Amazon Forecast n'est plus disponible pour les nouveaux clients. Les clients existants d'Amazon Forecast peuvent continuer à utiliser le service normalement. En savoir plus »
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Algorithme DeepAR+
Amazon Forecast DeepAr+ est un algorithme d'apprentissage supervisé permettant de prévoir des séries chronologiques scalaires (unidimensionnelles) à l'aide de réseaux neuronaux récurrents (). RNNs Les méthodes de prévisions classiques, telles que la moyenne mobile intégrée autorégressive (ARIMA) ou le lissage exponentiel (ETS) adaptent un seul modèle par série chronologique individuelle, qui sera utilisé pour extrapoler la série chronologique dans l'avenir. Néanmoins, dans la plupart des applications, vous pouvez avoir de nombreuses séries chronologiques semblables dans un ensemble d'unités transversales Ces groupements en séries chronologiques peuvent demander différents produits, des charges de serveurs et des demandes de pages web. Dans ce cas, il peut être avantageux de former un seul modèle commun à toutes ces séries chronologiques. DeepAR+ adopte cette approche. Lorsque votre ensemble de données contient des centaines de séries chronologiques de fonctions, l’algorithme DeepAR+ surpasse les méthodes standard ARIMA et ETS. Vous pouvez également utiliser le modèle formé pour générer des prévisions pour les nouvelles séries chronologiques similaires à celles pour laquelle il avait été formé.
Carnets en Python
Pour un step-by-step guide sur l'utilisation de l'algorithme DeepAr+, consultez Getting Started with
Fonctionnement de DeepAR+
Pendant la formation, DeepAR+ utilise un ensemble de données de formation et un ensemble de données de test facultatif. Il utilise l'ensemble de données de test pour évaluer le modèle formé. En général, les ensembles de données de formation et les ensembles de données de test ne doivent pas contenir le même ensemble de séries chronologiques. Vous pouvez utiliser un modèle entraîné sur un ensemble d'entraînement donné afin de générer des prévisions pour les séries chronologiques à venir dans l'ensemble d'entraînement, ainsi que pour les autres séries chronologiques. Les ensembles de données de formation et les ensembles de données de test se composent d'une (de préférence plusieurs) série chronologique cible. Ils peuvent éventuellement être associés à un vecteur de séries chronologiques de fonctionnalités et à un vecteur de caractéristiques catégorielles (pour plus de détails, voir Interface d'entrée/sortie DeePar dans SageMaker le guide du développeur AI). L'exemple suivant illustre comment cela fonctionne pour un élément d'ensemble de données de formation indexé par i. L'ensemble des données de formation se compose d'une série chronologique cible, zi,t et de deux séries chronologiques de fonctions associées, xi,1,t et xi,2,t.
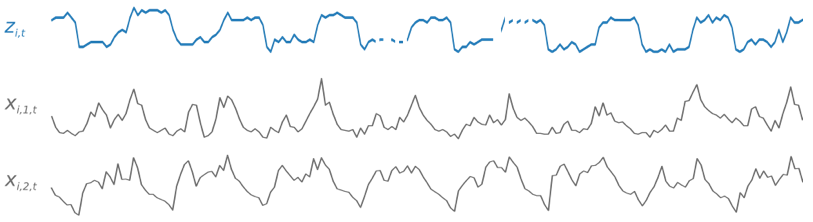
La série chronologique cible peut contenir des valeurs manquantes (représentées dans les graphiques par des ruptures de ligne dans les séries chronologiques). DeepAR+ prend uniquement en charge les séries chronologiques de fonctions connues dans le futur. Cela vous permet d'exécuter des scénarios « hypothético-déductifs ». Par exemple, « Que se passe-t-il si je modifie le prix d'un produit ? »
Chaque série chronologique cible peut également être associée à un certain nombre de caractéristiques catégorielles. Vous pouvez l'utiliser pour encoder le groupement auquel appartient la série chronologique. Avec les fonctions de catégorie le modèle apprend le comportement normal de ce groupe, ce qui peut augmenter le niveau de précision. Un modèle implémente ceci en apprenant un vecteur d'intégration pour chaque groupe qui capture les propriétés courantes de toutes les séries chronologiques du groupe.
