Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
AWS Arquitectura recomendada para la previsión de la demanda de nuevos productos
A medida que amplíe su cartera de IA/ML a varios productos y regiones, se recomienda que siga las mejores prácticas de operaciones de aprendizaje automático (MLOps) para garantizar la reproducibilidad, la fiabilidad y la escalabilidad. Para obtener más información, consulte Implementar MLOps en la documentación de Amazon SageMaker AI. La siguiente imagen muestra un ejemplo de AWS arquitectura para implementar un modelo de aprendizaje automático que prevé la demanda de nuevos productos.
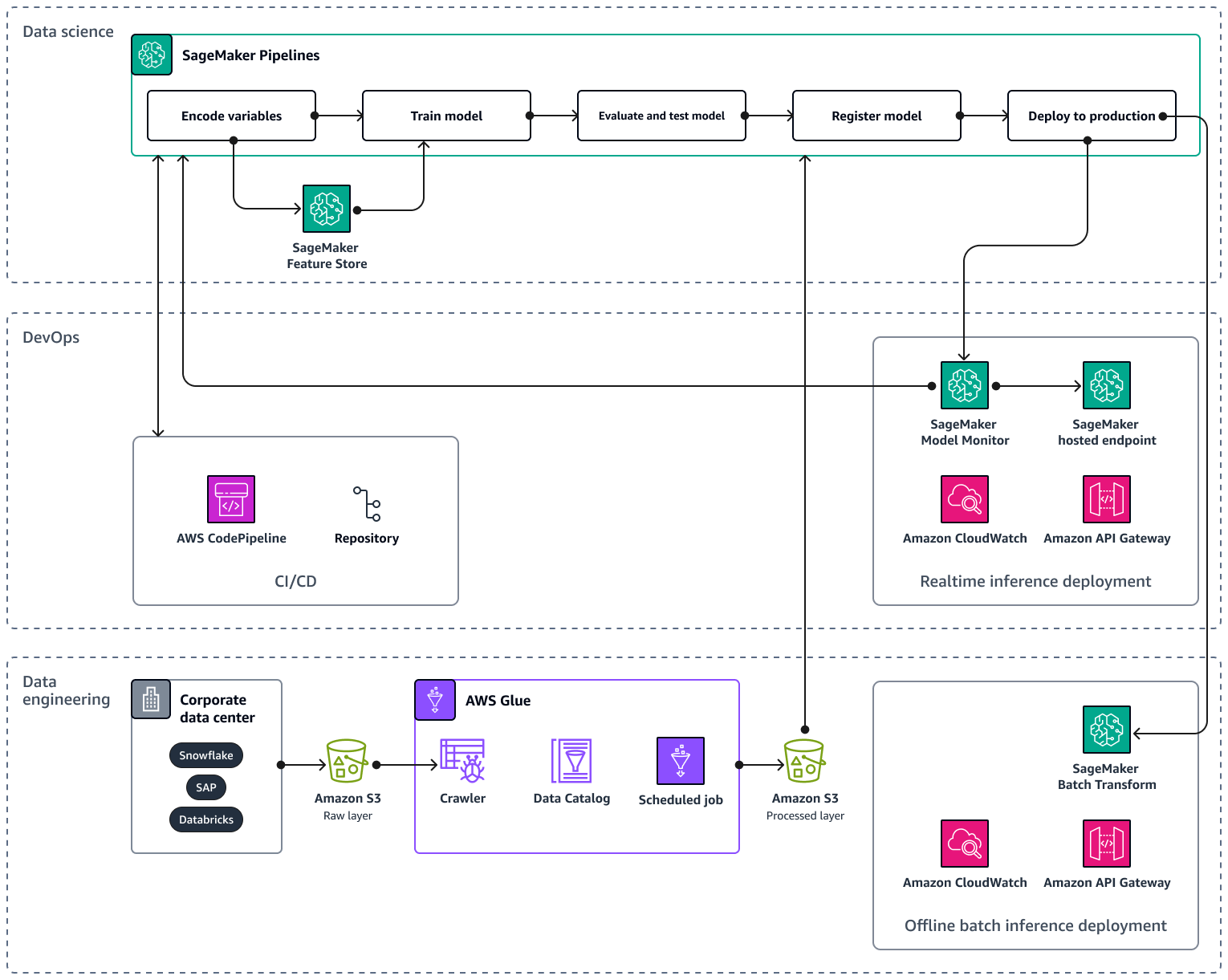
La AWS arquitectura de ejemplo consta de tres capas: ingeniería de datos y ciencia de datos. DevOps
La capa de ingeniería de datos se centra en la ingesta de datos de fuentes de datos corporativas mediante el uso AWS Gluey posterior almacenamiento de los datos de forma rentable en Amazon Simple Storage Service (Amazon S3). AWS Glue es un ETL servicio sin servidor totalmente gestionado que le ayuda a clasificar, limpiar, transformar y transferir datos de forma fiable entre diferentes almacenes de datos. Amazon S3: es un servicio de almacenamiento de objetos de AWS que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento. La capa de ingeniería de datos también muestra el despliegue de inferencia por lotes fuera de línea mediante la transformación por lotes en Amazon SageMaker AI. La transformación por lotes obtiene los datos de entrada de Amazon S3 y los envía en una o más HTTP solicitudes a través de Amazon API Gateway al modelo de canalización de inferencia. Amazon API Gateway es un servicio totalmente gestionado que le ayuda a crear, publicar, mantener, supervisar y proteger APIs a cualquier escala. Por último, la capa de ingeniería de datos muestra el uso de Amazon CloudWatch, un servicio que proporciona visibilidad del rendimiento de todo el sistema y le ayuda a configurar alarmas, reaccionar automáticamente ante los cambios y obtener una visión unificada del estado operativo. CloudWatch almacena los archivos de registro en un bucket de Amazon S3 que especifique.
La DevOps capa utiliza API Gateway y Amazon SageMaker AI Model Monitor para el despliegue de inferencias en tiempo real. CloudWatch Model Monitor le ayuda a configurar un sistema automatizado de activación de alertas en caso de desviaciones en la calidad del modelo, como desviaciones de datos o anomalías. Amazon CloudWatch Logs recopila archivos de registro de Model Monitor y le notifica cuando la calidad de su modelo alcanza ciertos umbrales, que usted preestableció. La DevOps capa también muestra el uso de AWS CodePipelinepara automatizar los procesos de entrega de códigos.
La capa de ciencia de datos muestra el uso de Amazon SageMaker AI Pipelines y Amazon SageMaker AI Feature Store para gestionar el ciclo de vida del aprendizaje automático. SageMaker AI Pipelines es un servicio de organización de flujos de trabajo especialmente diseñado que le ayuda a automatizar todas las fases del aprendizaje automático, desde el preprocesamiento de los datos hasta la supervisión de los modelos. Con una interfaz de usuario intuitiva y PythonSDK, puede gestionar canalizaciones de aprendizaje end-to-end automático repetibles a escala. La integración nativa con varios le Servicios de AWS ayuda a personalizar el ciclo de vida del aprendizaje automático en función de sus MLOps requisitos. Feature Store es un repositorio totalmente gestionado y diseñado específicamente para almacenar, compartir y gestionar las funciones de los modelos de aprendizaje automático. Las funciones son entradas para los modelos de aprendizaje automático y se utilizan durante el entrenamiento y la inferencia.
