Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques relatives à Amazon RDS.
Découvrez les bonnes pratiques d'utilisation de Amazon RDS. Nous mettrons à jour cette section à mesure que de nouvelles bonnes pratiques seront identifiées.
Rubriques
Utilisation de la surveillance améliorée pour identifier les problèmes de système d'exploitation
Utilisation des métriques pour identifier les problèmes de performances
Bonnes pratiques pour utiliser les moteurs de stockage PostgreSQL
Bonnes pratiques pour automatiser la création d'instances de base de données
Note
Pour obtenir des recommandations communes pour Amazon RDS, consultez Recommandations d’Amazon RDS.
Directives opérationnelles de base Amazon RDS
Voici les directives opérationnelles de base que toute personne doit suivre lorsqu'elle utilise Amazon RDS. Notez que le contrat de niveau de service (SLA) Amazon RDS exige que vous suiviez ces directives :
-
Utilisez des métriques pour surveiller votre mémoire, votre processeur, votre retard de réplica et votre utilisation du stockage. Vous pouvez configurer Amazon CloudWatch pour qu'il vous avertisse lorsque les habitudes d'utilisation changent ou lorsque votre déploiement approche des limites de capacité. Cela vous permet de maintenir les performances et la disponibilité du système.
-
Augmentez la capacité de votre instance de base de données lorsque vous atteignez la limite de stockage. Vous devrez disposer de capacités de mémoire et de stockage supplémentaires pour vous adapter aux hausses imprévues des besoins de vos applications.
-
Activez les sauvegardes automatiques et configurez-les pour qu'elles s'exécutent pendant la plus faible I/O par seconde en écriture de la journée. C'est à ce moment qu'une sauvegarde perturbe le moins l'utilisation de votre base de données.
-
Si la charge de travail de votre base de données est I/O supérieure à ce que vous avez provisionné, la restauration après un basculement ou une défaillance de la base de données sera lente. Pour augmenter la I/O capacité d'une instance de base de données, effectuez l'une ou l'ensemble des opérations suivantes :
Migrez vers une autre classe d'instance de base de données à haute I/O capacité.
Passez du stockage magnétique au stockage à usage général ou au stockage à IOPS provisionnées, suivant l'augmentation dont vous avez besoin. Pour plus d'informations sur les types de stockage disponibles, consultez Types de stockage Amazon RDS.
Si vous passez au stockage à IOPS provisionnées, veillez que vous utilisez également une classe d'instance de base de données optimisée pour les IOPS provisionnées. Pour plus d'informations sur les IOPS provisionnées, consultez Stockage SSD à IOPS provisionnées.
Si vous utilisez déjà un stockage d'IOPS provisionnées, allouez un débit supplémentaire.
-
Si votre application cliente met en cache les données DNS (Domain Name Service) de vos instances de base de données, définissez une valeur time-to-live (TTL) inférieure à 30 secondes. L’adresse IP sous-jacente d’une instance de base de données peut changer après un basculement. La mise en cache des données DNS pendant une période prolongée peut donc entraîner des échecs de connexion. Il se peut que votre application essaie de se connecter à une adresse IP qui n'est plus en service.
-
Testez le basculement pour votre instance de base de données afin de connaître la durée du processus pour votre cas d'utilisation particulier. Le basculement permet également de veiller à ce que l'application qui accède à votre instance de base de données puisse automatiquement se connecter à la nouvelle instance de base de données suite au basculement.
Recommandations RAM d'une instance de base de données
Une bonne pratique Amazon RDS en matière de performances consiste à attribuer suffisamment de RAM pour que votre ensemble de travail réside presque totalement en mémoire. L'ensemble de travail est les données et les index fréquemment utilisés sur votre instance. Plus vous utilisez l'instance de base de données, plus l'ensemble de travail se développera.
Pour savoir si votre ensemble de travail est presque entièrement en mémoire, vérifiez la métrique ReadiOps (à l'aide d' CloudWatchAmazon) lorsque l'instance de base de données est en charge. La valeur d'I/O par seconde en lecture doit être faible et stable. Dans certains cas, l'augmentation de la classe d'instance de base de données vers une classe disposant de davantage de mémoire RAM entraîne une chute spectaculaire de ReadIOPS. Dans ces cas, votre ensemble de travail n'était pas presque entièrement en mémoire. Continuez à augmenter jusqu'à ce que la valeur d'I/O par seconde en lecture ne chute plus de façon spectaculaire suite à une opération de dimensionnement, ou qu'elle soit réduite au minimum. Pour plus d'informations sur la supervision des métriques d'une instance de base de données, consultez Affichage des métriques dans la console Amazon RDS.
Maintien à jour des versions du moteur de base de données
Mettez régulièrement à niveau la version de votre moteur de base de données pour garantir la sécurité, les performances et la conformité. Amazon RDS publie de nouvelles versions mineures et majeures de l’environnement qui incluent des correctifs de sécurité, des améliorations de la performance et de nouvelles fonctionnalités. L'utilisation d'un moteur de base de données obsolète peut exposer vos charges de travail à des vulnérabilités connues, à des problèmes de compatibilité et à une assistance réduite de la part des fournisseurs de bases de données et de la part des AWS fournisseurs de bases de données.