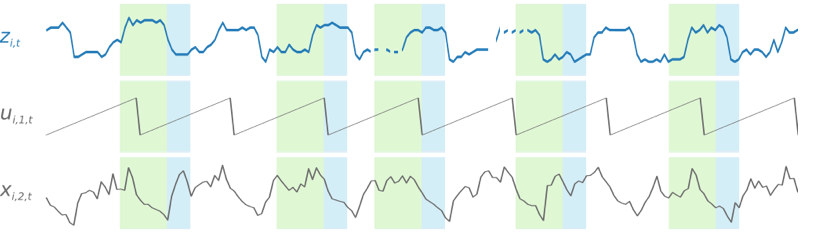
Afin de faciliter les schémas d'apprentissage liés au temps, tels que les pics durant les week-ends, DeepAR+ crée automatiquement des séries chronologiques de fonctions basées sur la granularité. Par exemple, DeepAR+ crée deux séries chronologiques de fonctions (jour du mois et jour de l'année) à une fréquence hebdomadaire. Il utilise ces séries chronologiques de fonctions dérivées avec les séries chronologiques de fonctions personnalisées que vous fournissez au cours de la formation et de l'inférence. L'exemple suivant montre deux fonctions de séries chronologiques dérivées : ui,1,t représente l'heure de la journée et ui,2,t le jour de la semaine.

DeepAR+ inclut automatiquement ces séries chronologiques de fonctions basées sur la fréquence des données et la taille des données de formation. Le tableau suivant répertorie les fonctions qui peuvent être obtenues pour chaque fréquence de temps prise en charge.
| Fréquence des séries chronologiques | Caractéristiques dérivées |
|---|---|
| Minute | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Heure | hour-of-day, day-of-week, day-of-month, day-of-year |
| jour | day-of-week, day-of-month, day-of-year |
| semaine | week-of-month, week-of-year |
| Mois | month-of-year |
Un modèle DeepAR+ est formé par plusieurs exemples de formation échantillonnés de façon aléatoire à partir de chacune des séries chronologiques de l'ensemble de données de formation. Chaque exemple d'entraînement se compose d'une paire de fenêtres de contexte et de prédiction adjacentes avec des longueurs prédéfinies fixes. L'hyperparamètre context_length contrôle jusqu'où peut remonter le réseau dans le passé et le paramètre ForecastHorizon contrôle jusqu'où peuvent porter les prévisions sur le futur. Pendant la formation, Amazon Forecast ignore les éléments de l'ensemble de données de formation dont la série chronologique est plus courte que la longueur de prévision spécifiée. L'exemple suivant illustre cinq échantillons avec une longueur de contexte (surlignée en vert) de 12 heures et une longueur de prévisions (surlignée en bleu) de 6 heures, tracés à partir de l'élément i. Pour simplifier, nous avons exclu les séries chronologiques de fonctions xi,1,t et ui,2,t.
Afin de capturer les variations saisonnières, DeepAR+ alimente automatiquement les valeurs décalées (période passée) issues des séries chronologiques cibles. Dans notre exemple d'échantillons pris sur une fréquence horaire, pour chaque index de temps t = T, le modèle prend les valeurs zi,t, qui se sont produites environ un, deux et trois jours par le passé (surlignées en rose).
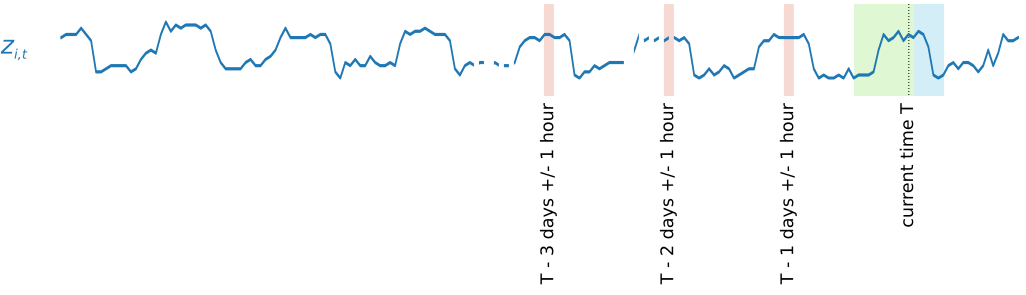
Pour l'inférence, le modèle formé utilise en entrée la série chronologique cible, qui peut ou non avoir été utilisée pendant la formation, puis prévoit une distribution de probabilités pour les prochaines valeurs ForecastHorizon. Puisque DeepAR+ est formé sur la totalité de l'ensemble de données, la prévision tient compte des modèles appris à partir de séries chronologiques similaires.
Pour plus d'informations sur les mathématiques derrière DeepAR+, consultez DeepAR : prévisions probabilistes avec réseaux récurrents autorégressifs
Hyperparamètres DeepAR+
Le tableau suivant répertorie les hyperparamètres que vous pouvez utiliser dans l’algorithme DeepAR+. Les paramètres en gras participent à l'optimisation des hyperparamètres (HPO).
| Nom du paramètre | Description |
|---|---|
context_length |
Le nombre de points temporels fournis au modèle avant de procéder à la prévision. La valeur de ce paramètre doit être à peu près la même que la
|
epochs |
Nombre maximal de passages sur les données de formation. La valeur optimale dépend de la taille des données et du taux d'apprentissage. Des jeux de données plus petits et des taux d'apprentissage plus faibles nécessitent plus de valeurs epoch pour obtenir de bons résultats.
|
learning_rate |
Le taux d'apprentissage utilisé dans l'entraînement.
|
learning_rate_decay |
Taux de diminution du taux d'apprentissage. Au maximum, le taux d'apprentissage est réduit
|
likelihood |
Le modèle génère une prévision probabiliste, et peut fournir des quantiles de la distribution et renvoyer des échantillons. En fonction de vos données, sélectionnez une probabilité appropriée (modèle de bruit) qui est utilisée pour les estimations d'incertitude. Valeurs valides
|
max_learning_rate_decays |
Le nombre maximal de réductions de taux d'apprentissage qui devraient se produire.
|
num_averaged_models |
Dans DeepAR +, une trajectoire de formation peut rencontrer plusieurs modèles. Chaque modèle peut avoir des forces et des faiblesses de prévisions différentes. DeepAR+ peut faire une moyenne des comportements de modèle pour profiter des forces de tous les modèles.
|
num_cells |
Le nombre de cellules à utiliser dans chaque couche masquée du réseau RNN.
|
num_layers |
Nombre de couches masquées du réseau RNN.
|
Réglage du modèle DeepAR+
Pour régler des modèles Amazon Forecast DeepAR+, suivez ces recommandations pour optimiser le processus de formation et la configuration matérielle.
Bonnes pratiques d'optimisation de processus
Pour obtenir les meilleurs résultats, suivez les recommandations suivantes :
-
Sauf lorsque vous fractionnez les ensembles de données, vous devez toujours fournir l'ensemble des séries chronologiques pour la formation et les tests, ainsi que lorsque vous appelez le modèle pour l'inférence. Quelle que soit la façon dont vous définissez
context_length, ne fractionnez pas la série chronologique et fournissez-la dans son intégralité. Le modèle utilisera les points de données d'un passé plus lointain quecontext_lengthpour la fonction des valeurs décalées. -
Pour le réglage du modèle, vous pouvez diviser l'ensemble de données en ensembles de données de test et de formation. Dans un scénario d'évaluation typique, vous devez tester le modèle sur les mêmes séries chronologiques que celles utilisées dans les formations, mais sur les points temporels futurs
ForecastHorizonimmédiatement après le dernier point visible. Pour créer des ensembles de données de formation et de test qui répondent à ces critères, utilisez tout l'ensemble de données (toutes les séries chronologiques) en tant qu'ensemble de données de test et supprimez les derniers pointsForecastHorizonde chaque série chronologique. De cette façon, lors de la formation, le modèle ne détecte pas les valeurs cibles pour les points temps sur lesquels il est évalué pendant le test. Dans cette phase de test, les derniers pointsForecastHorizonde chaque série chronologique de l'ensemble de données de test sont supprimées et une prévision est générée. La prévision est ensuite comparée aux valeurs réelles pour les derniers pointsForecastHorizon. Vous pouvez créer des évaluations plus complexes en répétant les séries chronologiques à plusieurs reprises dans l'ensemble de données de test, mais en les coupant à différents points de terminaison. Cela produit des métriques de précision qui sont calculées sur une moyenne de plusieurs prévisions à partir de différents points temps. -
Évitez d'utiliser des valeurs très grandes (> 400) pour le
ForecastHorizoncar cela ralentit le modèle et le rend moins précis. Si vous souhaitez procéder à des prévisions plus lointaines, envisagez de regrouper vos données à une fréquence plus élevée. Par exemple, utilisez5minplutôt que1min. -
En raison des décalages, le modèle peut rechercher dans un passé plus lointain
context_length. Par conséquent, vous n'avez pas à définir ce paramètre sur une grande valeur. Un bon point de départ pour ce paramètre est la même valeur queForecastHorizon. -
Former des modèles DeepAR+ avec autant de séries chronologiques qui sont disponibles. Même si un modèle DeepAR+ formé sur une seule série chronologique peut déjà bien fonctionner, des méthodes de prévisions standard tels que ARIMA ou ETS peuvent être plus précises et sont plus adaptées à ce cas d'utilisation. DeepAR+ commence à surpasser les méthodes standard lorsque votre ensemble de données contient des centaines de séries chronologiques de fonctions. Actuellement, DeepAR+ exige qu'il y ait au moins 300 observations disponibles sur l'ensemble des séries chronologiques de formation.
