Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Multi-AZ-DB-Instance-Bereitstellungen für Amazon RDS
Amazon RDS bietet Hochverfügbarkeit und Failover-Unterstützung für DB-Instances, die Multi-AZ-Bereitstellungen mit einer einzigen Standby-DB-Instance verwenden. Diese Art der Bereitstellung wird als Multi-AZ-DB-Instance-Bereitstellung bezeichnet. Amazon RDS verwendet verschiedene Technologien, um diese Failover-Unterstützung bereitzustellen. Multi-AZ-Bereitstellungen für MariaDB-, My-, Oracle-SQL, Postgre SQL - und RDS Custom for SQL Server-DB-Instances verwenden die Amazon-Failover-Technologie. Microsoft SQL Server-DB-Instances verwenden SQL Server Database Mirroring (DBM) oder AlwaysOn-Verfügbarkeitsgruppen (AGs). Informationen zur Unterstützung von SQL Serverversionen für Multi-AZ finden Sie unter. Multi-AZ-Bereitstellungen für Amazon RDS für Microsoft Server SQL Informationen zur Arbeit mit RDS Custom for SQL Server für Multi-AZ finden Sie unter. Verwaltung einer Multi-AZ-Bereitstellung für RDS Custom for Server SQL
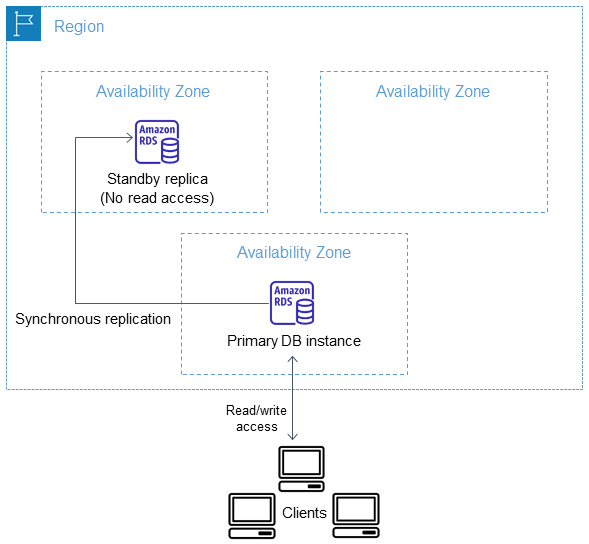
In einer Multi-AZ-DB-Instance-Bereitstellung stellt Amazon RDS automatisch ein synchrones Standby-Replikat in einer anderen Availability Zone bereit und verwaltet es. Die primäre DB-Instance wird synchron über Availability Zones hinweg auf ein Standby-Replikat repliziert, um Datenredundanz bereitzustellen und Latenzspitzen während Systemsicherungen zu minimieren. Wenn Sie eine DB-Instance mit hoher Verfügbarkeit ausführen, kann dies die Verfügbarkeit bei geplanten Systemwartungen verbessern. Sie kann auch Ihre Datenbanken bei Ausfällen der DB-Instance und bei Nichtverfügbarkeit von Availability Zones schützen. Weitere Informationen über Availability Zones finden Sie unter Regionen, Availability Zones und Local Zones.
Anmerkung
Die Option für hohe Verfügbarkeit ist keine Skalierungslösung für schreibgeschützte Szenarien. Sie können kein Standby-Replikat verwenden, um Leseverkehr bereitzustellen. Um schreibgeschützten Datenverkehr bereitzustellen, verwenden Sie stattdessen einen Multi-AZ-DB-Cluster oder ein Lesereplikat. Weitere Informationen zu Multi-AZ-DB-Clustern finden Sie unter Multi-AZ-DB-Cluster-Bereitstellungen für Amazon RDS. Weitere Informationen über Lesereplikate finden Sie unter Arbeiten mit DB-Instance-Lesereplikaten.
Mithilfe der RDS Konsole können Sie eine Multi-AZ-DB-Instance-Bereitstellung erstellen, indem Sie bei der Erstellung einer DB-Instance einfach Multi-AZ angeben. Sie können über die Konsole bestehende DB-Instances in Multi-AZ-Bereitstellungen für DB-Instances umwandeln, indem Sie die DB-Instance ändern und die Option „Multi-AZ“ angeben. Sie können auch eine Multi-AZ-DB-Instance-Bereitstellung mit dem AWS CLI oder Amazon RDS API angeben. Verwenden Sie den modify-db-instanceCLIBefehl create-db-instanceoder oder die odifyDBInstance API Operation C reateDBInstance oder M.
In der RDS Konsole wird die Availability Zone des Standby-Replikats (die so genannte sekundäre AZ) angezeigt. Sie können auch den describe-db-instancesCLIBefehl oder die escribeDBInstancesAPID-Operation verwenden, um die sekundäre AZ zu finden.
DB-Instances, die Multi-AZ-DB-Instance-Bereitstellungen verwenden, können im Vergleich zu einer Single-AZ-Bereitstellung eine höhere Schreib- und Commit-Latenz aufweisen. Dies kann aufgrund der auftretenden synchronen Datenreplikation geschehen. Es kann zu einer Änderung der Latenz kommen, wenn bei Ihrer Bereitstellung ein Failover auf das Standby-Replikat erfolgt, obwohl es AWS für Netzwerkverbindungen mit niedriger Latenz zwischen Availability Zones konzipiert wurde. Für Produktionsworkloads empfehlen wir, Provisioned IOPS (Eingabe-/Ausgabevorgänge pro Sekunde) zu verwenden, um eine schnelle, konsistente Leistung zu erzielen. Weitere Informationen zu DB-Instance-Klassen finden Sie unter .
