Administration
This section provides guidance on common administrative tasks required to operate an SAP HANA system, including information about starting, stopping, and cloning systems.
Starting and Stopping EC2 Instances Running SAP HANA Hosts
At any time, you can stop one or multiple SAP HANA hosts. Before stopping the EC2 instance of an SAP HANA host, first stop SAP HANA on that instance.
When you resume the instance, it will automatically start with the same IP address, network, and storage configuration as before. You also have the option of using the EC2 Scheduler
Figure 1: EC2 Scheduler

Tagging SAP Resources on AWS
Tagging your SAP resources on AWS can significantly simplify identification, security, manageability, and billing of those resources. You can tag your resources using the AWS Management Console or by using the create-tags functionality of the AWS Command Line Interface (AWS CLI). This table lists some example tag names and tag values:
| Tag name | Tag value |
|---|---|
|
Name |
SAP server’s virtual (host) name |
|
Environment |
SAP server’s landscape role; for example: SBX, DEV, QAT, STG, PRD. |
|
Application |
SAP solution or product; for example: ECC, CRM, BW, PI, SCM, SRM, EP |
|
Owner |
SAP point of contact |
|
Service level |
Known uptime and downtime schedule |
After you have tagged your resources, you can apply specific security restrictions such as access control, based on the tag values. Here is an example of such a policy from the AWS Security blog
{ "Version" : "2012-10-17", "Statement" : [ { "Sid" : "LaunchEC2Instances", "Effect" : "Allow", "Action" : [ "ec2:Describe*", "ec2:RunInstances" ], "Resource" : [ "*" ] }, { "Sid" : "AllowActionsIfYouAreTheOwner", "Effect" : "Allow", "Action" : [ "ec2:StopInstances", "ec2:StartInstances", "ec2:RebootInstances", "ec2:TerminateInstances" ], "Condition" : { "StringEquals" : { "ec2:ResourceTag/PrincipalId" : "${aws:userid}" } }, "Resource" : [ "*" ] } ] }
The AWS Identity and Access Management (IAM) policy allows only specific permissions based on the tag value. In this scenario, the current user ID must match the tag value in order for the user to be granted permissions. For more information on tagging, see the AWS documentation and AWS blog
Monitoring
You can use various AWS, SAP, and third-party solutions to monitor your SAP workloads. Here are some of the core AWS monitoring services:
-
Amazon CloudWatch
– CloudWatch is a monitoring service for AWS resources. It’s critical for SAP workloads where it’s used to collect resource utilization logs and to create alarms to automatically react to changes in AWS resources. -
AWS CloudTrail
– CloudTrail keeps track of all API calls made within your AWS account. It captures key metrics about the API calls and can be useful for automating trail creation for your SAP resources.
Configuring CloudWatch detailed monitoring for SAP resources is mandatory for getting AWS and SAP support. You can use native AWS monitoring services in a complementary fashion with the SAP Solution Manager. You can find third-party monitoring tools in AWS Marketplace
Automation
AWS offers multiple options for programmatically scripting your resources to operate or scale them in a predictable and repeatable manner. You can use AWS CloudFormation to automate and operate SAP systems on AWS. Here are some examples for automating your SAP environment on AWS:
|
Area |
Activities |
AWS services |
|
Infrastructure deployment |
Provision new SAP environment SAP system cloning |
|
|
Capacity management |
Automate scale-up/scale-out of SAP application servers |
|
|
Operations |
SAP backup automation (see the backup example) Performing monitoring and visualization |
Amazon CloudWatchhttps://docs.aws.amazon.com/systems-manager/latest/userguide/what-is-systems-manager.html[AWS Systems Manager] |
Patching
There are two ways for you to patch your SAP HANA database, with options for minimizing cost and/or downtime. With AWS, you can provision additional servers as needed to minimize downtime for patching in a cost-effective manner. You can also minimize risks by creating on-demand copies of your existing production SAP HANA databases for lifelike production readiness testing.