Pour minimiser les perturbations, tenez compte des points suivants lorsque vous planifiez des mises à niveau :
-
Effectuez des tests dans un environnement intermédiaire : validez la nouvelle version par rapport à votre charge de travail avant de mettre à niveau les bases de données de production.
-
Utilisez les mises à niveau gérées par Amazon RDS : activez les mises à niveau automatiques des versions mineures pour faciliter l’application des correctifs.
-
Planifiez les mises à niveau des versions majeures : consultez les notes de mise à jour, testez la compatibilité des applications et planifiez une fenêtre de mise à niveau contrôlée.
Des mises à niveau régulières permettent de garantir que votre base de données reste sécurisée, optimisée et conforme aux bonnes pratiques AWS .
AWS pilotes de base de données
Nous recommandons la AWS suite de pilotes pour la connectivité des applications. Les pilotes ont été conçus pour accélérer les temps de basculement et de basculement, ainsi que pour l'authentification avec AWS Secrets Manager, Gestion des identités et des accès AWS (IAM) et l'identité fédérée. Les pilotes AWS s’appuient sur la surveillance de l’état de l’instance de base de données et sur la connaissance de la topologie de l’instance pour déterminer le nouvel enregistreur. Cette approche réduit les temps de bascule et de basculement à moins de 10 secondes, contre des dizaines de secondes pour les pilotes open source.
À mesure que de nouvelles fonctionnalités de service sont introduites, l'objectif de la AWS suite de pilotes est de fournir un support intégré pour ces fonctionnalités de service.
Pour de plus amples informations, veuillez consulter Connexion aux instances de base de données avec les AWS pilotes.
Utilisation de la surveillance améliorée pour identifier les problèmes de système d'exploitation
Lorsque la surveillance améliorée est activée, Amazon RDS fournit des métriques en temps réel pour le système d’exploitation sur lequel votre instance de base de données s’exécute. Vous pouvez afficher les métriques de votre instance de base de données à l'aide de la console. Vous pouvez également utiliser la sortie JSON Enhanced Monitoring d'Amazon CloudWatch Logs dans le système de surveillance de votre choix. Pour plus d'informations sur la surveillance améliorée, consultez la section Surveillance des métriques du système d’exploitation à l’aide de la Surveillance améliorée.
Utilisation des métriques pour identifier les problèmes de performances
Pour identifier les problèmes de performances causés par des ressources insuffisantes et d'autres goulots d'étranglement courants, vous pouvez surveiller les métriques disponibles pour votre instance de base de données Amazon RDS.
Consultation des métriques de performances
Vous devez régulièrement surveiller les métriques de performances pour observer les valeurs moyennes, maximum et minimum pour différents intervalles de temps. De cette façon, vous pouvez identifier quand les performances se dégradent. Vous pouvez également définir des CloudWatch alarmes Amazon pour des seuils métriques spécifiques afin d'être alerté s'ils sont atteints.
Pour résoudre les problèmes de performances, il est important de comprendre les performances de base du système. Lorsque vous configurez une instance de base de données et que vous l'exécutez avec une charge de travail classique, capturez les valeurs moyenne, maximale et minimale de toutes les mesures de performance. Faites-le à différents intervalles (par exemple, une heure, 24 heures, une semaine, deux semaines). Cela vous permet de vous faire une idée de ce qui est normal. Cela permet de comparer l'activité pendant les heures pleines et les heures creuses. Vous pouvez ensuite utiliser ces informations pour identifier quand les performances chutent sous les niveaux standard.
Pour les clusters de bases de données multi-AZ, surveillez la différence de temps entre la dernière transaction sur l'instance de base de données de rédacteur et la dernière transaction appliquée sur une instance de base de données de lecteur. Cette différence s'appelle décalage (retard) de réplica. Pour de plus amples informations, veuillez consulter Retard de réplica et clusters de base de données multi-AZ.
Vous pouvez consulter les CloudWatch statistiques et les statistiques combinées dans le tableau de bord Performance Insights et surveiller votre instance de base de données. Si vous souhaitez utiliser cette vue de surveillance, Performance Insights doit être activé pour votre instance de base de données. Pour obtenir des informations sur cette vue de surveillance, consultez Affichage des métriques combinées avec le tableau de bord Performance Insights.
Vous pouvez créer un rapport d’analyse des performances pour une période spécifique et consulter les informations identifiées et les recommandations pour résoudre les problèmes. Pour plus d’informations, consultez Création d’un rapport d’analyse des performances dans Performance Insights.
Pour consulter les métriques de performances
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. Dans le panneau de navigation, sélectionnez Bases de données, choisissez une instance de base de données.
Choisissez Surveillance.
Le tableau de bord fournit les métriques de performances. Les métriques affichent par défaut les informations des trois dernières heures.
Utilisez les boutons numérotés dans l'angle supérieur droit de la page pour parcourir les autres métriques ou ajustez les paramètres pour consulter d'autres métriques.
Choisissez une métrique de performances pour régler l'intervalle de temps afin de consulter d'autres données que celles du jour même. Vous pouvez changer les valeurs Statistic (Statistique), Time Range (Plage de temps) et Period (Période) pour régler les informations affichées. Par exemple, vous pouvez consulter les valeurs maximales d'une métrique pour chaque jour des deux dernières semaines. Si tel est le cas, définissez Statistic (Statistiques) sur Maximum, Time Range (Plage de temps) sur Last 2 Weeks (Deux dernières semaines) et Period (Période) sur Day (Jour).
