erros. Para verificar erros, consulte a tabela STL_LOAD_ERRORS, conforme mostrado no exemplo a seguir.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
Os resultados da consulta STL_LOAD_ERRORS devem ser semelhantes aos resultados a seguir.
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
Examinando os resultados, você pode ver que existem duas mensagens na coluna error_reasons:
-
Invalid digit, Value '#', Pos 0, Type: IntegEsses erros são causados pelo arquivo
customer-fw.tbl.log. O problema é que se trata de um arquivo de log, não um arquivo de dados, e não deve ser carregado. Você pode usar um arquivo manifesto para evitar carregar o arquivo errado. -
String contains invalid or unsupported UTF8O tipo de dados VARCHAR dá suporte a caracteres UTF-8 multibyte até três bytes. Se os dados de carga contiverem caracteres incompatíveis ou inválidos, você poderá usar a opção ACCEPTINVCHARS para substituir cada caractere inválido por um caractere alternativo especificado.
Outro problema com a carga é mais difícil de detectar — a carga produziu resultados inesperados. Para investigar esse problema, execute o comando a seguir para consultar a tabela CUSTOMER.
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
As linhas devem ser exclusivas, mas há duplicações.
Outra maneira de verificar se há resultados inesperados é consultar o número de linhas que foram carregadas. Em nosso caso, 100.000 linhas devem ter sido carregadas, mas a mensagem de carga relatou o carregamento de 112.497. As linhas extra foram carregadas porque COPY carregou um arquivo estranho, customer-fw.tbl0000.bak.
Neste exercício, você usa um arquivo manifesto para evitar carregar os arquivos errados.
ACCEPTINVCHARS
Por padrão, quando encontra um caractere que não seja compatível com o tipo de dados da coluna, COPY ignora a linha retorna um erro. Para obter informações sobre caracteres UTF-8 inválidos, consulte Erros no carregamento de caracteres multibyte.
Você pode usar a opção MAXERRORS para ignorar erros e continuar carregando, a consulta STL_LOAD_ERRORS para localizar os caracteres inválidos e corrigir os arquivos de dados. Porém, MAXERRORS é mais bem usado na solução de problemas de carga e normalmente não deve ser usado em um ambiente de produção.
A opção ACCEPTINVCHARS normalmente é uma opção melhor para gerenciar caracteres inválidos. ACCEPTINVCHARS orienta COPY a substituir cada caractere inválido por um caractere válido especificado e continuar a operação de carga. Você pode especificar qualquer caractere ASCII válido, exceto NULL, como o caractere substituto. O caractere de substituição padrão é um ponto de interrogação (? ). COPY substitui caracteres multibyte por uma string de substituição de comprimento igual. Por exemplo, um caractere de 4 bytes seria substituído por '????'.
COPY retorna o número de linhas que continham caracteres UTF-8 errados. Ele também adiciona uma entrada à tabela STL_REPLACEMENTS para cada linha afetada, até um máximo de 100 linhas por fatia de nó. Os caracteres UTF-8 inválidos adicionais também são substituídos, mas esses eventos substitutos não são registrados.
ACCEPTINVCHARS só é válido para colunas VARCHAR.
Para esta etapa, você adiciona o ACCEPTINVCHARS com o caractere de substituição '^'.
MANIFEST
Quando você COPY do Amazon S3 usando um prefixo das chave, há o risco de carregar tabelas indesejadas. Por exemplo, a pasta 's3://amzn-s3-demo-bucket/load/ contém oito arquivos de dados que compartilham o prefixo de chaves customer-fw.tbl: customer-fw.tbl0000, customer-fw.tbl0001 e assim por diante. Porém, a mesma pasta também contém arquivos estranhos customer-fw.tbl.log e customer-fw.tbl-0001.bak.
Para garantir que você carregue todos os arquivos corretos, e somente os corretos, use um arquivo manifesto. Manifesto é um arquivo de texto em formato JSON que lista explicitamente a chave de objeto exclusiva para cada arquivo de origem a ser carregado. Os objetos de arquivo podem estar em pastas ou em buckets diferentes, mas devem estar na mesma região. Para obter mais informações, consulte MANIFEST.
A seguir, o texto customer-fw-manifest.
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
Para carregar os dados da tabela CUSTOMER usando o arquivo manifesto
-
Abra o arquivo
customer-fw-manifestem um editor de texto. -
Substitua
<your-bucket-name>pelo nome do seu bucket. -
Salve o arquivo.
-
Faça upload do arquivo na pasta de carga do bucket.
-
Execute o comando COPY a seguir.
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
Carregar a tabela DWDATE usando DATEFORMAT
Nesta etapa, você usa as opções DELIMITER e DATEFORMAT para carregar a tabela DWDATE.
Ao carregar as colunas DATE e TIMESTAMP, COPY espera o formato padrão, que é AAAA-MM-DD para datas e AAAA-MM-DD HH:MI SS para timestamps. Se os dados de carga não usarem um formato padrão, você poderá usar DATEFORMAT e TIMEFORMAT para especificar o formato.
O trecho a seguir mostra formatos de data na tabela DWDATE. Observe que os formatos de data na coluna dois são inconsistentes.
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
DATEFORMAT
Você pode especificar somente um formato de data. Se os dados de carga contiverem formatos inconsistentes, possivelmente em colunas diferentes, ou se o formato não for conhecido no tempo de carregamento, você usará DATEFORMAT com o argumento 'auto'. Quando 'auto' for especificado, COPY reconhece qualquer formato de data ou hora válido e o converterá no formato padrão. A opção 'auto' reconhece diversos formatos não compatíveis ao usar uma string DATEFORMAT e TIMEFORMAT. Para obter mais informações, consulte Usar o reconhecimento automático com DATEFORMAT e TIMEFORMAT.
