This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Optimizing HPC components
The AWS Cloud provides a broad range of scalable, flexible infrastructure services that you select to match your workloads and tasks. This gives you the ability to choose the most appropriate mix of resources for your specific applications. Cloud computing makes it easy to experiment with infrastructure components and architecture design. The HPC solution components listed below are a great starting point to set up and manage your HPC cluster. Always test various solution configurations to find the best performance at the lowest cost.
Compute
The optimal compute solution for a particular HPC architecture depends on the workload deployment method, degree of automation, usage patterns, and configuration. Different compute solutions may be chosen for each step of a process. Selecting the appropriate compute solution for an architecture can lead to higher performance efficiency and lower cost.
There are multiple compute options available on AWS, and at a high level, they are separated into three categories: instances, containers, and functions. Amazon EC2 instances, or servers, are resizable compute capacity in the cloud. Containers provide operating system virtualization for applications that share an underlying operating system installed on a server. Functions are a serverless computing model that allows you to run code without thinking about provisioning and managing the underlying servers. For CFD workloads, EC2 instances are the primary compute choice.
Amazon EC2 lets you choose from a variety of compute instance types that can be configured to suit your needs. Instances come in different families and sizes to offer a wide variety of capabilities. Some instance families target specific workloads, for example, compute-, memory-, or GPU-intensive workloads, while others are general purpose. Both the targeted-workload and general-purpose instance families are useful for CFD applications based on the step in the CFD process.
When considering CFD steps, different instance types can be targeted for pre-processing, solving, and post-processing. In pre-processing, the geometry step can benefit from an instance with a GPU, while the mesh generation stage may require a higher memory-to-core ratio, such as general-purpose or memory-optimized instances. When solving CFD cases, evaluate your case size and cluster size.
If the case is spread across multiple instances, the memory requirements are low per core, and compute-optimized instances are recommended as the most cost-effective and performant choice. If a single-instance calculation is desired, it may require more memory per core and benefit from a general-purpose, or memory-optimized instance.
Optimal performance is typically obtained with compute-optimized
instances (Intel, AMD, or Graviton), and when using multiple
instances with cells per core below 100,000, instances with higher
network throughput and packet rate performance are preferred.
Refer to the
Instance
Type Matrix
AWS enables simultaneous multithreading (SMT), or hyper-threading technology for Intel processors, commonly referred to as “hyperthreading” by default for supported processors. Hyperthreading improves performance for some systems by allowing multiple threads to be run simultaneously on a single core. Most CFD applications do not benefit from hyperthreading, and therefore, disabling it tends to be the preferred environment. Hyperthreading is easily disabled in Amazon EC2. Unless an application has been tested with hyperthreading enabled, it is recommended that hyperthreading be disabled and that processes are launched and pinned to individual cores.
There are many compute options available to optimize your compute environment. Cloud deployment allows for experimentation on every level from operating system to instance type to bare-metal deployments. Time spent experimenting with cloud-based clusters is vital to achieving the desired performance.
Network
Most CFD workloads exceed the capacity of a single compute node and require a cluster-based solution. A crucial factor in achieving application performance with a multi-node cluster is optimizing the performance of the network connecting the compute nodes.
Launching instances within a cluster placement group provides consistent, low latency within a cluster. Instances launched within a cluster placement group are also launched to the same Availability Zone.
To further improve the network performance between EC2 instances, you can use an Elastic Fabric Adapter (EFA) on select instance types. EFA is designed for tightly coupled HPC workloads by providing an operating system (OS)-bypass capability and hardware-designed reliability to take advantage of the EC2 network. It works well with CFD solvers. OS-bypass is an access model that allows an application to bypass the operating system’s TCP/IP stack and communicate directly with the network device. This provides lower and more consistent latency and higher throughput than the TCP transport traditionally used. When using EFA, your normal IP traffic remains routable and can communicate with other network resources.
CFD applications use EFA through a message passing interface (MPI)
implementation using the
Libfabric
Storage
AWS provides many storage options for CFD, including object
storage with Amazon S3
A vital part of working with CFD solvers on AWS is the management of case data, which includes files such as CAD, meshes, input files, and output figures. In general, all CFD users want to maintain availability of the data when it is in use and to archive a subset of the data if it’s needed at some point in the future.
An efficient data lifecycle uses a combination of storage types and tiers to minimize costs. Data is described as hot, warm, and cold, depending on the immediate need of the data.
-
Hot data is data that you need immediately, such as a case or sweep of cases about to be deployed.
-
Warm data is your data, which is not needed at the moment, but it may be used sometime in the near future; perhaps within the next six months.
-
Cold data is data that may not ever be used again, but it is stored for archival purposes.
