本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Amazon CloudWatch 監控 OpenSearch 叢集指標
Amazon OpenSearch Service 將資料從您的網域發佈到 Amazon CloudWatch。CloudWatch 可讓您擷取這些資料點的相關統計數字作為一組排序時間序列資料,也就是指標。OpenSearch Service 會以 60 秒的間隔將大多數指標傳送至 CloudWatch。如果您使用一般用途或磁帶 EBS 磁碟區,EBS 磁碟區指標將僅每隔 5 分鐘更新一次。所有累積指標 (例如 ThreadpoolWriteRejected、ThreadpoolSearchRejected) 都是記憶體內,且將會失去狀態。指標會在節點捨棄、節點退信、節點取代和藍/綠部署期間重設。如需 Amazon CloudWatch 的詳細資訊,請參閱《Amazon CloudWatch 使用者指南》。
OpenSearch Service 主控台會根據 CloudWatch 的原始資料顯示一系列圖形。根據需求,您可能偏好在 CloudWatch 中檢視叢集資料,而非在主控台中檢視圖形。此服務會封存指標兩週,之後才會捨棄它們。這些指標為免費提供,無須額外付費,但 CloudWatch 仍會針對建立儀表板和警示收費。如需詳細資訊,請參閱 Amazon CloudWatch 定價
OpenSearch Service 會將以下指標發佈至 CloudWatch:
在 CloudWatch 中檢視指標
首先依服務命名空間對 CloudWatch 指標分組,然後再依各命名空間內不同的維度組合分組。
使用 CloudWatch 主控台檢視指標
-
在 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 -
在左側導覽窗格中,尋找 Metrics (指標),然後選擇 All metrics (所有指標)。選取 ES/OpenSearchService 命名空間。
-
選擇維度以檢視對應指標。個別節點的指標位於
ClientId, DomainName, NodeId維度中。叢集指標位於Per-Domain, Per-Client Metrics維度中。某些節點指標會在叢集層級彙總,因此包含在這兩個維度中。碎片指標位於ClientId, DomainName, NodeId, ShardRole維度中。
使用 檢視指標清單 AWS CLI
執行以下命令:
aws cloudwatch list-metrics --namespace "AWS/ES"
解讀 OpenSearch Service 中的運作狀態圖表
若要檢視 OpenSearch Service 中的指標,請使用 Cluster health (叢集運作狀態) 和 Instance health (執行個體運作狀態) 索引標籤。Instance health (執行個體運作狀態) 索引標籤使用方塊圖,可快速查看每個 OpenSearch 節點的運作狀態:
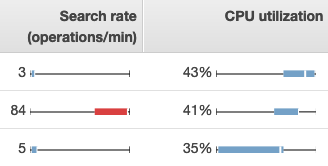
-
每個色彩方塊都能顯示該節點在整段指定時間的值範圍。
-
藍色方塊表示其值與其他節點相符。紅色方塊表示其值出現異常。
-
每個方塊中的白色線條則表示目前節點的值。
-
每個方塊在任何一邊上的「whiskers」則表示所有節點在整段時間的最小值與最大值。
如果您對網域進行組態變更,則 Cluster health (叢集運作狀態) 和 Instance health (執行個體運作狀態) 索引標籤上個別執行個體清單的大小通常會短暫出現加倍的情況,然後才恢復為正確的數字。如需此行為的說明,請參閱在 Amazon OpenSearch Service 中進行組態變更。
叢集指標
Amazon OpenSearch Service 提供下列叢集指標。
| 指標 | 描述 |
|---|---|
ClusterStatus.green |
1 的值表示將所有索引碎片分配至叢集中的節點。 相關統計資訊:Maximum |
ClusterStatus.yellow |
1 的值表示將所有索引的主要碎片分配給叢集中的節點,但用於至少一個索引的複寫碎片則不分配。如需詳細資訊,請參閱黃色叢集狀態。 相關統計資訊:Maximum |
ClusterStatus.red |
1 的值表示至少一個索引的主要碎片和複寫碎片未分配至叢集中的節點。如需詳細資訊,請參閱紅色叢集狀態。 相關統計資訊:Maximum |
Shards.active |
作用中主要碎片和複本碎片的總數。 相關統計數字:最大,總和 |
Shards.unassigned |
未分配至叢集中節點的碎片數目。 相關統計數字:最大,總和 |
Shards.delayedUnassigned |
其節點分配已被逾時設定延遲的碎片數量。 相關統計數字:最大,總和 |
Shards.activePrimary |
活動中主要碎片的數量。 相關統計數字:最大,總和 |
Shards.initializing |
正在初始化的碎片數量。 相關統計資料:總和 |
Shards.relocating |
正在重新放置的碎片數量。 相關統計資料:總和 |
Nodes |
OpenSearch Service 叢集中的節點數,包括專用主節點和 UltraWarm 節點。如需詳細資訊,請參閱在 Amazon OpenSearch Service 中進行組態變更。 相關統計資訊:Maximum |
SearchableDocuments |
叢集中跨所有資料節點的可搜尋文件的總數。 相關統計資料:下限、上限、平均數 |
DeletedDocuments |
叢集中跨所有資料節點的標記進行刪除文件的總數。這些文件不再出現於搜尋結果中,但 OpenSearch 在區段合併時只會從磁碟移除已刪除的文件。此指標會在刪除請求後增加,在區段合併後降低。 相關統計資料:下限、上限、平均數 |
CPUUtilization |
叢集中資料節點的 CPU 用量百分比。上限顯示具有最高 CPU 用量的節點。平均值代表叢集中的所有節點。此指標也適用於個別節點。 相關統計資訊:Maximum、Average |
FreeStorageSpace |
叢集中資料節點的可用空間。 OpenSearch Service 主控台會以 GiB 為單位顯示此值。Amazon CloudWatch 主控台會以 MiB 為單位顯示它。 注意
相關統計資訊:Minimum、Maximum、Average、Sum |
ClusterUsedSpace |
已用於叢集的空間總數。您必須保留一分鐘的間隔,才能取得正確的數值。 OpenSearch Service 主控台會以 GiB 為單位顯示此值。Amazon CloudWatch 主控台會以 MiB 為單位顯示它。 相關統計資訊:Minimum、Maximum |
ClusterIndexWritesBlocked |
指示您的叢集是否要接受或封鎖外來的寫入請求。0 值表示叢集接受請求。1 值表示叢集封鎖請求。 常見的因素包括: 相關統計資訊:Maximum |
JVMMemoryPressure |
用於叢集中所有資料節點的 Java heap 的最大百分比。OpenSearch Service 針對 Java 堆積使用執行個體 RAM 的一半,堆積大小最多可達 32 GiB。您可以垂直擴展執行個體高達 64 GiB 的 RAM,屆時便能透過新增執行個體進行水平擴展。請參閱 Amazon OpenSearch Service 的建議 CloudWatch 警示。 相關統計資訊:Maximum 注意此指標的邏輯在服務軟體 R20220323 中有所變更。如需詳細資訊,請參閱版本備註。 |
OldGenJVMMemoryPressure |
用於叢集中所有資料節點的「舊一代」的 Java 堆積的最大百分比。此指標也適用於節點層級。 相關統計資訊:Maximum |
AutomatedSnapshotFailure |
叢集中失敗的自動快照數量。 相關統計資訊:Minimum、Maximum |
CPUCreditBalance |
可供叢集中資料節點使用的剩餘 CPU 點數。一個 CPU 點數提供一分鐘、一個 CPU 核心的完整效能。如需詳細資訊,請參閱 Amazon EC2 開發人員指南中的 CPU 點數。此指標僅適用於 T2 執行個體類型。 相關統計資訊:Minimum |
OpenSearchDashboardsHealthyNodes |
OpenSearch Dashboards 的運作狀態檢查。如果最小值、最大值和平均值都等於 1,則 Dashboards 的行為正常。如果您有 10 個節點,其中最大為 1,最小為 0,平均為 0.7,這表示 7 個節點 (70%) 狀況良好,3 個節點 (30%) 狀況不良。 相關統計資料:下限、上限、平均數 |
OpensearchDashboardsReportingFailedRequestSysErrCount |
因伺服器問題或功能限制而失敗的產生 OpenSearch Dashboards 報告的請求數。 相關統計資料:總和 |
OpensearchDashboardsReportingFailedRequestUserErrCount |
因用戶端問題而失敗的產生 OpenSearch Dashboards 報告的請求數。 相關統計資料:總和 |
OpensearchDashboardsReportingRequestCount |
產生 OpenSearch Dashboards 報告的請求總數。 相關統計資料:總和 |
OpensearchDashboardsReportingSuccessCount |
產生 OpenSearch Dashboards 報告的成功請求數。 相關統計資料:總和 |
KMSKeyError |
值 1 表示用來加密靜態資料的 AWS KMS 金鑰已停用。若要使網域恢復正常運作,請重新啟用此金鑰。主控台只會針對加密靜態資料的網域顯示此指標。 相關統計資訊:Minimum、Maximum |
KMSKeyInaccessible |
值 1 表示用來加密靜態資料的 AWS KMS 金鑰已刪除或撤銷其對 OpenSearch Service 的授予。您無法復原此狀態的網域。但是,如果您有手動快照,您可以用它來將網域的資料遷移至新的網域。主控台只會針對加密靜態資料的網域顯示此指標。 相關統計資訊:Minimum、Maximum |
InvalidHostHeaderRequests |
對 OpenSearch 叢集發出的 HTTP 請求數,請求中包括無效 (或遺漏) 主機標頭。有效的請求包括網域主機名稱作為主機標頭值。OpenSearch Service 會拒絕沒有限制性存取政策的公有存取網域的無效請求。我們建議將限制存取政策套用到所有網域。 如果您看見此指標有較大值,請確認 OpenSearch 用戶端在其請求中包含網域主機名稱 (而非其 IP 地址)。 相關統計資料:總和 |
OpenSearchRequests (previously
ElasticsearchRequests) |
對 OpenSearch 叢集發出的請求數。 相關統計資料:總和 |
2xx, 3xx, 4xx, 5xx |
產生指定 HTTP 回應碼 (2xx、3xx、4xx、5xx) 的網域請求數。 相關統計資料:總和 |
ThroughputThrottle |
指出磁碟是否已調節。當 如需執行個體輸送量的資訊,請參閱 Amazon EBS 最佳化執行個體。如需磁碟區輸送量的資訊,請參閱 Amazon EBS 磁碟區類型 相關統計資訊:Minimum、Maximum |
IopsThrottle |
指出是否已調節網域上的每秒輸入/輸出操作數 (IOPS)。當資料節點的 IOPS 超過 EBS 磁碟區或資料節點的 EC2 執行個體允許的上限時,就會發生限流。 如需執行個體 IOPS 的資訊,請參閱 Amazon EBS 最佳化執行個體。如需磁碟區 IOPS 的資訊,請參閱 Amazon EBS 磁碟區類型 相關統計資訊:Minimum、Maximum |
HighSwapUsage |
值 1 表示由於頁面故障而交換可能會導致特定期間內基礎磁碟使用量激增。 相關統計資訊:Maximum |
專用主節點指標
Amazon OpenSearch Service 提供下列專用主節點指標。
| 指標 | 描述 |
|---|---|
MasterCPUUtilization |
專用主節點使用的 CPU 資源的最大百分比。當這項指標達到 60% 時,建議提高執行個體類型的大小。 相關統計資訊:Maximum |
MasterFreeStorageSpace |
此指標無關,可忽略。此服務不使用主節點做為資料節點。 |
MasterJVMMemoryPressure |
用於叢集中所有專用主節點的 Java heap 的最大百分比。當這項指標達到 85% 時,建議移至較大的執行個體類型。 相關統計資訊:Maximum 注意此指標的邏輯在服務軟體 R20220323 中有所變更。如需詳細資訊,請參閱版本備註。 |
MasterOldGenJVMMemoryPressure |
用於每個主節點「舊一代」的 Java 堆積最大百分比。 相關統計資訊:Maximum |
MasterCPUCreditBalance |
可供叢集中專用主節點使用的剩餘 CPU 額度。一個 CPU 點數提供一分鐘、一個 CPU 核心的完整效能。如需詳細資訊,請參閱 Amazon EC2 開發人員指南中的 CPU 點數。此指標僅適用於 T2 執行個體類型。 相關統計資訊:Minimum |
MasterReachableFromNode |
失敗表示無法從來源節點連線主節點。通常是網路連線問題或 AWS 相依性問題的結果。 相關統計資訊:Maximum |
MasterSysMemoryUtilization |
已使用主節點記憶體的百分比。 相關統計資訊:Maximum |
專用協調器節點指標
Amazon OpenSearch Service 為專用協調器節點提供下列指標。
| 指標 | 描述 |
|---|---|
CoordinatorCPUUtilization |
專用協調器節點使用的 CPU 資源百分比上限。我們建議在此指標達到 80% 時,增加執行個體類型的大小。 相關統計資訊:Maximum |
CoordinatorJVMMemoryPressure |
用於叢集中所有專用協調器節點的 Java 堆積百分比上限。當這項指標達到 85% 時,建議移至較大的執行個體類型。 相關統計資訊:Maximum |
CoordinatorOldGenJVMMemoryPressure |
用於每個主節點「舊一代」的 Java 堆積最大百分比。 相關統計資訊:Maximum |
CoordinatorSysMemoryUtilization |
使用中的協調器節點記憶體百分比。 相關統計資訊:Maximum |
CoordinatorFreeStorageSpace |
此指標表示服務不使用協調器節點做為資料節點。 |
EBS 磁碟區指標
Amazon OpenSearch Service 提供下列 EBS 磁碟區指標。
| 指標 | 描述 |
|---|---|
ReadLatency |
EBS 磁碟區讀取操作的延遲 (以秒為單位)。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
WriteLatency |
EBS 磁碟區寫入操作的延遲 (以秒為單位)。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
ReadThroughput |
EBS 磁碟區讀取操作的傳輸量 (以位元組/秒為單位)。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
ReadThroughputMicroBursting |
考量微爆量 相關統計資料:下限、上限、平均數 |
WriteThroughput |
EBS 磁碟區寫入操作的傳輸量 (以位元組/秒為單位)。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
WriteThroughputMicroBursting |
考量微爆量 相關統計資料:下限、上限、平均數 |
DiskQueueDepth |
等待中的 EBS 磁碟區輸入與輸出 (I/O) 請求數。 相關統計資料:下限、上限、平均數 |
ReadIOPS |
EBS 磁碟區讀取操作的每秒輸入與輸出 (I/O) 操作數。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
ReadIOPSMicroBursting |
考量微爆量 相關統計資料:下限、上限、平均數 |
WriteIOPS |
EBS 磁碟區寫入操作的每秒輸入與輸出 (I/O) 操作數。此指標也適用於個別節點。 相關統計資料:下限、上限、平均數 |
WriteIOPSMicroBursting |
考量微爆量時,EBS 磁碟區上每秒寫入操作 相關統計資料:下限、上限、平均數 |
BurstBalance |
EBS 磁碟區的爆量儲存貯體中剩餘的輸入與輸出 (I/O) 點數百分比。值 100 表示磁碟區已累積至最大點數。如果此百分比低於 70%,請參閱 低 EBS 爆量餘額。對於具有 gp3 磁碟區類型的網域,以及具有磁碟區大小高於 1000 GiB 之 gp2 磁碟區的網域,爆量餘額會保持在 0。 相關統計資料:下限、上限、平均數 |
VolumeStalledIOcheck |
EBS 磁碟區的狀態,以判斷何時受損。指標是二進位值,根據 EBS 磁碟區是否可以完成輸入和輸出操作,傳回 0 (通過) 或 1 (失敗) 狀態。 相關統計資料:下限、上限、平均數 |
執行個體指標
Amazon OpenSearch Service 提供網域中每個執行個體的下列指標。OpenSearch Service 也彙總這些執行個體指標,讓您深入了解整體叢集運作狀態。您可以在主控台使用 Sample Count (取樣計數) 統計數字來驗證此行為。請注意,下表中每個指標有節點和叢集的相關統計資料。
重要
在處理 _index API 的呼叫時,不同版本的 Elasticsearch 會使用不同的執行緒集區。Elasticsearch 1.5 和 2.3 版會使用索引執行緒集區。Elasticsearch 5.x、6.0 和 6.2 版會使用大量執行緒集區。OpenSearch 和 Elasticsearch 6.3 及較新版本會使用寫入執行緒集區。目前,OpenSearch Service 主控台不包含大量執行緒集區的圖形。
使用 GET _cluster/settings?include_defaults=true 來檢查叢集的執行緒集區和佇列大小。
| 指標 | 描述 |
|---|---|
FetchLatency |
節點中所有碎片擷取操作在分鐘 N 和分鐘 (N - 1) 之間的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
FetchRate |
資料節點上所有碎片的每分鐘碎片擷取操作總數。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限、總和 |
ScrollTotal |
資料節點上所有碎片的每分鐘碎片捲動操作總數。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 |
ScrollCurrent |
目前正在執行的碎片捲動操作數目。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 |
OpenContexts |
開放搜尋內容的數量。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 |
ThreadCount |
OpenSearch 程序目前正在使用的執行緒總數。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 |
ShardReactivateCount |
從閒置狀態啟動所有碎片的總次數。 相關節點統計資料:總和、最大值 相關叢集統計資料:總和、最大值 |
ConcurrentSearchRate |
資料節點上所有碎片每分鐘使用並行區段搜尋的搜尋請求總數。對於 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限、總和 |
ConcurrentSearchLatency |
在分鐘 N 和分鐘 (N-1) 之間的節點中使用並行區段搜尋的所有搜尋所取得的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
IndexingLatency |
節點中所有索引操作在分鐘 N 和分鐘 (N-1) 之間的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
IndexingRate |
每分鐘進行的索引操作次數。對於 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限、總和 |
SearchLatency |
節點中介於分鐘 N 和分鐘 (N-1) 之間的所有搜尋所取得的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
SearchRate |
資料節點上每分鐘對所有碎片發出搜尋請求的總次數。對於 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限、總和 |
SegmentCount |
資料節點上的區段數。您擁有的區段越多,每個搜尋所需的時間越長。OpenSearch 偶爾會將較小的區段合併成較大的區段。 相關節點統計數字:最大,平均 相關叢集統計資訊:總和、上限、平均數 |
SysMemoryUtilization |
已使用執行個體記憶體的百分比。此測量結果的高值是正常的,通常不代表叢集的問題。如需有關潛在效能和穩定性問題的更佳指標,請參閱 相關節點統計資訊:下限、上限、平均數 相關叢集統計資訊:下限、上限、平均數 |
JVMGCYoungCollectionCount |
「新一代」廢棄項目收集的已執行次數。大量、持續擴增的執行次數是叢集操作的正常情況。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
JVMGCYoungCollectionTime |
叢集已執行「新一代」廢棄項目收集的時間 (單位為毫秒)。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
JVMGCOldCollectionCount |
「舊一代」廢棄項目收集的已執行次數。在資源充足的叢集中,這個數字應該很小,而且不常擴增。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
JVMGCOldCollectionTime |
叢集已花在執行「舊一代」廢棄項目收集的時間 (單位為毫秒)。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
OpenSearchDashboardsConcurrentConnections |
OpenSearch Dashboards 的作用中並行連線的數目。如果此數值持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
OpenSearchDashboardsHealthyNode |
個別 OpenSearch Dashboards 節點的運作狀態檢查。1 值表示正常行為。0 值表示無法存取 Dashboards。 相關節點統計數字:最小 相關叢集統計資訊:下限、上限、平均數 |
OpenSearchDashboardsHeapTotal |
分配給 OpenSearch Dashboards 的堆積記憶體容量 (單位為 MiB)。不同的 EC2 執行個體類型可能會影響精確的記憶體分配。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
OpenSearchDashboardsHeapUsed |
OpenSearch Dashboards 使用的堆積記憶體的絕對容量 (單位為 MiB)。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
OpenSearchDashboardsHeapUtilization |
OpenSearch Dashboards 使用的可用堆積記憶體的最大百分比。如果此值超過 80%,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:下限、上限、平均數 |
OpenSearchDashboardsOS1MinuteLoad |
OpenSearch Dashboards 的一分鐘平均 CPU 負載。CPU 負載理想情況下應該保持在 1.00 以下。雖然暫時峰值沒問題,但如果此指標一致高於 1.00,建議您增加執行個體類型的大小。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
OpenSearchDashboardsRequestTotal |
對 OpenSearch Dashboards 發出的 HTTP 請求總數。如果您的系統速度緩慢或您看到大量 Dashboards 請求,請考慮增加執行個體類型的大小。 相關節點統計數字:總和 相關叢集統計資訊:總和 |
OpenSearchDashboardsResponseTimesMaxInMillis |
OpenSearch Dashboards 回應請求所需的時間上限,單位為毫秒。如果請求持續需要很長的時間才能傳回結果,請考慮增加執行個體類型的大小。 相關節點統計資訊:上限 相關叢集統計數字:最大,平均 |
SearchTaskCancelled |
取消協調器節點的數量。 相關節點統計數字:總和 相關叢集統計資訊:總和 |
SearchShardTaskCancelled |
資料節點取消的數量。 相關節點統計數字:總和 相關叢集統計資料:總和、 |
ThreadpoolForce_mergeQueue |
強制合併執行緒集區中的已排入佇列任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
ThreadpoolForce_mergeRejected |
強制合併執行緒集區中的已拒絕任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
ThreadpoolForce_mergeThreads |
強制合併執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolIndexQueue |
索引執行緒集區中的已排入佇列任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。索引佇列的大小上限為 200。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
ThreadpoolIndexRejected |
索引執行緒集區中的已拒絕任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
ThreadpoolIndexThreads |
索引執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolSearchQueue |
搜尋執行緒集區中的已排入佇列任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。搜尋佇列的大小上限為 1,000。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
ThreadpoolSearchRejected |
搜尋執行緒集區中的已拒絕任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
ThreadpoolSearchThreads |
搜尋執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
Threadpoolsql-workerQueue |
SQL 搜尋執行緒集區中的已排入佇列的任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
Threadpoolsql-workerRejected |
SQL 搜尋執行緒集區中的已拒絕的任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
Threadpoolsql-workerThreads |
SQL 搜尋執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolBulkQueue |
大量執行緒集區中的已排入佇列任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
ThreadpoolBulkRejected |
大量執行緒集區中的已拒絕任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
ThreadpoolBulkThreads |
大量執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolIndexSearcherQueue |
索引搜尋器執行緒集區中的佇列任務數目。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
ThreadpoolIndexSearcherRejected |
索引搜尋器執行緒集區中遭拒的任務數量。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
ThreadpoolIndexSearcherThreads |
索引搜尋器執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolWriteThreads |
寫入執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolWriteQueue |
寫入執行緒集區中的已排入佇列任務數量。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
ThreadpoolWriteRejected |
寫入執行緒集區中的已拒絕任務數量。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 注意由於 7.1 版中的預設寫入佇列大小從 200 增加到 10000,這個指標不再是 OpenSearch Service 拒絕的唯一指標。使用 |
CoordinatingWriteRejected |
自上次 OpenSearch Service 處理程序啟動後,協調節點上由於索引壓力而發生的拒絕總數。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 在 7.1 版及更高版本中可使用此指標。 |
PrimaryWriteRejected |
自上次 OpenSearch Service 處理程序啟動後,主碎片上由於索引壓力而發生的拒絕總數。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 在 7.1 版及更高版本中可使用此指標。 |
ReplicaWriteRejected |
自上次 OpenSearch Service 處理程序啟動後,複本碎片上由於索引壓力而發生的拒絕總數。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 在 7.1 版及更高版本中可使用此指標。 |
WorkloadManagementEnabled |
指出工作負載管理功能是否已啟用。值 1 表示已啟用,值 0 表示其 相關節點統計資料:最大值、最小值 相關叢集統計資訊:平均數、總和 在 7.1 版及更高版本中可使用此指標。 |
SoftQueryGroupCount |
網域中處於軟模式的查詢群組數量。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 在 7.1 版及更高版本中可使用此指標。 |
EnforcedQueryGroupCount |
網域中強制執行模式下的查詢群組數目。 相關節點統計資料:平均值、最大值 相關叢集統計資訊:平均數、上限、總和 在 7.1 版及更高版本中可使用此指標。 |
UltraWarm 指標
Amazon OpenSearch Service 提供下列 UltraWarm 節點指標。
| 指標 | 描述 |
|---|---|
WarmCPUUtilization |
叢集中 UltraWarm 節點的 CPU 用量百分比。上限顯示具有最高 CPU 用量的節點。平均值代表叢集中的所有 UltraWarm 節點。此指標也適用於個別 UltraWarm 節點。 相關統計資訊:Maximum、Average |
WarmFreeStorageSpace |
可用暖儲存空間量 (以 MiB 為單位)。由於 UltraWarm 使用 Simple Storage Service (Amazon S3) 而不是連接的磁碟, 相關統計資料:總和 |
WarmSearchableDocuments |
叢集中跨所有暖索引的可搜尋文件的總數。您必須保留一分鐘的間隔,才能取得正確的數值。 相關統計資料:總和 |
WarmSearchLatency
|
UltraWarm 中所有搜尋在分鐘 N 和分鐘 (N-1) 之間的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限 |
WarmSearchRate
|
UltraWarm 節點上每分鐘對所有碎片發出搜尋請求的總次數。對於 相關節點統計資訊:平均數 相關叢集統計資訊:平均數、上限、總和 |
WarmStorageSpaceUtilization |
叢集所使用暖儲存空間的總量 (單位為 MiB)。 相關統計資訊:Maximum |
HotStorageSpaceUtilization
|
叢集所使用熱儲存空間的總量。 相關統計資訊:Maximum |
WarmSysMemoryUtilization |
已使用溫節點記憶體的百分比。 相關統計資訊:Maximum |
HotToWarmMigrationQueueSize
|
目前等待從熱儲存遷移至暖儲存的索引數目。 相關統計資訊:Maximum |
WarmToHotMigrationQueueSize
|
目前等待從暖儲存遷移至熱儲存的索引數目。 相關統計資訊:Maximum |
HotToWarmMigrationFailureCount
|
從熱儲存遷移至暖儲存的失敗總數。 相關統計資料:總和 |
HotToWarmMigrationForceMergeLatency
|
遷移程序的強制合併階段的平均延遲。如果此階段始終需要太長時間,考慮增加 相關統計資訊:平均數 |
HotToWarmMigrationSnapshotLatency
|
遷移程序的快照階段的平均延遲。如果此階段持續需要太長時間,請確保您的碎片適當調整大小並分佈在整個叢集中。 相關統計資訊:平均數 |
HotToWarmMigrationProcessingLatency
|
從熱儲存成功遷移到暖儲存的平均延遲,不包括佇列中花費的時間。此值是完成遷移程序的強制合併、快照和碎片重新放置階段所需的時間總和。 相關統計資訊:平均數 |
HotToWarmMigrationSuccessCount
|
從熱儲存遷移至暖儲存的成功總數。 相關統計資料:總和 |
HotToWarmMigrationSuccessLatency
|
從熱儲存成功遷移到暖儲存的平均延遲,包括佇列中花費的時間。 相關統計資訊:平均數 |
WarmThreadpoolSearchThreads |
UltraWarm 搜尋執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資訊:平均數、總和 |
WarmThreadpoolSearchRejected |
UltraWarm 搜尋執行緒集區中已拒絕的任務數量。如果此數值持續增加,請考慮新增更多 UltraWarm 節點。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
WarmThreadpoolSearchQueue |
UltraWarm 搜尋執行緒集區中已排入佇列的任務數量。如果佇列大小持續高居不下,請考慮新增更多的 UltraWarm 節點。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
WarmJVMMemoryPressure |
用於 UltraWarm 節點的 Java 堆積最大百分比。 相關統計資訊:Maximum 注意此指標的邏輯在服務軟體 R20220323 中有所變更。如需詳細資訊,請參閱版本備註。 |
WarmOldGenJVMMemoryPressure |
用於 UltraWarm 節點「舊一代」的 Java 堆積最大百分比。 相關統計資訊:Maximum |
WarmJVMGCYoungCollectionCount |
「新一代」廢棄項目收集在 UltraWarm 節點上執行的次數。大量、持續擴增的執行次數是叢集操作的正常情況。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
WarmJVMGCYoungCollectionTime |
叢集在 UltraWarm 節點上執行「新一代」廢棄項目收集花費的時間 (單位為毫秒)。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
WarmJVMGCOldCollectionCount |
「舊一代」廢棄項目收集在 UltraWarm 節點上執行的次數。在資源充足的叢集中,這個數字應該很小,而且不常擴增。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
WarmConcurrentSearchRate |
UltraWarm 節點上所有碎片每分鐘使用並行區段搜尋的搜尋請求總數。對於 相關節點統計資訊:平均數 相關叢集統計資訊:總和、上限、平均數 |
WarmConcurrentSearchLatency |
在分鐘 N 和分鐘 (N-1) 之間的 UltraWarm 節點中使用並行區段搜尋的所有搜尋所取得的總時間差異,以毫秒為單位。 相關節點統計資訊:平均數 相關叢集統計數字:最大,平均 |
WarmThreadpoolIndexSearcherQueue |
UltraWarm 索引搜尋器執行緒集區中的佇列任務數量。 相關節點統計資訊:上限 相關叢集統計資訊:總和、上限、平均數 |
WarmThreadpoolIndexSearcherRejected |
UltraWarm 索引搜尋器執行緒集區中遭拒的任務數量。 相關節點統計資訊:上限 相關叢集統計資訊:總和 |
WarmThreadpoolIndexSearcherThreads |
UltraWarm 索引搜尋器執行緒集區的大小。 相關節點統計資訊:上限 相關叢集統計資料:總和、平均 |
冷儲存指標
Amazon OpenSearch Service 提供下列冷儲存指標。
| 指標 | 描述 |
|---|---|
ColdStorageSpaceUtilization
|
叢集所使用冷儲存空間的總量 (單位為 MiB)。 相關統計資料:上限 |
ColdToWarmMigrationFailureCount |
從冷儲存遷移至暖儲存的失敗總數。 相關統計資料:總和 |
ColdToWarmMigrationLatency |
成功完成從冷儲存遷移至暖儲存所需的時間量。 相關統計資訊:平均數 |
ColdToWarmMigrationQueueSize |
目前等待從冷儲存遷移至暖儲存的索引數目。 相關統計資訊:Maximum |
ColdToWarmMigrationSuccessCount
|
從冷儲存遷移至暖儲存的成功總數。 相關統計資料:總和 |
WarmToColdMigrationFailureCount
|
從暖儲存遷移至冷儲存的失敗總數。 相關統計資料:總和 |
WarmToColdMigrationLatency |
成功完成從暖儲存遷移至冷儲存所需的時間量。 相關統計資訊:平均數 |
WarmToColdMigrationQueueSize |
目前等待從暖儲存遷移至冷儲存的索引數目。 相關統計資訊:Maximum |
WarmToColdMigrationSuccessCount |
從暖儲存遷移至冷儲存的成功總數。 相關統計資料:總和 |
OR1 指標
Amazon OpenSearch Service 為 OR1 執行個體提供下列指標。
| 指標 | 描述 |
|---|---|
RemoteStorageUsedSpace
|
叢集正在使用的 Amazon S3 空間總量,以 MiB 為單位。 相關統計資料:總和 |
RemoteStorageWriteRejected |
主要碎片因遠端儲存和複寫壓力而拒絕的請求總數。這是從上次 OpenSearch Service 程序啟動開始計算的。 相關統計資料:總和 |
ReplicationLagMaxTime |
複本碎片落後於主要碎片的時間量,以毫秒為單位。 相關統計資訊:Maximum |
提醒指標
Amazon OpenSearch Service 提供下列提醒指標。
| 指標 | 描述 |
|---|---|
AlertingDegraded |
值為 1 表示提醒索引為紅色,或是有一或多個節點不在排程上。0 值表示正常行為。 相關統計資訊:Maximum |
AlertingIndexExists |
值為 1 表示存在 相關統計資訊:Maximum |
AlertingIndexStatus.green |
索引的運作狀態。值為 1 表示綠色。值為 0 表示索引不存在,或是並非綠色。 相關統計資訊:Maximum |
AlertingIndexStatus.red |
索引的運作狀態。值為 1 表示紅色。值為 0 表示索引不存在,或是並非紅色。 相關統計資訊:Maximum |
AlertingIndexStatus.yellow |
索引的運作狀態。值為 1 表示黃色。值為 0 表示索引不存在,或是並非黃色。 相關統計資訊:Maximum |
AlertingNodesNotOnSchedule |
值為 1 表示有些任務並未依照排程執行。值為 0 則表示所有提醒任務都正在依照排程執行 (或是沒有提醒任務)。檢查 OpenSearch Service 主控台或提出 相關統計資訊:Maximum |
AlertingNodesOnSchedule |
值為 1 則表示所有提醒任務都正在依照排程執行 (或是沒有提醒任務)。值為 0 表示有些任務並未依照排程執行。 相關統計資訊:Maximum |
AlertingScheduledJobEnabled |
值為 1 表示 相關統計資訊:Maximum |
異常偵測指標
Amazon OpenSearch Service 提供下列異常偵測指標。
| 指標 | 描述 |
|---|---|
ADPluginUnhealthy |
值 1 表示異常偵測外掛程式無法正常運作,原因是大量失敗或它使用的其中一個索引是紅色。值 0 表示外掛程式如預期般運作。 相關統計資訊:Maximum |
ADExecuteRequestCount |
偵測異常的請求數。 相關統計資料:總和 |
ADExecuteFailureCount
|
偵測異常的失敗請求數。 相關統計資料:總和 |
ADHCExecuteFailureCount |
偵測高基數偵測器異常的失敗請求數。 相關統計資料:總和 |
ADHCExecuteRequestCount |
偵測高基數偵測器異常的請求數。 相關統計資料:總和 |
ADAnomalyResultsIndexStatusIndexExists |
值為 1 表示 相關統計資訊:Maximum |
ADAnomalyResultsIndexStatus.red |
值為 1 表示 相關統計資訊:Maximum |
ADAnomalyDetectorsIndexStatusIndexExists |
值為 1 表示 相關統計資訊:Maximum |
ADAnomalyDetectorsIndexStatus.red |
值為 1 表示 相關統計資訊:Maximum |
ADModelsCheckpointIndexStatusIndexExists |
值為 1 表示 相關統計資訊:Maximum |
ADModelsCheckpointIndexStatus.red |
值為 1 表示 相關統計資訊:Maximum |
非同步搜尋指標
Amazon OpenSearch Service 提供下列非同步搜尋指標。
非同步搜尋協調器節點統計數字 (每個協調器節點)
| 指標 | 描述 |
|---|---|
AsynchronousSearchSubmissionRate |
過去一分鐘內提交的非同步搜尋數量。 |
AsynchronousSearchInitializedRate |
過去一分鐘內初始化的非同步搜尋數量。 |
AsynchronousSearchRunningCurrent |
目前正在執行的非同步搜尋數量。 |
AsynchronousSearchCompletionRate |
過去一分鐘內成功完成的非同步搜尋數量。 |
AsynchronousSearchFailureRate |
過去一分鐘內完成和失敗的非同步搜尋數量。 |
AsynchronousSearchPersistRate |
過去一分鐘內持續的非同步搜尋數量。 |
AsynchronousSearchPersistFailedRate |
過去一分鐘內無法持續的非同步搜尋數量。 |
AsynchronousSearchRejected |
自節點啟動時間以來拒絕的非同步搜尋總數。 |
AsynchronousSearchCancelled |
自節點啟動時間以來已取消的非同步搜尋總數。 |
AsynchronousSearchMaxRunningTime |
在最後一分鐘的節點上執行非同步搜尋的最長持續時間。 |
非同步搜尋叢集統計數字
| 指標 | 描述 |
|---|---|
AsynchronousSearchStoreHealth |
最後一分鐘內持續索引中的存放運作狀態 (紅色/非紅色)。 |
AsynchronousSearchStoreSize |
過去一分鐘內所有碎片的系統索引大小。 |
AsynchronousSearchStoredResponseCount |
過去一分鐘內系統索引中存放的回應數量。 |
自動調整指標
Amazon OpenSearch Service 為 Auto-Tune 提供下列指標。
| 指標 | 描述 |
|---|---|
AutoTuneChangesHistoryHeapSize |
MiB 中堆積大小調校值的變更歷史記錄。 |
AutoTuneChangesHistoryJVMYoungGenArgs |
JVM YongGen 引數的變更歷史記錄。 |
AutoTuneFailed |
指出自動調整變更是否失敗的布林值。 |
AutoTuneSucceeded |
布林值,指出自動調整變更是否成功。 |
AutoTuneValue |
佇列變更歷史記錄 (計數) 和快取會調校變更歷史記錄 (以 MiB 為單位) 是否有不中斷的變更。 |
具有待命指標的異地同步備份
Amazon OpenSearch Service 為具有待命的異地同步備份提供下列指標。
作用中可用區域中資料節點的節點層級指標
| 指標 | 描述 |
|---|---|
CPUUtilization |
叢集中資料節點的 CPU 用量百分比。上限顯示具有最高 CPU 用量的節點。平均值代表叢集中的所有節點。此指標也適用於個別節點。 |
FreeStorageSpace |
叢集中資料節點的可用空間。 OpenSearch Service 主控台會以 GiB 為單位顯示此值。Amazon CloudWatch 主控台會以 MiB 為單位顯示它。 |
JVMMemoryPressure |
用於叢集中所有資料節點的 Java heap 的最大百分比。OpenSearch Service 針對 Java 堆積使用執行個體 RAM 的一半,堆積大小最多可達 32 GiB。您可以垂直擴展執行個體高達 64 GiB 的 RAM,屆時便能透過新增執行個體進行水平擴展。請參閱 Amazon OpenSearch Service 的建議 CloudWatch 警示。 |
SysMemoryUtilization |
已使用執行個體記憶體的百分比。此測量結果的高值是正常的,通常不代表叢集的問題。如需有關潛在效能和穩定性問題的更佳指標,請參閱 JVMMemoryPressure 指標。 |
IndexingLatency |
節點中所有索引操作在分鐘 N 和分鐘 (N-1) 之間的總時間差異,以毫秒為單位。 |
IndexingRate |
每分鐘進行的索引操作次數。 |
SearchLatency |
節點中介於分鐘 N 和分鐘 (N-1) 之間的所有搜尋所取得的總時間差異,以毫秒為單位。 |
SearchRate |
資料節點上每分鐘對所有碎片發出搜尋請求的總次數。 |
ThreadpoolSearchQueue |
搜尋執行緒集區中的已排入佇列任務數量。如果佇列大小持續高居不下,請考慮擴展您的叢集。搜尋佇列的大小上限為 1,000。 |
ThreadpoolWriteQueue |
寫入執行緒集區中的已排入佇列任務數量。 |
ThreadpoolSearchRejected |
搜尋執行緒集區中的已拒絕任務數量。如果這個數量持續增加,請考慮擴展您的叢集。 |
ThreadpoolWriteRejected |
寫入執行緒集區中的已拒絕任務數量。 |
作用中可用區域中叢集的叢集層級指標
| 指標 | 描述 |
|---|---|
DataNodes |
作用中和待命碎片的總數。 |
DataNodesShards.active |
作用中主要碎片和複本碎片的總數。 |
DataNodesShards.unassigned |
未分配至叢集中節點的碎片數目。 |
DataNodesShards.initializing |
正在初始化的碎片數量。 |
DataNodesShards.relocating |
正在重新放置的碎片數量。 |
可用區域輪換指標
如果為 ActiveReads.,則區域為作用中。如果為 Availability-Zone = 1ActiveReads.,則區域處於待命狀態。Availability-Zone = 0
時間點指標
Amazon OpenSearch Service 為時間點 (PIT) 搜尋提供下列指標。
PIT 協調器節點統計資料 (每個協調器節點)
| 指標 | 描述 |
|---|---|
CurrentPointInTime |
節點中作用中 PIT 搜尋內容的數量。 |
TotalPointInTime |
節點啟動時間之後過期的 PIT 搜尋內容數目。 |
AvgPointInTimeAliveTime |
從節點啟動時間開始,PIT 搜尋內容的平均持續作用。 |
HasActivePointInTime |
值 1 表示自節點啟動時間以來,節點上有作用中的 PIT 內容。值為 0 表示沒有。 |
HasUsedPointInTime |
值 1 表示節點上自節點啟動時間以來有過期的 PIT 內容。值為 0 表示沒有。 |
SQL 指標
Amazon OpenSearch Service 提供下列 SQL 支援指標。
| 指標 | 描述 |
|---|---|
SQLFailedRequestCountByCusErr |
因用戶端問題而失敗的 相關統計資料:總和 |
SQLFailedRequestCountBySysErr |
因伺服器問題或功能限制而失敗的 相關統計資料:總和 |
SQLRequestCount |
向 相關統計資料:總和 |
SQLDefaultCursorRequestCount |
類似於 相關統計資料:總和 |
SQLUnhealthy |
值為 1 表示在特定請求的回應中,SQL 外掛程式正在傳回 5xx 回應碼,或是正在將無效的查詢 DSL 傳遞至 OpenSearch。其他請求應會繼續成功。值為 0 表示最近沒有任何失敗。如果您看到值持續為 1,請針對您用戶端向外掛程式提出的請求進行故障診斷。 相關統計資訊:Maximum |
k-NN 指標
Amazon OpenSearch Service 包含 k 近鄰 (k-NN) 外掛程式的下列指標。
| 指標 | 描述 |
|---|---|
KNNCacheCapacityReached |
是否已達到快取容量的每個節點指標。此指標僅與近似的 K-NN 搜尋相關。 相關統計資訊:Maximum |
KNNCircuitBreakerTriggered |
是否觸發斷路器的每個叢集指標。如果任何節點為 相關統計資訊:Maximum |
KNNEvictionCount |
因記憶體限制或閒置時間而從快取移出的圖形數目的每個節點指標。因索引刪除而發生的明確移出不會計算在內。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
KNNGraphIndexErrors |
將文件的 相關統計資料:總和 |
KNNGraphIndexRequests |
將文件的 相關統計資料:總和 |
KNNGraphMemoryUsage |
目前快取大小 (記憶體中所有圖形的總大小) 的每個節點指標 (KB)。此指標僅與近似的 K-NN 搜尋相關。 相關統計資訊:平均數 |
KNNGraphQueryErrors |
產生錯誤之圖形查詢數目的每個節點指標。 相關統計資料:總和 |
KNNGraphQueryRequests |
圖形查詢數目的每個節點指標。 相關統計資料:總和 |
KNNHitCount |
快取命中次數的每個節點指標。當使用者查詢已載入記憶體的圖形時,就會發生快取命中。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
KNNLoadExceptionCount |
嘗試將圖形載入快取時發生例外狀況的次數的每個節點指標。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
KNNLoadSuccessCount |
外掛程式成功將圖形載入快取的次數的每個節點指標。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
KNNMissCount |
快取遺漏次數的每個節點指標。當使用者查詢尚未載入記憶體的圖形時,就會發生快取遺漏。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
KNNQueryRequests |
K-NN 外掛程式接收之查詢請求數目的每個節點指標。 相關統計資料:總和 |
KNNScriptCompilationErrors |
指令碼編譯期間錯誤數目的每個節點指標。此統計數字僅與 K-NN 分數指令碼搜尋相關。 相關統計資料:總和 |
KNNScriptCompilations |
K-NN 指令碼編譯次數的每個節點指標。此值通常應該為 1 或 0,但是如果包含已編譯指令碼的快取已填滿,K-NN 指令碼可能會被重新編譯。此統計數字僅與 K-NN 分數指令碼搜尋相關。 相關統計資料:總和 |
KNNScriptQueryErrors |
指令碼查詢期間錯誤數目的每個節點指標。此統計數字僅與 K-NN 分數指令碼搜尋相關。 相關統計資料:總和 |
KNNScriptQueryRequests |
指令碼查詢總數的每個節點指標。此統計數字僅與 K-NN 分數指令碼搜尋相關。 相關統計資料:總和 |
KNNTotalLoadTime |
K-NN 將圖形載入到快取所需的時間 (以奈秒為單位)。此指標僅與近似的 K-NN 搜尋相關。 相關統計資料:總和 |
跨叢集搜尋指標
Amazon OpenSearch Service 提供下列跨叢集搜尋指標。
來源網域指標
| 指標 | 維度 | 描述 |
|---|---|---|
CrossClusterOutboundConnections |
|
連線節點數。如果回應包含一或多個略過的網域,請使用此指標以追蹤任何運作狀態不良的連線。如果這個數字掉到 0,則表示連線運作狀態不良。 |
CrossClusterOutboundRequests |
|
傳送至目的地網域的搜尋請求數。用來檢查跨叢集搜尋請求的負載是否佔用網域,將此指標中的任何尖峰與任何 JVM/CPU 尖峰相互關聯。 |
目的地網域指標
| 指標 | 維度 | 描述 |
|---|---|---|
CrossClusterInboundRequests |
|
從來源網域收到的傳入連線請求數。 |
如果發生意外遺失連線的情況,則新增 CloudWatch 提醒。如需建立提醒的步驟,請參閱根據靜態閾值建立 CloudWatch 提醒。
跨叢集複寫指標
Amazon OpenSearch Service 提供下列跨叢集複寫指標。
| 指標 | 描述 |
|---|---|
ReplicationRate |
每秒平均複寫操作速率。此指標類似於 |
LeaderCheckPoint |
對於特定連線,為所有複寫索引中領導檢查點值的總和。您可以使用此指標來測量複寫延遲。 |
FollowerCheckPoint |
對於特定連線,為所有複寫索引中追蹤檢查點值的總和。您可以使用此指標來測量複寫延遲。 |
ReplicationNumSyncingIndices |
具有複寫狀態 |
ReplicationNumBootstrappingIndices |
具有複寫狀態 |
ReplicationNumPausedIndices |
具有複寫狀態 |
ReplicationNumFailedIndices |
具有複寫狀態 |
|
|
追隨網域上的複寫傳輸請求數目。傳輸請求是內部的,每次呼叫複寫 API 操作時都會發生。當追隨網域輪詢來自領導網域的變更時,也會發生這種情況。 |
|
|
領導網域上的複寫傳輸請求數量。傳輸請求是內部的,每次呼叫複寫 API 操作時都會發生。 |
AutoFollowNumSuccessStartReplication |
針對特定連線,複寫規則成功建立的追蹤索引數目。 |
AutoFollowNumFailedStartReplication |
當有相符模式時,複寫規則無法建立的追蹤索引數目。此問題可能是因為遠端叢集上的網路問題或安全性問題 (也就是說,關聯的角色沒有啟動複寫的許可) 所導致。 |
AutoFollowLeaderCallFailure |
從追蹤索引到領導索引以選取新資料的査詢是否失敗。值 |
Learning to Rank 指標
Amazon OpenSearch Service 提供下列 Learning to Rank 指標。
| 指標 | 描述 |
|---|---|
LTRRequestTotalCount |
排名請求的總數。 |
LTRRequestErrorCount |
未成功請求的總數。 |
LTRStatus.red |
追蹤需要執行外掛程式的其中一個索引是否為紅色。 |
LTRMemoryUsage |
外掛程式使用的總記憶體。 |
LTRFeatureMemoryUsageInBytes |
Learning to Rank 功能欄位使用的記憶體容量 (以位元組為單位)。 |
LTRFeaturesetMemoryUsageInBytes |
所有 Learning to Rank 功能集使用的記憶體容量 (以位元組為單位)。 |
LTRModelMemoryUsageInBytes |
所有 Learning to Rank 模型使用的記憶體容量 (以位元組為單位)。 |
Piped Processing Language 指標
Amazon OpenSearch Service 提供下列 Piped Processing Language 指標。
| 指標 | 描述 |
|---|---|
PPLFailedRequestCountByCusErr |
因用戶端問題而失敗的 |
PPLFailedRequestCountBySysErr |
因伺服器問題或功能限制而失敗的 |
PPLRequestCount |
向 |
