Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation des réplicas en lecture d'instance de base de données
Un réplica en lecture est une copie en lecture seule d'une instance de base de données. Vous pouvez réduire la charge sur votre instance de base de données principale en acheminant les requêtes depuis vos applications vers le réplica en lecture. Ainsi, vous pouvez effectuer une montée en puissance élastique au-delà des contraintes de capacité d'une seule instance de base de données dans le cas de charges de travail de base de données à lecture intensive.
Pour créer un réplica en lecture à partir d'une instance de base de données source, Amazon RDS utilise les fonctions de réplication intégrées du moteur de base de données. Pour plus d'informations sur l'utilisation de réplicas en lecture avec un moteur spécifique, veuillez consulter les sections suivantes :
Après que vous avez créé un réplica en lecture à partir d'une instance de base de données source, la source devient l'instance de base de données principale. Lorsque vous apportez des mises à jour à l'instance de base de données principale, Amazon RDS les copie de manière asynchrone vers le réplica en lecture. Le schéma suivant montre une instance de base de données source effectuant la réplication vers un réplica en lecture dans une zone de disponibilité (AZ) différente. Les clients ont read/write accès à l'instance de base de données principale et ont un accès en lecture seule à la réplique.
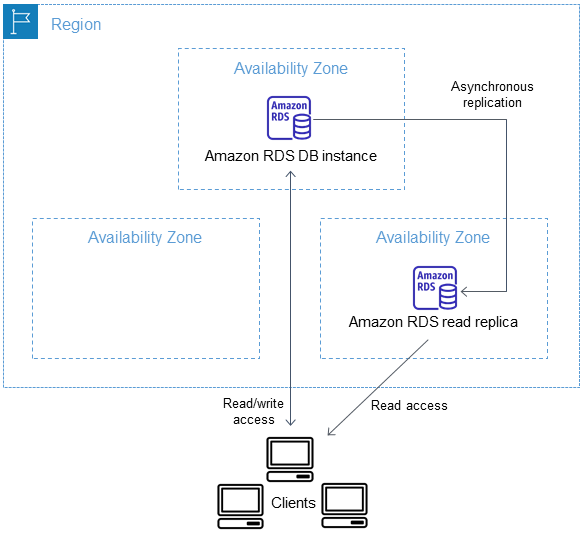
Les répliques de lecture sont facturées en tant qu'instances de base de données standard aux mêmes taux que la classe d'instance de base de données utilisée pour la réplique. Le transfert de données effectué lors de la réplication de données entre l'instance de base de données source et une réplique en lecture au sein de celle-ci Région AWS ne vous est pas facturé. Pour plus d’informations, consultez Coûts de la réplication entre régions et Facturation d'instance de base de données pour Amazon.
Rubriques
Présentation des réplicas en lecture Amazon RDS
Les sections ci-dessous traitent des réplicas en lecture d'une instance de base de données. Pour plus d'informations sur les réplicas en lecture d'un cluster de bases de données multi-AZ, consultez Utilisation de répliques de lecture de clusters de bases de données multi-AZ pour Amazon RDS.
Cas d'utilisation pour les réplicas en lecture
Le déploiement d'un ou de plusieurs réplicas en lecture pour une instance de bases de données source donnée peut être judicieux dans divers scénarios, notamment dans les suivants :
-
Extensibilité au-delà du calcul ou de la I/O capacité d'une seule instance de base de données pour les charges de travail de base de données gourmandes en lecture. Vous pouvez diriger ce trafic en lecture excessif vers un ou plusieurs réplicas en lecture.
-
Service du trafic en lecture alors que l'instance de bases de données source est indisponible. Dans certains cas, votre instance de base de données source peut ne pas être en mesure de répondre aux I/O demandes, par exemple en raison d'une suspension des E/S pour les sauvegardes ou d'une maintenance planifiée. Vous pouvez alors diriger le trafic de lecture vers vos réplicas en lecture. Dans ce cas d'utilisation, gardez à l'esprit que les données sur le réplica en lecture peuvent être « périmées » car l'instance de bases de données source est indisponible.
-
Scénarios de création de rapports commerciaux ou d'entreposage de données, dans lesquels vous pouvez souhaiter que les requêtes de rapports commerciaux s'exécutent sur un réplica en lecture, plutôt que sur votre instance de bases de données de production.
-
Mise en œuvre de la reprise après sinistre. Vous pouvez effectuez la promotion d'un réplica en lecture en instance autonome comme plan de reprise après sinistre en cas de défaillance de l'instance de base de données principale.
Fonctionnement des réplicas en lecture
Lorsque vous créez une réplique en lecture, vous spécifiez une instance de base de données existante comme source. Ensuite, Amazon RDS prend un instantané de l'instance source et crée une instance en lecture seule à partir de celui-ci. Amazon RDS utilise la méthode de réplication asynchrone pour le moteur de base de données afin de mettre à jour le réplica en lecture chaque fois qu'une modification est apportée à l'instance de base de données principale.
La réplique en lecture fonctionne comme une instance de base de données qui autorise uniquement les connexions en lecture seule. Les exceptions sont le RDS pour DB2 et le RDS pour les moteurs de base de données Oracle, qui prennent en charge les répliques de bases de données en mode veille et en mode monté, respectivement. Une réplique en veille et une réplique montée n'acceptent pas les connexions utilisateur et ne peuvent donc pas prendre en charge les charges de travail en lecture seule. Les répliques de secours et les répliques montées sont principalement utilisées pour la reprise après sinistre entre régions. Pour plus d’informations, consultez Utilisation de répliques pour Amazon RDS pour DB2 et Utilisation de réplicas en lecture pour Amazon RDS for Oracle.
Les applications se connectent à un réplica en lecture de la même façon qu'à toute instance de base de données. Amazon RDS réplique toutes les bases de données à partir de l'instance de base de données source.
Vous devez créer manuellement des répliques de lecture. RDS ne prend pas en charge le dimensionnement automatique des répliques de lecture, qui consiste à ajouter ou à supprimer automatiquement des répliques de lecture lorsque la demande de lecture change.
Réplicas en lecture dans un déploiement multi-AZ
Vous pouvez configurer un réplica en lecture pour une instance de base de données disposant également d'un réplica de secours configuré pour la haute disponibilité dans un déploiement multi-AZ. La réplication avec le réplica de secours est synchrone. Contrairement à un réplica en lecture, un réplica de secours ne peut pas servir au trafic de lecture.
Dans le scénario suivant, les clients ont read/write accès à une instance de base de données principale dans une zone de disponibilité. L'instance principale copie les mises à jour de manière asynchrone vers un réplica en lecture dans une deuxième zone de disponibilité et les copie également de manière synchrone vers un réplica de secours dans une troisième zone de disponibilité. Les clients possèdent un accès en lecture uniquement au réplica en lecture.
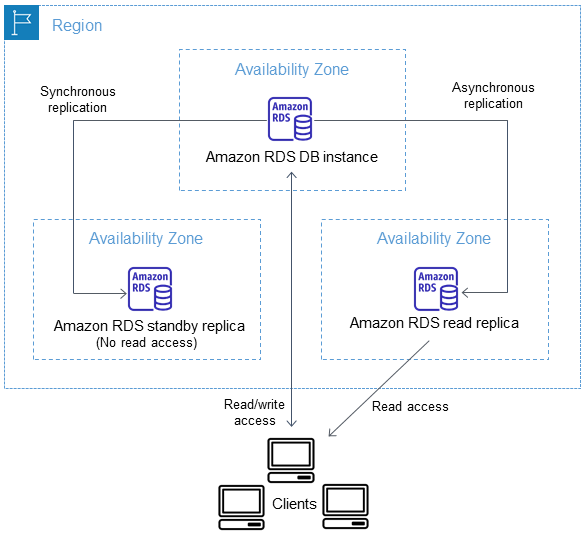
Pour plus d'informations sur les réplicas de secours configurés pour une haute disponibilité, consultez Configuration et gestion d'un déploiement multi-AZ pour Amazon RDS.
Réplicas en lecture entre Régions
Dans certains cas, une réplique en lecture réside dans une instance de base de données Région AWS différente de son instance de base de données principale. Dans ces cas, Amazon RDS configure un canal de communication sécurisé entre l'instance de base de données principale et le réplica en lecture. Amazon RDS établit toutes les configurations AWS de sécurité nécessaires pour activer le canal sécurisé, telles que l'ajout d'entrées de groupe de sécurité. Pour plus d'informations sur les réplicas en lecture entre régions, veuillez consulter Création d'un réplica en lecture dans une autre Région AWS.
Les informations de ce chapitre s'appliquent à la création de répliques de lecture Amazon RDS, soit dans la même Région AWS instance de base de données source, soit dans une instance séparée. Région AWS Les informations suivantes ne s'appliquent pas à la configuration de la réplication avec une instance exécutée sur une EC2 instance Amazon ou sur site.
Types de stockage de réplica en lecture
Par défaut, un réplica en lecture est créé avec le même type de stockage que l'instance de bases de données source. Toutefois, vous pouvez créer un réplica en lecture disposant d'un autre type de stockage que l'instance de bases de données source, en fonction des options répertoriées dans le tableau suivant.
| Type de stockage de l'instance de bases de données source | Allocation de stockage d'instance de bases de données source | Options de type de stockage du réplica en lecture |
|---|---|---|
| IOPS provisionnés | 100 Gio–64 Tio | IOPS provisionnés, usage général, magnétique |
| Usage général | 100 Gio–64 Tio | IOPS provisionnés, usage général, magnétique |
| Usage général | <100 Gio | Usage général, magnétique |
| Magnétique | 100 Gio - 6 Tio | IOPS provisionnés, usage général, magnétique |
| Magnétique | <100 Gio | Usage général, magnétique |
Note
Lorsque vous augmentez le stockage alloué d'un réplica en lecture, il doit être d'au moins 10 %. Si vous tentez d'augmenter la valeur de moins de 10 %, une erreur s'affiche.
Restrictions relatives à la création d'un réplica à partir d'un réplica
Amazon RDS ne prend pas en charge la réplication circulaire. Vous ne pouvez pas configurer une instance de base de données afin de l'utiliser comme source de réplication pour une instance de base de données existante. Vous pouvez uniquement créer un nouveau réplica en lecture à partir d'une instance de base de données existante. Par exemple, si MySourceDBInstance est répliqué sur ReadReplica1, vous ne pouvez pas configurer ReadReplica1 de façon à ce qu'il soit répliqué sur MySourceDBInstance.
Pour RDS for MariaDB et RDS for MySQL, et pour certaines versions de RDS for PostgreSQL, vous pouvez créer un réplica en lecture à partir d'un réplica en lecture existant. Par exemple, vous pouvez créer un nouveau réplica en lecture ReadReplica2 à partir d'un réplica ReadReplica1 existant. Pour RDS pour DB2, RDS pour Oracle et RDS pour SQL Server, vous ne pouvez pas créer de réplique en lecture à partir d'une réplique en lecture existante.
Considérations relatives à la suppression de réplicas
RDS ne prend pas en charge le dimensionnement automatique des répliques de lecture. Ainsi, RDS n'augmentera pas le nombre de répliques lorsque la demande augmente ou ne diminuera pas le nombre de répliques lorsque la demande diminue. Si vous n'avez plus besoin de répliques de lecture, supprimez-les manuellement en utilisant les mêmes mécanismes que ceux utilisés pour supprimer une instance de base de données. Si vous supprimez une instance de base de données source sans supprimer ses répliques de lecture Région AWS, chaque réplique est promue en instance de base de données autonome.
Pour plus d'informations sur la création d'une instance de base de données, veuillez consulter Suppression d'une instance DB. Pour plus d'informations sur la promotion d'un réplica en lecture, veuillez consulter Promotion d'un réplica en lecture en instance de bases de données autonome. Pour plus d'informations sur la suppression de l'instance de base de données source pour une réplique de lecture entre régions, consultezConsidérations liées à la réplication entre régions.
