Get started with Lambda
All projects need a compute capability to handle processing tasks. Here are some examples:
-
Handling web application and API requests
-
Transforming batches of data
-
Processing messages from a queue
-
Resizing images
-
Generating dynamic PDFs from customer data
In traditional applications, you write code to do these tasks. You organize that code into functions. You put the function code inside an application framework. Whichever framework you picked will run inside a language dependent runtime environment. Finally, that runtime environment will be hosted on a virtual or physical server.
Setting up, configuring and maintaining the frameworks, runtime environments, and virtual or physical infrastructure slows down your delivery of features, bug fixes, and improvements.
What is Lambda?
In Lambda, you write function code. Lambda runs the functions. That’s it. There are no servers.

“No Server Is Easier To Manage Than No Server” - Werner Vogels, VP and CTO
The Lambda service runs instances of your function only when needed and scales automatically from zero requests per day to thousands per second. You pay only for the compute time that’s actually used — there is no charge when your code is not running.
Fundamentals
Serverless solutions are based on event-driven architecture, or EDA, where services send and receive events, which represent an update or change in state. The primary activity of Lambda functions is to process events.
Within the Lambda service, your function code is stored in a code package, deployed as a .zip or a container image. All interaction with the code occurs through the Lambda API. There is no direct invocation of functions from outside of the Lambda service.
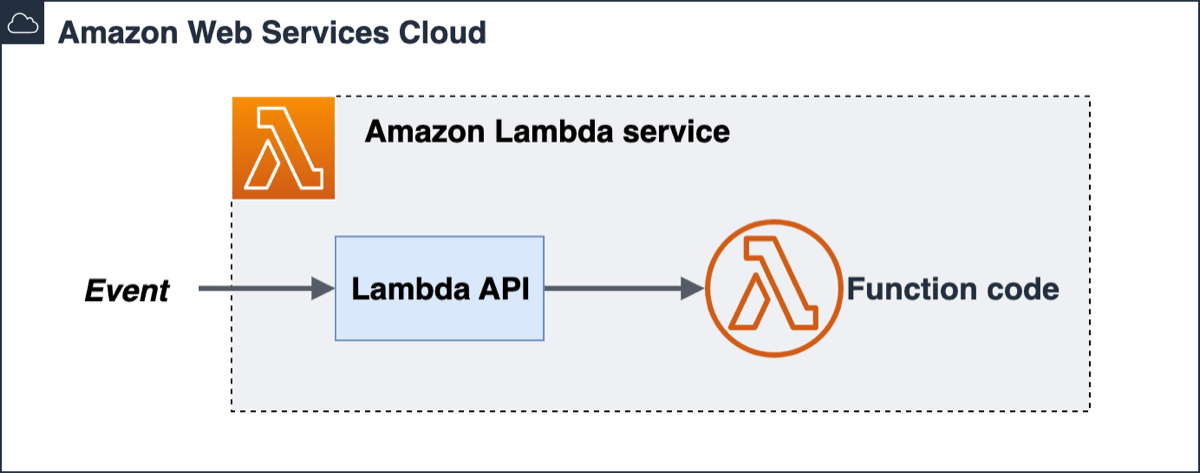
What you will learn on your journey to building applications with Lambda:
-
How the event-driven programming model invokes Lambda functions
-
How to create, invoke, test, update, package, and secure functions
-
How the execution and runtime environment runs your functions
-
How to view logs and monitor your functions
-
Where to find hands-on opportunities to learn how to invoke functions
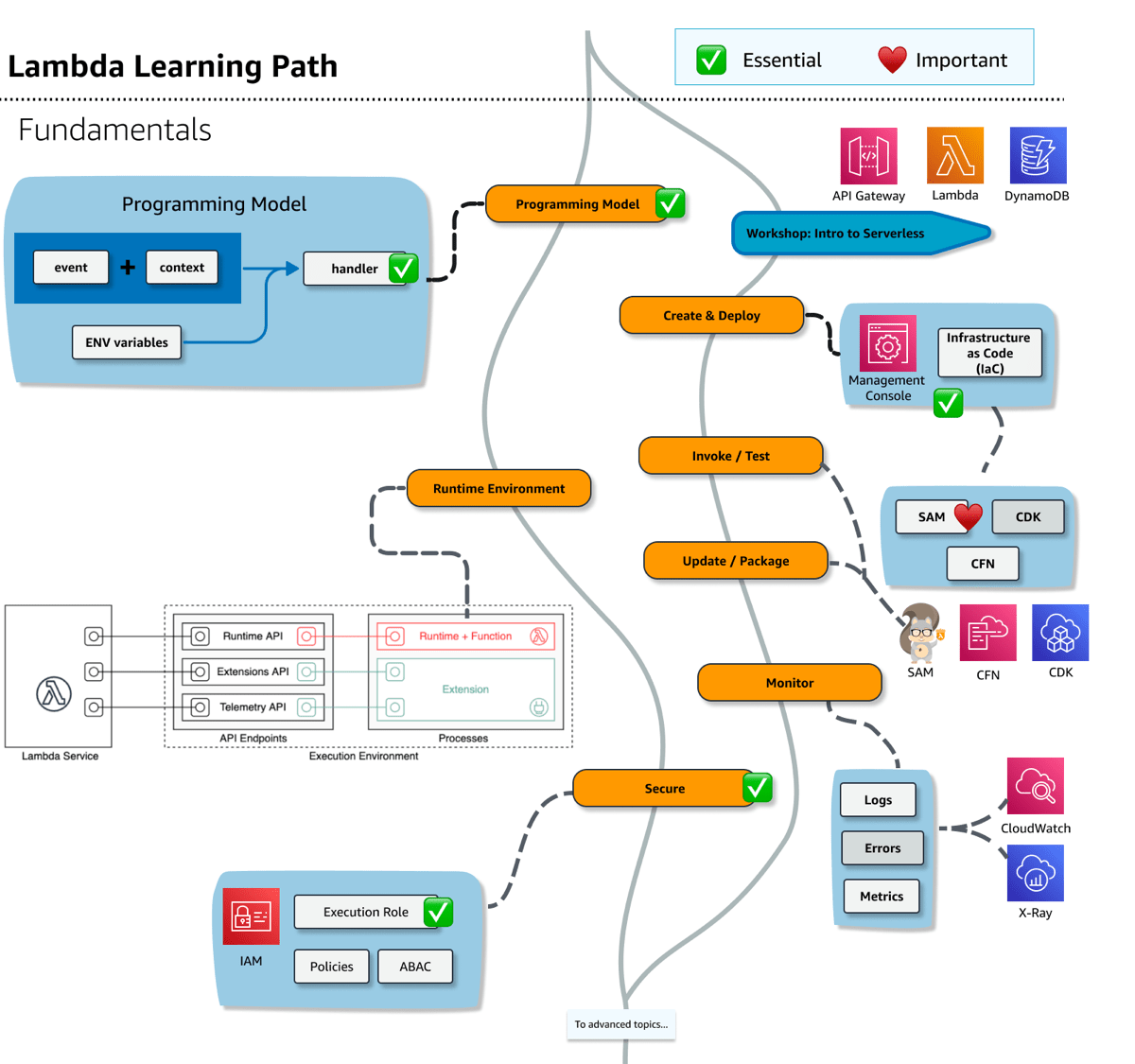
Fundamentals - conceptual and practical paths
The following is a text representation of the key concepts in the preceding diagram.
The Lambda learning path forks into two paths. The conceptual path focuses on the programming model, runtime environment, and security concepts. The other path includes practical steps to build a application while introducing development workflow activities such as how to create and deploy functions, invoke and test, update and package, and monitor the logs and troubleshoot errors.
Programming Model
-
Event plus Context and Environment variables (ENV) are inputs to a Handler function
-
ENV variables
-
Runtime environment
Create & Deploy
-
Management Console
-
Infrastructure as Code (IaC) - CloudFormation (CFN), AWS SAM (SAM), AWS Cloud Development Kit (AWS CDK)
-
Deploy .zip file archives — when you need additional libraries, or compiled languages.