Vous pouvez également consulter les métriques de performances à l'aide de la CLI ou de l'API. Pour de plus amples informations, veuillez consulter Affichage des métriques dans la console Amazon RDS.
Pour régler une CloudWatch alarme
-
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le panneau de navigation, sélectionnez Bases de données, choisissez une instance de base de données.
-
Choisissez Logs & events (Journaux et événements).
-
Dans la section CloudWatch des alarmes, choisissez Créer une alarme.
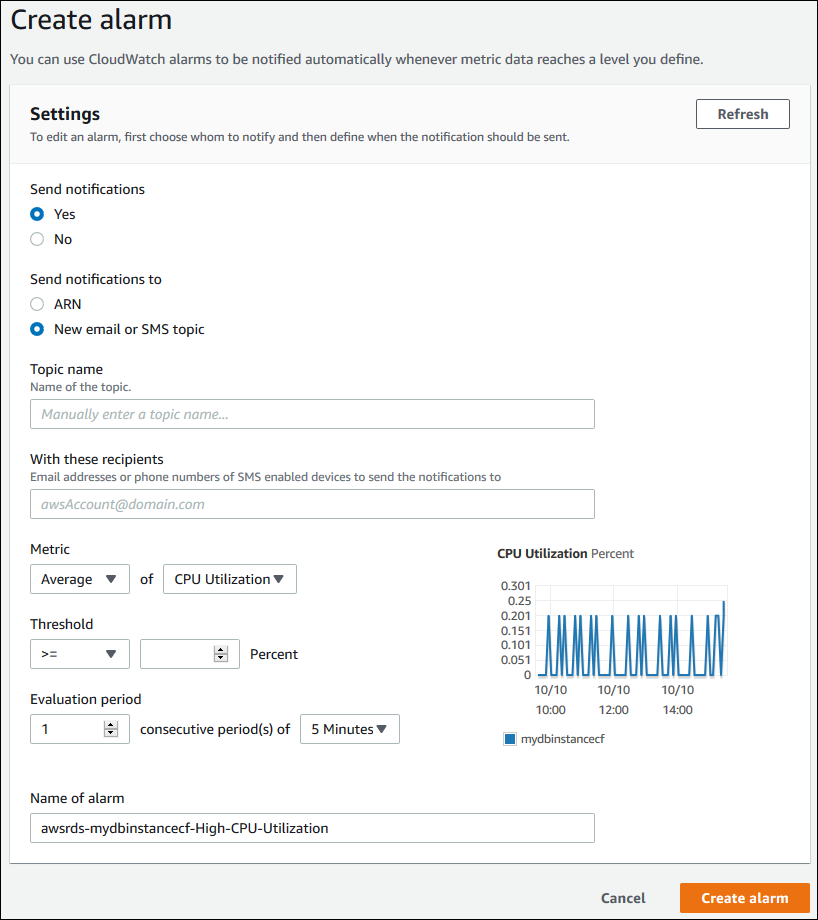
-
Pour Envoyer des notifications, choisissez Oui et pour Envoyer des notifications à, choisissez New email or SMS topic (Nouvel e-mail ou nouvelle rubrique SMS).
-
Dans Nom de la rubrique, entrez un nom pour la notification, et pour Avec ces destinataires, entrez une liste séparée par des virgules d'adresses e-mail et de numéros de téléphone.
-
Pour Métrique, choisissez la statistique et la métrique d'alarme à définir.
-
Pour Seuil, indiquez si la métrique doit être supérieure, inférieure ou égale au seuil, et définissez la valeur du seuil.
-
Sous Evaluation period (Période d'évaluation), choisissez la période d'évaluation de l'alarme. Pour consecutive period(s) of (Période(s) consécutive(s) de), choisissez la durée pendant laquelle le seuil doit avoir été atteint pour déclencher l'alarme.
-
Pour Name of alarm (Nom de l'alarme), entrez un nom pour l'alarme.
-
Sélectionnez Create Alarm (Créer une alerte).
L'alarme apparaît dans la section des CloudWatch alarmes.
Évaluation des métriques de performances
Une instance de base de données possède un nombre de catégories différentes de métriques, et la manière de déterminer les valeurs acceptables dépend de la métrique.
CPU
Utilisation du processeur : pourcentage de capacité de traitement informatique utilisée.
Mémoire
-
Mémoire libérable : combien de RAM est disponible sur l’instance de base de données, en octets. La ligne rouge des métriques de l'onglet Monitoring est marqué à 75 % pour les métriques d'UC, de mémoire et de stockage. Si la consommation de la mémoire de l'instance franchit régulièrement cette ligne, cela indique que vous devez vérifier votre charge de travail ou mettre à niveau votre instance.
Utilisation de l’échange : combien d’espace d’échange est utilisé par l’instance de base de données, en octets.
Espace disque
Espace de stockage libre : combien d'espace disque n'est pas utilisé actuellement par l'instance de base de données, en octets.
Opérations d'entrée/sortie
E/S par seconde en lecture, E/S par seconde en écriture : le nombre moyen d'opérations de lecture ou d'écriture sur disque par seconde.
Latence de lecture, latence d'écriture : la durée moyenne d'une opération de lecture ou d'écriture en millisecondes.
Débit de lecture, débit d'écriture : le nombre moyen d'octets lus depuis un disque ou écrits sur un disque par seconde.
Profondeur de la file d'attente : nombre d' I/O opérations en attente d'écriture ou de lecture sur le disque.
Trafic réseau
Débit réseau reçu, débit réseau transmis : – la vitesse du trafic réseau vers et depuis l'instance de base de données en octets par seconde.
Connexions de la base de données
Connexions DB : le nombre de sessions client qui sont connectées à l'instance de base de données.
Pour des descriptions individuelles plus détaillées des métriques de performances disponibles, consultez Surveillance des métriques Amazon RDS () avec Amazon CloudWatch.
En général, les valeurs acceptables pour les métriques de performances dépendent de vos données de référence et de l'activité de votre application. Enquêtez sur les écarts cohérents ou tendanciels de vos données de référence. Voici quelques conseils sur les types spécifiques de métriques :
Forte utilisation de l'UC et de la RAM – Des valeurs importantes de l'utilisation de l'UC ou de la RAM peuvent être appropriées. Par exemple, elles peuvent être élevées si elles sont conformes aux objectifs pour votre application (comme le débit ou la simultanéité) et sont attendues.
Utilisation de l'espace disque – Enquêtez sur l'utilisation de l'espace disque si l'espace utilisé est constamment égal ou supérieur à 85 pour cent de l'espace disque total. Voyez s’il est possible de supprimer des données de l’instance ou d’archiver des données sur un système différent pour libérer de l’espace.
Trafic réseau : pour le trafic réseau, discutez avec votre administrateur pour connaître le débit attendu pour votre domaine réseau et votre connexion Internet. Enquêtez sur le trafic réseau si le débit est constamment inférieur à vos attentes.
Connexions de la base de données – Envisagez de limiter les connexions de la base de données si vous constatez un nombre important de connexions utilisateur conjointement avec une baisse des performances de l'instance et des temps de réponse. Le bon nombre de connexions utilisateur pour votre instance de base de données dépendra de votre classe d'instance et de la complexité des opérations exécutées. Pour déterminer le nombre de connexions de la base de données, associez votre instance de base de données à un groupe de paramètres. Dans ce groupe, définissez le paramètre User Connections (Connexions utilisateurs) sur une valeur autre que 0 (illimitée). Vous pouvez utiliser un groupe de paramètres existant ou en créer un nouveau. Pour plus d’informations, consultez Groupes de paramètres pour Amazon RDS.
Métriques IOPS : les valeurs attendues pour les métriques d’IOPS dépendent de la spécification du disque et de la configuration du serveur, donc utilisez vos données de référence pour connaître les caractéristiques typiques. Enquêtez si les valeurs sont constamment différentes de vos données de référence. Pour de meilleures performances d'I/O par seconde, veillez à ce que votre ensemble de travail typique puisse être chargé en mémoire pour minimiser les opérations de lecture et écriture.
Pour les problèmes liés aux indicateurs de performance, la première étape pour améliorer les performances consiste à ajuster les requêtes les plus utilisées et les plus coûteuses. Ajustez-les pour voir si cela réduit la pression sur les ressources du système. Pour plus d’informations, consultez Réglage des requêtes.
Si vos requêtes sont ajustées et qu'un problème persiste, pensez à mettre à niveau votre Amazon RDS Classes d'instances de base de données . Vous pouvez le mettre à niveau vers un autre avec une plus grande partie des ressources (processeur, RAM, espace disque, bande passante réseau, I/O capacité) associées au problème.
Réglage des requêtes
L'un des meilleurs moyens d'améliorer les performances d'une instance de base de données est d'ajuster les requêtes les plus communément utilisées et exigeantes en ressources. Ici, vous les ajustez pour les rendre moins onéreuses à utiliser. Pour plus d'informations sur l'amélioration des requêtes, utilisez les ressources suivantes :
-
MySQL : consultez Optimisation des instructions SELECT
dans la documentation MySQL. Pour des ressources supplémentaires de réglage des requêtes, vous pouvez également consulter MySQL Performance Tuning and Optimization Resources (Ressources d'optimisation et de réglage de performance MySQL) . -
Oracle : consultez Database SQL Tuning Guide (Guide de paramétrage SQL de base de données)
dans la documentation Oracle Database. -
SQL Server : consultez Analyse d’une requête
dans la documentation Microsoft. Vous pouvez également utiliser les vues de gestion des données relatives à l'exécution, à l'index et aux E/S (DMVs) décrites dans la section Vues de gestion dynamique du système de la documentation Microsoft pour résoudre les problèmes liés aux requêtes SQL Server. Un aspect courant du réglage de requête est la création d'index efficaces. Pour des améliorations potentielles de l'index de votre instance de base de données, consultez Assistant Paramétrage du moteur de base de données
dans la documentation Microsoft. Pour plus d'informations sur l'utilisation de l’Assistant Paramétrage sur RDS for SQL Server, consultez Analyse de la charge de travail d'une base de données sur une instance de base de données Amazon RDS for SQL Server avec l'Assistant Paramétrage du moteur de base de données. -
PostgreSQL : consultez Using EXPLAIN (Utilisation de EXPLAIN)
dans la documentation PostgreSQL pour savoir comment analyser un plan de requête. Vous pouvez utiliser ces informations pour modifier une requête ou des tables sous-jacentes afin d'améliorer les performances des requêtes. Pour des informations sur la façon dont vous pouvez spécifier des jointures dans votre requête afin d’améliorer les performances, consultez Controlling the planner with explicit JOIN clauses (Contrôler le planificateur avec des clauses JOIN explicites)
. -
MariaDB : consultez Optimisations de requête
dans la documentation MariaDB.
