As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Conectar-se à fonte de dados
No Amazon SageMaker Canvas, você pode importar dados de um local fora do seu sistema de arquivos local por meio de um AWS serviço, uma plataforma SaaS ou outros bancos de dados usando conectores JDBC. Por exemplo, para importar tabelas de um data warehouse no Amazon Redshift ou para importar dados do Google Analytics.
Ao passar pelo fluxo de trabalho de Importação para importar dados na aplicação Canvas, você pode escolher sua fonte de dados e, em seguida, selecionar os dados que deseja importar. Para determinadas fontes de dados, como o Snowflake e o Amazon Redshift, você deve especificar suas credenciais e adicionar uma conexão à fonte de dados.
A captura de tela a seguir mostra a barra de ferramentas das fontes de dados no fluxo de trabalho de Importação, com todas as fontes de dados disponíveis destacadas. Você só pode importar dados das fontes de dados que estão disponíveis para você. Entre em contato com o administrador se a fonte de dados desejada não estiver disponível.
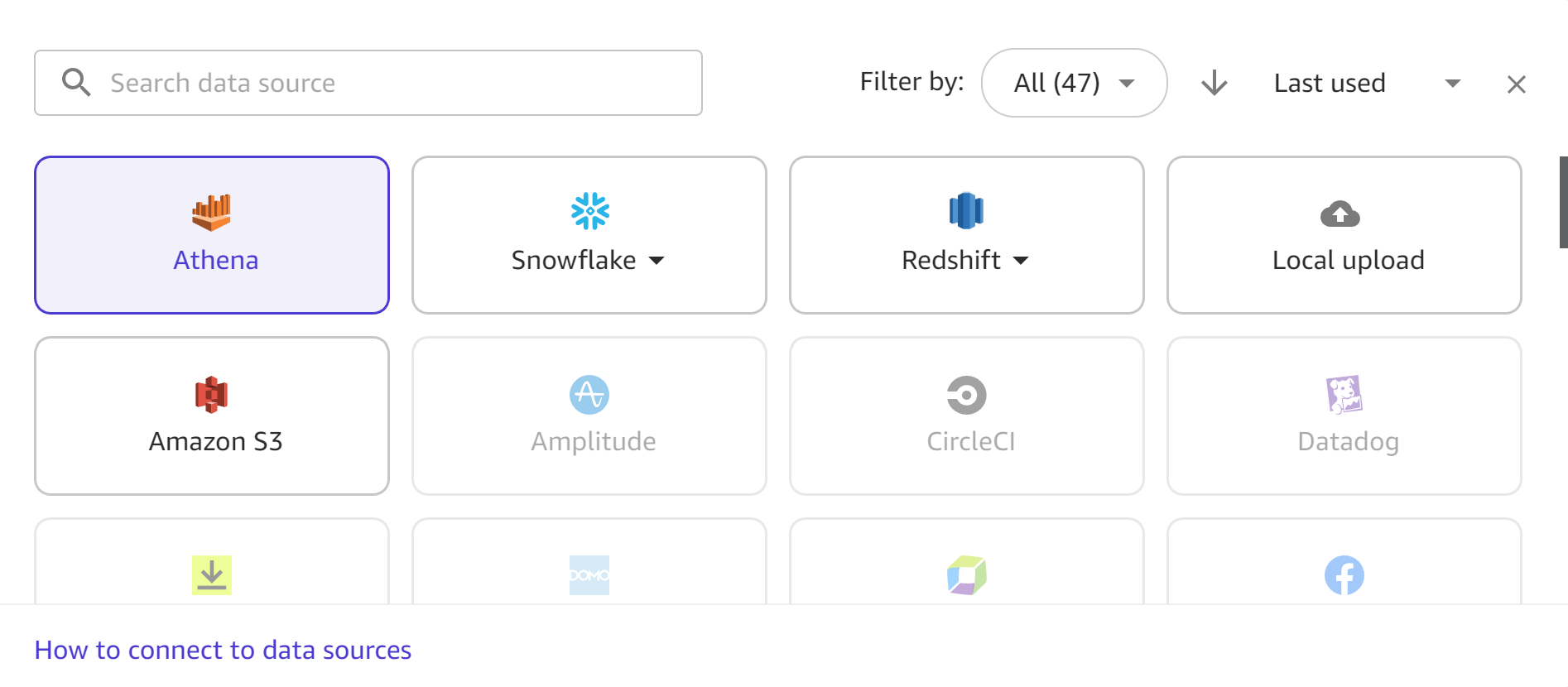
As seções a seguir fornecem informações sobre como estabelecer conexões com fontes de dados externas e importar dados delas. Analise primeiro a seção a seguir para determinar quais permissões você precisa para importar dados da sua fonte de dados.
Permissões
Analise as informações a seguir para garantir que você tenha as permissões necessárias para importar dados da sua fonte de dados:
Amazon S3: você pode importar dados de qualquer bucket do Amazon S3, desde que seu usuário tenha permissões para acessar o bucket. Para obter mais informações sobre o uso AWS do IAM para controlar o acesso aos buckets do Amazon S3, consulte Gerenciamento de identidade e acesso no Amazon S3 no Guia do usuário do Amazon S3.
Amazon Athena: Se você tiver a AmazonSageMakerFullAccesspolítica e a AmazonSageMakerCanvasFullAccesspolítica vinculadas à função de execução do seu usuário, poderá consultá-la AWS Glue Data Catalog com o Amazon Athena. Se você faz parte de um grupo de trabalho do Athena, certifique-se de que o usuário do Canvas tenha as permissões para executar consultas do Athena nos dados. Para obter mais informações, consulte Usar grupos de trabalho para executar consultas no Manual do usuário do Amazon Athena.
Amazon DocumentDB: você pode importar dados de qualquer banco de dados do Amazon DocumentDB, desde que tenha as credenciais (nome de usuário e senha) para se conectar ao banco de dados e tenha as permissões básicas mínimas do Canvas associadas perfil de execução do usuário. Para obter mais informações sobre as permissões do Canvas, consulte Pré-requisitos para configurar o Amazon Canvas SageMaker .
Amazon Redshift: para dar a si mesmo as permissões necessárias para importar dados do Amazon Redshift, consulte Conceder permissões aos usuários para importar dados do Amazon Redshift.
Amazon RDS: Se você tiver a AmazonSageMakerCanvasFullAccesspolítica anexada à função de execução do seu usuário, poderá acessar seus bancos de dados do Amazon RDS a partir do Canvas.
