AWS IoT Greengrass Version 1 2023 年 6 月 30 日进入延长寿命阶段。有关更多信息,请参阅 AWS IoT Greengrass V1 维护策略。在此日期之后,将 AWS IoT Greengrass V1 不会发布提供功能、增强功能、错误修复或安全补丁的更新。在上面运行的设备 AWS IoT Greengrass V1 不会中断,将继续运行并连接到云端。我们强烈建议您迁移到 AWS IoT Greengrass Version 2,这样可以添加重要的新功能并支持其他平台。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
如何使用 AWS Management Console配置机器学习推理
要按照本教程中的步骤操作,你需要 C AWS IoT Greengrass ore v1.10 或更高版本。
您可以使用本地生成的数据在 Greengrass 核心设备上本地执行机器学习 (ML) 推理。有关信息(包括要求和约束),请参阅执行机器学习推理。
本教程介绍如何使用配置 Greengrass 群组 AWS Management Console 以运行 Lambda 推理应用程序,该应用程序可在本地识别来自相机的图像,而无需将数据发送到云端。推理应用程序访问 Raspberry Pi 上的摄像头模块,并使用开源模型运行推理。SqueezeNet
本教程包含以下概括步骤:
先决条件
要完成此教程,需要:
-
Raspberry Pi 4 Model B 或 Raspberry Pi 3 Model B/B+,已设置并配置为与一起使用。 AWS IoT Greengrass要使用 AWS IoT Greengrass设置 Raspberry Pi,请运行 Greengrass 设备安装脚本,或确保您已完成 入门 AWS IoT Greengrass 的模块 1 和模块 2。
注意
Raspberry Pi 可能需要一个 2.5A 的电源
来运行通常用于图像分类的深度学习框架。额定值不足的电源可能会导致设备重新启动。 -
Raspberry Pi 摄像机模块 V2 - 800 万像素,1080p
。要了解关于如何设置摄像机的更多信息,请参阅 Raspberry Pi 文档中的连接摄像机 。 -
Greengrass 组和 Greengrass 核心。有关如何创建 Greengrass 组或核心的信息,请参阅 入门 AWS IoT Greengrass。
注意
本教程使用 Raspberry Pi,但 AWS IoT Greengrass 支持其他平台,例如英特尔凌动和 NVIDIA Jetson TX2。在 Jetson 的示例中 TX2,您可以使用静态图像代替从摄像机传输的图像。如果使用 Jetson TX2 示例,则可能需要安装 Python 3.6 而不是 Python 3.7。有关配置设备以便安装 C AWS IoT Greengrass ore 软件的信息,请参阅设置其他设备。
对于 AWS IoT Greengrass 不支持的第三方平台,您必须在非容器化模式下运行 Lambda 函数。要在非容器化模式下运行,必须以 root 用户身份运行 Lambda 函数。有关更多信息,请参阅选择 Lambda 函数容器化时的注意事项 和为组中的 Lambda 函数设置默认访问身份。
步骤 1:配置 Raspberry Pi
在该步骤中,将安装 Raspbian 操作系统的更新,安装摄像机模块软件和 Python 依赖项,以及启用摄像机接口。
在您的 Raspberry Pi 终端中运行以下命令。
-
安装 Raspbian 的更新。
sudo apt-get update sudo apt-get dist-upgrade -
安装适用于摄像机模块的
picamera接口以及本教程所需的其他 Python 库。sudo apt-get install -y python3-dev python3-setuptools python3-pip python3-picamera验证安装:
-
确保您的 Python 3.7 安装包含 pip。
python3 -m pip如果未安装 pip,请从 pip 网站
下载它,然后运行以下命令。 python3 get-pip.py -
确保您的 Python 版本为 3.7 或更高版本。
python3 --version如果输出列出了早期版本,请运行以下命令。
sudo apt-get install -y python3.7-dev -
确保已成功安装 Setuptools 和 Picamera。
sudo -u ggc_user bash -c 'python3 -c "import setuptools"' sudo -u ggc_user bash -c 'python3 -c "import picamera"'如果输出未包含错误,则表示验证成功。
注意
如果设备上安装的 Python 可执行文件是
python3.7,请将python3.7而非python3用于本教程中的命令。确保 pip 安装映射到正确的python3.7或python3版本以避免依赖项错误。 -
-
重启 Raspberry Pi。
sudo reboot -
打开 Raspberry Pi 配置工具。
sudo raspi-config -
使用箭头键打开接口选项并启用摄像机接口。如果出现提示,请允许设备重新启动。
-
使用以下命令测试摄像机设置。
raspistill -v -o test.jpg这将在 Raspberry Pi 上打开一个预览窗口,将名为
test.jpg的图片保存到您的当前目录,并在 Raspberry Pi 终端中显示有关摄像机的信息。
步骤 2:安装 MXNet 框架
在此步骤中,在 Raspberry Pi 上安装 MXNet 库。
-
远程登录您的 Raspberry Pi。
ssh pi@your-device-ip-address -
打开 MXNet 文档,打开 “安装
” MXNet,然后按照说明在设备 MXNet 上安装。 注意
我们建议在本教程中安装版本 1.5.0 并 MXNet 从源代码构建,以避免设备冲突。
-
安装后 MXNet,请验证以下配置:
-
确保
ggc_user系统帐户可以使用该 MXNet框架。sudo -u ggc_user bash -c 'python3 -c "import mxnet"' -
确保 NumPy 已安装。
sudo -u ggc_user bash -c 'python3 -c "import numpy"'
-
步骤 3:创建 MXNet 模型包
在此步骤中,创建一个模型包,其中包含要上传到亚马逊简单存储服务 (Amazon S3) 的预训练 MXNet 模型示例。 AWS IoT Greengrass 可以使用 Amazon S3 中的模型包,前提是您使用 tar.gz 或 zip 格式。
-
在您的计算机上,从下载 Raspberry Pi 的 MXNet 示例机器学习示例。
-
不要解压下载的
mxnet-py3-armv7l.tar.gz文件。 -
导航到
squeezenet目录。cdpath-to-downloaded-sample/mxnet-py3-armv7l/models/squeezenet此目录中的
squeezenet.zip文件是您的模型包。它包含用于图像分类模型的 SqueezeNet 开源模型工件。稍后,您可将此模型包上传到 Amazon S3。
步骤 4:创建并发布 Lambda 函数
在此步骤中,创建 Lambda 函数部署程序包和 Lambda 函数。接下来,发布函数版本并创建别名。
首先,创建 Lambda 函数部署程序包。
-
在您的计算机上,导航到您在步骤 3:创建 MXNet 模型包中提取的示例程序包中的
examples目录。cdpath-to-downloaded-sample/mxnet-py3-armv7l/examplesexamples目录包含函数代码和依赖项。-
greengrassObjectClassification.py是本教程中使用的推理代码。可以将此代码用作模板来创建您自己的推理函数。 -
greengrasssdk是适用于 Python 的 AWS IoT Greengrass 核心 SDK 的 1.5.0 版本。注意
如果提供了新版本,您可以下载该版本并升级部署程序包中的开发工具包版本。有关更多信息,请参阅适用于 Python 的AWS IoT Greengrass 核心开发工具包
GitHub。
-
-
将
examples目录的内容压缩到一个名为greengrassObjectClassification.zip的文件中。这就是您的部署程序包。zip -r greengrassObjectClassification.zip .注意
确保
.py文件和依赖项位于该目录的根目录中。下一步,创建 Lambda 函数。
-
在 AWS IoT 控制台中,选择 “函数” 和 “创建函数”。
-
选择从头开始创作并使用以下值创建您的函数:
-
对于函数名称,请输入
greengrassObjectClassification。 -
对于运行时系统,选择 Python 3.7。
对于权限,请保留默认设置。这将创建一个授予基本 Lambda 权限的执行角色。此角色未被使用 AWS IoT Greengrass。
-
-
选择 Create function (创建函数)。
现在,上传您的 Lambda 函数部署程序包并注册处理程序。
-
选择您的 Lambda 函数并上传您的 Lambda 函数部署包。
-
在代码选项卡上的代码源下,选择上传自。从下拉列表中选择 .zip 文件。
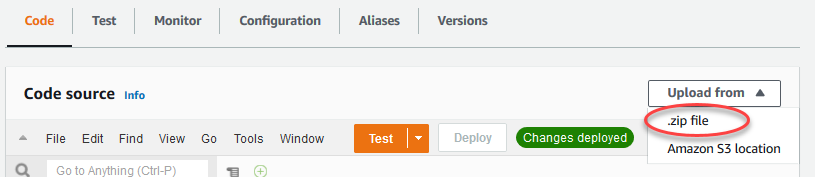
-
选择上传,然后选择您的
greengrassObjectClassification.zip部署包。然后,选择保存。 -
在函数的代码选项卡中,在运行时设置下选择编辑,然后输入以下值。
-
对于运行时系统,选择 Python 3.7。
-
对于处理程序,输入
greengrassObjectClassification.function_handler。
选择保存。
-
接下来,发布您的 Lambda 函数的第一个版本。然后,创建版本的别名。
注意
Greengrass 组可以按别名(推荐)或版本引用 Lambda 函数。使用别名,您可以更轻松地管理代码更新,因为您在更新函数代码时,不必更改订阅表或组定义。相反,您只需将别名指向新的函数版本。
-
-
在操作菜单上,选择发布新版本。

-
对于版本描述,输入
First version,然后选择发布。 -
在greengrassObjectClassification:1 配置页面上,从 “操作” 菜单中选择 “创建别名”。

-
在创建新别名页面上,使用以下值:
-
对于名称,输入
mlTest。 -
对于 Version (版本),输入
1。
注意
AWS IoT Greengrass 不支持 $LATEST 版本的 Lambda 别名。
-
-
选择保存。
现在,将 Lambda 函数添加到 Greengrass 组。
步骤 5:将 Lambda 函数添加到 Greengrass 组
在该步骤中,将 Lambda 函数添加到该组,然后配置其生命周期和环境变量。
首先,将 Lambda 函数添加到 Greengrass 组。
-
在 AWS IoT 控制台导航窗格的管理下,展开 Greengrass 设备,然后选择群组 (V1)。
-
在组配置页面上,选择 Lambda 函数选项卡。
-
在我的 Lambda 函数部分下,选择添加。
-
对于 Lambda 函数,请选择。greengrassObjectClassification
-
对于 Lambda 函数版本,请选择 Alias:mlTest。
接下来,配置 Lambda 函数的生命周期和环境变量。
-
在 Lambda 函数配置部分中,进行以下更新。
注意
我们建议您在不进行容器化的情况下运行 Lambda 函数,除非您的业务案例需要这样做。这有助于您在无需配置设备资源的前提下访问您的设备 GPU 和摄像头。如果您在没有容器化的情况下运行,则还必须授予对 Lambda 函数 AWS IoT Greengrass 的根访问权限。
-
在不进行容器化的情况下运行:
-
对于系统用户和群,请选择
Another user ID/group ID。在系统用户 ID 中,输入0。在系统组 ID 中,输入0。这将允许您的 Lambda 函数以根用户身份运行。有关以根用户身份运行的更多信息,请参阅 为组中的 Lambda 函数设置默认访问身份。
提示
您还必须更新
config.json文件,从而能够为 Lambda 函数授予根用户访问权限。有关此步骤,请参阅 以根用户身份运行 Lambda 函数。 -
对于 Lambda 函数容器化,请选择无容器。
有关不进行容器化的情况下运行的更多信息,请参阅 选择 Lambda 函数容器化时的注意事项。
-
对于超时,输入
10 seconds。 -
对于已固定,选择 True。
有关更多信息,请参阅 Greengrass Lambda 函数的生命周期配置。
-
-
改为在容器化模式下运行:
注意
我们不建议以容器化模式运行,除非您的业务案例需要这样做。
-
对于系统用户和组,选择使用组默认值。
-
对于 Lambda 函数容器化,选择使用组默认值。
-
对于内存限制,输入
96 MB。 -
对于超时,输入
10 seconds。 -
对于已固定,选择 True。
有关更多信息,请参阅 Greengrass Lambda 函数的生命周期配置。
-
-
-
在 Environment variables (环境变量) 下,创建一个键/值对。与 Raspberry Pi 上的 MXNet 模型交互的函数需要键值对。
对于键,使用 MXNET_ENGINE_TYPE。对于该值,请使用 NaiveEngine。
注意
在您自己的用户定义的 Lambda 函数中,您可以选择在函数代码中设置环境变量。
-
为所有其他属性保留默认值,然后选择添加 Lambda 函数。
步骤 6:将资源添加到 Greengrass 组
在该步骤中,将为摄像机模块和 ML 推理模型创建资源,并将该资源与 Lambda 函数关联。这使 Lambda 函数能够访问核心设备上的资源。
注意
如果您在非容器化模式下运行,则无需配置这些设备资源 AWS IoT Greengrass 即可访问您的设备 GPU 和摄像头。
首先,为摄像机创建两种本地设备资源:一种用于共享内存,另一种用于设备接口。有关本地资源访问的更多信息,请参阅使用 Lambda 函数和连接器访问本地资源。
-
在组配置页面上,选择资源选项卡。
-
在本地资源部分,选择添加本地资源。
-
在 添加本地资源 页面上,使用以下值:
-
对于资源名称,输入
videoCoreSharedMemory。 -
对于 Resource type (资源类型),选择 Device (设备)。
-
对于 本地设备路径,输入
/dev/vcsm。设备路径是设备资源的本地绝对路径。该路径只能引用
/dev下的字符设备或块储存设备。 -
在 系统组所有者和文件访问权限 下,选择 自动添加拥有资源的系统组的文件系统权限。
组所有者文件访问权限选项可让您授予对 Lambda 进程的额外的文件访问权限。有关更多信息,请参阅 组所有者文件访问权限。
-
-
接下来,您将为摄像机接口添加本地设备资源。
-
选择添加本地资源。
-
在 添加本地资源 页面上,使用以下值:
-
对于资源名称,输入
videoCoreInterface。 -
对于 Resource type (资源类型),选择 Device (设备)。
-
对于 本地设备路径,输入
/dev/vchiq。 -
在 系统组所有者和文件访问权限 下,选择 自动添加拥有资源的系统组的文件系统权限。
-
-
在页面底部,选择添加资源。
现在,将推理模型添加为机器学习资源。该步骤包含将 squeezenet.zip 模型包上传到 Amazon S3。
-
在组的资源选项卡上,在机器学习部分,选择添加机器学习资源。
-
在 添加机器学习资源 页面上,对于 资源名称,输入
squeezenet_model。 -
对于模型来源,选择使用存储在 S3 中的模型,例如通过深度学习编译器优化的模型。
-
对于 S3 URI,请输入 S3 桶的保存路径。
-
选择浏览 S3。这会在 Amazon S3 控制台中打开一个新选项卡。
-
在 Amazon S3 控制台选项卡上,将
squeezenet.zip文件上传到 S3 桶。有关信息,请参阅 Amazon Simple Storage Service 用户指南中的如何将文件和文件夹上传到 S3 存储桶?。注意
为了便于访问 S3 桶,桶名称必须包含字符串
greengrass并且桶所在的区域必须与您用于 AWS IoT Greengrass的区域相同。请选择唯一名称(如greengrass-bucket-)。不要在存储桶名称中使用句点 (user-id-epoch-time.)。 -
在 AWS IoT Greengrass 控制台选项卡上,找到并选择您的 S3 存储桶。找到并上传
squeezenet.zip文件,然后选择 Select (选择)。您可能需要选择刷新以更新可用存储桶和文件的列表。 -
对于 Destination path (目的地路径),输入
/greengrass-machine-learning/mxnet/squeezenet。这是 Lambda 运行时目标命名空间中本地模型的目标。部署群组时,会 AWS IoT Greengrass 检索源模型包,然后将内容提取到指定目录。本教程的示例 Lambda 函数已配置为使用该路径 (在
model_path变量中)。 -
在系统组所有者和文件访问权限下,选择不含系统组。
-
选择添加资源。
使用经过 SageMaker 人工智能训练的模型
本教程使用存储在 Amazon S3 中的模型,但您也可以轻松使用 SageMaker AI 模型。该 AWS IoT Greengrass 控制台内置了 SageMaker AI 集成,因此您无需手动将这些模型上传到 Amazon S3。有关使用 SageMaker AI 模型的要求和限制,请参阅支持的模型源。
要使用 SageMaker AI 模型,请执行以下操作:
-
对于模型来源,选择使用在 AWS SageMaker AI 中训练的模型,然后选择模型训练作业的名称。
-
对于本地路径,输入您的 Lambda 函数在其中查找该模型的目录的路径。
步骤 7:将订阅添加到 Greengrass 组
在该步骤中,将订阅添加到该组。此订阅允许 Lambda 函数 AWS IoT 通过向 MQTT 主题发布预测结果来发送预测结果。
-
在组配置页面中,选择订阅选项卡,然后选择添加订阅。
-
在订阅详细信息页面中,按如下所述配置源和目标:
-
在源类型中,选择 Lambda 函数,然后选择。greengrassObjectClassification
-
对于目标类型,选择服务,然后选择 IoT 云。
-
-
在主题筛选条件字段中,输入
hello/world,然后选择订阅。
步骤 8:部署 Greengrass 组
在该步骤中,将最新版本的组定义部署到 Greengrass 核心设备。该定义包含您添加的 Lambda 函数、资源和订阅配置。
-
确保 AWS IoT Greengrass 核心正在运行。根据需要在您的 Raspberry Pi 终端中运行以下命令。
要检查进程守护程序是否正在运行,请执行以下操作:
ps aux | grep -E 'greengrass.*daemon'如果输出包含
root的/greengrass/ggc/packages/1.11.6/bin/daemon条目,则表示进程守护程序正在运行。注意
路径中的版本取决于 AWS IoT Greengrass 核心设备上安装的 Core 软件版本。
启动进程守护程序:
cd /greengrass/ggc/core/ sudo ./greengrassd start
-
在组配置页面上,选择部署。
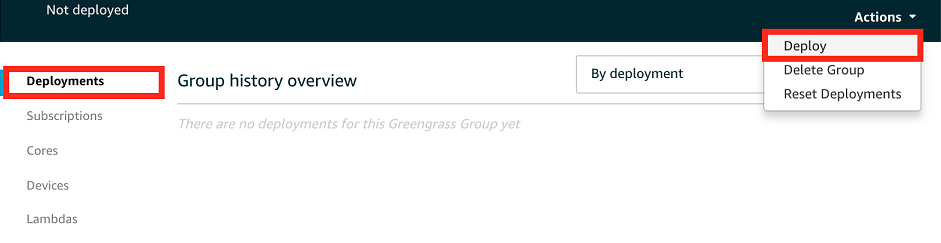
-
在 Lambda 函数选项卡的系统 Lambda 函数部分下,选择 IP 检测器,再选择编辑。
-
在编辑 IP 检测器设置对话框中,选择自动检测和覆盖 MQTT 代理端点。
-
选择保存。
这使得设备可以自动获取核心的连接信息,例如 IP 地址、DNS 和端口号。建议使用自动检测,但 AWS IoT Greengrass 也支持手动指定的端点。只有在首次部署组时,系统才会提示您选择发现方法。
注意
如果出现提示,请授予创建 Greengrass 服务角色并将其与当前角色关联的权限。 AWS 账户 AWS 区域此角色 AWS IoT Greengrass 允许访问您在 AWS 服务中的资源。
部署页面显示了部署时间戳、版本 ID 和状态。完成后,部署的状态应显示为 已完成。
有关部署的更多信息,请参阅 将 AWS IoT Greengrass 群组部署到 AWS IoT Greengrass 核心。有关问题排查帮助,请参阅故障排除 AWS IoT Greengrass。
步骤 9:测试推理应用程序
现在,您可以验证是否正确配置了部署。要进行测试,您应订阅 hello/world 主题并查看由 Lambda 函数发布的预测结果。
注意
如果将一个监视器连接到 Raspberry Pi,活动摄像机源将显示在预览窗口中。
-
在 AWS IoT 控制台的测试下,选择 MQTT 测试客户端。
-
对于 Subscriptions (订阅),使用以下值:
-
对于订阅主题,请使用 hello/world。
-
在其他配置下,对于 MQTT 负载显示,请选择将负载显示为字符串。
-
-
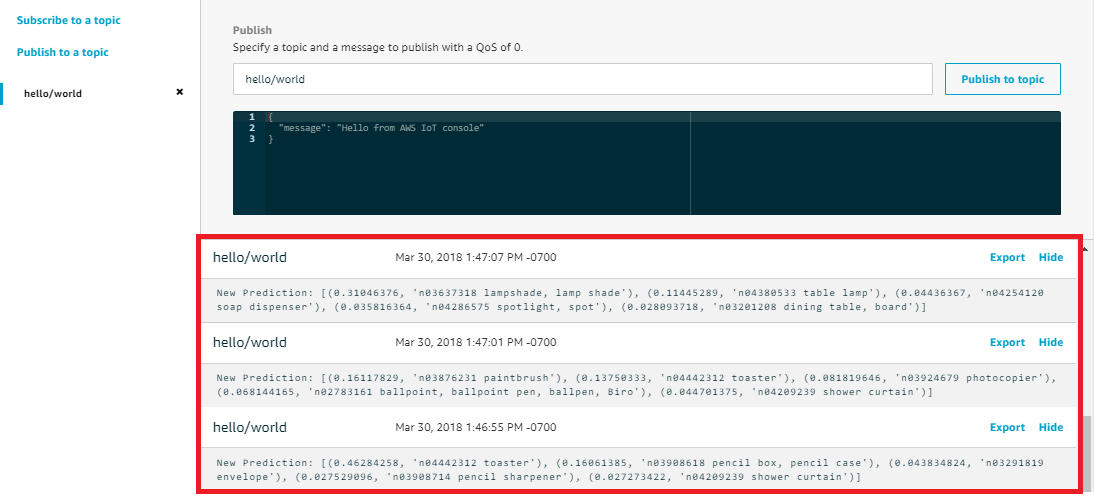
选择订阅。
如果测试成功,来自 Lambda 函数的消息将显示在页面底部。每条消息包含图像的前 5 个预测结果,这些结果使用以下格式:可能性、预测的类 ID 及对应的类名称。
对 AWS IoT Greengrass ML 推理进行故障排除
如果测试失败,您可以尝试以下问题排查步骤。在您的 Raspberry Pi 终端中运行以下命令。
检查错误日志
-
切换到根用户并导航到
log目录。访问 AWS IoT Greengrass 日志需要 root 权限。sudo su cd /greengrass/ggc/var/log -
在
system目录中,选中runtime.log或python_runtime.log。在
user/目录中,选中region/account-idgreengrassObjectClassification.log。有关更多信息,请参阅 使用日志排查问题。
runtime.log 中的“解压缩”错误
如果 runtime.log 包含类似于下面的错误,请确保您的 tar.gz 源模型包具有一个父目录。
Greengrass deployment error: unable to download the artifact model-arn: Error while processing.
Error while unpacking the file from /tmp/greengrass/artifacts/model-arn/path to /greengrass/ggc/deployment/path/model-arn,
error: open /greengrass/ggc/deployment/path/model-arn/squeezenet/squeezenet_v1.1-0000.params: no such file or directory如果您的包没有包含模型文件的父目录,请使用以下命令重新打包模型:
tar -zcvf model.tar.gz ./model
例如:
─$tar -zcvf test.tar.gz ./test./test ./test/some.file ./test/some.file2 ./test/some.file3
注意
不要在此命令中包含尾随 /* 字符。
验证 Lambda 函数是否已成功部署
-
列出
/lambda目录中已部署的 Lambda 的内容。在运行命令前替换占位符值。cd /greengrass/ggc/deployment/lambda/arn:aws:lambda:region:account:function:function-name:function-versionls -la -
验证该目录是否包含与您在 步骤 4:创建并发布 Lambda 函数 中上传的
greengrassObjectClassification.zip部署程序包相同的内容。确保
.py文件和依赖项位于该目录的根目录中。
验证推理模型是否已成功部署
-
查找 Lambda 运行时进程的进程标识号 (PID):
ps aux | grep 'lambda-function-name*'在输出中,PID 显示在 Lambda 运行时进程的行的第二列中。
-
输入 Lambda 运行时命名空间。在运行命令之前,请务必替换占位符
pid值。注意
此目录及其内容位于 Lambda 运行时命名空间中,因此它们不会显示在常规 Linux 命名空间中。
sudo nsenter -tpid-m /bin/bash -
列出您为 ML 资源指定的本地目录的内容。
cd /greengrass-machine-learning/mxnet/squeezenet/ ls -ls您应该看到以下文件:
32 -rw-r--r-- 1 ggc_user ggc_group 31675 Nov 18 15:19 synset.txt 32 -rw-r--r-- 1 ggc_user ggc_group 28707 Nov 18 15:19 squeezenet_v1.1-symbol.json 4832 -rw-r--r-- 1 ggc_user ggc_group 4945062 Nov 18 15:19 squeezenet_v1.1-0000.params
后续步骤
接下来,探索其他推理应用程序。 AWS IoT Greengrass 提供了其他 Lambda 函数,您可以使用这些函数来尝试局部推理。您可以在您在步骤 2:安装 MXNet 框架中下载的预编译库文件夹中查找示例程序包。
配置 Intel Atom
要在 Intel Atom 设备上运行本教程,您必须提供源图像、配置 Lambda 函数并添加其他本地设备资源。要使用 GPU 进行推理,请确保您的设备上已安装以下软件:
-
OpenCL 版本 1.0 或更高版本
-
Python 3.7 和 pip
注意
如果您的设备是使用 Python 3.6 预构建的,则可改为创建指向 Python 3.7 的符号链接。有关更多信息,请参阅 步骤 2。
-
下载 Lambda 函数的静态 PNG 或 JPG 图像以用于图像分类。该示例最适合小型图像文件。
将图像文件保存在包含
greengrassObjectClassification.py文件的目录中(或保存在此目录的子目录中)。此目录位于您在 步骤 4:创建并发布 Lambda 函数 中上传的 Lambda 函数部署程序包中。注意
如果您正在使用 AWS DeepLens,则可以使用机载摄像头或安装自己的摄像头,对捕获的图像而不是静态图像进行推理。但是,我们强烈建议您先用静态图像开始。
如果您使用的是摄像机,请确保
awscamAPT 程序包已安装并且是最新的。有关更多信息,请参阅 AWS DeepLens 开发人员指南中的更新 AWS DeepLens 设备。 -
如果您使用的不是 Python 3.7,请确保创建从 Python 3.x 到 Python 3.7 的符号链接。这会将你的设备配置为使用 Python 3。 AWS IoT Greengrass运行以下命令可查找您的 Python 安装:
which python3运行以下命令可创建符号链接:
sudo ln -spath-to-python-3.x/python3.xpath-to-python-3.7/python3.7重新启动设备。
-
编辑 Lambda 函数的配置。按照步骤 5:将 Lambda 函数添加到 Greengrass 组中的程序操作。
注意
我们建议您在不进行容器化的情况下运行 Lambda 函数,除非您的业务案例需要这样做。这有助于您在无需配置设备资源的前提下访问您的设备 GPU 和摄像头。如果您在没有容器化的情况下运行,则还必须授予对 Lambda 函数 AWS IoT Greengrass 的根访问权限。
-
在不进行容器化的情况下运行:
-
对于系统用户和群,请选择
Another user ID/group ID。在系统用户 ID 中,输入0。在系统组 ID 中,输入0。这将允许您的 Lambda 函数以根用户身份运行。有关以根用户身份运行的更多信息,请参阅 为组中的 Lambda 函数设置默认访问身份。
提示
您还必须更新
config.json文件,从而能够为 Lambda 函数授予根用户访问权限。有关此步骤,请参阅 以根用户身份运行 Lambda 函数。 -
对于 Lambda 函数容器化,请选择无容器。
有关不进行容器化的情况下运行的更多信息,请参阅 选择 Lambda 函数容器化时的注意事项。
-
将 Timeout (超时) 值更新为 5 秒。这可确保请求不会过早超时。设置后,需要几分钟以运行推理。
-
对于已固定,选择 True。
-
在其他参数下,在对 sys 目录的只读权限中选择启用。
-
对于 Lambda 生命周期,选择 Make this function long-lived and keep it running indefinitely (使此函数长时间生存,保持其无限期运行)。
-
-
改为在容器化模式下运行:
注意
我们不建议以容器化模式运行,除非您的业务案例需要这样做。
-
将 Timeout (超时) 值更新为 5 秒。这可确保请求不会过早超时。设置后,需要几分钟以运行推理。
-
对于已固定,选择 True。
-
在其他参数下,在对 sys 目录的只读权限中选择启用。
-
-
-
如果在容器化模式下运行,请添加所需的本地设备资源以授予对设备 GPU 的访问权限。
注意
如果您在非容器化模式下运行,则无需配置设备 AWS IoT Greengrass 资源即可访问您的设备 GPU。
-
在组配置页面上,选择资源选项卡。
-
选择添加本地资源。
-
定义资源:
-
对于资源名称,输入
renderD128。 -
对于 资源类型,选择 本地设备。
-
对于 Device path (设备路径),输入
/dev/dri/renderD128。 -
在 系统组所有者和文件访问权限 下,选择 自动添加拥有资源的系统组的文件系统权限。
-
对于 Lambda 函数从属关系,为您的 Lambda 函数授予读写访问权限。
-
-
配置 NVIDIA Jetson TX2
要在 NVIDIA Jetson 上运行本教程 TX2,请提供源图像并配置 Lambda 函数。如果您使用的是 GPU,则还必须添加本地设备资源。
-
确保您的 Jetson 设备已配置,以便您可以安装 AWS IoT Greengrass Core 软件。有关配置设备的更多信息,请参阅设置其他设备。
-
打开 MXNet 文档,前往在 Jetson MXNet 上安装
,然后按照说明在 Jetson 设备 MXNet 上进行安装。 注意
如果要 MXNet 从源代码构建,请按照说明构建共享库。编辑
config.mk文件中的以下设置以使用 Jetson TX2 设备:-
将
-gencode arch=compute-62, code=sm_62添加到CUDA_ARCH设置。 -
打开 CUDA。
USE_CUDA = 1
-
-
下载 Lambda 函数的静态 PNG 或 JPG 图像以用于图像分类。该应用最适合小型图像文件。或者,您可以分析 Jetson 板上的摄像机来捕获源图像。
将图像文件保存在包含
greengrassObjectClassification.py文件的目录中。您也可以将这些文件保存在此目录的子目录中。此目录位于您在 步骤 4:创建并发布 Lambda 函数 中上传的 Lambda 函数部署程序包中。 -
创建从 Python 3.7 到 Python 3.6 的符号链接以使用 Python 3。 AWS IoT Greengrass运行以下命令可查找您的 Python 安装:
which python3运行以下命令可创建符号链接:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7重新启动设备。
-
确保
ggc_user系统账户可以使用该 MXNet 框架:“sudo -u ggc_user bash -c 'python3 -c "import mxnet"' -
编辑 Lambda 函数的配置。按照步骤 5:将 Lambda 函数添加到 Greengrass 组中的程序操作。
注意
我们建议您在不进行容器化的情况下运行 Lambda 函数,除非您的业务案例需要这样做。这有助于您在无需配置设备资源的前提下访问您的设备 GPU 和摄像头。如果您在没有容器化的情况下运行,则还必须授予对 Lambda 函数 AWS IoT Greengrass 的根访问权限。
-
在不进行容器化的情况下运行:
-
对于系统用户和群,请选择
Another user ID/group ID。在系统用户 ID 中,输入0。在系统组 ID 中,输入0。这将允许您的 Lambda 函数以根用户身份运行。有关以根用户身份运行的更多信息,请参阅 为组中的 Lambda 函数设置默认访问身份。
提示
您还必须更新
config.json文件,从而能够为 Lambda 函数授予根用户访问权限。有关此步骤,请参阅 以根用户身份运行 Lambda 函数。 -
对于 Lambda 函数容器化,请选择无容器。
有关不进行容器化的情况下运行的更多信息,请参阅 选择 Lambda 函数容器化时的注意事项。
-
在其他参数下,在对 sys 目录的只读权限中选择启用。
-
在 环境变量下,将以下键/值对添加到 Lambda 函数。这将配置 AWS IoT Greengrass 为使用 MXNet 框架。
键
值
路径
/usr/local/cuda/bin: $PATH
MXNET_HOME
$HOME/mxnet/
PYTHONPATH
$MXNET_HOME/python:$PYTHONPATH
CUDA_HOME
/usr/local/cuda
LD_LIBRARY_PATH
$LD_LIBRARY_PATH:${CUDA_HOME}/lib64
-
-
改为在容器化模式下运行:
注意
我们不建议以容器化模式运行,除非您的业务案例需要这样做。
-
提高内存限制值。使用 500 MB(对于 CPU)或至少使用 2000 MB(对于 GPU)。
-
在其他参数下,在对 sys 目录的只读权限中选择启用。
-
在 环境变量下,将以下键/值对添加到 Lambda 函数。这将配置 AWS IoT Greengrass 为使用 MXNet 框架。
键
值
路径
/usr/local/cuda/bin: $PATH
MXNET_HOME
$HOME/mxnet/
PYTHONPATH
$MXNET_HOME/python:$PYTHONPATH
CUDA_HOME
/usr/local/cuda
LD_LIBRARY_PATH
$LD_LIBRARY_PATH:${CUDA_HOME}/lib64
-
-
-
如果在容器化模式下运行,请添加以下本地设备资源以授予对设备 GPU 的访问权限。按照步骤 6:将资源添加到 Greengrass 组中的程序操作。
注意
如果您在非容器化模式下运行,则无需配置设备 AWS IoT Greengrass 资源即可访问您的设备 GPU。
对于每个资源:
-
对于 Resource type (资源类型),选择 Device (设备)。
-
在 系统组所有者和文件访问权限 下,选择 自动添加拥有资源的系统组的文件系统权限。
名称
设备路径
nvhost-ctrl
/dev/nvhost-ctrl
nvhost-gpu
/dev/nvhost-gpu
nvhost-ctrl-gpu
/dev/ nvhost-ctrl-gpu
nvhost-dbg-gpu
/dev/ nvhost-dbg-gpu
nvhost-prof-gpu
/dev/ nvhost-prof-gpu
nvmap
/dev/nvmap
nvhost-vic
/dev/nvhost-vic
tegra_dc_ctrl
/dev/tegra_dc_ctrl
-
-
如果在容器化模式下运行,请添加以下本地卷资源以授予对设备摄像头的访问权限。按照步骤 6:将资源添加到 Greengrass 组中的程序操作。
注意
如果您在非容器化模式下运行,则无需配置音量资源 AWS IoT Greengrass 即可访问设备摄像头。
-
对于资源类型,选择卷。
-
在 系统组所有者和文件访问权限 下,选择 自动添加拥有资源的系统组的文件系统权限。
名称
源路径
目的地路径
shm
/dev/shm
/dev/shm
tmp
/tmp
/tmp
-
