Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Empfohlene AWS Architektur für die Prognose der Nachfrage nach neuen Produkten
Wenn Sie Ihre KI/ML-Pipeline auf mehrere Produkte und Regionen skalieren, wird empfohlen, die Best Practices für Machine-Learning-Operationen (MLOps) im Hinblick auf Reproduzierbarkeit, Zuverlässigkeit und Skalierbarkeit zu befolgen. Weitere Informationen finden Sie unter Implementieren MLOps in der Amazon SageMaker AI-Dokumentation. Die folgende Abbildung zeigt eine AWS Beispielarchitektur für die Implementierung eines ML-Modells, das die Nachfrage nach neuen Produkteinführungen prognostiziert.
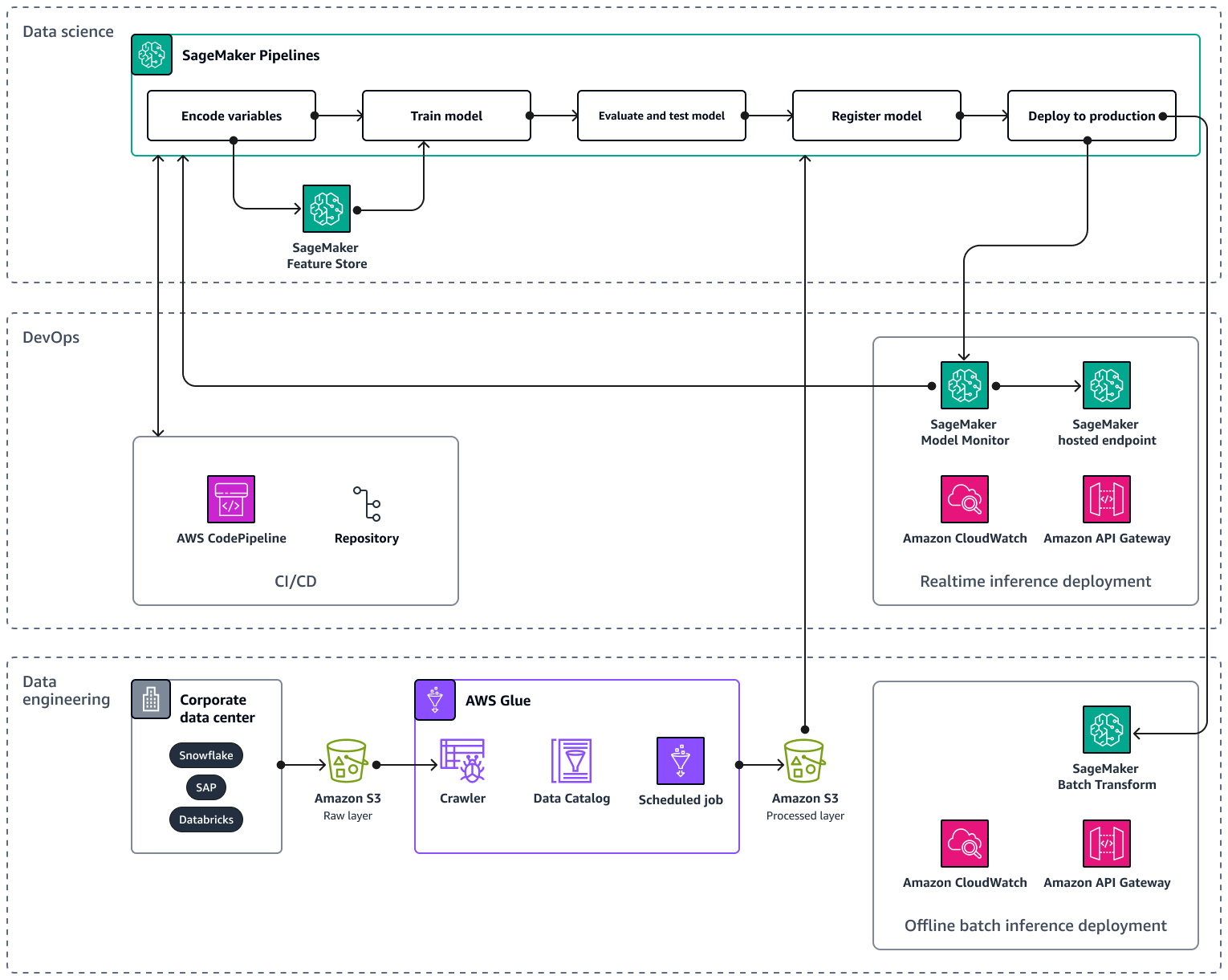
Die AWS Beispielarchitektur besteht aus drei Ebenen: Datentechnik und Datenwissenschaft. DevOps
Die Datenentwicklungsebene konzentriert sich auf die Erfassung von Daten aus Unternehmensdatenquellen, indem die Daten verwendet AWS Glueund anschließend kostengünstig in Amazon Simple Storage Service (Amazon S3) gespeichert werden. AWS Glue ist ein vollständig verwalteter serverloser ETL Service, der Sie dabei unterstützt, Daten zu kategorisieren, zu bereinigen, zu transformieren und zuverlässig zwischen verschiedenen Datenspeichern zu übertragen. Amazon S3 ist ein Objektspeicherservice, der Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung bietet. Die Datentechnikebene zeigt auch die Offline-Bereitstellung von Batch-Inferenzen mithilfe der Batch-Transformation in Amazon SageMaker AI. Die Batch-Transformation erhält die Eingabedaten von Amazon S3 und sendet sie in einer oder mehreren HTTP Anfragen über Amazon API Gateway an das Inferenz-Pipeline-Modell. Amazon API Gateway ist ein vollständig verwalteter Service, der Sie bei der Erstellung, Veröffentlichung, Wartung, Überwachung und Sicherung APIs in jeder Größenordnung unterstützt. Schließlich zeigt die Datentechnik-Ebene die Nutzung von Amazon CloudWatch, einem Service, der Einblick in die systemweite Leistung bietet und Ihnen hilft, Alarme einzustellen, automatisch auf Änderungen zu reagieren und einen einheitlichen Überblick über den Betriebsstatus zu erhalten. CloudWatch speichert die Protokolldateien in einem Amazon S3 S3-Bucket, den Sie angeben.
Die DevOps Ebene verwendet API Gateway und Amazon SageMaker AI Model Monitor für die Bereitstellung von Inferenzen in Echtzeit. CloudWatch Model Monitor hilft Ihnen bei der Einrichtung eines automatisierten Systems, das Warnmeldungen für Abweichungen in der Modellqualität, wie Datendrift und Anomalien, auslöst. Amazon CloudWatch Logs sammelt Protokolldateien von Model Monitor und benachrichtigt Sie, wenn die Qualität Ihres Modells bestimmte, von Ihnen voreingestellte Schwellenwerte erreicht. Die DevOps Ebene zeigt auch die Verwendung von AWS CodePipelinefür die Automatisierung von Pipelines für die Codebereitstellung.
Die Data-Science-Ebene zeigt die Verwendung von Amazon SageMaker AI Pipelines und Amazon SageMaker AI Feature Store zur Verwaltung des Machine-Learning-Lebenszyklus. SageMaker AI Pipelines ist ein speziell entwickelter Workflow-Orchestrierungsservice, mit dem Sie alle ML-Phasen automatisieren können, von der Datenvorverarbeitung bis zur Modellüberwachung. Mit einer intuitiven Benutzeroberfläche und Python SDK können Sie wiederholbare end-to-end ML-Pipelines skalierbar verwalten. Die native Integration mit mehreren AWS-Services hilft Ihnen dabei, den ML-Lebenszyklus an Ihre MLOps Anforderungen anzupassen. Feature Store ist ein vollständig verwaltetes, speziell entwickeltes Repository zum Speichern, Teilen und Verwalten von Funktionen für ML-Modelle. Funktionen sind Eingaben für ML-Modelle und werden während des Trainings und der Inferenz verwendet.