Plataformas SaaS: se você tiver a AmazonSageMakerFullAccesspolítica e a AmazonSageMakerCanvasFullAccesspolítica vinculadas à função de execução do seu usuário, terá as permissões necessárias para importar dados das plataformas SaaS. Consulte Usar conectores SaaS com o Canvas para obter mais informações sobre como se conectar-se a um conector SaaS específico.
Conectores JDBC: para fontes de banco de dados como Databricks, MySQL ou MariaDB, você deve habilitar a autenticação de nome de usuário e senha no banco de dados de origem antes de tentar se conectar a partir do Canvas. Se você estiver se conectando a um banco de dados do Databricks, deverá ter o URL do JDBC que contém as credenciais necessárias.
Conecte-se a um banco de dados armazenado em AWS
Talvez você queira importar os dados que você armazenou AWS. Você pode importar dados do Amazon S3, usar o Amazon Athena para consultar um banco de dados no, importar dados AWS Glue Data Catalog do Amazon RDS ou fazer uma conexão com um banco de dados provisionado do Amazon Redshift (não com o Redshift Serverless).
Você pode criar várias conexões com o Amazon Redshift. No Amazon Athena, você pode acessar qualquer banco de dados existente em seu AWS Glue Data Catalog. No Amazon S3, você pode importar dados de um bucket, desde que tenha as permissões necessárias.
Para obter mais informações, verifique as seções a seguir.
Conectar-se aos dados no Amazon S3, Amazon Athena ou Amazon RDS
No Amazon S3, você pode importar dados de qualquer bucket do Amazon S3, desde que tenha permissões para acessar o bucket.
Para o Amazon Athena, você pode acessar bancos de dados em seu, AWS Glue Data Catalog desde que tenha permissões por meio do seu grupo de trabalho do Amazon Athena.
Para o Amazon RDS, se você tiver a AmazonSageMakerCanvasFullAccesspolítica anexada à sua função de usuário, poderá importar dados de seus bancos de dados do Amazon RDS para o Canvas.
Para importar dados de um bucket do Amazon S3 ou para executar consultas e importar tabelas de dados com o Amazon Athena, consulte Criar um conjunto de dados. Você pode importar somente dados tabulares do Amazon Athena e pode importar dados tabulares e de imagem do Amazon S3.
Conecte-se a um conjunto de dados Amazon DocumentDB
O Amazon DocumentDB é um serviço de banco de dados de documentos totalmente gerenciado e com tecnologia sem servidor. Você pode importar dados de documentos não estruturados armazenados em um banco de dados Amazon DocumentDB SageMaker para o Canvas como um conjunto de dados tabular e, em seguida, criar modelos de aprendizado de máquina com os dados.
Importante
Seu domínio de SageMaker IA deve ser configurado somente no modo VPC para adicionar conexões ao Amazon DocumentDB. Você só pode acessar clusters do Amazon DocumentDB na mesma Amazon VPC da sua aplicação Canvas. Além disso, o Canvas só pode se conectar a clusters Amazon DocumentDB habilitados para TLS. Para obter mais informações sobre como configurar o Canvas no modo somente VPC, consulte. Configurar o Amazon SageMaker Canvas em uma VPC sem acesso à Internet
Para importar dados dos bancos de dados do Amazon DocumentDB, você deve ter credenciais para acessar o banco de dados do Amazon DocumentDB e especificar o nome de usuário e a senha ao criar uma conexão com o banco de dados. Você pode configurar permissões mais granulares e restringir o acesso modificando as permissões de usuário do Amazon DocumentDB. Para saber mas sobre o controle de acesso no Amazon DocumentDB, consulte Acesso ao banco de dados usando controle de acesso baseado em funções no Guia do desenvolvedor do Amazon DocumentDB.
Quando você importa do Amazon DocumentDB, o Canvas converte seus dados não estruturados em um conjunto de dados tabular mapeando os campos em colunas em uma tabela. Tabelas adicionais são criadas para cada campo complexo (ou estrutura aninhada) nos dados, onde as colunas correspondem aos subcampos do campo complexo. Para obter informações mais detalhadas sobre esse processo e exemplos de conversão de esquema, consulte a página Amazon DocumentDB JDBC Driver
O Canvas só pode fazer uma conexão com um único banco de dados no Amazon DocumentDB. Para importar dados de um banco de dados diferente, crie uma nova conexão.
É possível importar dados do Amazon DocumentDB para o Canvas usando os seguintes métodos:
-
Criar um conjunto de dados. Você pode importar seus dados do Amazon DocumentDB e criar um conjunto de dados tabular no Canvas. Se você escolher esse método, siga o procedimento Importar dados tabulares.
-
Criar um conjunto de dados. Você pode criar um pipeline de preparação de dados no Canvas e adicionar seu banco de dados Amazon DocumentDB como fonte de dados.
Para continuar com a importação de seus dados, siga o procedimento de um dos métodos vinculados na lista anterior.
Ao chegar à etapa em qualquer fluxo de trabalho para escolher uma fonte de dados (Etapa 6 para criar um conjunto de dados ou Etapa 8 para criar um fluxo de dados), faça o seguinte:
Em Fonte de dados, abra o menu suspenso e escolha DocumentDB.
Escolha Adicionar conexão.
-
Na caixa de diálogo, especifique suas credenciais do Amazon DocumentDB:
Insira um Nome de conexão. Isso é um nome usado pelo Canvas para identificar esta conexão.
Para Cluster, selecione o cluster no Amazon DocumentDB que armazena seus dados. O Canvas preenche automaticamente o menu suspenso com clusters Amazon DocumentDB na mesma VPC da sua aplicação Canvas.
Insira o nome de usuário do seu cluster do Amazon DocumentDB.
Insira a senha para seu cluster do Amazon DocumentDB.
Insira o nome do conjunto de dados ao qual deseja se conectar.
-
A opção de Preferência de leitura determina de quais tipos de instâncias no seu cluster Canvas lê os dados. Selecione um dos seguintes:
Preferencial secundário: O Canvas usa como padrão a leitura das instâncias secundárias do cluster, mas se uma instância secundária não estiver disponível, o Canvas lê a partir de uma instância primária.
Secundário: O Canvas lê somente as instâncias secundárias do cluster, o que impede que as operações de leitura interfiram nas operações regulares de leitura e gravação do cluster.
-
Escolha Adicionar conexão. A imagem a seguir mostra a caixa de diálogo com os campos anteriores para uma conexão do Amazon DocumentDB.