Para carregar a tabela DWDATE, execute o comando COPY a seguir.
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
Carregar vários arquivos de dados
Você pode usar as opções GZIP e COMPUPDATE para carregar uma tabela.
Você pode carregar uma tabela usando um único arquivo de dados ou vários arquivos. Isso permite comparar os tempos de carregamento dos dois métodos.
GZIP, LZOP e BZIP2
Você pode compactar os arquivos usando os formatos de compactação gzip, lzop ou bzip2. Ao carregar de arquivos compactados, COPY descompacta os arquivos durante o processo de carga. Compactar os arquivos economiza espaço de armazenamento e encurta tempos de upload.
COMPUPDATE
Quando carrega uma tabela vazia sem codificações de compactação, COPY analisa os dados de carga para determinar as codificações ideais. Em seguida, ele altera a tabela para usar essas codificações antes de iniciar a carga. Esse processo de análise demora, mas ocorre, no máximo, uma vez por tabela. Para economizar tempo, você pode ignorar esta etapa desativando COMPUPDATE. Para permitir uma avaliação precisa dos tempos de COPY, você desativa COMPUPDATE para esta etapa.
Vários arquivos
O comando COPY pode carregar dados de maneira muito eficiente ao carregar de vários arquivos em paralelo, em vez de carregar de um único arquivo. É possível dividir seus dados em arquivos de modo que o número de arquivos seja um múltiplo do número de fatias em seu cluster. Se você fizer isso, o Amazon Redshift dividirá o workload e distribuirá os dados uniformemente entre as fatias. O número de fatias por nó depende do tamanho do nó do cluster. Para obter mais informações sobre o número de fatias que cada tamanho de nó possui, consulte “Clusters e nós no Amazon Redshift” no Guia de gerenciamento de clusters do Amazon Redshift.
Por exemplo, neste tutorial, os nós de computação no cluster podem ter duas fatias cada; portanto, um cluster com quatro nós tem oito fatias. Em etapas anteriores, os dados da carga estavam contidos em oito arquivos, mesmo que os arquivos fossem muito pequenos. Nesta etapa, você compara a diferença de tempo entre o carregamento de um único arquivo grande e o carregamento de vários arquivos.
Até mesmo arquivos que contêm 15 milhões de registros e ocupam 1,2 GB são muito pequenos na escala do Amazon Redshift. Mas eles são suficientes para demonstrar a vantagem em termos de performance de carregar de vários arquivos.
A imagem a seguir mostra os arquivos de dados para a tabela LINEORDER.

Para avaliar a performance de COPY com vários arquivos
-
Em um teste de laboratório, o comando a seguir foi executado para fazer o COPY usando um único arquivo. Este comando mostra um bucket fictício.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Os resultados são mostrados a seguir. Observe o tempo de execução.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
Em seguida, o comando abaixo foi executado para fazer o COPY usando vários arquivos.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Os resultados são mostrados a seguir. Observe o tempo de execução.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
Compare tempos de execução.
No nosso experimento, o tempo para carregar 15 milhões de registros diminuiu de 51,56 segundos para 17,7 segundos, uma redução de 65,7%.
Esses resultados se baseiam no uso de um cluster de quatro nós. Se o cluster tiver mais nós, o tempo economizado será multiplicado. Para clusters típicos do Amazon Redshift, com dezenas a centenas de nós, a diferença é ainda mais dramática. Se você tiver um único cluster de nó, haverá pouca diferença entre os tempos de execução.
Etapa 6: Vacuum e análise do banco de dados
Sempre que adicionar, excluir ou modificar um número significativo de linhas, você deve executar um comando VACUUM e depois um comando ANALYZE. Uma limpeza recupera o espaço de linhas excluídas e restaura a ordem de classificação. O comando ANALYZE atualiza os metadados de estatísticas, o que permite ao otimizador de consultas gerar planos de consulta mais precisos. Para obter mais informações, consulte Vacuum de tabelas.
Se você carregar os dados na ordem da chave de classificação, a limpeza será rápida. Neste tutorial, você adicionou um número significativo de linhas, mas as adicionou a tabelas vazias. Sendo esse o caso, não há necessidade de corrigir, e você não excluiu linhas. COPY atualizará automaticamente estatísticas de atualizações depois de carregar uma tabela vazia, logo, as estatísticas devem permanecer atualizadas. Porém, por uma questão de boas práticas de manutenção, você conclui este tutorial limpando e analisando o banco de dados.
Para limpar e analisar o banco de dados, execute os comandos a seguir.
vacuum; analyze;
Etapa 7: limpar os recursos
O cluster continua acumulando cobranças enquanto está em execução. Ao concluir este tutorial, você deve retornar seu ambiente ao estado anterior seguindo as etapas na Etapa 5: Revogar o acesso e excluir sua amostra de cluster no Guia de conceitos básicos do Amazon Redshift.
Caso queira manter o cluster, mas recuperar o armazenamento usado pelas tabelas SSB, execute os comandos a seguir.
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
Próximo
Resumo
Neste tutorial, você carregou arquivos de dados no Amazon S3 e, em seguida, usou os comandos COPY para carregar os dados dos arquivos nas tabelas do Amazon Redshift.
Você carregou dados usando os seguintes formatos:
-
Delimitado por caracteres
-
CSV
-
Largura fixa
Você usou a tabela do sistema STL_LOAD_ERRORS para solucionar erros de carga e usou as opções REGION, MANIFEST, MAXERROR, ACCEPTINVCHARS, DATEFORMAT e NULL AS para resolver os erros.
Você aplicou estas melhores práticas para carregar dados:
Para obter mais informações sobre as práticas recomendadas do Amazon Redshift, consulte os seguintes links:
