本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
透過資料庫連結使用直接 Oracle Data Pump Import,將內部部署 Oracle 資料庫遷移至 Amazon RDS for Oracle
Rizwan Wangde,Amazon Web Services
Summary
許多模式涵蓋使用 Oracle Data Pump 將內部部署 Oracle 資料庫遷移至 Amazon Relational Database Service (Amazon RDS) for Oracle,這是遷移大型 Oracle 工作負載的首選方式。這些模式通常涉及將應用程式結構描述或資料表匯出至傾印檔案、將傾印檔案傳輸至 Amazon RDS for Oracle 上的資料庫目錄,然後從傾印檔案匯入應用程式結構描述和資料。
使用該方法,根據資料的大小和將傾印檔案傳輸至 Amazon RDS 執行個體所需的時間,遷移可能需要更長的時間。此外,傾印檔案位於 Amazon RDS 執行個體的 Amazon Elastic Block Store (Amazon EBS) 磁碟區上,其大小必須足以容納資料庫和傾印檔案。匯入後刪除傾印檔案時,無法擷取空白空間,因此您繼續支付未使用的空間。
此模式可透過透過資料庫連結使用 Oracle Data Pump API (DBMS_DATAPUMP),在 Amazon RDS 執行個體上執行直接匯入來緩解這些問題。模式會在來源和目標資料庫之間啟動同時匯出和匯入管道。此模式不需要調整傾印檔案的 EBS 磁碟區大小,因為磁碟區上不會建立或存放傾印檔案。此方法 可節省未使用的磁碟空間的每月成本。
先決條件和限制
先決條件
作用中的 Amazon Web Services (AWS) 帳戶。
在至少兩個可用區域中設定私有子網路的虛擬私有雲端 (VPC),以提供 Amazon RDS 執行個體的網路基礎設施。
內部部署資料中心中的 Oracle 資料庫,或在 Amazon Elastic Compute Cloud (Amazon EC2) 上自我管理。
單一可用區域中現有的 Amazon RDS for Oracle 執行個體。使用單一可用區域可改善遷移期間的寫入效能。異地同步備份部署可以在切換前 24-48 小時啟用。
此解決方案也可以使用 Amazon RDS Custom for Oracle 做為目標。
AWS Direct Connect (建議用於大型資料庫)。
內部部署的網路連線和防火牆規則,設定為允許從 Amazon RDS 執行個體到內部部署 Oracle 資料庫的傳入連線。
限制
截至 2022 年 12 月,Amazon RDS for Oracle 的資料庫大小限制為 64 TB (TiB)。
Amazon RDS for Oracle 資料庫執行個體上單一檔案的大小上限為 16 TiB。這很重要,因為您可能需要將資料表分散到多個資料表空間。
產品版本
來源資料庫:Oracle Database 10g 版本 1 和更新版本。
目標資料庫:如需 Amazon RDS 上支援版本的最新清單,請參閱 AWS 文件中的 Amazon RDS for Oracle。
架構
來源技術堆疊
內部部署或雲端中的自我管理 Oracle 資料庫
目標技術堆疊
Amazon RDS for Oracle 或 Amazon RDS Custom for Oracle
目標架構
下圖顯示從內部部署 Oracle 資料庫遷移到單一可用區環境中 Amazon RDS for Oracle 的架構。箭頭方向描述架構中的資料流程。圖表不會顯示哪個元件正在啟動連線。
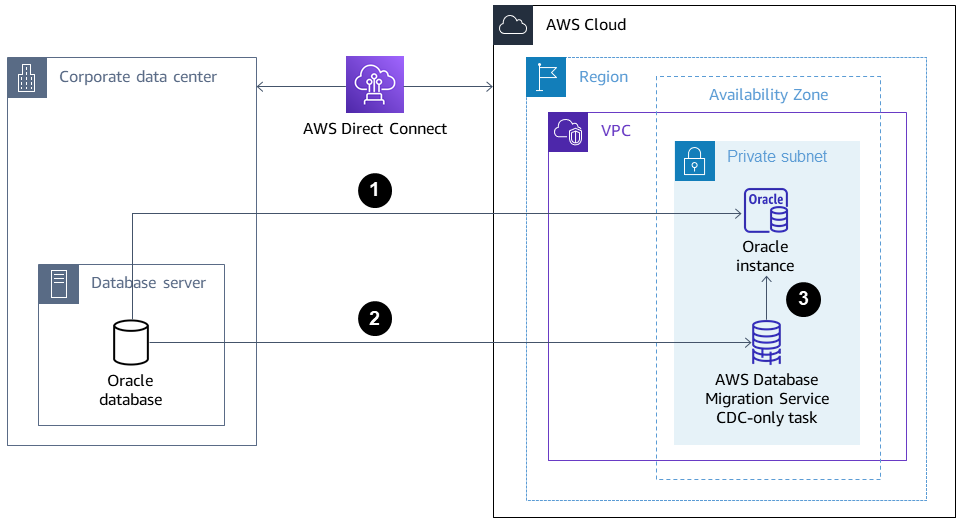
Amazon RDS for Oracle 執行個體會連線至現場部署來源 Oracle 資料庫,以透過資料庫連結執行完全載入遷移。
AWS Database Migration Service (AWS DMS) 會連線至內部部署來源 Oracle 資料庫,以使用變更資料擷取 (CDC) 執行持續複寫。
CDC 變更會套用至 Amazon RDS for Oracle 資料庫。
工具
AWS 服務
AWS Database Migration Service (AWS DMS) 可協助您將資料存放區遷移到 AWS 雲端 或在雲端和內部部署設定的組合之間遷移。此模式使用 CDC,且僅複寫資料變更設定。
AWS Direct Connect 會透過標準乙太網路光纖纜線將您的內部網路連結至某個 AWS Direct Connect 位置。使用此連線,您可以直接建立對公有的虛擬介面, AWS 服務 同時略過網路路徑中的網際網路服務提供者。
Amazon Relational Database Service 可協助您在 AWS 雲端中設定、操作和擴展 Oracle 關聯式資料庫。
其他工具
Oracle Data Pump
可協助您以高速將資料和中繼資料從一個資料庫移至另一個資料庫。 Oracle Instant Client
或 SQL Developer 等用戶端工具用於在資料庫上連接和執行 SQL 查詢。
最佳實務
雖然 AWS Direct Connect 使用內部部署網路與 之間的專用私有網路連線 AWS,但請考慮下列選項,以取得傳輸中資料的額外安全性和資料加密:
使用 從內部部署網路到網路的虛擬私有網路 (VPN) AWS Site-to-Site VPN 或 IPsec VPN 連線 AWS
使用 TLS
加密
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
設定從目標資料庫到來源資料庫的網路連線。 | 設定內部部署網路和防火牆,以允許從目標 Amazon RDS 執行個體傳入連線至內部部署來源 Oracle 資料庫。 | 網路管理員、安全工程師 |
建立具有適當權限的資料庫使用者。 | 在內部部署來源 Oracle 資料庫中建立資料庫使用者,具有使用 Oracle Data Pump 在來源和目標之間遷移資料的權限:
| DBA |
準備內部部署來源資料庫以進行 CDC AWS DMS 遷移。 | (選用) 在完成 Oracle Data Pump Full Load 之後,準備內部部署來源 Oracle 資料庫以進行 AWS DMS CDC 遷移:
| DBA |
安裝和設定 SQL Developer。 | 安裝並設定 SQL Developer | DBA,遷移工程師 |
產生指令碼以建立資料表空間。 | 使用下列範例 SQL 查詢在來源資料庫上產生指令碼:
指令碼將套用至目標資料庫。 | DBA |
產生指令碼以建立使用者、設定檔、角色和權限。 | 若要產生指令碼來建立資料庫使用者、設定檔、角色和權限,請使用 Oracle 支援文件中的指令碼 如何使用 dbms_metadata.get_ddl (Doc ID 2739952.1) 擷取使用者的 DDL,包括權限和角色 指令碼將套用至目標資料庫。 | DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立來源資料庫的資料庫連結並驗證連線。 | 若要建立內部部署來源資料庫的資料庫連結,您可以使用下列範例命令:
若要驗證連線能力,請執行下列 SQL 命令:
如果回應為 ,連線會成功 | DBA |
執行指令碼以準備目標執行個體。 | 執行先前產生的指令碼以準備目標 Amazon RDS for Oracle 執行個體:
這有助於確保 Oracle Data Pump 遷移可以建立結構描述及其物件。 | DBA,遷移工程師 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
遷移所需的結構描述。 | 若要將所需結構描述從來源現場部署資料庫遷移至目標 Amazon RDS 執行個體,請使用其他資訊區段中的程式碼: 若要調整遷移的效能,您可以執行下列命令來調整平行程序的數量:
| DBA |
收集結構描述統計資料以改善效能。 | 收集結構描述統計資料命令會傳回針對資料庫物件收集的 Oracle 查詢最佳化工具統計資料。透過使用此資訊,最佳化工具可以為針對這些物件的任何查詢選取最佳執行計畫:
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
在來源現場部署 Oracle 資料庫上擷取 SCN。 | 擷取來源內部部署 Oracle 資料庫上的系統變更編號 (SCN) 若要在來源資料庫上產生目前的 SCN,請執行下列 SQL 陳述式:
| DBA |
執行結構描述的完全載入遷移。 | 若要將所需的結構描述 ( 在程式碼中,
若要調整遷移的效能,您可以調整平行程序的數量:
| DBA |
停用遷移結構描述下的觸發條件。 | 開始僅限 AWS DMS CDC 任務之前,請在遷移的結構描述 | DBA |
收集結構描述統計資料以改善效能。 | 收集結構描述統計資料命令會傳回針對資料庫物件收集的 Oracle 查詢最佳化工具統計資料:
透過使用此資訊,最佳化工具可以為針對這些物件的任何查詢選取最佳執行計畫。 | DBA |
使用 AWS DMS 執行從來源到目標的持續複寫。 | 使用 AWS DMS 執行從來源 Oracle 資料庫到目標 Amazon RDS for Oracle 執行個體的持續複寫。 如需詳細資訊,請參閱使用 建立持續複寫的任務 AWS DMS,以及部落格文章如何使用 中的原生 CDC 支援 AWS DMS | DBA,遷移工程師 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
在切換前 48 小時啟用執行個體上的異地同步備份。 | 如果這是生產執行個體,建議您在 Amazon RDS 執行個體上啟用異地同步備份部署,以提供高可用性 (HA) 和災難復原 (DR) 的優點。 | DBA,遷移工程師 |
停止僅限 AWS DMS CDC 的任務 (如果已開啟 CDC)。 |
| DBA |
啟用觸發條件。 | 啟用您在建立 | DBA |
相關資源
AWS
Oracle 文件
其他資訊
程式碼 1:僅限完全載入遷移,單一應用程式結構描述
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''<schema_name>'')'); -- To migrate one selected schema DBMS_DATAPUMP.METADATA_FILTER (hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
程式碼 2:僅限完全載入遷移,多個應用程式結構描述
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'SCHEMA_LIST', '''<SCHEMA_1>'',''<SCHEMA_2>'', ''<SCHEMA_3>'''); -- To migrate multiple schemas DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
程式碼 3:僅在 CDC 任務之前進行完全載入遷移,單一應用程式結構描述
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''<schema_name>'')'); -- To migrate one selected schema DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARAMETER (handle => v_hdnl, name => 'FLASHBACK_SCN', value => <CURRENT_SCN_VALUE_IN_SOURCE_DATABASE>); -- SCN required for AWS DMS CDC only task. DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
程式碼 4:僅限 CDC 任務之前的完全載入遷移,多個應用程式結構描述
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN (operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE (handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'SCHEMA_LIST', '''<SCHEMA_1>'',''<SCHEMA_2>'', ''<SCHEMA_3>'''); -- To migrate multiple schemas DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARAMETER (handle => v_hdnl, name => 'FLASHBACK_SCN', value => <CURRENT_SCN_VALUE_IN_SOURCE_DATABASE>); -- SCN required for AWS DMS CDC only task. DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
混合遷移方法可以更好地運作的案例
在來源資料庫包含數百萬資料列和非常大型 LOBSEGMENT 資料欄的資料表極少數情況下,此模式會減慢遷移速度。Oracle 透過網路連結逐一遷移 LOBSEGMENTs。它會從來源資料表擷取單一資料列 (以及 LOB 資料欄資料),並將資料列插入目標資料表,重複此程序,直到遷移所有資料列為止。透過資料庫連結的 Oracle Data Pump 不支援 LOBSEGMENTs的大量載入或直接路徑載入機制。
在這種情況下,我們建議下列事項:
透過新增下列中繼資料篩選條件,在 Oracle Data Pump 遷移期間略過已識別的資料表:
dbms_datapump.metadata_filter(handle =>h1, name=>'NAME_EXPR', value => 'NOT IN (''TABLE_1'',''TABLE_2'')');使用 AWS DMS 任務 (完整載入遷移,視需要使用 CDC 複寫) 來遷移已識別的資料表。 AWS DMS 會從來源 Oracle 資料庫擷取多個資料列,並將其批次插入目標 Amazon RDS 執行個體,以改善效能。