Bonnes pratiques d'utilisation de MySQL
La taille et le nombre des tables contenues dans une base de données MySQL peuvent tous deux nuire aux performances.
Taille des tables
En règle générale, les contraintes imposées par le système d'exploitation sur la taille des fichiers déterminent la taille maximale effective des tables des bases de données MySQL. Par conséquent, les limites ne dépendent généralement pas de contraintes internes de MySQL.
Sur une instance de base de données MySQL, évitez que les tables de votre base de données deviennent trop volumineuses. Bien que la limite du stockage général soit de 64 Tio,les limites de stockage alloué réduisent la taille maximale d'un fichier de table MySQL à 64 To. Partitionnez vos tables volumineuses pour que la taille des fichiers soit inférieure à la limite de 16 To. Cette approche peut également améliorer les performances et le temps de récupération. Pour plus d’informations, consultez Limites de taille des fichiers MySQL dans Amazon RDS.
Les tables très volumineuses (de plus de 100 Go) peuvent nuire aux performances des lectures et écritures (y compris pour les instructions DML, et en particulier pour les instructions DDL). Sur les tables volumineuses, les index peuvent considérablement améliorer les performances de sélection, mais ils peuvent également dégrader les performances des instructions DML. Les instructions DDL, telles que ALTER TABLE, peuvent être significativement plus lentes pour les tables volumineuses car, dans certains cas, ces opérations peuvent entraîner une reconstitution totale des tables. Ces instructions DDL peuvent verrouiller les tables pendant toute la durée de l'opération.
La quantité de mémoire requise par MySQL pour les lectures et les écritures dépend des tables impliquées dans les opérations. Il est recommandé de disposer de suffisamment de RAM pour les index des tables activement utilisées. Pour rechercher les dix tables et index les plus volumineux d'une base de données, utilisez la requête suivante :
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Nombre de tables
Votre système de fichiers sous-jacent peut imposer des limites en termes de nombre de fichiers représentant les tables. Cependant, MySQL n'a aucune limite quant au nombre de tables. Cela dit, le nombre total de tables contenues dans le moteur de stockage MySQL InnoDB peut contribuer à la dégradation des performances, quelle que soit la taille de ces tables. Pour limiter l'impact sur le système d'exploitation, vous pouvez répartir les tables entre plusieurs bases de données de la même instance de base de données MySQL. Cela limitera éventuellement le nombre de fichiers contenus dans un répertoire mais ne résoudra pas le problème global.
Toute dégradation des performances liée à la présence d'un grand nombre de tables (plus de 10 000) est due au fait que MySQL intervient sur les fichiers de stockage, notamment sur leur ouverture et leur fermeture. Pour résoudre ce problème, vous pouvez augmenter la taille des paramètres table_open_cache et table_definition_cache. L'augmentation des valeurs de ces paramètres peut toutefois augmenter la quantité de mémoire utilisée par MySQL, voire utiliser toute la mémoire disponible. Pour plus d'informations, consultez Comment MySQL ouvre et ferme les tables
En outre, la présence d'un trop grand nombre de tables peut avoir un impact significatif sur le temps de démarrage de MySQL. L'arrêt et le redémarrage propres ainsi que la reprise sur incident peuvent être affectés, en particulier dans les versions antérieures à MySQL 8.0.
Nous recommandons de maintenir le nombre total de tables en dessous de 10 000 dans toutes les bases de données d'une instance de base de données. Un cas d'utilisation d'un grand nombre de tables dans une base de données MySQL est disponible dans la section Un million de tables dans MySQL 8.0
Moteur de stockage
Les fonctionnalités de point-in-time restauration et de restauration instantanée d'Amazon RDS for MySQL nécessitent un moteur de stockage récupérable en cas de panne. Ces fonctions sont uniquement prises en charge pour le moteur de stockage InnoDB. Bien que MySQL prenne en charge plusieurs moteurs de stockage avec diverses capacités, toutes ne sont pas optimisées pour la récupération sur incident et la durabilité des données. Par exemple, le moteur de stockage MyISAM ne prend pas en charge une restauration fiable en cas de panne et peut empêcher point-in-time une restauration ou une restauration instantanée de fonctionner comme prévu. Cela peut entraîner la perte ou la corruption de données lors du redémarrage de MySQL après un incident.
InnoDB est le moteur de stockage recommandé et pris en charge pour les instances de base de données MySQL sur Amazon RDS. Les instances InnoDB peuvent également être migrées vers Aurora, au contraire des instances MySQL. Toutefois, les performances de MyISAM sont meilleures qu'InnoDB si vous avez besoin de capacités intenses de recherche en texte intégral. Si vous choisissez d'utiliser MyISAM avec Amazon RDS, suivre les étapes décrites dans Sauvegardes automatiques avec moteurs de stockage MySQL non pris en charge peut être utile dans certaines situations pour la fonctionnalité de restauration d'instantané.