-
Versions - by publishing a version of your function, you can store your code and configuration as separate stable resources
Invoke/Test
-
Synchronous invocation
-
Testing locally and in the cloud with the help of AWS SAM templates and AWS SAM CLI
Update / Package
-
Updating code and dependencies
-
Packaging with the help of AWS SAM templates and AWS SAM CLI
Monitor
-
Logs in CloudWatch
-
Errors and tracing in X-Ray
-
Metrics
Secure
-
Execution role
-
Policies that grant least privilege to your functions
Workshop - Intro to Serverless - Before diving too deep, you can choose to try out serverless in a workshop or tutorial. Connect to a data source and create a REST API with your first Lambda function.”
-
Services used: AWS Management Console, Lambda, DynamoDB, API Gateway
Programming Model
The Lambda service provides the same event-based programming model for all languages. The Lambda runtime passes an invocation event and context to your Lambda function handler which does some work and produces a resulting event:
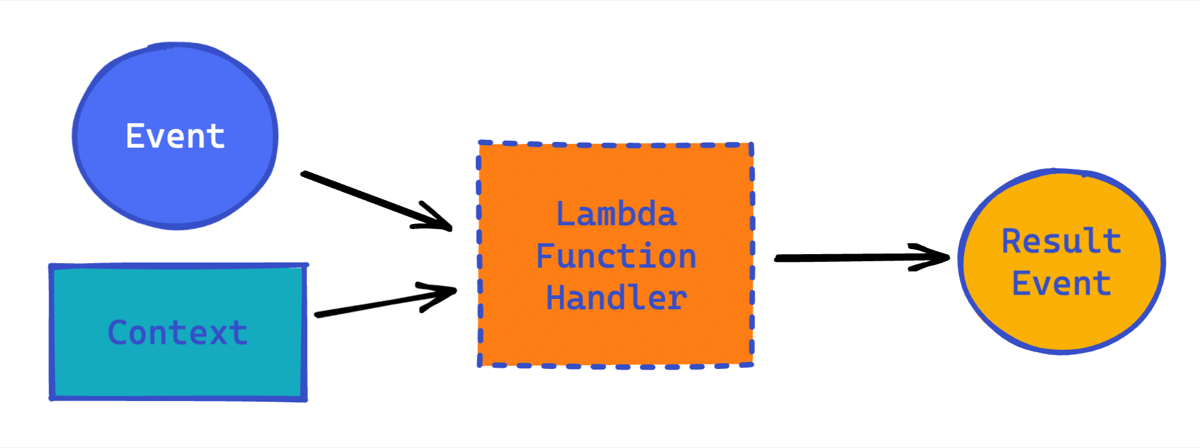
The invocation event contains data, as a JSON packet, which varies from service to service. For example, API gateway events include path, HTTP method, query string parameters, headers, cookies, and more. DynamoDB events could contain updated or delete record data. S3 events include the bucket name and object key, among other things.
The context contains information about the environment the function is running inside. Additional contextual information can be set in familiar environment variables (ENV).
The function handler is a method in your function code that processes the inbound event. The handler, which is a standard function in your language of choice, does some work and emits a result event.
After the handler finishes processing the first event, the runtime sends it another, and another. Each instance of your function could process thousands of requests.
Unlike traditional servers, Lambda functions do not run constantly. When a function is triggered by an event, this is called an invocation. Lambda functions are limited to 15 minutes in duration, but on average, across all AWS customers, most invocations last for less than a second.
There are many types of invocation events. Some examples:
-
HTTP request from API Gateway
-
Schedule managed by an EventBridge rule
-
Message from an IOT device
-
Notification that a file was uploaded to an S3 bucket
Even the smallest Lambda-based application uses at least one event that invokes your function.
How Lambda invokes your function (runtime environment)
Lambda invokes your function in an execution environment, which contains a secure and isolated runtime environment.
-
A runtime provides a language-specific environment which relays invocation events, context information, and responses between the Lambda and your functions.
-
An execution environment manages the processes and resources that are required to run the function.
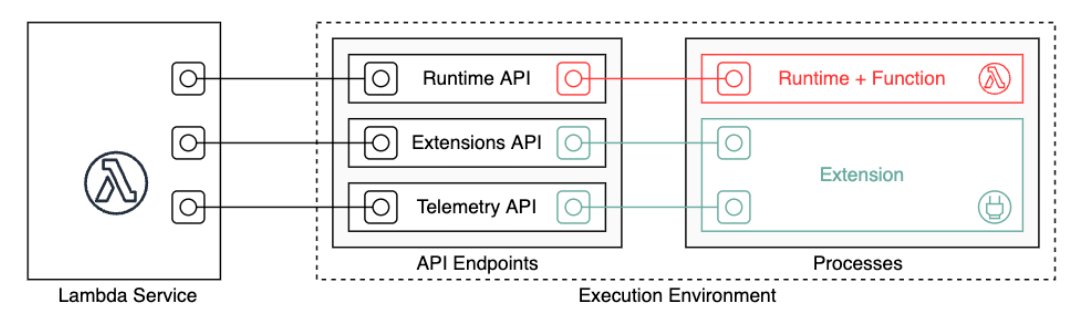
You can use runtimes that Lambda provides for JavaScript (Node.js), TypeScript, Python, Java, Go, C#, and PowerShell, or you can build your own custom runtime environment inside of a container.
If you package your code as a .zip file archive, you must configure your function to use a runtime that matches your programming language. For a container image, you include the runtime when you build the image.
How to process events with a Lambda handler
Conceptually, there are only three steps to processing events with Lambda:
-
Configure the entry point to your function, known as the handler, and deploy the function.
-
Lambda service initializes the function, then it invokes the handler with an invocation event and context.
-
Your handler function processes the event and returns a response event.
Subsequent events will invoke the handler again, without the initialization delay. During this cycle, the function stays in memory, so clients and variables declared outside of the handler method can be reused.
After a period of time, Lambda will eventually tear down the runtime. This can happen for a variety of reasons; some examples: scaling down to conserve resources, updating the function, updating the runtime.
The function handler is the essential component of your function code. As noted previously, the handler is the entry point, but it may not be the only function in your code. In fact, a best practice is keeping the handler sparse and doing the actual processing in other functions in your code.
Here are some example handlers:
Handlers in interpreted languages can be deployed directly through the web-based AWS Management Console. Compiled languages, such as Java and C#, or functions that use external libraries are deployed using .zip file archives or container images. Because of that additional process, this guide will focus on Python for examples.
Regardless of language, Lambda functions will generally return a response event on successful completion. The following program listing is an example response event to send back to API Gateway so that it can handle a request:
{
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"isBase64Encoded": false,
"multiValueHeaders": {
"X-Custom-Header": ["My value", "My other value"],
},
"body": "{\n \"TotalCodeSize\": 104330022,\n \"FunctionCount\": 26\n}"
}How to write logs with serverless applications
You might have noticed the logging statements in the preceding handler code. Where do those log messages go?
During invocation, the Lambda runtime automatically captures function output to Amazon CloudWatch
In addition to logging your function's output, the runtime also logs entries when function invocation starts and ends. This includes a report log with the request ID, billed duration, initialization duration, and other details. If your function throws an error, the runtime returns that error to the invoker.
To help simplify troubleshooting, the AWS Serverless Application Model CLI (AWS SAM CLI) has a command called sam logs which will show you CloudWatch Logs generated by your Lambda function.
For example, the following terminal command would show the live tail of logs generated by the YourLambdaFunctionName Lambda function:
sam logs -n YourLambdaFunctionName --tail
Logging and debugging go hand in hand. Traces of events are available with Amazon X-Ray for debugging.
Securing functions
AWS Identity and Access Management
-
resource policy: Defines which events are authorized to invoke the function.
-
execution role policy: Limits what the Lambda function is authorized to do.
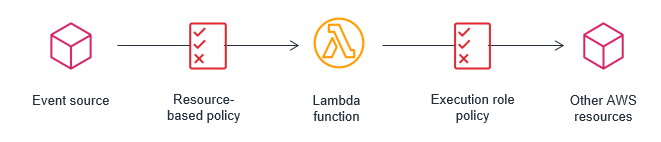
Using IAM roles to describe a Lambda function’s permissions, decouples security configuration from the code. This helps reduce the complexity of a lambda function, making it easier to maintain.
A Lambda function’s resource and execution policy should be granted the minimum required permissions for the function to perform it’s task effectively. This is sometimes referred to as the rule of least privilege. As you develop a Lambda function, you expand the scope of this policy to allow access to other resources as required.
Advanced Topics
You can do a lot by just creating a function and connecting it to an event source like API Gateway or S3 triggers.
As you progress on your journey, you should explore the following more advanced topics.
-
Connect services with event source mapping
-
Deploy code in containers
-
Add additional code with layers
-
Augment functions with extensions
-
Launch functions faster with SnapStart
-
Connect to functions with Function URLs
Event source mapping
Some services can trigger Lambda functions directly, for example, when an image is added to an S3 bucket, a Lambda can be triggered to resize it. Some services cannot invoke Lambda directly; but you can instead use an event source mapping which is a polling mechanism that reads from an event source and invokes a Lambda function.
You can use event source mappings to process items from a stream or queue in the following services:
Related resource:
-
Event source mapping official documentation, including the default behavior that batches records together into a single payload that Lambda sends to your function.
Deploy with containers
If you need a custom runtime that is not provided by AWS, you can create and deploy a custom container image. AWS provides base images preloaded with a language runtime and other components that are required to run the image on Lambda. AWS provides a Dockerfile for each of the base images to help with building your container image.
Custom containers are one way you might experiment with lift and shift of existing code to Lambda runtimes. If you do this, consider the architectural differences between always running containers, versus on demand nature of Lambda functions.
Related resource:
Add code with Layers
A Lambda layer is a .zip file archive that can contain additional code or other content. A layer can contain libraries, a custom runtime, data, or configuration files. Layers are also necessary if your function .zip archive exceeds the size limit.
Layers provide a convenient way to package libraries and other dependencies that you can use with your Lambda functions. Using layers reduces the size of uploaded deployment archives and makes it faster to deploy your code. Layers also promote code sharing and separation of responsibilities so that you can iterate faster on writing business logic.
Related resource:
Extensions
You can use Lambda extensions to augment your Lambda functions. For example, use Lambda Extensions to integrate with your preferred monitoring, observability, security, and governance tools.
Lambda supports internal or external extensions. An internal extension runs as part of the runtime process. An external extension runs as an independent process in the execution environment and continues to run after the function invocation is fully processed.
Related resources:
-
Datadog Lambda Extension
- an extension that supports submitting custom metrics, traces, and logs asynchronously while your Lambda function executes.
Launch functions faster with SnapStart
Lambda SnapStart for Java can improve startup performance by up to 10x at no extra cost, typically with no changes to your function code. The largest contributor to startup latency (often referred to as cold start time) is the time that Lambda spends initializing the function, which includes loading the function's code, starting the runtime, and initializing the function code.
![]()
With SnapStart, Lambda initializes your function when you publish a function version. Lambda takes a Firecracker microVM
Note: You can use SnapStart only on published function versions and aliases that point to versions. You can't use SnapStart on a function's unpublished version ($LATEST).
Related resources:
-
Accelerate Your Lambda Functions with Lambda SnapStart
- an AWS Compute blog article by Jeff Barr from Nov 2022 that shows the configuration change and vast difference from roughly six seconds init time to 142 milliseconds of restore time with SnapStart
Connect to functions with Function URLs
A function URL is a dedicated HTTP(S) endpoint for your Lambda function. You can create and configure a function URL through the Lambda console or the Lambda API. When you create a function URL, Lambda automatically generates a unique URL endpoint for you. Once you create a function URL, its URL endpoint never changes. Function URL endpoints have the following format:
https://<url-id>.lambda-url.<region>.on.aws
After you configure a function URL for your function, you can invoke your function through its HTTP(S) endpoint with a web browser, curl, Postman, or any HTTP client.
Related resources:
-
Function URLs - official documentation
Additional resources
Official AWS documentation:
-
AWS Lambda Developer Guide - extensive and complete documentation for Lambda
Next steps
Learn serverless techniques in an online workshop
Learn by doing in the Serverless Patterns Workshop