This table summarizes the tradeoffs of the two patching methods:
| Patching method | Benefits | Tradeoff | Technologies available |
|---|---|---|---|
|
Patch an existing server |
No costs for additional on-demand instances Lowest levels of relative complexity and setup tasks involved |
Need to patch the existing operating system and database Longest downtime to the existing server and database |
Native OS patching tools Patch Manager |
|
Provision and patch a new server |
Leverage latest AMIs (only database patch is required) Shortest downtime on the existing server and database Option to patch and test the operating system and database separately or together |
More costs for additional on-demand instances More complexity and setup tasks involved |
SAP HANA System Replication SAP Notes:
1984882
1913302 |
The first method (patch an existing server) involves patching the operating system (OS) and database (DB) components of your SAP HANA server. The goal of this method is to minimize any additional server costs and to avoid any tasks needed to set up additional systems or tests. This method may be most appropriate if you have a well-defined patching process and are satisfied with your current downtime and costs. With this method you must use the correct operating system (OS) update process and tools for your Linux distribution. See this SUSE blog
In addition to patching tools provided by our Linux partners,AWS offers a free of charge patching service
The second method (provision and patch a new server) involves provisioning a new EC2 instance that will receive a copy of your source system and database. The goal of the method is to minimize downtime, minimize risks (by having production data and executing production-like testing), and have repeatable processes. This method may be most appropriate if you are looking for higher degrees of automation to enable these goals and are comfortable with the trade- offs. This method is more complex and has a many more options to fit your requirements. Certain options are not exclusive and can be used together. For example, your AWS CloudFormation template can include the latest Amazon Machine Images (AMIs), which you can then use to automate the provisioning, set up, and configuration of a new SAP HANA server.
For more information, see Automated patching.
Backup and Recovery
This section provides an overview of the AWS services used in the backup and recovery of SAP HANA systems and provides an example backup and recovery scenario. This guide does not include detailed instructions on how to execute database backups using native HANA backup and recovery features or third- party backup tools. Please refer to the standard OS, SAP, and SAP HANA documentation or the documentation provided by backup software vendors. In addition, backup schedules, frequency, and retention periods might vary with your system type and business requirements. See the following standard SAP documentation for guidance on these topics.
Note
For a discussion of both general and advanced backup and recovery concepts for SAP systems on AWS, see the SAP on AWS Backup and Recovery Guide
| SAP Note | Description |
|---|---|
|
FAQ: SAP HANA Database Backup & Recovery |
|
|
Determining required recovery files |
|
|
Checking backups using hdbbackupcheck |
|
|
Checking recoverability with hdbbackupdiag --check |
|
|
Scheduling SAP HANA Database Backups in Linux |
|
|
Scheduling backups for multi-tenant SAP HANA Cockpit 2.0 |
Creating an Image of an SAP HANA System
You can use the AWS Management Console or the command line to create your own AMI based on an existing instance. For more information, see the AWS documentation. You can use an AMI of your SAP HANA instance for the following purposes:
-
To create a full offline system backup (of the OS /usr/sap, HANA shared, backup, data, and log files) – AMIs are automatically saved in multiple Availability Zones within the same AWS Region.
-
To move a HANA system from one AWS Region to another – You can create an image of an existing EC2 instance and move it to another AWS Region by following the instructions in the AWS documentation. When the AMI has been copied to the target AWS Region, you can launch the new instance there.
-
To clone an SAP HANA system – You can create an AMI of an existing SAP HANA system to create an exact clone of the system. See the next section for additional information.
Note
See Restoring SAP HANA Backups and Snapshots later in this whitepaper to view the recommended restoration steps for production environments.
Tip
The SAP HANA system should be in a consistent state before you create an AMI. To do this, stop the SAP HANA instance before creating the AMI or by following the instructions in SAP Note 1703435
AWS Services and Components for Backup Solutions
AWS provides a number of services and options for storage and backup, including Amazon Simple Storage Service (Amazon S3), AWS Identity and Access Management (IAM), and S3 Glacier.
Amazon S3
Amazon S3
IAM
With IAM
During the deployment process, AWS CloudFormation creates an IAM role that allows access to get objects from and/or put objects into Amazon S3. That role is subsequently assigned to each EC2 instance that is hosting SAP HANA master and worker nodes at launch time as they are deployed.
Figure 2: IAM role example

To ensure security that applies the principle of least privilege, permissions for this role are limited only to actions that are required for backup and recovery.
{"Statement":[ {"Resource":"arn:aws:s3::: <amzn-s3-demo-bucket>/*", "Action":["s3:GetObject","s3:PutObject","s3:DeleteObject", "s3:ListBucket","s3:Get*","s3:List*"], "Effect":"Allow"}, {"Resource":"*","Action":["s3:List*","ec2:Describe*","ec2:Attach NetworkInterface", "ec2:AttachVolume","ec2:CreateTags","ec2:CreateVolume","ec2:RunI nstances", "ec2:StartInstances"],"Effect":"Allow"}]}
To add functions later, you can use the AWS Management Console to modify the IAM role.