Si vous souhaitez convertir les tables MyISAM existantes en tables InnoDB, vous pouvez utiliser le processus décrit dans la section Converting Tables from MyISAM to InnoDB
De plus, Federated Storage Engine n'est pour l'instant pas pris en charge par Amazon RDS for MySQL.
Bonnes pratiques d'utilisation de MariaDB
La taille et le nombre des tables contenues dans une base de données MariaDB peuvent tous deux nuire aux performances.
Taille des tables
En règle générale, les contraintes imposées par le système d'exploitation sur la taille des fichiers déterminent la taille maximale effective des tables des bases de données MariaDB. Par conséquent, les limites ne dépendent généralement pas de contraintes internes de MariaDB.
Sur une instance de base de données MariaDB, veillez à ce que les tables de votre base de données ne deviennent pas trop volumineuses. Bien que la limite du stockage général soit de 64 Tio, les limites de stockage alloué réduisent la taille maximale d'un fichier de table MariaDB à 16 Tio. Partitionnez vos tables volumineuses pour que la taille des fichiers soit inférieure à la limite de 16 To. Cette approche peut également améliorer les performances et le temps de récupération.
Les tables très volumineuses (de plus de 100 Go) peuvent nuire aux performances des lectures et écritures (y compris pour les instructions DML, et en particulier pour les instructions DDL). Sur les tables volumineuses, les index peuvent considérablement améliorer les performances de sélection, mais ils peuvent également dégrader les performances des instructions DML. Les instructions DDL, telles que ALTER TABLE, peuvent être significativement plus lentes pour les tables volumineuses car, dans certains cas, ces opérations peuvent entraîner une reconstitution totale des tables. Ces instructions DDL peuvent verrouiller les tables pendant toute la durée de l'opération.
La quantité de mémoire requise par MariaDB pour les lectures et les écritures dépend des tables impliquées dans les opérations. Il est recommandé de disposer de suffisamment de RAM pour les index des tables activement utilisées. Pour rechercher les dix tables et index les plus volumineux d'une base de données, utilisez la requête suivante :
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Nombre de tables
Votre système de fichiers sous-jacent peut imposer des limites en termes de nombre de fichiers représentant les tables. Cependant, MariaDB n'a aucune limite quant au nombre de tables. Cela dit, le nombre total de tables contenues dans le moteur de stockage MariaDB InnoDB peut contribuer à la dégradation des performances, quelle que soit la taille de ces tables. Pour limiter l'impact sur le système d'exploitation, vous pouvez répartir les tables entre plusieurs bases de données de la même instance de base de données MariaDB. Cela limitera éventuellement le nombre de fichiers contenus dans un répertoire mais ne résoudra pas le problème global.
Toute dégradation des performances liée à la présence d'un grand nombre de tables (plus de 10 000) est due au fait que MariaDB intervient sur les fichiers de stockage. Ce travail inclut l'ouverture et la fermeture de fichiers de stockage par MariaDB. Pour résoudre ce problème, vous pouvez augmenter la taille des paramètres table_open_cache et table_definition_cache. L'augmentation des valeurs de ces paramètres peut toutefois augmenter la quantité de mémoire utilisée par MariaDB. Elle peut même utiliser toute la mémoire disponible. Pour plus d'informations, consultez Optimisation de table_open_cache
En outre, la présence d'un trop grand nombre de tables peut avoir un impact significatif sur le temps de démarrage de MariaDB. L'arrêt et le redémarrage propres ainsi que la reprise sur incident peuvent être affectés. Nous recommandons de maintenir le nombre total de tables en dessous de dix mille dans toutes les bases de données d'une instance de base de données.
Moteur de stockage
Les fonctionnalités de point-in-time restauration et de restauration de snapshots d'Amazon RDS pour MariaDB nécessitent un moteur de stockage récupérable en cas de panne. Bien que MariaDB prenne en charge plusieurs moteurs de stockage avec diverses capacités, toutes ne sont pas optimisées pour la récupération sur incident et la durabilité des données. Par exemple, bien qu'Aria remplace MyISAM en toute sécurité, il peut tout de même empêcher une point-in-time restauration ou une restauration instantanée de fonctionner comme prévu. Cela peut entraîner la perte ou la corruption de données lors du redémarrage de MariaDB après un incident. InnoDB est le moteur de stockage recommandé et pris en charge pour les instances de base de données MariaDB sur Amazon RDS. Si vous choisissez d'utiliser Aria avec Amazon RDS, suivre les étapes décrites dans Sauvegardes automatiques avec moteurs de stockage MariaDB non pris en charge peut être utile dans certaines situations pour la fonctionnalité de restauration d'instantané.
Si vous souhaitez convertir les tables MyISAM existantes en tables InnoDB, vous pouvez utiliser le processus décrit dans la section Converting Tables from MyISAM to InnoDB
Bonnes pratiques d'utilisation d'Oracle
Pour plus d’informations sur les bonnes pratiques d’utilisation de Amazon RDS for Oracle, consultez les Bonnes pratiques pour l’exécution d’une base de données Oracle sur Amazon Web Services.
Un atelier AWS virtuel organisé en 2020 comprenait une présentation sur l'exécution de bases de données Oracle de production sur Amazon RDS. Une vidéo de la présentation est disponible ici:
Bonnes pratiques pour utiliser les moteurs de stockage PostgreSQL
Parmi les deux principaux domaines dans lesquels vous pouvez améliorer les performances avec RDS pour PostgreSQL, l’un est lorsque vous chargez des données dans une instance de base de données. Une autre utilisation est lorsque vous utilisez la fonction autovacuum de PostgreSQL. Les sections suivantes couvrent certaines pratiques que nous recommandons pour ces domaines en particulier.
Pour plus d’informations sur la façon dont Amazon RDS met en œuvre d’autres tâches DBA courantes pour PostgreSQL, consultez Tâches courantes d’administration de bases de données pour Amazon RDS pour PostgreSQL.
Chargement des données dans une instance de base de données PostgreSQL
Lors du chargement des données dans une instance de base de données Amazon RDS pour PostgreSQL, modifiez vos paramètres d’instance de base de données et vos valeurs de groupe de paramètres de base de données. Définissez-les pour permettre l'importation de données la plus efficace possible dans votre instance de base de données.
Modifiez les paramètres de l'instance de base de données comme suit :
-
Désactivez les sauvegardes de l'instance de base de données (affectez la valeur 0 à backup_retention)
-
Désactivez le mode multi-AZ
Modifiez votre groupe de paramètres DB pour inclure les paramètres suivants. Testez également les réglages des paramètres pour déterminer les réglages les plus efficaces pour votre instance de base de données.
-
Augmentez la valeur du paramètre
maintenance_work_mem. Pour plus d'informations sur les paramètres de consommation de ressources PostgreSQL, consultez la documentation PostgreSQL. -
Augmentez la valeur des paramètres
max_wal_sizeetcheckpoint_timeoutpour réduire le nombre d'écritures dans le journal d'écriture anticipée (WAL). -
Désactivez le paramètre
synchronous_commit. -
Désactivez le paramètre autovacuum de PostgreSQL.
-
Assurez-vous qu'aucune des tables que vous importez n'est pas journalisée. Les données stockées dans les tables non journalisées peuvent être perdues lors d'un basculement. Pour plus d’informations, consultez CREATE TABLE UNLOGGED
(CRÉER UNE TABLE NON JOURNALISÉE).
Utilisez les commandes pg_dump -Fc (compressé) ou pg_restore -j (parallèle) avec ces paramètres.
Une fois l'opération de chargement terminée, réinitialisez votre instance de base de données et les paramètres de base de données à leurs paramètres normaux.
Utilisation de la fonction autovacuum de PostgreSQL
La fonction autovacuum pour les bases de données PostgreSQL est une fonction que nous vous recommandons vivement d'utiliser pour maintenir l'état de votre instance de bases de données PostgreSQL. Autovacuum automatise l'exécution des commandes VACUUM et ANALYZE ; son utilisation est exigée par PostgreSQL, non imposée par Amazon RDS et essentielle pour garantir de bonnes performances. La fonction est activée par défaut pour toutes les nouvelles instances de bases de données Amazon RDS pour PostgreSQL, et les paramètres de configuration associés sont configurés par défaut de manière appropriée.
Votre administrateur de base de données doit connaître et comprendre cette opération de maintenance. Pour accéder à la documentation PostgreSQL sur la fonction autovacuum, consultez The Autovacuum Daemon
Autovacuum n'est pas une opération « sans utilisation de ressources », mais elle fonctionne en arrière-plan et profite autant que possible aux opérations utilisateur. Lorsqu'elle est activée, la fonction autovacuum vérifie les tables ayant eu un grand nombre de tuples mis à jour ou supprimés. Elle protège également contre la perte de données très anciennes due au bouclage de l’ID de transaction. Pour plus d’informations, consultez Preventing Transaction ID Wraparound Failures
Autovacuum ne doit pas être considérée comme une opération aux frais généraux élevés qui peut être réduite pour améliorer les performances. Au contraire, les tables qui mettent à jour et suppriment très rapidement se détériorent vite avec le temps si la fonction autovacuum n'est pas exécutée.
Important
La non-exécution de la fonction autovacuum peut entraîner un arrêt obligatoire ultérieur pour effectuer une opération de nettoyage bien plus intrusive. Dans certains cas, une instance de base de données RDS pour PostgreSQL peut devenir indisponible en raison d’une utilisation trop prudente de l’autovacuum. Dans ces cas, la base de données PostgreSQL s'arrête pour se protéger. À ce stade, Amazon RDS doit effectuer un nettoyage single-user-mode complet directement sur l'instance de base de données. Ce vacuum complet peut entraîner une panne de plusieurs heures. Nous vous recommandons donc vivement de ne pas désactiver la fonction autovacuum, qui est activée par défaut.
Les paramètres d'autovacuum déterminent sa fréquence et son intensité de travail. Les paramètresautovacuum_vacuum_threshold et autovacuum_vacuum_scale_factor déterminent le moment où la fonction autovacuum est exécutée. Les paramètres autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit et autovacuum_cost_delay déterminent l'intensité de travail d'autovacuum. Pour plus d’informations sur la fonction autovacuum, son exécution et les paramètres obligatoires, consultez la Routine Vacuuming
La requête suivante indique le nombre de tuples « inactifs » dans une table appelée table1 :
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
Les résultats de la requête ressembleront à l'exemple ci-dessous :
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Vidéo des bonnes pratiques Amazon RDS pour PostgreSQL
La conférence AWS re:Invent 2020 comprenait une présentation sur les nouvelles fonctionnalités et les meilleures pratiques d'utilisation de PostgreSQL sur Amazon RDS. Une vidéo de la présentation est disponible ici:
Bonnes pratiques pour l'utilisation de SQL Server
Les bonnes pratiques pour un déploiement multi-AZ avec une instance de base de données SQL Server sont les suivantes :
Utilisez les événements de base de données Amazon RDS pour surveiller les basculements. Par exemple, vous pouvez être notifié par sms ou e-mail en cas de basculement d'une instance de base de données. Pour plus d’informations sur les événements Amazon RDS, consultez Utiliser la notification d'événements d'Amazon RDS.
Si votre application met en cache des valeurs DNS, configurez leatime-to-live (TTL) à moins de 30 secondes. La configuration de la durée de vie est une bonne pratique en tant que tel en cas de basculement. Lors d'un basculement, l'adresse IP peut changer et la valeur mise en cache peut ne plus être en service.
Nous vous recommandons de ne pas activer les modes suivants car ils désactivent la journalisation des transactions, qui est obligatoire pour le déploiement multi-AZ :
-
Mode de récupération simple
-
Mode hors ligne
-
Mode lecture seule
-
Testez pour déterminer combien de temps votre instance de base de données met-elle pour basculer. Les délais de basculement peuvent varier en raison du type de base de données, la classe d'instance et le type de stockage utilisé. Vous devez également tester la capacité de votre application à continuer de fonctionner en cas de basculement.
Pour raccourcir les délais de basculement, procédez comme suit :
Veillez à avoir suffisamment d'IOPS provisionnées allouées pour votre charge de travail. InadéquatI/O can lengthen failover times. Database recovery requires I/O.
Utilisez de plus petites transactions. La récupération de la base de données repose sur les transactions, donc si vous pouvez séparer d'importantes transactions en plusieurs transactions plus petites, vos délais de basculement devraient diminuer.
Pensez que lors d'un basculement, les temps de latence sont élevés. Dans le cadre d'un processus de basculement, Amazon RDS réplique automatiquement vos données vers une nouvelle instance de secours. Cette réplication signifie que de nouvelles données sont transférées vers deux instances de base de données différentes. Il peut donc y avoir une certaine latence jusqu'à ce que l'instance de base de données de secours rattrape la nouvelle instance de base de données principale.
Déployez vos applications dans toutes les zones de disponibilité. Si une zone de disponibilité tombe en panne, vos applications qui se trouvent dans les autres zones de disponibilité seront toujours disponibles.
Lorsque vous travaillez avec un déploiement multi-AZ de SQL Server, rappelez-vous qu'Amazon RDS crée des réplicas pour toutes les bases de données SQL Server sur votre instance. Si vous ne souhaitez pas que des bases de données spécifiques aient des réplicas secondaires, configurez une instance de base de données séparée qui n'utilise pas de déploiement multi-AZ pour ces bases de données.
Vidéo des bonnes pratiques Amazon RDS pour SQL Server
La conférence AWS re:Invent 2019 comprenait une présentation sur les nouvelles fonctionnalités et les meilleures pratiques relatives à l'utilisation de SQL Server sur Amazon RDS. Une vidéo de la présentation est disponible ici:
Utilisation des groupes de paramètres DB
Nous vous recommandons de tester les modifications apportées aux groupes de paramètres de base de données sur une instance de base de données test avant d'appliquer ces modifications à vos instances de base de données de production. La configuration incorrecte de paramètres de moteur DB dans un groupe de paramètres de base de données peut avoir des effets contraires involontaires, notamment une dégradation de la performance et une instabilité du système. Montrez-vous toujours prudent lorsque vous modifiez des paramètres de moteur DB et sauvegardez votre instance de base de données avant de modifier un groupe de paramètres de base de données.
Pour plus d'informations sur la sauvegarde de votre instance de base de données, consultez Sauvegarde, restauration et exportation de données.
Bonnes pratiques pour automatiser la création d'instances de base de données
Une des bonnes pratiques de Amazon RDS consiste à créer une instance de base de données avec la version mineure préférée du moteur de base de données. Vous pouvez utiliser l' AWS CLI API Amazon RDS ou automatiser la création AWS CloudFormation d'instances de base de données. Lorsque vous utilisez ces méthodes, vous pouvez spécifier uniquement la version principale et Amazon RDS crée automatiquement l'instance avec la version mineure préférée. Par exemple, si PostgreSQL 12.5 est la version mineure préférée, et que vous spécifiez la version 12 avec create-db-instance, l'instance de base de données sera à la version 12.5.
Pour déterminer la version mineure préférée, vous pouvez exécuter la commande describe-db-engine-versions avec l'option --default-only, comme illustré dans l'exemple suivant.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
Pour plus d'informations sur la création d'instances de base de données par programmation, consultez les ressources suivantes :
En utilisant le AWS CLI — create-db-instance
Utilisation de AWS CloudFormation — AWS : :RDS : : DBInstance
Vidéo sur les nouvelles fonctionnalités Amazon RDS
La conférence AWS re:Invent 2023 comprenait une présentation sur les nouvelles fonctionnalités d'Amazon RDS. Une vidéo de la présentation est disponible ici:
