Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Déploiements de clusters de base de données multi-AZ
Un déploiement de cluster de bases de données multi-AZ est un mode de déploiement semi-synchrone à haute disponibilité d'Amazon RDS avec deux instances de base de données répliques lisibles. Un cluster de base de données multi-AZ possède une instance de base de données d'écriture et deux instances de base de données de lecture dans trois zones de disponibilité distinctes d'une même Région AWS. Les clusters de base de données multi-AZ offrent une haute disponibilité, une capacité accrue pour les charges de travail en lecture et une moindre latence en écriture par rapport aux déploiements d'instances de base de données multi-AZ.
Vous pouvez importer des données d'une base de données sur site vers un cluster de bases de données multi-AZ en suivant les instructions dans Importation de données vers une base de données MariaDB ou MySQL Amazon RDS avec un temps d'arrêt réduit.
Vous pouvez acheter des instances de base de données réservées pour un cluster de bases de données multi-AZ. Pour plus d’informations, consultez Instances de base de données réservées pour un cluster de bases de données multi-AZ.
La disponibilité et la prise en charge des fonctionnalités varient selon les versions spécifiques de chaque moteur de base de données, et selon les Régions AWS. Pour obtenir plus d'informations sur la disponibilité des versions et des régions d'Amazon RDS avec des clusters de bases de données multi-AZ, consultez Régions et moteurs de base de données pris en charge pour les clusters de bases de données multi-AZ sur Amazon RDS.
Rubriques
- Disponibilité des classes d'instance pour les clusters de bases de données multi-AZ
- Présentation des clusters de base de données multi-AZ
- Gestion d'un cluster de bases de données multi-AZ à l'aide du AWS Management Console
- Utilisation des groupes de paramètres pour clusters de base de données multi-AZ
- Mise à niveau de la version du moteur d'un cluster de bases de données multi-AZ
- Utilisation de RDS Proxy avec des clusters de bases de données multi-AZ
- Configuration de la réplication externe à partir de clusters de bases de données multi-AZ
- Retard de réplica et clusters de base de données multi-AZ
- Processus de basculement des clusters de base de données multi-AZ
- Instantanés de clusters de bases de données multi-AZ
- Création d'un cluster de base de données multi-AZ
- Connexion à un cluster de base de données multi-AZ
- Connexion automatique d'une ressource de calcul AWS et d'un cluster de bases de données multi-AZ
- Modification d'un cluster de base de données multi-AZ
- Renommage d'un cluster de bases de données multi-AZ
- Redémarrage d'un cluster de base de données multi-AZ et des instances de base de données de lecteur
- Utilisation des réplicas en lecture d'un cluster de base de données multi-AZ
- Utilisation de la réplication logique PostgreSQL avec les clusters de bases de données multi-AZ
- Suppression d'un cluster de base de données multi-AZ
- Limites des clusters de bases de données multi-AZ
Important
Les clusters de base de données multi-AZ sont différents des clusters de base de données Aurora. Pour en savoir plus sur les clusters de base de données Aurora, consultez le Guide de l'utilisateur Amazon Aurora.
Disponibilité des classes d'instance pour les clusters de bases de données multi-AZ
Les déploiements de clusters de bases de données multi-AZ sont pris en charge pour les classes d'instances de base de données suivantes : db.m5d db.m6gd db.m6id db.m6idndb.r5d,db.r6gd,db.x2iedn,db.r6id,db.r6idn, et. db.c6gd
Note
Les classes d'instance c6gd sont les seules à prendre en charge la taille de l'mediuminstance.
Pour plus d'informations sur les classes d'instance de base de données, veuillez consulter Classes d'instances de base de données .
Présentation des clusters de base de données multi-AZ
Avec un cluster de base de données multi-AZ, Amazon RDS réplique les données de l'instance de base de données d'écriture dans les deux instances de base de données de lecture en tirant parti des capacités de réplication natives du moteur de base de données. Lorsqu'une modification est apportée à l'instance de base de données d'écriture, elle est transmise à chaque instance de base de données de lecture.
Les déploiements de clusters de bases de données multi-AZ utilisent une réplication semi-synchrone, qui nécessite un accusé de réception d'au moins une instance de base de données de lecture pour qu'une modification soit appliquée. Il n'est pas nécessaire de confirmer que les événements ont été entièrement exécutés et validés sur tous les réplicas.
Les instances de base de données d'écriture font office de cibles de basculement automatique et traitent également le trafic en lecture pour accroître le débit de lecture des applications. En cas de panne sur votre instance de base de données de rédacteur, RDS gère laquelle des instances de base de données de lecteur devient la cible de basculement. RDS procède en fonction de l'instance de base de données de lecteur qui a l'enregistrement de changement le plus récent.
Le schéma suivant illustre un cluster de base de données multi-AZ.
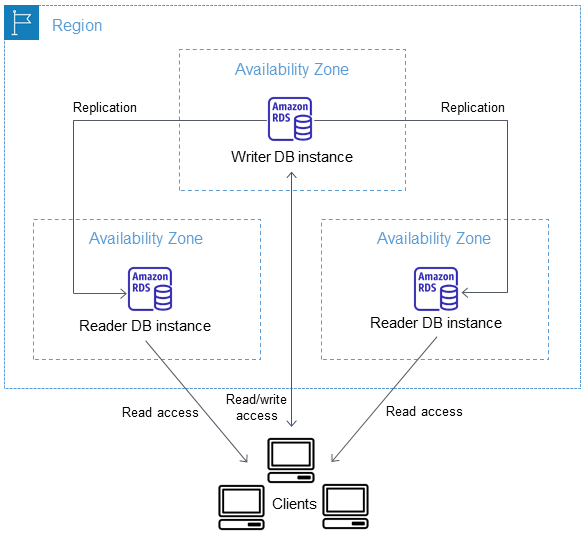
Les clusters de base de données multi-AZ ont généralement une latence d'écriture moindre par rapport aux déploiements d'instances de base de données multi-AZ. Ils permettent également d'exécuter des charges de travail en lecture seule sur des instances de base de données de lecteurs. La console RDS affiche la zone de disponibilité de l'instance de base de données d'écriture et les zones de disponibilité des instances de base de données de lecture. Vous pouvez également utiliser la commande describe-db-clustersCLI ou l'opération d'API DescribeDBclusters pour trouver ces informations.
Important
Pour éviter les erreurs de réplication dans les clusters de bases de données multi-AZ RDS for MySQL, nous recommandons vivement que toutes les tables aient une clé primaire.
Gestion d'un cluster de bases de données multi-AZ à l'aide du AWS Management Console
Vous pouvez gérer un cluster de base de données multi-AZ avec la console.
Pour gérer un cluster de base de données multi-AZ avec la console
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/rds/
. -
Dans le panneau de navigation, choisissez Databases (Bases de données), puis le cluster de base de données multi-AZ que vous souhaitez gérer.
L'image suivante montre un cluster de base de données multi-AZ dans la console.
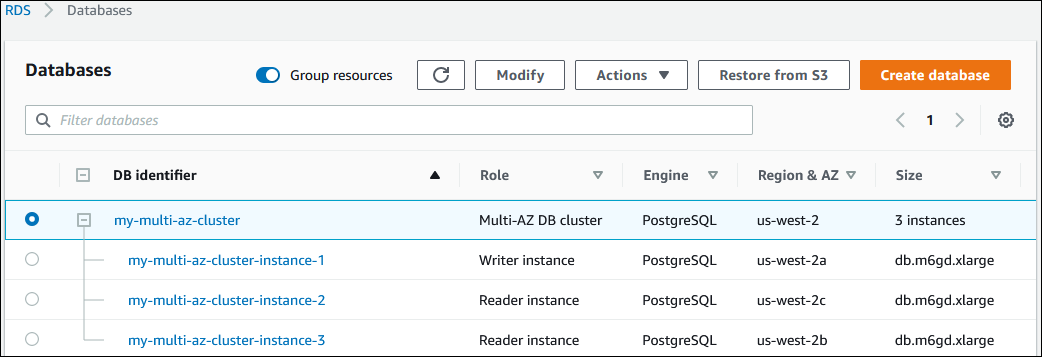
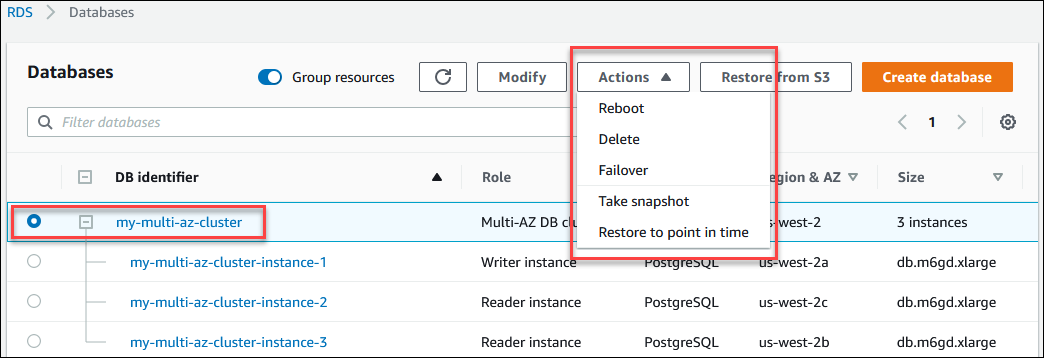
Les actions disponibles dans le menu Actions varient selon que vous sélectionnez le cluster de base de données multi-AZ ou une instance de base de données du cluster.
Choisissez le cluster de base de données multi-AZ pour en afficher les détails et effectuer des actions au niveau du cluster.
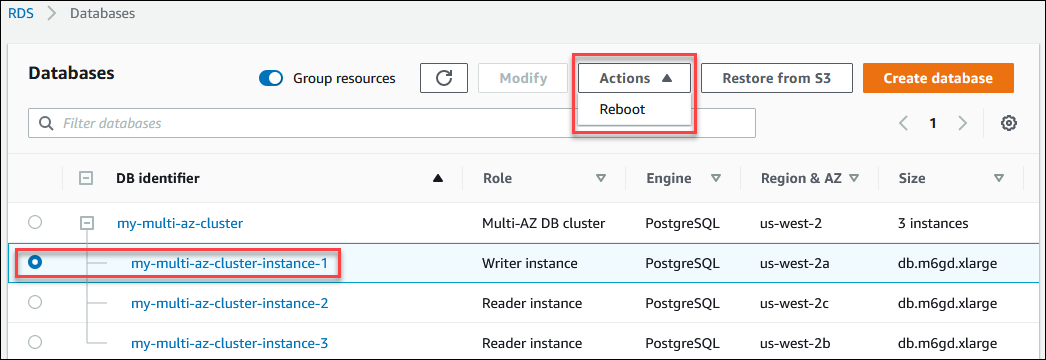
Choisissez une instance de base de données dans un cluster de base de données multi-AZ pour en afficher les détails et effectuer des actions au niveau de cette instance de base de données.
Utilisation des groupes de paramètres pour clusters de base de données multi-AZ
Dans un cluster de base de données multi-AZ, un groupe de paramètres de cluster de base de données sert de conteneur pour les valeurs de configuration du moteur qui sont appliquées à chaque instance de base de données contenue dans le cluster de base de données multi-AZ.
Dans un cluster de base de données multi-AZ, un groupe de paramètres de base de données est défini comme étant le groupe de paramètres de base de données par défaut pour le moteur et la version du moteur de base de données Les paramètres du groupe de paramètres de cluster de base de données s'appliquent à toutes les instances de base de données du cluster.
Pour plus d'informations sur les groupes de paramètres, veuillez consulter Utilisation des groupes de paramètres de clusters de base de données pour les clusters de base de données Multi-AZ.
Mise à niveau de la version du moteur d'un cluster de bases de données multi-AZ
Amazon RDS fournit des versions plus récentes de chaque moteur de base de données pris en charge afin que vous puissiez maintenir votre cluster de bases de données multi-AZ à jour. Quand Amazon RDS prend en charge une nouvelle version d'un moteur de base de données, vous pouvez choisir comment et quand mettre à niveau votre cluster de bases de données multi-AZ.
Il existe deux types de mises à niveau que vous pouvez effectuer :
- Mises à niveau des versions majeures
-
Une mise à niveau majeure d'une version du moteur peut introduire des modifications incompatibles avec les applications existantes. Lorsque vous lancez une mise à niveau de version majeure, Amazon RDS met à niveau simultanément les instances du lecteur et du rédacteur. Par conséquent, il est possible que votre cluster de base de données ne soit pas disponible tant que la mise à niveau n'est pas terminée.
- Mises à niveau de versions mineures
-
Une mise à niveau de version mineure contient uniquement des modifications rétrocompatibles avec les applications existantes. Lorsque vous lancez une mise à niveau d'une version mineure, Amazon RDS met d'abord à niveau les instances de base de données du lecteur une par une. Ensuite, l'une des instances de base de données du lecteur devient la nouvelle instance de base de données du rédacteur. Amazon RDS met ensuite à niveau l'ancienne instance d'écriture (qui est désormais une instance de lecteur).
Les temps d'arrêt pendant la mise à niveau sont limités au temps nécessaire à l'une des instances de base de données du lecteur pour devenir la nouvelle instance de base de données du rédacteur. Ce temps d'arrêt agit comme un basculement automatique. Pour plus d’informations, consultez Processus de basculement des clusters de base de données multi-AZ. Notez que le délai de réplication de votre cluster de base de données multi-AZ peut affecter le temps d'arrêt. Pour plus d’informations, consultez Retard de réplica et clusters de base de données multi-AZ.
Pour les répliques de lecture de clusters de bases de données multi-AZ RDS pour PostgreSQL, Amazon RDS met à niveau les instances membres du cluster une par une. Les rôles du cluster de lecture et d'écriture ne changent pas pendant la mise à niveau. Par conséquent, votre cluster de base de données peut être indisponible pendant qu'Amazon RDS met à niveau l'instance du rédacteur de cluster.
Note
Le temps d'arrêt pour une mise à niveau d'une version mineure d'un cluster de base de données multi-AZ est généralement de 35 secondes. Lorsqu'il est utilisé avec le proxy RDS, vous pouvez réduire davantage les temps d'arrêt à une seconde ou moins. Pour plus d’informations, consultez Utilisation d'Amazon RDS Proxy . Vous pouvez également utiliser un proxy de base de données open source tel que ProxySQL
ou le pilote PgBouncer AWS JDBC pour MySQL.
Actuellement, Amazon RDS prend en charge les mises à niveau de versions majeures uniquement pour les clusters de bases de données multi-AZ RDS for PostgreSQL. Amazon RDS prend en charge les mises à niveau de versions mineures pour tous les moteurs de base de données qui prennent en charge les clusters de bases de données multi-AZ.
Amazon RDS ne met pas automatiquement à niveau les réplicas en lecture des clusters de bases de données multi-AZ. Pour les mises à niveau de versions mineures, vous devez d'abord mettre à niveau manuellement toutes les répliques en lecture, puis mettre à niveau le cluster. Dans le cas contraire, la mise à niveau est bloquée. Quand vous effectuez une mise à niveau de version majeure d'un cluster, l'état de réplication de tous les réplicas en lecture devient résilié. Vous devez supprimer et recréer les réplicas en lecture une fois la mise à niveau terminée. Pour plus d’informations, consultez Supervision de la réplication en lecture.
Le processus de mise à niveau de la version du moteur d'un cluster de bases de données multi-AZ est identique au processus de mise à niveau de la version du moteur d'une instance de base de données. Pour obtenir des instructions, veuillez consulter Mise à niveau de la version du moteur d'une instance de base de données. La seule différence est que lorsque vous utilisez le AWS Command Line Interface (AWS CLI), vous utilisez la modify-db-clustercommande et spécifiez le --db-cluster-identifier paramètre (ainsi que le --allow-major-version-upgrade paramètre).
Pour plus d'informations sur les mises à niveau des versions majeures et mineures, consultez la documentation suivante relative à votre moteur de base de données :
Utilisation de RDS Proxy avec des clusters de bases de données multi-AZ
Vous pouvez utiliser Amazon RDS Proxy pour créer un proxy pour vos clusters de bases de données multi-AZ. En utilisant le proxy RDS, vos applications peuvent regrouper et partager des connexions à des bases de données afin d'améliorer leur capacité à évoluer. Chaque proxy effectue le multiplexage des connexions, également appelé réutilisation des connexions. Grâce au multiplexage, RDS Proxy exécute toutes les opérations d'une transaction à l'aide d'une connexion de base de données sous-jacente. Le proxy RDS peut également réduire à une seconde ou moins le temps d'arrêt lié à une mise à niveau de version mineure d'un cluster de base de données multi-AZ. Pour plus d'informations sur les avantages de RDS Proxy, consultez Utilisation d'Amazon RDS Proxy .
Pour configurer un proxy pour un cluster de base de données multi-AZ, choisissez Créer un proxy RDS lors de la création du cluster. Pour obtenir des instructions sur la création et la gestion des points de terminaison RDS Proxy, consultez Utilisation des points de terminaison Amazon RDS Proxy.
Configuration de la réplication externe à partir de clusters de bases de données multi-AZ
Vous pouvez configurer la réplication entre un cluster de bases de données multi-AZ et une base de données externe à Amazon RDS. Consultez les instructions des sections suivantes en fonction de votre moteur de base de données.
RDS for MySQL
Pour configurer la réplication externe pour un cluster de bases de données multi-AZ RDS pour MySQL, vous devez conserver les fichiers journaux binaires sur les instances de base de données du cluster suffisamment longtemps pour garantir que les modifications sont appliquées à la réplique avant qu'Amazon RDS ne supprime le fichier binlog. Pour ce faire, configurez la conservation des journaux binaires en appelant la procédure mysql.rds_set_configuration stockée et en spécifiant le binlog retention hours paramètre. Pour plus d’informations, consultez nombre d'heures de conservation du journal binaire.
La valeur par défaut pour binlog retention hours estNULL, ce qui signifie que les journaux binaires ne sont pas conservés (0 heure). Si vous souhaitez configurer une réplication externe pour un cluster de base de données multi-AZ, vous devez définir le paramètre sur une valeur autre queNULL.
Vous ne pouvez configurer la conservation des journaux binaires qu'à partir de l'instance de base de données Writer du cluster de base de données Multi-AZ, et le paramètre est propagé à toutes les instances de base de données de lecture de manière asynchrone.
En outre, nous vous recommandons vivement d'activer la réplication basée sur le GTID sur votre réplique externe. Ensuite, si l'une des instances de base de données échoue, vous pouvez reprendre la réplication à partir d'une autre instance de base de données saine au sein du cluster. Pour plus d'informations, consultez la section Réplication avec des identifiants de transaction globaux
RDS for PostgreSQL
Pour configurer la réplication externe pour un cluster de bases de données multi-AZ RDS pour PostgreSQL, vous devez activer la réplication logique. Pour obtenir des instructions, veuillez consulter Utilisation de la réplication logique PostgreSQL avec les clusters de bases de données multi-AZ.
Retard de réplica et clusters de base de données multi-AZ
Le retard de réplica est la différence de temps entre la dernière transaction au niveau de l'instance de base de données d'enregistreur et la dernière transaction appliquée sur une instance de base de données de lecteur. La CloudWatch métrique Amazon ReplicaLag représente ce décalage horaire. Pour plus d'informations sur CloudWatch les métriques, consultezSurveillance des métriques RDS avec Amazon CloudWatch.
Bien que les clusters de base de données Multi-AZ permettent des performances d'écriture élevées, un retard de réplica peut toujours se produire en raison de la nature de la réplication basée sur le moteur. Étant donné que tout basculement doit d'abord résoudre le retard du réplica avant de promouvoir une nouvelle instance de base de données d'enregistreur, la surveillance et la gestion de ce retard de réplica sont à prendre en compte.
Pour les clusters de base de données Multi-AZ RDS for MySQL, le temps de basculement dépend du décalage de réplica des deux instances de base de données de lecteur restantes. Les deux instances de base de données de lecteur doivent appliquer des transactions non appliquées avant que l'une d'elles ne soit promue vers la nouvelle instance de base de données de rédacteur.
Pour les clusters de bases de données Multi-AZ RDS for PostgreSQL, le temps de basculement dépend du décalage de réplica le plus bas des deux instances de bases de données de lecture restantes. L'instance de base de données de lecteur ayant le plus faible décalage de réplica doit appliquer les transactions non appliquées avant d'être promue en tant que nouvelle instance de base de données de rédacteur.
Pour un didacticiel expliquant comment créer une CloudWatch alarme lorsque le délai de réplication dépasse une durée définie, voirDidacticiel : Création d'une alarme Amazon CloudWatch pour un décalage de réplica de cluster de bases de données Multi-AZ.
Causes courantes du retard de réplica
En général, le retard de réplica se produit lorsque la charge de travail en écriture est trop élevée pour que les instances de base de données du lecteur puissent appliquer efficacement les transactions. Diverses charges de travail peuvent entraîner un retard de réplica temporaire ou continu. Voici quelques exemples de causes courantes :
-
Une concurrence d'écriture élevée ou une mise à jour par lots lourde sur l'instance de base de données de l'enregistreur, ce qui entraîne un retard du processus d'application sur les instances de base de données du lecteur.
-
Une charge de travail de lecture lourde qui utilise des ressources sur une ou plusieurs instances de base de données du lecteur. L'exécution de requêtes lentes ou volumineuses peut affecter le processus d'application et entraîner un retard de réplica.
-
Les transactions qui modifient de grandes quantités de données ou d'instructions DDL peuvent parfois entraîner une augmentation temporaire du retard de réplica, car la base de données doit préserver l'ordre de validation.
Atténuation du retard de réplica
Pour les clusters de base de données multi-AZ pour RDS for MySQL et RDS for PostgreSQL, vous pouvez réduire le retard de réplica en réduisant la charge sur votre instance de base de données d'enregistreur. Vous pouvez également utiliser le contrôle de flux pour réduire le décalage de réplica. Le contrôle de flux fonctionne en limitant les écritures sur l'instance de base de données d'enregistreur, ce qui garantit que le retard de réplica ne continue pas à augmenter sans limite. La limitation des écritures est obtenue en ajoutant un délai à la fin d'une transaction, ce qui réduit le débit d'écriture sur l'instance de base de données d'enregistreur. Bien que le contrôle de flux ne garantit pas l'élimination du retard, il peut contribuer à réduire le retard global pour de nombreuses charges de travail. Les sections suivantes fournissent des informations sur l'utilisation du contrôle de flux avec RDS for MySQL et RDS for PostgreSQL.
Atténuation du décalage de réplica avec le contrôle de flux pour RDS for MySQL
Lorsque vous utilisez les clusters de bases de données Multi-AZ RDS for PostgreSQL, le contrôle de flux est activé par défaut à l'aide du paramètre dynamique rpl_semi_sync_master_target_apply_lag. Ce paramètre spécifie la limite supérieure souhaitée pour le décalage du réplica. Lorsque le délai de réplication approche de cette limite configurée, le contrôle de flux limite les transactions d'écriture sur l'instance de base de données du rédacteur pour essayer de contenir le décalage de réplication en dessous de la valeur spécifiée. Dans certains cas, le décalage de réplica peut dépasser la limite spécifiée. Par défaut, ce paramètre est défini à 120 secondes. Pour désactiver le contrôle du flux, réglez ce paramètre sur sa valeur maximale de 86 400 secondes (un jour).
Pour afficher le délai de courant injecté par le contrôle de flux, affichez le paramètre Rpl_semi_sync_master_flow_control_current_delay en exécutant la requête suivante.
SHOW GLOBAL STATUS like '%flow_control%';
Votre sortie doit ressembler à ce qui suit :
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)Note
Le délai est affiché en microsecondes.
Lorsque Performance Insights est activé pour un cluster de bases de données Multi-AZ RDS for MySQL, vous pouvez surveiller l'événement d'attente correspondant à une instruction SQL indiquant que les requêtes ont été retardées par un contrôle de flux. Lorsqu'un délai a été introduit par un contrôle de flux, vous pouvez afficher l'événement d'attente /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond correspondant à l'instruction SQL du tableau de bord Performance Insights. Pour afficher ces métriques, assurez-vous que le schéma de performances est activé. Pour plus d'informations sur Performance Insights, veuillez consulter Surveillance de la charge de base de données avec Performance Insights sur RDSAmazon.
Atténuation du décalage de réplica avec le contrôle de flux pour RDS for PostgreSQL
Lorsque vous utilisez les clusters de base de données Multi-AZ RDS for PostgreSQL, le contrôle de flux est déployé en tant qu'extension. Il active un processus de travail en arrière-plan pour toutes les instances de base de données du cluster de base de données. Par défaut, les processus de travail en arrière-plan sur les instances de base de données de lecteur communiquent le retard actuel du réplica avec le processus de travail en arrière-plan sur l'instance de base de données d'enregistreur. Si le retard dépasse deux minutes sur n'importe quelle instance de base de données de lecteur, le processus de travail en arrière-plan de l'instance de base de données d'enregistreur ajoute un délai à la fin d'une transaction. Pour contrôler le seuil de retard, utilisez le paramètre flow_control.target_standby_apply_lag.
Lorsqu'un contrôle de flux limite un processus PostgreSQL, l'événement d'attente Extension dans pg_stat_activity et Performance Insights l'indique. La fonction get_flow_control_stats affiche des détails sur le délai actuellement ajouté.
Le contrôle de flux peut bénéficier à la plupart des charges de travail de traitement transactionnel en ligne (OLTP) ayant des transactions courtes mais très concurrentes. Si le retard est causé par des transactions de longue durée, telles que des opérations par lots, le contrôle de flux n'offre pas un avantage aussi important.
Vous pouvez désactiver le contrôle de flux en supprimant l'extension de shared_preload_libraries et en redémarrant votre instance de base de données.
Processus de basculement des clusters de base de données multi-AZ
En cas d'arrêt planifié ou non planifié de votre instance de base de données de rédacteur dans un cluster de base de données Multi-AZ, Amazon RDS bascule automatiquement sur une instance de base de données de lecteur dans une zone de disponibilité différente. La durée du basculement dépend de l'activité de base de données et d'autres conditions au moment où l'instance de base de données d'écriture est devenue indisponible. Les durées de basculement sont généralement inférieures à 35 secondes. Le basculement se termine lorsque les deux instances de base de données de lecture ont appliqué les transactions en suspens de l'instance d'écriture défaillante. Lorsque le basculement est terminé, un temps supplémentaire peut être nécessaire pour que la console RDS reflète la nouvelle zone de disponibilité.
Rubriques
Basculements automatiques
Étant donné qu'Amazon RDS gère automatiquement les basculements, vous pouvez reprendre les opérations de base de données aussi rapidement que possible sans intervention administrative. Pour basculer, l'instance de base de données d'écriture bascule automatiquement sur une instance de base de données de lecture.
Basculement manuel d'un cluster de base de données multi-AZ
Si vous basculez manuellement sur un cluster de base de données multi-AZ, RDS met d'abord fin à l'instance de base de données principale. Ensuite, le système de surveillance interne détecte que l'instance de base de données principale est défectueuse et promeut une instance de base de données de réplique lisible. Les durées de basculement sont généralement inférieures à 35 secondes.
Vous pouvez basculer manuellement sur un cluster de base de données multi-AZ à l'aide de l' AWS Management Console API, de AWS CLI, ou de l'API RDS.
Pour faire basculer manuellement un cluster de base de données multi-AZ
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/rds/
. -
Dans le panneau de navigation, choisissez Databases (Bases de données).
-
Choisissez le cluster de base de données multi-AZ que vous voulez faire basculer.
-
Pour Actions, choisissez Failover (Basculement).
La page Failover DB Cluster s'affiche.
-
Choisissez Failover (Basculement) pour confirmer le basculement manuel.
Pour basculer manuellement sur un cluster de base de données multi-AZ, utilisez la AWS CLI commande failover-db-cluster.
aws rds failover-db-cluster --db-cluster-identifiermymultiazdbcluster
Pour faire basculer manuellement un cluster de base de données multi-AZ, appelez l'opération FailoverDBCluster de l'API Amazon RDS et spécifiez DBClusterIdentifier.
Déterminer si un cluster de base de données multi-AZ a basculé
Pour déterminer si votre cluster de base de données multi-AZ a basculé, voici ce que vous pouvez faire :
Configurez les abonnements aux événements de base de données de sorte qu'ils vous notifient par e-mail ou SMS qu'un basculement a été initié. Pour plus d'informations sur les événements, consultez Utilisation des notifications d'RDSévénements Amazon.
Examinez vos événements de base de données à l'aide de la console Amazon RDS ou des opérations d'API.
Consultez l'état actuel de votre cluster de base de données multi-AZ à l'aide de la console Amazon RDS, de l'API et de l' AWS CLI API RDS.
Pour savoir comment répondre aux basculements, réduire le temps de récupération et découvrir d'autres bonnes pratiques pour Amazon RDS, consultez Bonnes pratiques pour Amazon RDS.
Configuration de la durée de vie de la JVM pour les recherches de nom DNS
Le mécanisme de basculement modifie automatiquement l'enregistrement DNS de l'instance de base de données pour pointer vers l'instance de base de données de lecture. Par conséquent, vous devez rétablir toutes les connexions existantes à votre instance de base de données. Dans un environnement de machine virtuelle Java, vous devrez peut-être reconfigurer les paramètres de votre machine virtuelle Java, en raison du fonctionnement du mécanisme de mise en cache Java du DNS.
La machine virtuelle Java met en cache les recherches de noms DNS. Lorsque la JVM convertit un nom d'hôte en adresse IP, elle met l'adresse IP en cache pendant une période spécifiée, connue sous le nom de time-to-live(TTL).
Étant donné que les AWS ressources utilisent des entrées de nom DNS qui changent occasionnellement, nous vous recommandons de configurer votre JVM avec une valeur TTL ne dépassant pas 60 secondes. De cette manière, lorsque l'adresse IP d'une ressource change, votre application peut recevoir et utiliser la nouvelle adresse IP de la ressource en interrogeant le DNS.
Dans certaines configurations Java, la durée de vie par défaut de la JVM est définie de façon à ce que la JVM n'actualise jamais les entrées DNS tant qu'elle n'est pas redémarrée. Ainsi, si l'adresse IP d'une AWS ressource change alors que votre application est toujours en cours d'exécution, elle ne peut pas utiliser cette ressource tant que vous n'avez pas redémarré manuellement la JVM et que les informations IP mises en cache ne sont pas actualisées. Dans ce cas, il est essentiel de définir la durée de vie de la JVM de façon à ce que ses informations IP mises en cache soient régulièrement actualisées.
Note
La durée de vie par défaut peut varier en fonction de la version de votre JVM et selon qu'un gestionnaire de sécurité est installé ou non. De nombreuses JVM fournissent une durée de vie par défaut de moins de 60 secondes. Si c'est le cas pour la JVM que vous utilisez et que vous n'avez pas recours à un gestionnaire de sécurité, vous pouvez ignorer le reste de cette rubrique. Pour de plus amples informations sur les responsables de la sécurité dans Oracle, veuillez consulter The Security Manager
Pour modifier la durée de vie de la JVM, définissez la valeur de la propriété networkaddress.cache.ttl
-
Pour définir globalement la valeur de la propriété pour toutes les applications qui utilisent la JVM, définissez
networkaddress.cache.ttldans le fichier$JAVA_HOME/jre/lib/security/java.security.networkaddress.cache.ttl=60 -
Pour définir la propriété localement pour votre application uniquement, définissez
networkaddress.cache.ttldans le code d'initialisation de votre application avant que les connexions réseau ne soient établies.java.security.Security.setProperty("networkaddress.cache.ttl" , "60");
Instantanés de clusters de bases de données multi-AZ
Amazon RDS crée et enregistre des sauvegardes automatisées de votre cluster de base de données multi-AZ pendant la fenêtre de sauvegarde configurée. RDS crée un instantané du volume de stockage de votre cluster de base de données, en sauvegardant l'ensemble du cluster et pas seulement les instances individuelles.
Vous pouvez également effectuer des sauvegardes manuelles de votre cluster de base de données multi-AZ. Pour les sauvegardes à très long terme, envisagez d'exporter les données des instantanés vers Amazon S3. Pour plus d’informations, consultez Création d'un instantané de cluster de bases de données multi-AZ.
Vous pouvez restaurer un cluster de base de données Multi-AZ à un moment précis dans le temps, en créant un nouveau cluster de base de données Multi-AZ. Pour obtenir des instructions, veuillez consulter Restauration d'un cluster de base de données multi-AZ à une date définie.
Vous pouvez également restaurer un instantané de cluster de base de données multi-AZ vers un déploiement mono-AZ ou un déploiement d'instance de base de données multi-AZ. Pour obtenir des instructions, consultez Restauration d'un instantané de cluster de bases de données multi-AZ dans une instance de base de données.