Your data lifecycle can occur only within AWS, or it can be
combined with an on-premises workflow. For example, you may move
case data, such as a case file, from your local computing
facilities, to Amazon S3, and then to an EC2 cluster. Completed
runs can traverse the same path in reverse back to your
on-premises environment or to Amazon S3 where they can remain in
the S3 Standard or S3 Infrequent Access storage class, or
transitioned to
Amazon S3 Glacier
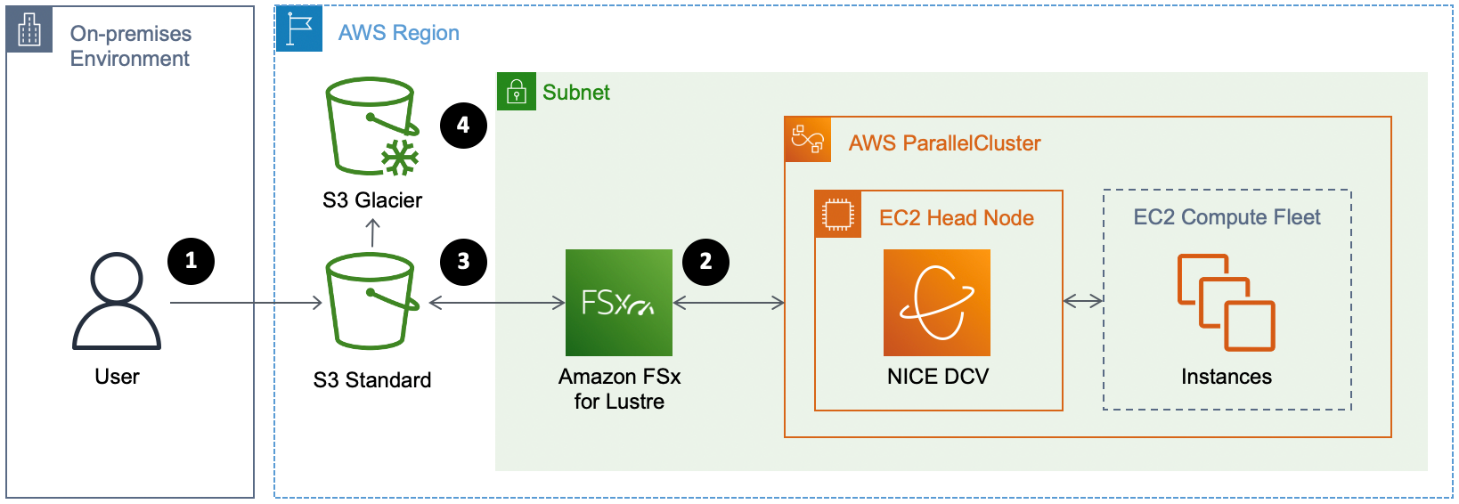
Data lifecycle
-
Transferring input data to AWS
-
Running your simulation with input (hot) data
-
Storing your output (warm) data
-
Archiving inactive (cold) data
Transferring input data
Input data, such as a CAD file, may start on-premises and be transferred to AWS. Input data is often transferred to Amazon S3 and stored until you are ready to run your simulation. S3 offers highly scalable, reliable, durable, and secure storage. An S3 workflow decouples storage from your compute cluster and provides a cost-effective approach. Alternatively, you can transfer your input data to an existing file system at runtime. This approach is generally slower and less cost effective when compared to S3 because it requires more expensive resources, such as compute instances or managed file systems, to be running for the duration of the transfer.
For the data transfer, you can choose a manual, scripted, or
managed approach. Manual and scripted approaches can use the AWS CLI for transferring data to S3, which helps optimize the data
transfer to S3 by running parallel uploads. A managed approach
can use a service, such as
AWS DataSync
Running your CFD simulation
Input data for your CFD simulation is considered “hot” data when you are ready to run your simulation. This data is often accessed in a shared file system or placed on the head node if the CFD application does not require a shared drive.
If your CFD workload requires a high-performance file system, Amazon FSx for Lustre is highly recommended. FSx for Lustre works natively with Amazon S3, making it easy for you to access the input data that is already stored in S3. When linked to an S3 bucket, an FSx for Lustre file system transparently presents S3 objects as files and allows you to write results back to S3.
During the simulation, you can periodically checkpoint and write intermediate results to your S3 data repository. FSx for Lustre automatically transfers Portable Operating System Interface (POSIX) metadata for files, directories, and symbolic links (symlinks) when importing and exporting data to and from the linked data repository on S3. This allows you to maintain access controls and restart your workload at any time using the latest data stored in S3.
When your workload is done, you can write final results from your file system to your S3 data repository and delete your file system.
Storing output data
Output data from your simulation is considered “warm” data after the simulation finishes. For a cost-effective workflow, transfer the output data off of your cluster and terminate the more expensive compute and storage resources. If you stored your data in an Amazon EBS volume, transfer your output data to S3 with the AWS CLI. If you used FSx for Lustre, create a data repository task to manage the transfer of output data and metadata to S3 or export your files with HSM commands. You can also periodically push the output data to S3 with a data repository task.
Archiving inactive data
After your output data is stored in S3 and is considered cold or
inactive, transition it to a more cost-effective storage class,
such as
Amazon S3 Glacier and S3 Glacier Deep Archive
Storage summary
Use the following table to select the best storage solution for your workload:
Table 1 — Storage services and their uses
| Service | Description | Use |
|---|---|---|
| Amazon EBS | Block storage | Block storage or export as a Network File System (NFS) share |
| Amazon FSx for Lustre | Managed Lustre | Fast parallel high-performance file system optimized for HPC workloads |
| Amazon S3 | Object storage | Store case files, input, and output data |
| Amazon S3 Glacier | Archival storage | Long-term storage of archival data |
| Amazon EFS | Managed NFS | Network File System (NFS) to share files across multiple instances. Occasionally used for home directories. Not generally recommended for CFD cases. |
Visualization
A graphical interface is useful throughout the CFD solution
process, from building meshes, debugging flow-solution errors, and
visualizing the flow field. Many CFD solvers include visualization
packages as part of their installation. As an example,
ParaView
Post processing in AWS can reduce manual extractions, lower time to results, and decrease data transfer costs. Visualization is often performed remotely with either an application that supports client-server mode or with remote visualization of the server desktop. Client-server mode works well on AWS and can be implemented in the same way as other remote desktop set-ups. When using client-server mode for an application, it is important to connect to the server using the public IP address and not the private IP address, unless you have private network connectivity configured, such as a Site-to-Site VPN.
AWS offers NICE
DCV
AWS also offers managed desktop and application streaming
services, such as
Amazon WorkSpaces
In general, visualizing CFD results on AWS reduces the need to download large data back to on-premises storage, and it helps reduce cost and increase productivity.