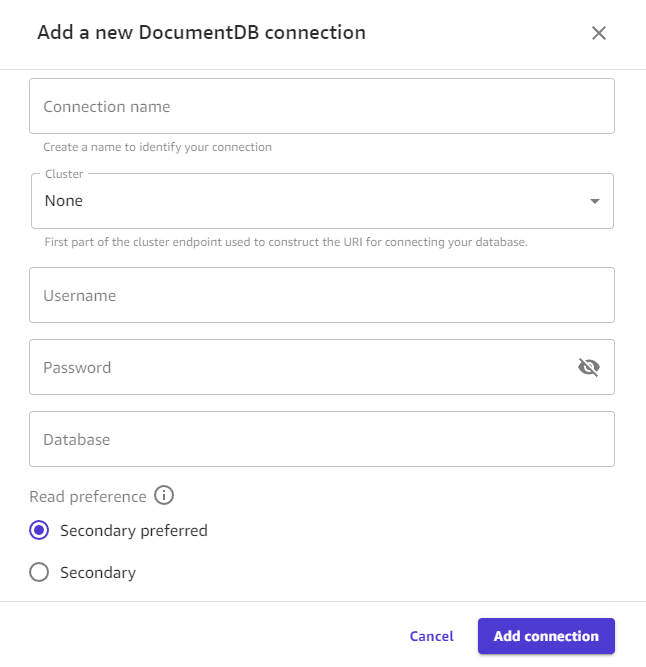
Agora você deve ter uma conexão com o Amazon DocumentDB e pode usar seus dados do Amazon DocumentDB no Canvas para criar um conjunto de dados ou um fluxo de dados.
Conectar-se a um banco de dados do Amazon Redshift
Você pode importar dados do Amazon Redshift, um data warehouse onde sua organização guarda seus dados. Antes de importar dados do Amazon Redshift, a função do AWS IAM que você usa deve ter a política AmazonRedshiftFullAccess gerenciada anexada. Para obter instruções sobre como anexar esta política, consulte Conceder permissões aos usuários para importar dados do Amazon Redshift.
Para importar dados do Amazon Redshift, faça o seguinte:
-
Crie uma conexão com um banco de dados do Amazon Redshift.
-
Alterar os dados que você quer importar.
-
Importe os dados.
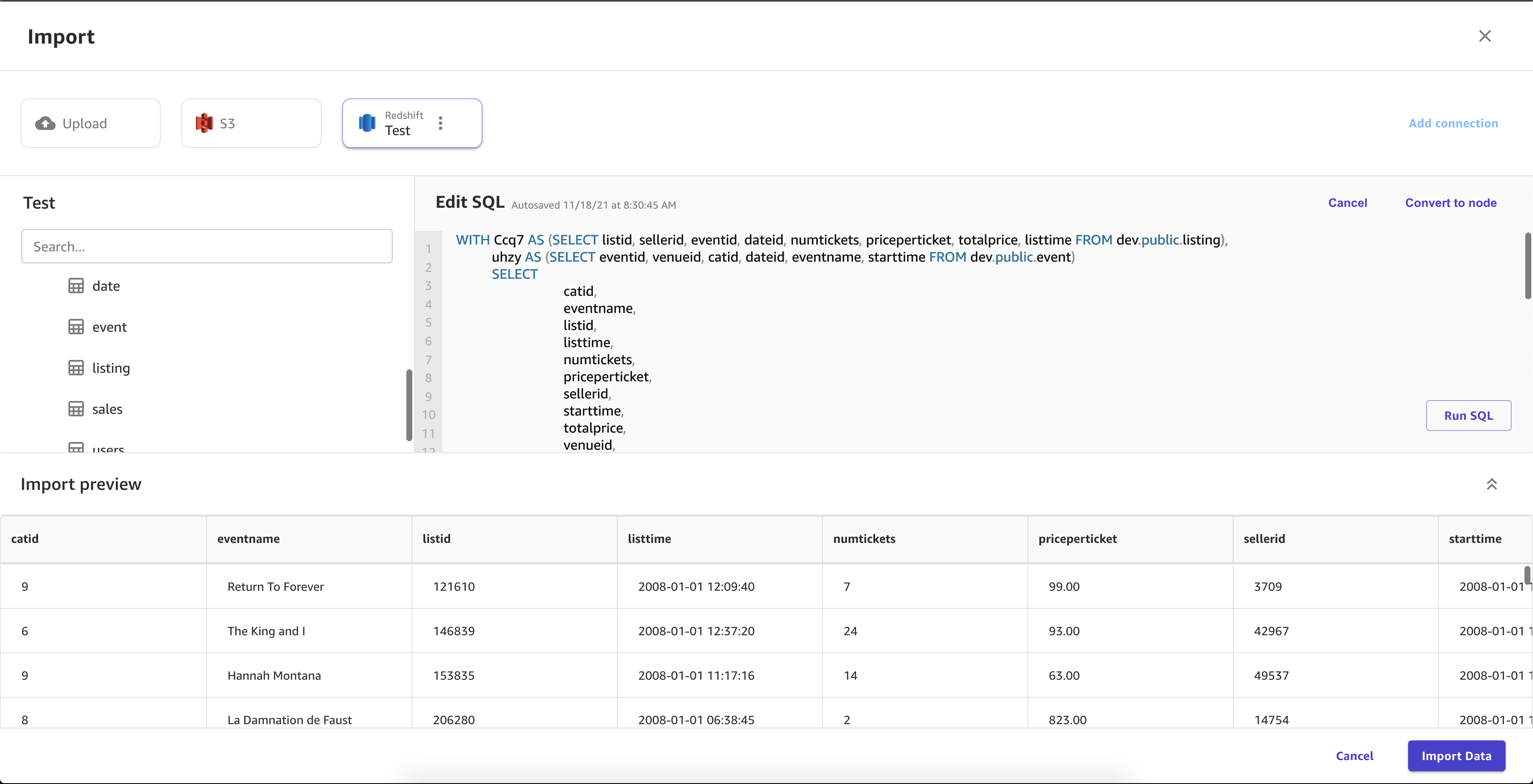
Você pode usar o editor Amazon Redshift para arrastar conjuntos de dados para o painel de importação e importá-los para o Canvas. SageMaker Para obter mais controle sobre os valores retornados no conjunto de dados, use o seguinte:
-
Consultas SQL
-
Junções
As consultas SQL permitem que você personalize a forma como você importa os valores no conjunto de dados. Por exemplo, você pode especificar as colunas retornadas no conjunto de dados ou o intervalo de valores de uma coluna.
Você pode usar junções para combinar vários conjuntos de dados do Amazon Redshift em um único conjunto de dados. Você pode arrastar seus conjuntos de dados do Amazon Redshift para o painel que permite juntar os conjuntos de dados.
Você pode usar o editor SQL para editar o conjunto de dados que você juntou e converter o conjunto de dados associado em um único nó. Você pode juntar outro conjunto de dados ao nó. Você pode importar os dados que você selecionou para o SageMaker Canvas.
Use o procedimento a seguir para importar dados do Amazon Redshift.
No aplicativo SageMaker Canvas, acesse a página Conjuntos de dados.
Escolha Criar e, no menu suspenso, escolha Tabular.
-
Insira um nome para o conjunto de dados e escolha Criar.
Em Fonte de dados, abra o menu suspenso e escolha Redshift.
-
Escolha Adicionar conexão.
-
Na caixa de diálogo, especifique suas credenciais do Amazon Redshift:
-
Em Método de autenticação, escolha IAM.
-
Insira o Identificador de cluster para especificar a qual cluster você deseja se conectar. Insira somente o identificador do cluster e não o endpoint completo do cluster do Amazon Redshift.
-
Insira o Nome do banco de dados ao qual deseja se conectar.
-
Insira um Usuário do banco de dados para identificar o usuário que você deseja usar para se conectar ao banco de dados.
-
Para o ARN, insira o ARN do perfil do IAM da função que o cluster do Amazon Redshift deve assumir para mover e gravar dados no Amazon S3. Para obter mais informações sobre essa função, consulte Autorizar o Amazon Redshift a acessar AWS outros serviços em seu nome no Guia de gerenciamento do Amazon Redshift.
-
Insira um Nome de conexão. Isso é um nome usado pelo Canvas para identificar esta conexão.
-
-
Na guia que tem o nome da sua conexão, arraste o arquivo .csv que você está importando para o painel Arrastar e soltar tabela para importar.
-
Opcional: arraste tabelas adicionais para o painel de importação. Você pode usar a GUI para juntar as tabelas. Para obter mais especificidade em suas junções, escolha Editar em SQL.
-
Opcional: se você estiver usando SQL para consultar os dados, poderá escolher Contexto para adicionar contexto à conexão especificando valores para o seguinte:
-
Warehouse
-
Banco de dados
-
Schema
-
-
Escolha Importar dados.
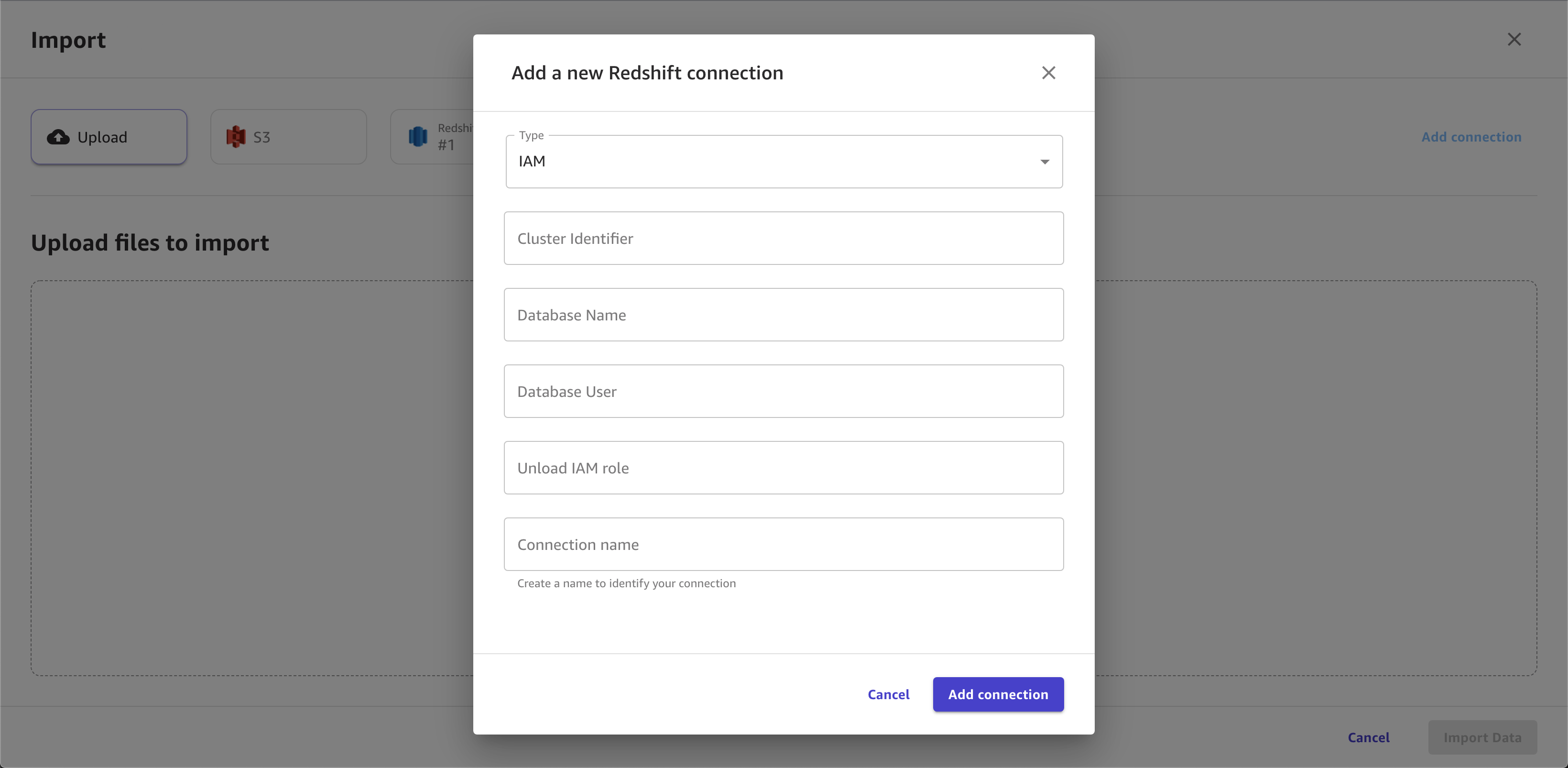
A imagem a seguir mostra um exemplo de campos especificados para uma conexão do Amazon Redshift.