S3 Glacier
S3 Glacier
However, with expedited retrieval, S3 Glacier provides you with an option to retrieve data in 3-5 minutes, which can be ideal for occasional urgent requests. With S3 Glacier, you can reliably store large or small amounts of data for as little as $0.01 per gigabyte per month, a significant savings compared to on-premises solutions. You can use lifecycle policies, as explained in the Amazon S3 Developer Guide, to push SAP HANA backups to S3 Glacier for long-term archiving.
Backup Destination
The primary difference between backing up SAP systems on AWS compared with traditional on-premises infrastructure is the backup destination. Tape is the typical backup destination used with on-premises infrastructure. On AWS, backups are stored in Amazon S3. Amazon S3 has many benefits over tape, including the ability to automatically store backups offsite from the source system, since data in Amazon S3 is replicated across multiple facilities within the AWS Region.
SAP HANA systems provisioned with AWS Launch Wizard for SAP are configured with a set of EBS volumes to be used as an initial local backup destination. HANA backups are first stored on these local EBS volumes and then copied to Amazon S3 for long-term storage.
You can use SAP HANA Studio, SQL commands, or the DBA Cockpit to start or schedule SAP HANA data backups. Log backups are written automatically unless disabled. The /backup file system is configured as part of the deployment process.
Figure 3: SAP HANA file system layout
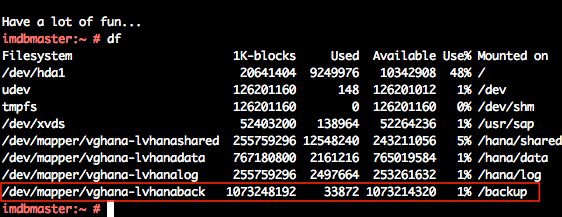
The SAP HANA global.ini configuration file has been customized for database backups to go directly to /backup/data/<SID>, while automatic log archival files go to /backup/log/<SID>.
[persistence] basepath_shared = no savepoint_intervals = 300 basepath_datavolumes = /hana/data/<SID> basepath_logvolumes = /hana/log/<SID> basepath_databackup = /backup/data/<SID> basepath_logbackup = /backup/log/<SID>
Some third-party backup tools like Commvault, NetBackup, and IBM Tivoli Storage Manager (IBM TSM) are integrated with Amazon S3 capabilities and can be used to trigger and save SAP HANA backups directly into Amazon S3 without needing to store the backups on EBS volumes first.
AWS CLI
The AWS Command Line Interface
imdbmaster:/backup # aws s3 ls --region=us-east-1 s3://node2- hana-s3bucket-gcynh5v2nqs3
Bucket: node2-hana-s3bucket-gcynh5v2nqs3
Prefix:
LastWriteTime Length Name
------------- ------ ----
Backup Example
Here are the steps you can take for a typical backup task:
-
In the SAP HANA Backup Editor, choose Open Backup Wizard. You can also open the Backup Wizard by right-clicking the system that you want to back up and choosing Back Up.
-
Select the destination type File. This will back up the database to files in the specified file system.
-
Specify the backup destination (
/backup/data/<SID>) and the backup prefix.Figure 4: SAP HANA backup example
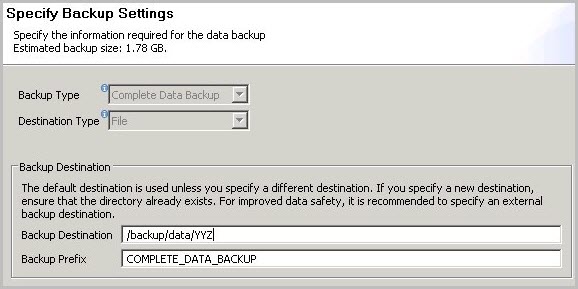
-
Choose Next and then Finish. A confirmation message will appear when the backup is complete.
-
Verify that the backup files are available at the OS level. The next step is to push or synchronize the backup files from the /backup file system to Amazon S3 by using the aws s3 sync command.
imdbmaster:/ # aws s3 sync backup s3://node2-hana-s3bucket- gcynh5v2nqs3 --region=us-east-1
-
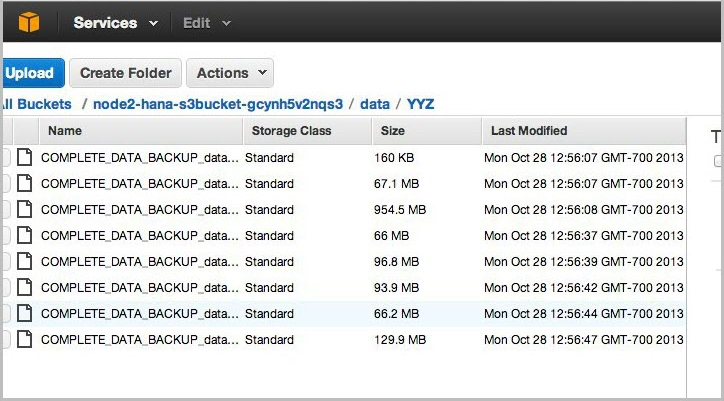
-
Use the AWS Management Console to verify that the files have been pushed to Amazon S3. You can also use the aws s3 ls command shown previously in the AWS Command Line Interface section.
Figure 5: Amazon S3 bucket contents after backup
Tip
The
aws s3 synccommand will only upload new files that don’t exist in Amazon S3. Use a periodically scheduledcronjob to sync, and then delete files that have been uploaded. See SAP Note 1651055for scheduling periodic backup jobs in Linux, and extend the supplied scripts with aws s3 synccommands.
Scheduling and Executing Backups Remotely
You can use the AWS Systems Manager Run Command, along with Amazon CloudWatch Events, to schedule backups of your SAP HANA system remotely without the need to log in to the EC2 instances. You can also use cron or any other instance-level scheduling mechanism.
The Systems Manager Run Command lets you remotely and securely manage the configuration of your managed instances. A managed instance is any EC2 instance or on-premises machine in your hybrid environment that has been configured for Systems Manager. The Run Command enables you to automate common administrative tasks and perform ad hoc configuration changes at
scale. You can use the Run Command from the Amazon EC2 console, the AWS CLI, Windows PowerShell, or the AWS SDKs.
Systems Manager Prerequisites
Systems Manager has the following prerequisites.
|
Supported operating system (Linux) |
Instances must run a supported version of Linux. 64-bit and 32-bit systems: * Amazon Linux 2014.09, 2014.03 or later * Ubuntu Server 16.04 LTS, 14.04 LTS, or 12.04 LTS * Red Hat Enterprise Linux (RHEL) 6.5 or later * CentOS 6.3 or later 64-bit systems only: * Amazon Linux 2015.09, 2015.03 or later * Red Hat Enterprise Linux (RHEL) 7.x or later * CentOS 7.1 or later * SUSE Linux Enterprise Server (SLES) 12 or higher For the latest information about supported operating systems, see the AWS Systems Manager documentation. |
|
Roles for Systems Manager |
Systems Manager requires an IAM role for instances that will process commands and a separate role for users who are executing commands. Both roles require permission policies that enable them to communicate with the Systems Manager API. You can choose to use Systems Manager managed policies or you can create your own roles and specify permissions. For more information, see Configuring Security Roles for Systems Manager in the AWS documentation. If you are configuring on-premises servers or virtual machines (VMs) that you want to configure using Systems Manager, you must also configure an IAM service role. For more information, see Create an IAM Service Role in the AWS documentation. |
|
SSM Agent (EC2 Linux instances) |
AWS Systems Manager Agent (SSM Agent) processes Systems Manager requests and configures your machine as specified in the request. You must download and install SSM Agent to your EC2 Linux instances. For more information, see Installing SSM Agent on Linux in the AWS documentation. |
To schedule remote backups, follow these high-level steps:
-
Install and configure SSM Agent on the EC2 instance. For detailed installation steps, see the AWS Systems Manager documentation.
-
Provide SSM access to the EC2 instance role that is assigned to the SAP HANA instance. For detailed information on how to assign SSM access to a role, see the AWS Systems Manager documentation.
-
Create an SAP HANA backup script. You can use the following sample script as a starting point and modify it to meet your requirements.
#!/bin/sh set -x S3Bucket_Name=<Name of the S3 bucket where backup files will be copied> TIMESTAMP=$(date +\%F\_%H\%M) exec 1>/backup/data/${SAPSYSTEMNAME}/${TIMESTAMP}_backup_log.out 2>&1 echo "Starting to take backup of Hana Database and Upload the backup files to S3" echo "Backup Timestamp for $SAPSYSTEMNAME is $TIMESTAMP" BACKUP_PREFIX=${SAPSYSTEMNAME}_${TIMESTAMP} echo $BACKUP_PREFIX # source HANA environment source $DIR_INSTANCE/hdbenv.sh # execute command with user key hdbsql -U BACKUP "backup data using file ('$BACKUP_PREFIX')" echo "HANA Backup is completed" echo "Continue with copying the backup files in to S3" echo $BACKUP_PREFIX sudo -u root /usr/local/bin/aws s3 cp --recursive /backup/data/${SAPSYSTEMNAME}/ s3://${S3Bucket_Name}/bkps/${SAPSYSTEMNAME}/data/ --exclude "*" --include "${BACKUP_PREFIX}*" echo "Copying HANA Database log files in to S3" sudo -u root /usr/local/bin/aws s3 sync /backup/log/${SAPSYSTEMNAME}/ s3://${S3Bucket_Name}/bkps/${SAPSYSTEMNAME}/log/ --exclude "*" --include "log_backup*" sudo -u root /usr/local/bin/aws s3 cp /backup/data/${SAPSYSTEMNAME}/${TIMESTAMP}_backup_log.out s3://${S3Bucket_Name}/bkps/${SAPSYSTEMNAME}
Note
This script takes into consideration that
hdbuserstorehas a key namedBackup. -
Test a one-time backup by executing an
ssmcommand directly.Note
For this command to execute successfully, you will have to enable
<sid>adm loginusingsudo.aws ssm send-command --instance-ids <HANA master instance ID> --document-name {aws}-RunShellScript --parameters commands="sudo - u <HANA_SID>adm TIMESTAMP=$(date +\%F\_%H\%M) SAPSYSTEMNAME=<HANA_SID> DIR_INSTANCE=/hana/shared/${SAPSYSTEMNAME}/HDB00 -i /usr/sap/HDB/HDB00/hana_backup.sh"
-
Using CloudWatch Events, you can schedule backups remotely at any desired frequency. Navigate to the CloudWatch Events page and create a rule.
-
Choose Schedule.
-
Select SSM Run Command as the target.
-
Select AWS-RunShellScript (Linux) as the document type.
-
Choose InstanceIds or Tags as the target key.
-
Choose Constant under Configure Parameters, and type the
runcommand.Figure 6: Creating Amazon CloudWatch Events rules
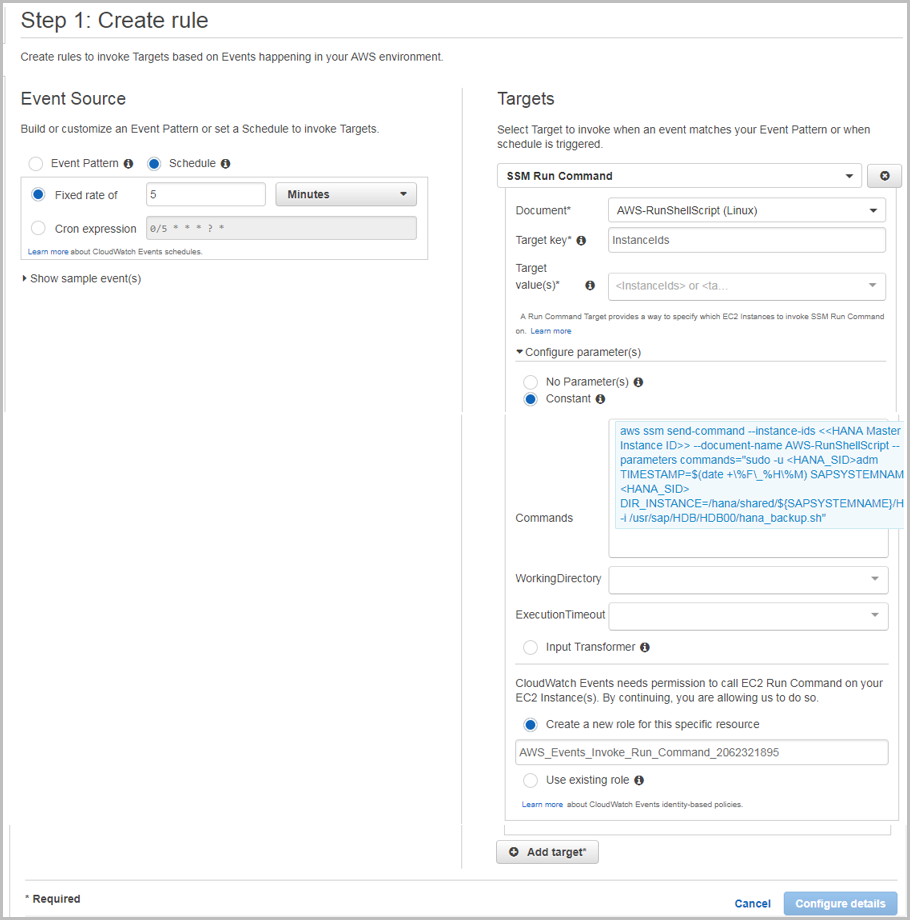
-
Restoring SAP HANA Backups and Snapshots
Restoring SAP Backups
To restore your SAP HANA database from a backup, perform the following steps:
-
If the backup files are not already available in the /backup file system but are in Amazon S3, restore the files from Amazon S3 by using the aws s3 cp command. This command has the following syntax:
aws --region <region> cp <s3-bucket/path> --recursive <backup- prefix>*.
For example:
imdbmaster:/backup/data/YYZ # aws --region us-east-1 s3 cp s3://node2-hana-s3bucket-gcynh5v2nqs3/data/YYZ . --recursive -- include COMPLETE*
-
Recover the SAP HANA database by using the Recovery Wizard as outlined in the SAP HANA Administration Guide
. Specify File as the destination type and enter the correct backup prefix. Figure 7: Restore example

-
When the recovery is complete, you can resume normal operations and clean up backup files from the ` /backup/<SID>/*` directories.
Restoring EBS Snapshots
To restore EBS snapshots, perform the following steps:
-
Create a new volume from the snapshot:
aws ec2 create-volume --region us-west-2 --availability-zone us- west-2a --snapshot-id snap-1234abc123a12345a --volume-type gp2
-
Attach the newly created volume to your EC2 host:
aws ec2 attach-volume --region=us-west-2 --volume-id vol- 4567c123e45678dd9 --instance-id i-03add123456789012 --device /dev/sdf
-
Mount the logical volume associated with SAP HANA data on the host:
mount /dev/sdf /hana/data
-
Start your SAP HANA instance.
Note
For large mission-critical systems, we highly recommend that you execute the volume initialization command on the database data and log volumes after restoring the AMI but before starting the database. Executing the volume initialization command will help you avoid extensive wait times before the database is available. Here is the sample fio command that you can use:
sudo fio –filename=/dev/xvdf –rw=read –bs=128K –iodepth=32 – ioengine=libaiodirect=1 –name=volume-initialize
For more information about initializing Amazon EBS volumes, see the AWS documentation.
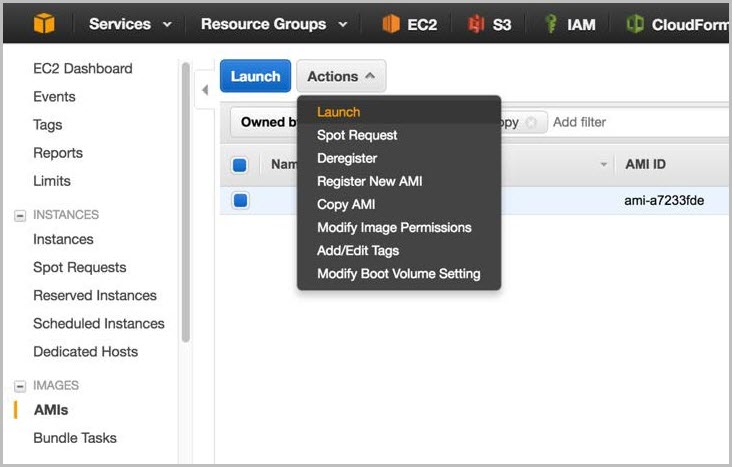
Restoring AMI Snapshots
You can restore your SAP HANA AMI snapshots through the AWS Management Console. Open the Amazon EC2 console
Choose the AMI that you want to restore, expand Actions, and then choose Launch.
Figure 8: Restoring an AMI snapshot