Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Capturar datos de IoT directamente en Amazon S3 de forma rentable con AWS IoT Greengrass
Sebastian Viviani y Rizwan Syed, Amazon Web Services
Resumen
Este patrón le muestra cómo incorporar datos de Internet de las cosas (IoT) de forma rentable directamente en un depósito de Amazon Simple Storage Service (Amazon S3) mediante un dispositivo AWS IoT Greengrass versión 2. El dispositivo ejecuta un componente personalizado que lee los datos de IoT y los guarda en un almacenamiento persistente (es decir, un disco o volumen local). A continuación, el dispositivo comprime los datos de IoT en un archivo de Apache Parquet y los carga periódicamente en un bucket de S3.
La cantidad y la velocidad de los datos de IoT que ingiere están limitadas únicamente por las capacidades de su hardware periférico y el ancho de banda de la red. Puede utilizar Amazon Athena para analizar de forma rentable los datos ingeridos. Athena admite archivos comprimidos de Apache Parquet y la visualización de datos mediante el uso de Amazon Managed Grafana.
Requisitos previos y limitaciones
Requisitos previos
Una cuenta de AWS activa
Una puerta de enlace perimetral que se ejecuta en AWS IoT Greengrass versión 2 y recopila datos de los sensores (las fuentes de datos y el proceso de recopilación de datos están fuera del alcance de este patrón, pero puede usar casi cualquier tipo de datos de sensores). Este patrón utiliza un intermediario MQTT
local con sensores o puertas de enlace que publican los datos de forma local. Componentes, roles y dependencias del SDK
de AWS IoT Greengrass Un componente de administrador de transmisiones para cargar los datos al bucket de S3
AWS SDK para Java
, AWS SDK para JavaScript o AWS SDK para Python (Boto3) para ejecutar APIs
Limitaciones
Los datos de este patrón no se cargan en tiempo real en el bucket de S3. Hay un período de retraso y puede configurarlo. Los datos se almacenan temporalmente en el dispositivo perimetral y, una vez transcurrido el período, se cargan.
El SDK está disponible en Java, Node.js o Python.
Arquitectura
Pila de tecnología de destino
Amazon S3
AWS IoT Greengrass
Intermediario MQTT
Componente Stream Manager
Arquitectura de destino
El siguiente diagrama muestra una arquitectura diseñada para capturar datos de sensores de IoT y almacenarlos en un bucket de S3.
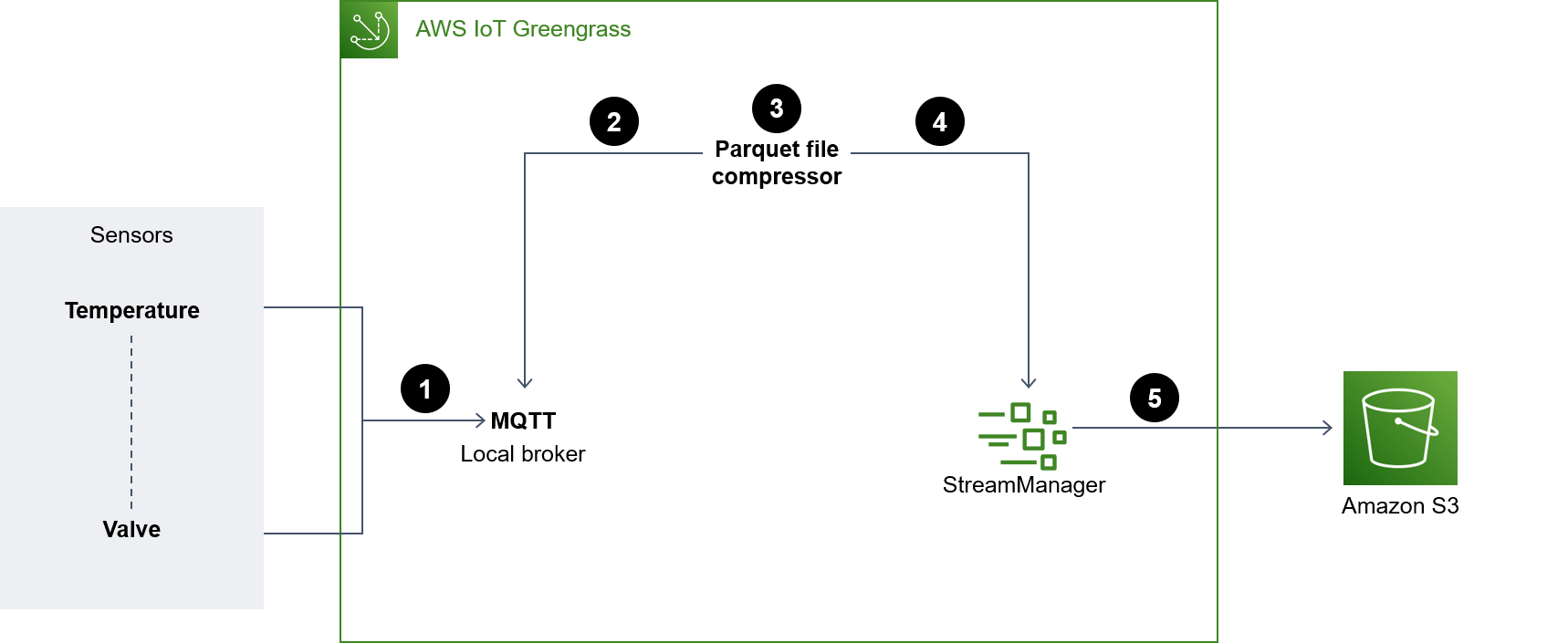
En el diagrama, se muestra el siguiente flujo de trabajo:
Las actualizaciones de varios sensores (por ejemplo, de temperatura y válvula) se publican en un agente de MQTT local.
El compresor de archivos Parquet que está suscrito a estos sensores actualiza los temas y recibe estas actualizaciones.
El compresor de archivos Parquet almacena las actualizaciones de forma local.
Una vez transcurrido el período, los archivos almacenados se comprimen en archivos Parquet y se pasan al administrador de flujos para cargarlos en el bucket de S3 especificado.
El administrador de transmisión carga los archivos de Parquet en el bucket de S3.
nota
El administrador de transmisiones (StreamManager) es un componente administrado. Para ver ejemplos de cómo exportar datos a Amazon S3, consulte Stream Manager en la documentación de AWS IoT Greengrass. Puede utilizar un bróker MQTT local como componente u otro bróker como Eclipse Mosquitto
Herramientas
Herramientas de AWS
Amazon Athena es un servicio de consultas interactivo que facilita el análisis de datos en Amazon S3 con SQL estándar.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
AWS IoT Greengrass es un servicio en la nube y de tiempo de ejecución de borde de IoT de código abierto que le ayuda a crear, implementar y administrar aplicaciones de IoT en los dispositivos.
Otras herramientas
Apache Parquet
es un formato de archivo de datos de código abierto orientado por columnas diseñado para el almacenamiento y la recuperación. El MQTT (Message Queuing Telemetry Transport) es un protocolo de mensajería ligero diseñado para dispositivos restringidos.
Prácticas recomendadas
Utilice el formato de partición adecuado para los datos cargados
No hay requisitos específicos para los nombres de los prefijos raíz del bucket de S3 (por ejemplo, "myAwesomeDataSet/" o"dataFromSource"), pero le recomendamos que utilice una partición y un prefijo significativos para que sea fácil entender el propósito del conjunto de datos.
También le recomendamos que utilice la partición correcta en Amazon S3 para que las consultas se ejecuten de forma óptima en el conjunto de datos. En el siguiente ejemplo, los datos se dividen en formato HIVE para optimizar la cantidad de datos escaneados por cada consulta de Athena. Esto puede mejorar el rendimiento y reducir los costos.
s3://<ingestionBucket>/<rootPrefix>/year=YY/month=MM/day=DD/HHMM_<suffix>.parquet
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree un bucket de S3. |
| Desarrollador de aplicaciones |
Añada permisos de IAM al bucket de S3. | Para conceder a los usuarios acceso de escritura al bucket y al prefijo de S3 que creó anteriormente, añada la siguiente política de IAM a su rol de AWS IoT Greengrass:
Para obtener más información, consulte Creación de una política de IAM para acceder a los recursos de Amazon S3 en la documentación de Aurora. A continuación, actualice la política de recursos (si es necesario) del bucket de S3 para permitir el acceso de escritura con los principios de AWS correctos. | Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Actualizar la receta del componente. | Actualice la configuración del componente al crear una implementación según el siguiente ejemplo:
| Desarrollador de aplicaciones |
Cree el componente. | Realice una de las siguientes acciones:
| Desarrollador de aplicaciones |
Actualice el cliente MQTT. | El código de ejemplo no utiliza la autenticación porque el componente se conecta localmente al intermediario. Si su situación es diferente, actualice la sección del cliente de MQTT según sea necesario. Además, realice lo siguiente:
| Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Actualice la implementación del dispositivo principal. | Si la implementación del dispositivo principal de AWS IoT Greengrass versión 2 ya existe, revise la implementación. Si la implementación no existe, cree una nueva. Para asignar al componente el nombre correcto, actualice la configuración del administrador de registros para el nuevo componente (si es necesario) en función de lo siguiente:
Por último, complete la revisión de la implementación de su dispositivo principal AWS IoT Greengrass. | Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Compruebe los registros del volumen de AWS IoT Greengrass. | Compruebe lo siguiente:
| Desarrollador de aplicaciones |
Compruebe el bucket de S3. | Compruebe si los datos se cargan en el bucket de S3. Puede ver los archivos que se están cargando en cada período. También puede comprobar si los datos se han cargado en el depósito de S3 consultando los datos en la siguiente sección. | Desarrollador de aplicaciones |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Crear una base de datos y tabla. |
| Desarrollador de aplicaciones |
Concede a Athena acceso a los datos. |
| Desarrollador de aplicaciones |
Solución de problemas
| Problema | Solución |
|---|---|
El cliente MQTT no se puede conectar |
|
El cliente MQTT no se suscribe | Validar los permisos en el bróker MQTT. Si tiene un bróker MQTT de AWS, consulte Broker MQTT 3.1.1 (Moquette) y MQTT 5 Broker (EMQX). |
Los archivos Parquet no se crean |
|
Los objetos no se cargan en el bucket de S3 |
|
Recursos relacionados
DataFrame
(Documentación de Pandas) Documentación de Apache Parquet
(documentación de Parquet) Desarrollo de componentes de AWS IoT Greengrass (Guía para desarrolladores de AWS IoT Greengrass, versión 2)
Implemente componentes de AWS IoT Greengrass en dispositivos (Guía para desarrolladores de AWS IoT Greengrass, versión 2)
Interactúe con dispositivos de IoT locales (Guía para desarrolladores de AWS IoT Greengrass, versión 2)
Broker MQTT 3.1.1 (Moquette) (Guía para desarrolladores de AWS IoT Greengrass, versión 2)
Broker MQTT 5 (EMQX) (Guía para desarrolladores de AWS IoT Greengrass, versión 2)
Información adicional
Análisis de costos
El siguiente escenario de análisis de costos demuestra cómo el enfoque de captura de datos incluido en este patrón puede afectar los costos de captura de datos en la nube de AWS. Los ejemplos de precios de este escenario se basan en los precios vigentes en el momento de la publicación. Los precios están sujetos a cambios. Además, los costos pueden variar en función de la región de AWS, las Service quotas de AWS y otros factores relacionados con el entorno de nube.
Conjunto de señales de entrada
Este análisis utiliza el siguiente conjunto de señales de entrada como base para comparar los costos de captura de IoT con otras alternativas disponibles.
Número de señales | Frecuencia | Datos por señal |
|---|---|---|
125 | 25 Hz | 8 bytes |
En este escenario, el sistema recibe 125 señales. Cada señal es de 8 bytes y se produce cada 40 milisegundos (25 Hz). Estas señales pueden venir individualmente o agrupadas en una carga útil común. Tiene la opción de dividir y empaquetar estas señales según sus necesidades. También puede determinar la latencia. La latencia consiste en el período de tiempo para recibir, acumular y capturar los datos.
A modo de comparación, la operación de captura de este escenario se basa en la región de AWS de us-east-1. La comparación de costos se aplica únicamente a los servicios de AWS. Otros costos, como el hardware o la conectividad, no se tienen en cuenta en el análisis.
Comparaciones de costos
La siguiente tabla muestra el costo mensual en dólares estadounidenses (USD) de cada método de ingestión.
Método | Costo mensual |
|---|---|
AWS SiteWise IoT* | 331,77 USD |
AWS IoT SiteWise Edge con paquete de procesamiento de datos (mantiene todos los datos en el borde) | 200 USD |
Reglas de AWS IoT Core y Amazon S3 para acceder a datos sin procesar | 84,54 USD |
Compresión de archivos Parquet en el borde y carga a Amazon S3 | 0,5 USD |
*Los datos se deben reducir para cumplir con las Service quotas. Esto significa que se pierden algunos datos con este método.
Métodos alternativos
En esta sección se muestran los costos equivalentes de los siguientes métodos alternativos:
AWS IoT SiteWise: cada señal debe cargarse en un mensaje individual. Por lo tanto, la cantidad total de mensajes por mes es de 125 × 25 × 3600 × 24 × 30, o sea, 8 100 millones de mensajes por mes. Sin embargo, AWS IoT solo SiteWise puede gestionar 10 puntos de datos por segundo por propiedad. Suponiendo que los datos se reduzcan a 10 Hz, la cantidad de mensajes por mes se reduce a 125 × 10 × 3600 × 24 × 30, o sea, 3,24 mil millones. Si utiliza el componente de publicación que agrupa las medidas en grupos de 10 (a 1 USD por millón de mensajes), el costo mensual será de 324 USD al mes. Suponiendo que cada mensaje tenga 8 bytes (1 Kb/125), se trata de 25,92 GB de almacenamiento de datos. Esto añade un costo mensual de 7,77 USD. El costo total del primer mes es de 331,77 USD y aumenta 7,77 USD cada mes.
AWS IoT SiteWise Edge con paquete de procesamiento de datos, que incluye todos los modelos y señales completamente procesados en el borde (es decir, sin ingesta de nubes): puede usar el paquete de procesamiento de datos como alternativa para reducir los costos y configurar todos los modelos que se calculan en el borde. Esto puede funcionar solo para el almacenamiento y la visualización, incluso si no se realiza ningún cálculo real. En este caso, es necesario utilizar un hardware potente para la puerta de enlace perimetral. Hay un costo fijo de 200 USD al mes.
Ingesta directa a AWS IoT Core por parte de MQTT y una regla de IoT para almacenar los datos sin procesar en Amazon S3: suponiendo que todas las señales se publiquen en una carga útil común, el número total de mensajes publicados en AWS IoT Core es de 25 × 3600 × 24 × 30, es decir, 64,8 millones por mes. A 1 USD por millón de mensajes, se trata de un costo mensual de 64,8 USD al mes. A 0,15 USD por millón de activaciones de reglas y con una regla por mensaje, esto añade un costo mensual de 19,44 USD. Con un costo de 0,023 USD por GB de almacenamiento en Amazon S3, se añaden otros 1,5 USD al mes (aumentando cada mes para reflejar los nuevos datos). El costo total del primer mes es de 84,54 USD y aumenta 1,5 USD cada mes.
Comprimir los datos en el borde de un archivo Parquet y subirlos a Amazon S3 (método propuesto): la relación de compresión depende del tipo de datos. Con los mismos datos industriales probados para MQTT, el total de datos de salida de un mes completo es de 1,2 Gb. Esto cuesta 0,03 USD al mes. Los índices de compresión (que utilizan datos aleatorios) descritos en otros puntos de referencia son del orden del 66 por ciento (lo que se acerca más al peor de los casos). El total de datos es de 21 Gb y cuesta 0,5 USD al mes.
Generador de archivos de parquet
El siguiente ejemplo de código muestra la estructura de un generador de archivos Parquet escrito en Python. El ejemplo de código es solo para fines ilustrativos y no funcionará si se pega en su entorno.
import queue import paho.mqtt.client as mqtt import pandas as pd #queue for decoupling the MQTT thread messageQueue = queue.Queue() client = mqtt.Client() streammanager = StreamManagerClient() def feederListener(topic, message): payload = { "topic" : topic, "payload" : message, } messageQueue.put_nowait(payload) def on_connect(client_instance, userdata, flags, rc): client.subscribe("#",qos=0) def on_message(client, userdata, message): feederListener(topic=str(message.topic), message=str(message.payload.decode("utf-8"))) filename = "tempfile.parquet" streamname = "mystream" destination_bucket= "amzn-s3-demo-bucket" keyname="mykey" period= 60 client.on_connect = on_connect client.on_message = on_message streammanager.create_message_stream( MessageStreamDefinition(name=streamname, strategy_on_full=StrategyOnFull.OverwriteOldestData) ) while True: try: message = messageQueue.get(timeout=myArgs.mqtt_timeout) except (queue.Empty): logger.warning("MQTT message reception timed out") currentTimestamp = getCurrentTime() if currentTimestamp >= nextUploadTimestamp: df = pd.DataFrame.from_dict(accumulator) df.to_parquet(filename) s3_export_task_definition = S3ExportTaskDefinition(input_url=filename, bucket=destination_bucket, key=key_name) streammanager.append_message(streamname, Util.validate_and_serialize_to_json_bytes(s3_export_task_definition)) accumulator = {} nextUploadTimestamp += period else: accumulator.append(message)