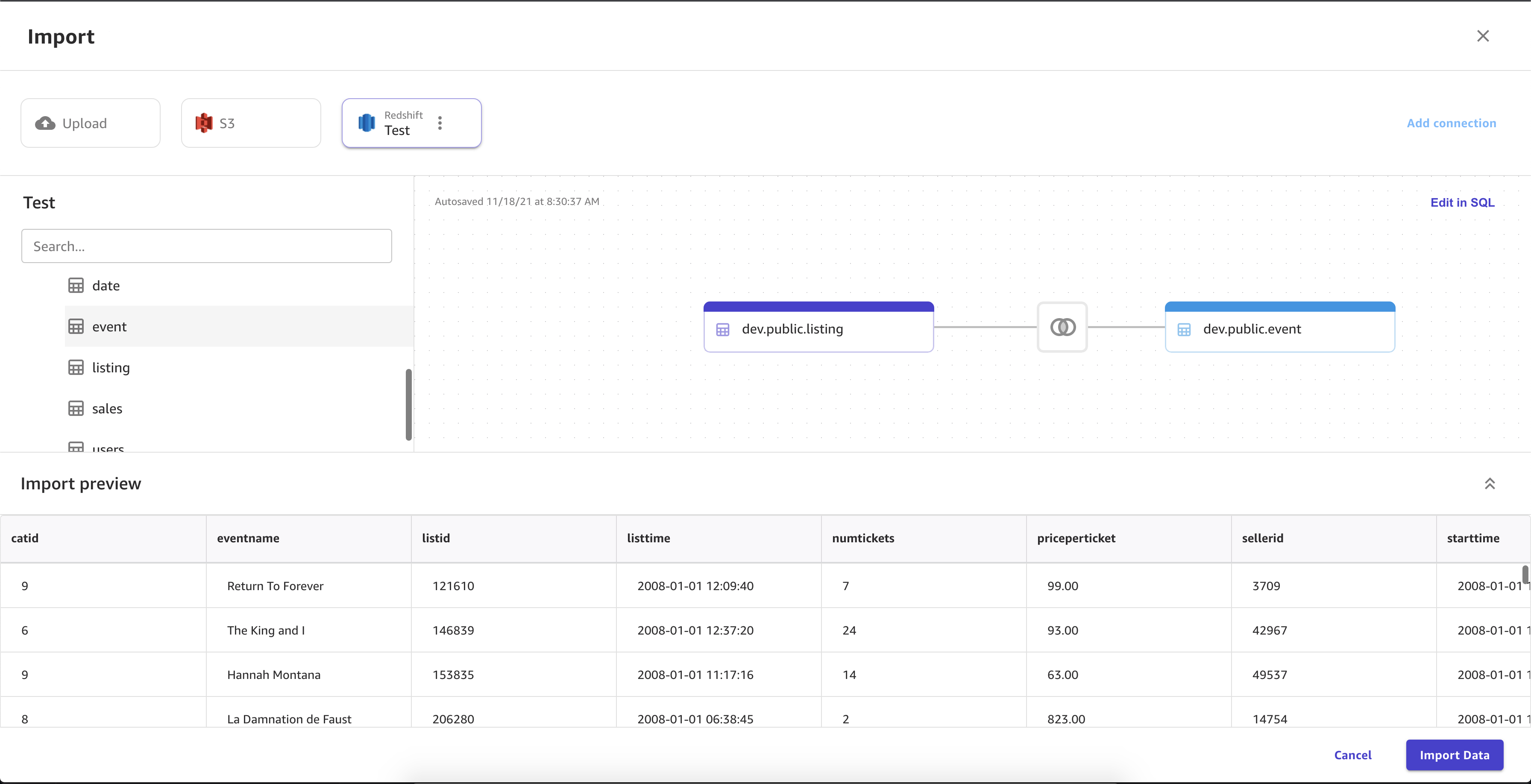
A imagem a seguir mostra a página usada para juntar conjuntos de dados no Amazon Redshift.
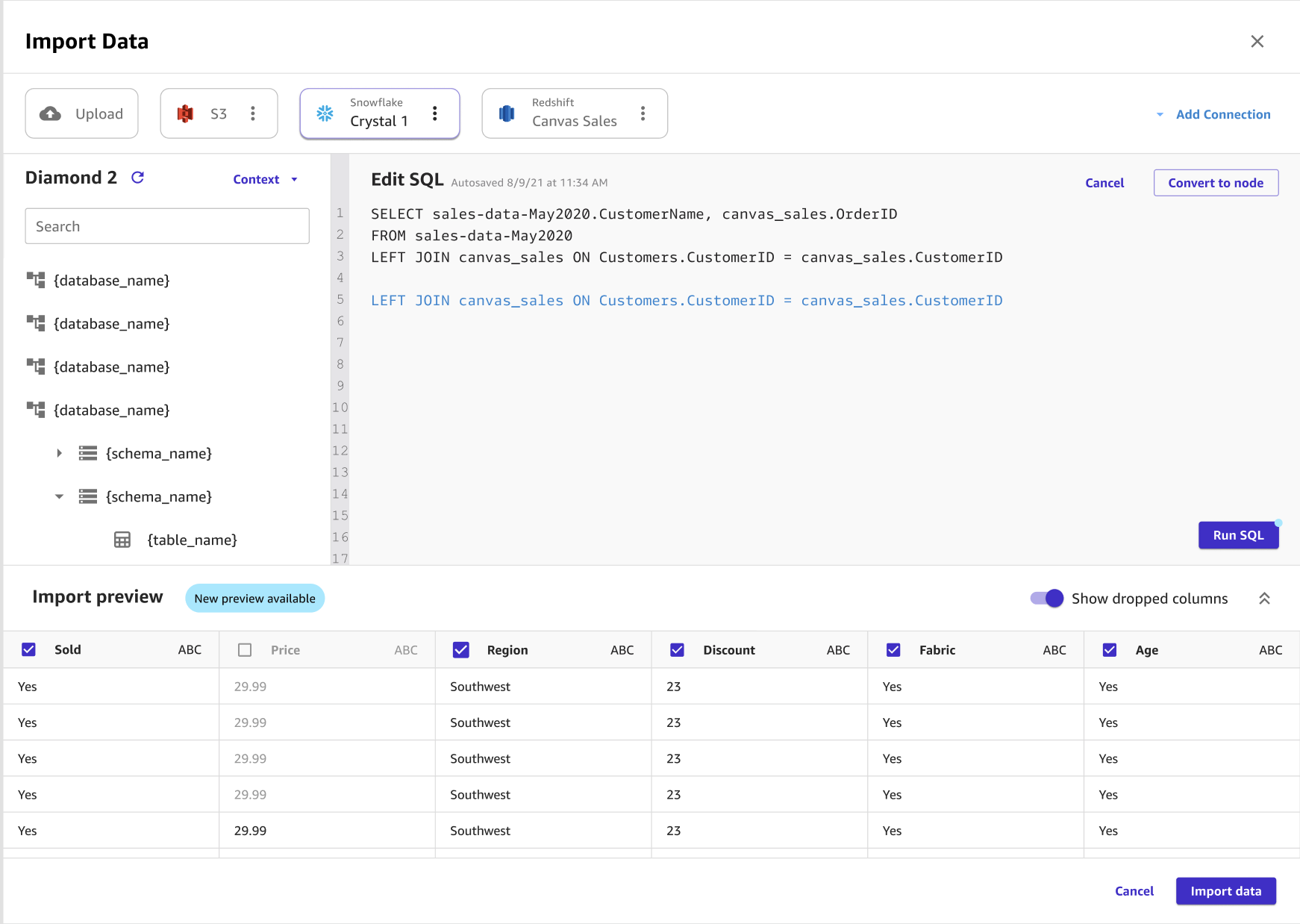
A imagem a seguir mostra uma consulta SQL sendo usada para editar uma junção no Amazon Redshift.
Conectar-se aos seus dados com conectores JDBC
Com o JDBC, você pode se conectar aos seus bancos de dados a partir de fontes como Databricks, SQLServer MySQL, PostgreSQL, MariaDB, Amazon RDS e Amazon Aurora.
Você deve se certificar de que tem as credenciais e permissões necessárias para criar a conexão a partir do Canvas.
Para o Databricks, você deve fornecer um URL do JDBC. A formatação do URL pode variar entre as instâncias do Databricks. Para obter informações sobre como encontrar o URL e especificar os parâmetros dentro dele, consulte os Parâmetros de configuração e conexão do JDBC
na documentação do Databricks. Veja a seguir um exemplo de como um URL pode ser formatado: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-tokenPara outras fontes de banco de dados, você deve configurar a autenticação de nome de usuário e senha e, em seguida, especificar essas credenciais ao se conectar ao banco de dados a partir do Canvas.
Além disso, sua fonte de dados deve estar acessível pela Internet pública ou, se sua aplicação Canvas estiver sendo executada no modo somente VPC, a fonte de dados deverá ser executada na mesma VPC. Para obter mais informações sobre a configuração de um banco de dados do Amazon RDS em uma VPC, consulte Amazon VPC VPCs e Amazon RDS no Guia do usuário do Amazon RDS.
Depois de configurar suas credenciais da fonte de dados, você pode entrar na aplicação Canvas e criar uma conexão com a fonte de dados. Especifique suas credenciais (ou, para o Databricks, o URL) ao criar a conexão.
Conecte-se às fontes de dados com OAuth
O Canvas suporta o uso OAuth como método de autenticação para se conectar aos seus dados no Snowflake e no Salesforce Data Cloud. OAuth
nota
Você só pode estabelecer uma OAuth conexão para cada fonte de dados.
Para autorizar a conexão, você deve seguir a configuração inicial descrita em Configure conexões com fontes de dados com OAuth.
Depois de configurar OAuth as credenciais, você pode fazer o seguinte para adicionar uma conexão do Snowflake ou do Salesforce Data Cloud com: OAuth
Faça login na aplicação Canvas.
Crie um conjunto de dados tabular. Quando solicitado a carregar dados, escolha Snowflake ou Salesforce Data Cloud como sua fonte de dados.
Crie uma nova conexão com sua fonte de dados do Snowflake ou do Salesforce Data Cloud. Especifique OAuth como método de autenticação e insira os detalhes da sua conexão.
Agora você conseguirá importar dados dos seus bancos de dados no Snowflake ou no Salesforce Data Cloud.
Conectar-se a uma plataforma SaaS
Você pode importar dados do Snowflake e de mais de 40 outras plataformas SaaS externas. Para obter uma lista completa de conectores, consulte a tabela em importar dados.
nota
Você pode importar somente dados tabulares, como tabelas de dados, de plataformas SaaS.
Usar o Snowflake com o Canvas
O Snowflake é um serviço de armazenamento e análise de dados, e você pode importar seus dados do Snowflake para o Canvas. SageMaker Para obter mais informações sobre o Snowflake, consulte a Documentação do Snowflake
É possível importar dados da sua conta do Snowflake da seguinte forma:
-
Crie uma conexão com o banco de dados do Snowflake.
-
Escolha os dados a serem importados arrastando e soltando a tabela do menu de navegação esquerdo para o editor.
-
Importe os dados.
Você pode usar o editor Snowflake para arrastar conjuntos de dados para o painel de importação e importá-los para o Canvas. SageMaker Para obter mais controle sobre os valores retornados no conjunto de dados, use o seguinte:
-
Consultas SQL
-
Junções
As consultas SQL permitem que você personalize a forma como você importa os valores no conjunto de dados. Por exemplo, você pode especificar as colunas retornadas no conjunto de dados ou o intervalo de valores de uma coluna.
Você pode juntar vários conjuntos de dados do Snowflake em um único conjunto de dados antes de importá-los para o Canvas usando SQL ou a interface Canvas. Você pode arrastar seus conjuntos de dados do Snowflake para o painel que permite juntar os conjuntos de dados ou pode editar as junções em SQL e converter o SQL em um único nó. Você pode juntar outros nós ao nó que você converteu. Em seguida, você pode combinar os conjuntos de dados juntados em um único nó e juntar os nós a um conjunto de dados diferente do Snowflake. Finalmente, você pode importar os dados selecionados para o Canvas.
Use o procedimento a seguir para importar dados do Snowflake para o Amazon SageMaker Canvas.
No aplicativo SageMaker Canvas, acesse a página Conjuntos de dados.
Escolha Criar e, no menu suspenso, escolha Tabular.
-
Insira um nome para o conjunto de dados e escolha Criar.
Em Fonte de dados, abra o menu suspenso e escolha Snowflake.
-
Escolha Adicionar conexão.
-
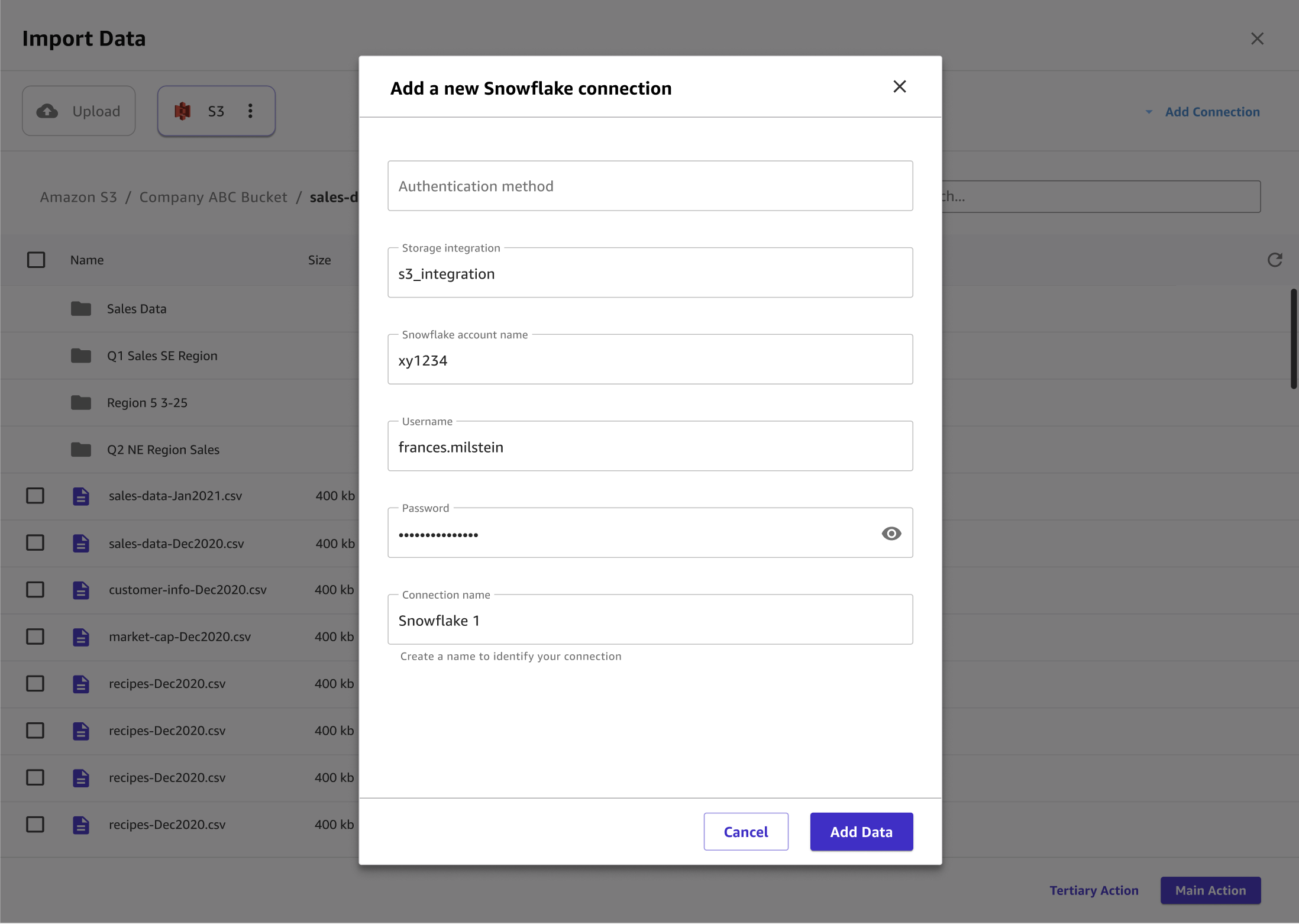
Na caixa de diálogo Adicionar uma nova conexão do Snowflake, especifique suas credenciais do Snowflake. Em Método de autenticação, escolha uma das seguintes opções:
Básico - nome de usuário e senha: Forneça seu ID de conta, nome de usuário e senha do Snowflake.
-
ARN — Para melhorar a proteção de suas credenciais do Snowflake, forneça o ARN de um segredo que contenha suas credenciais. AWS Secrets Manager Para obter mais informações, consulte Criar um AWS Secrets Manager segredo no Guia AWS Secrets Manager do usuário.
Seu segredo deve ter suas credenciais do Snowflake armazenadas no seguinte formato JSON:
{"accountid": "ID", "username": "username", "password": "password"} OAuth— OAuth permite que você se autentique sem fornecer uma senha, mas requer configuração adicional. Para obter mais informações sobre como configurar OAuth credenciais para o Snowflake, consulte. Configure conexões com fontes de dados com OAuth
-
Escolha Adicionar conexão.
-
Na guia que tem o nome da sua conexão, arraste o arquivo .csv que você está importando para o painel Arrastar e soltar tabela para importar.
-
Opcional: arraste tabelas adicionais para o painel de importação. Você pode usar a interface de usuário para juntar as tabelas. Para obter mais especificidade em suas junções, escolha Editar em SQL.
-
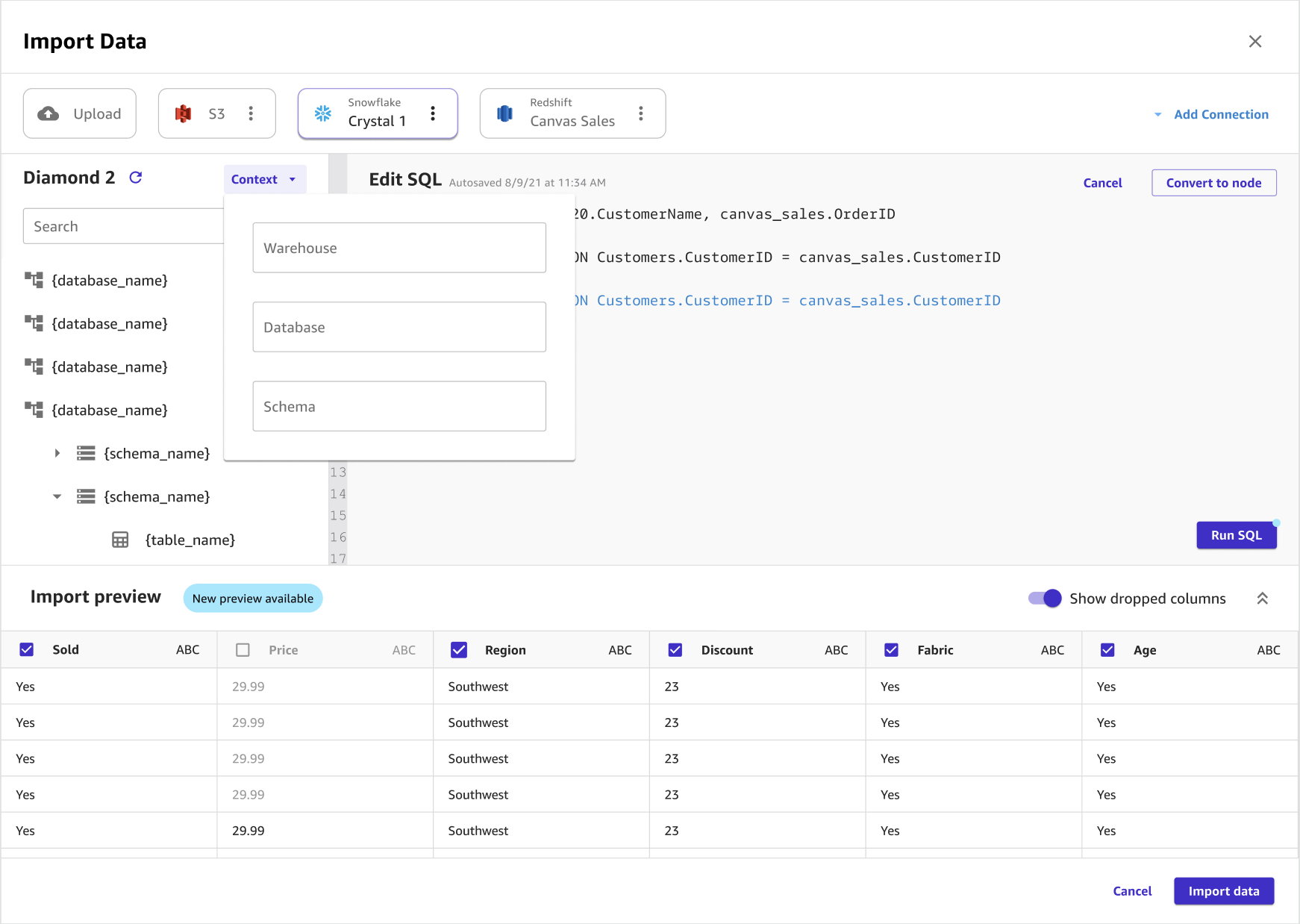
Opcional: se você estiver usando SQL para consultar os dados, poderá escolher Contexto para adicionar contexto à conexão especificando valores para o seguinte:
-
Warehouse
-
Banco de dados
-
Schema
Adicionar contexto a uma conexão facilita a especificação de futuras consultas.
-
-
Escolha Importar dados.
A imagem a seguir mostra um exemplo de campos especificados para uma conexão do Snowflake.
A imagem a seguir mostra a página usada para adicionar contexto a uma conexão.
A imagem a seguir mostra a página usada para juntar conjuntos de dados no Snowflake.
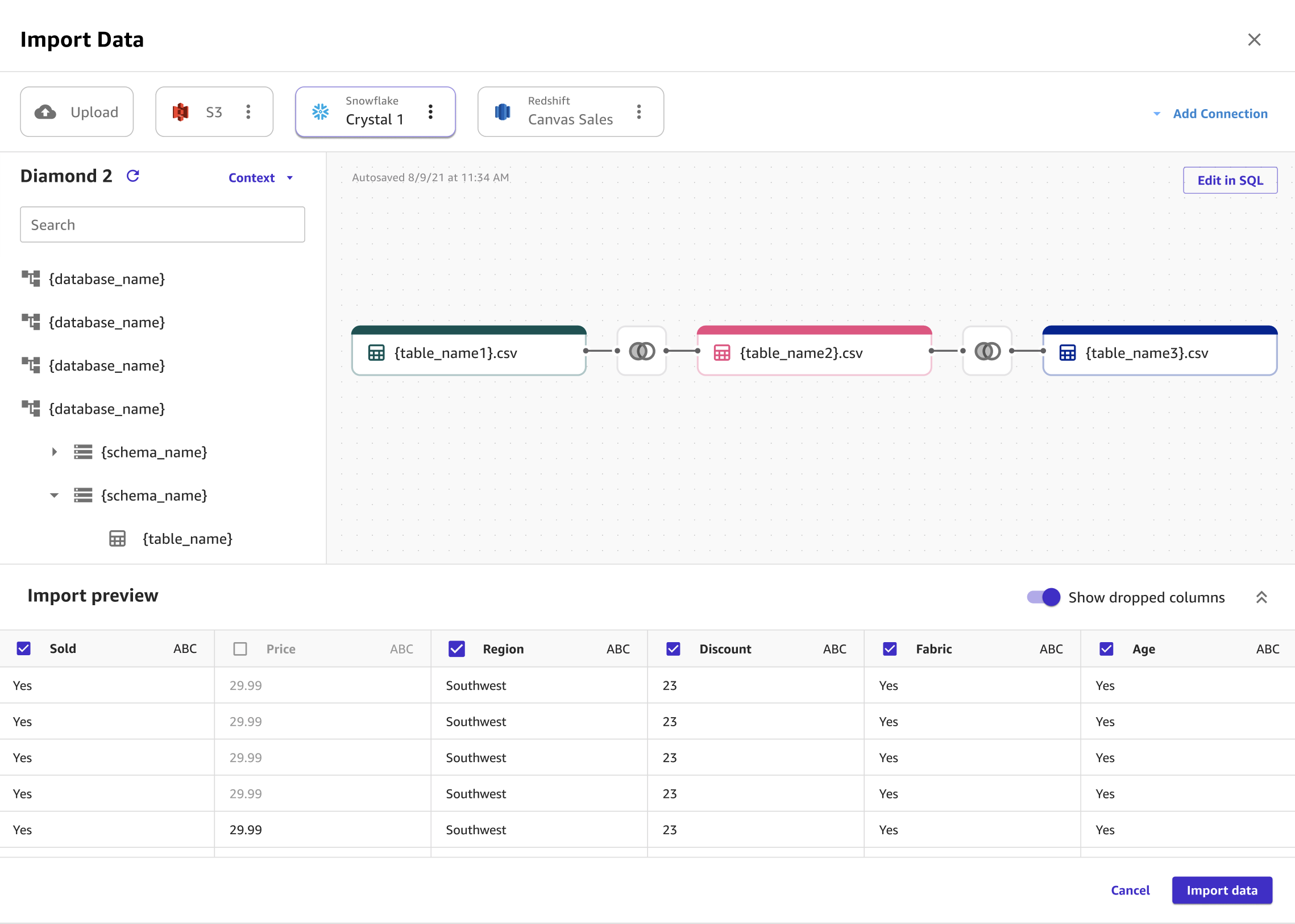
A imagem a seguir mostra uma consulta SQL sendo usada para editar uma junção no Snowflake.
Usar conectores SaaS com o Canvas
nota
Para plataformas SaaS além do Snowflake, você só pode ter uma conexão por fonte de dados.
Antes de importar dados de uma plataforma SaaS, seu administrador deve se autenticar e criar uma conexão com a fonte de dados. Para obter mais informações sobre como os administradores podem criar uma conexão com uma plataforma SaaS, consulte Gerenciamento de conexões da AppFlow Amazon no Guia do usuário da AppFlow Amazon.
Se você é um administrador que está começando a usar a Amazon AppFlow pela primeira vez, consulte Introdução no Guia do AppFlow usuário da Amazon.
Para importar dados de uma plataforma SaaS, você pode seguir o procedimento Importar dados tabulares padrão, que mostra como importar conjuntos de dados tabulares para o Canvas.
